

Linux性能优化:Cache对性能的影响
描述
Cache对性能的影响首先我们要知道,CPU访问内存时,不是直接去访问内存的,而是先访问缓存(cache)。
当缓存中已经有了我们要的数据时,CPU就会直接从缓存中读数据,而不是从内存中读。
CPU和缓存的关系如下:
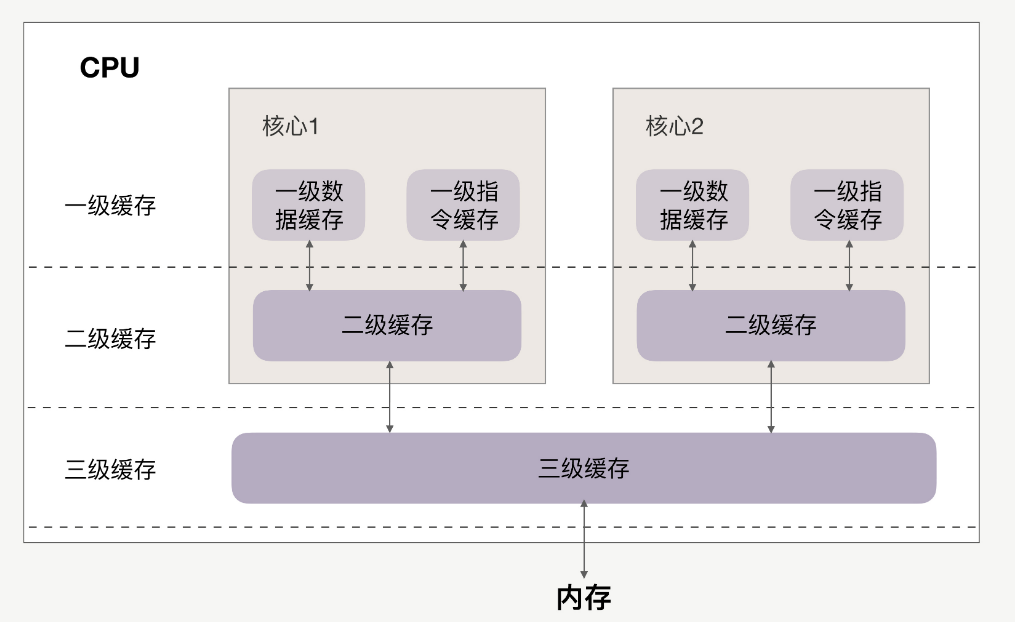
缓存分为一级、二级、三级,最靠近CPU的是一级缓存,最远的是内存,离CPU越近速度越快。
访问速度上,L1》L2》L3》内存,缓存比内存速度要快得非常多。
如果CPU操作的数据在缓存中,则直接从缓存中读取,这个过程就叫缓存命中。
因此提升性能的关键,就是要提高缓存命中率。下面来看如何提高缓存命中率。
提高数据缓存命中率来看一个实例,有一个N*N的二维数组,例如:
int array[N][N];
现在用两个for循环遍历这个数组,访问每个元素的内容:
for(i = 0; i 《 N; i+=1) { for(j = 0; j 《 N; j+=1) { array[i][j] = 0;//速度快
//array[j][i] = 0;//速度慢 } }
有两种访问方式:array[i][j]和array[j][i]。
在性能上,array[i][j]会比array[j][i]执行地更快,并且速度相差8倍。
1、速度更快的原因
首先数组在内存上是连续的,假设N等于2,则array[2][2]在内存中的排布是:
array[0][0]、array[0][1]、array[1][0]、array[1][1]、
以array[i][j]方式访问,即按内存中的顺序访问,当访问array[0][0]时,CPU就已经把数组的剩余三个数据(array[0][1]、array[1][0]、array[1][1])加载到了缓存当中。
当继续访问后三个元素时,CPU会直接从缓存中读取数据,而不需要从内存中读取(cache命中)。因此速度会很快。
如果以array[j][i]方式访问数组,则访问顺序为:
array[0][0]、array[1][0]、array[0][1]、array[1][1]
此时访问顺序是跳跃的,并不是按数组在内存中的的排布顺序来访问。如果N很大的话,那么执行array[j][i]时,array[j+1][i]的内容是没法读进缓存里的,等到要访问array[j+1][i]时就只能从内存中读取。
所以array[j][i]的速度会慢于array[i][j]。
2、速度相差8倍的原因
刚刚提到,如果这个二维数组的N很大,array[j+1][i]的内容是没法读到缓存里的,那CPU一次能够将多少数据加载进缓存里呢?
这个其实跟cache line有关,cache line代表缓存一次载入数据的大小。可以通过以下命令查看cache line为多大:
cat /sys/devices/system/cpu/cpu0/cache/index0/coherency_line_size

cache line为64,代表CPU缓存一次数据的大小为64字节。
当访问array[0][0]时,该元素所占用的字节数不到64字节,CPU就会按顺序补足后续元素,就会把后面的array[0][1]、array[1][0]等内容一起读到缓存里,直到凑够64字节。
正因如此,按顺序访问的array[i][j]才会比不按顺序访问的array[j][i]速度快。
再看看为什么速度相差8倍。我们知道,二维数组中,第一维元素放的是地址,第二维元素才是数据。64位系统中,地址占用8个字节,cache
line为64的话,地址已经占用了8字节,那每个cache line最多能载入不到8个二维数组元素,N很大的情况下,他们的性能平均下来就会相差将近8倍。
结论:按内存布局顺序访问,可以提高数据缓存命中率。
-
Linux系统性能优化技巧2025-08-27 1286
-
如何优化Linux服务器的性能2024-09-29 1633
-
Linux内核slab性能优化的核心思想2023-11-13 1827
-
Cache与性能优化精彩问答38条2023-01-11 2183
-
Linux性能优化大全!2022-11-21 1217
-
cache的排布与CPU的典型分布2022-10-18 3228
-
Linux内核文件Cache机制2021-08-31 1036
-
Linux CPU的性能应该如何优化2020-01-18 4448
-
Linux和Android系统故障和优化性能的方法和流程探讨2019-07-22 1264
-
Linux系统的性能优化策略2019-07-16 2130
-
你知道linux的cache memory?2019-04-26 1653
-
HBase性能优化方法总结2018-04-20 2064
-
NAS存储系统性能优化攻略2012-12-29 3643
-
基于Linux的Socket网络编程的性能优化2009-10-22 1334
全部0条评论

快来发表一下你的评论吧 !
