

为什么transformer性能这么好?Transformer的上下文学习能力是哪来的?
描述
有理论基础,我们就可以进行深度优化了。为什么 transformer 性能这么好?它给众多大语言模型带来的上下文学习 (In-Context Learning) 能力是从何而来?在人工智能领域里,transformer 已成为深度学习中的主导模型,但人们对于它卓越性能的理论基础却一直研究不足。 最近,来自 Google AI、苏黎世联邦理工学院、Google DeepMind 研究人员的新研究尝试为我们揭开谜底。在新研究中,他们对 transformer 进行了逆向工程,寻找到了一些优化方法。论文《Uncovering mesa-optimization algorithms in Transformers》:
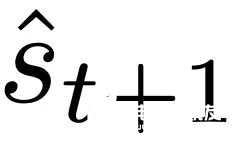 。 该研究的贡献包括:
。 该研究的贡献包括:
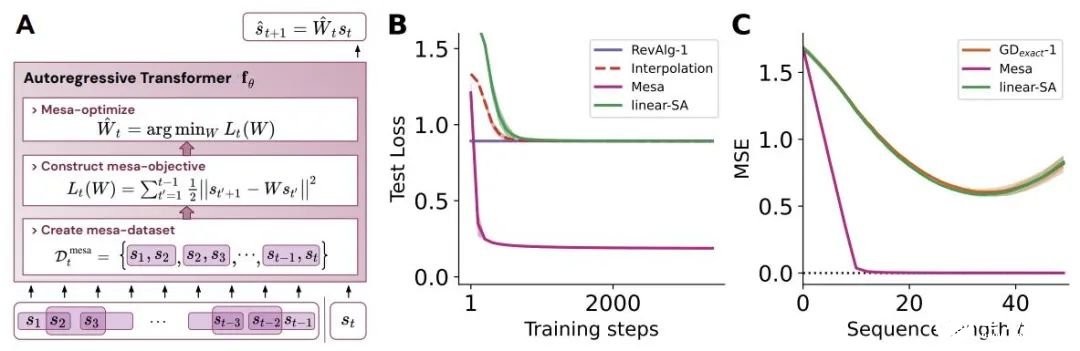
- 概括了 von Oswald 等人的理论,并展示了从理论上,Transformers 是如何通过使用基于梯度的方法优化内部构建的目标来自回归预测序列下一个元素的。
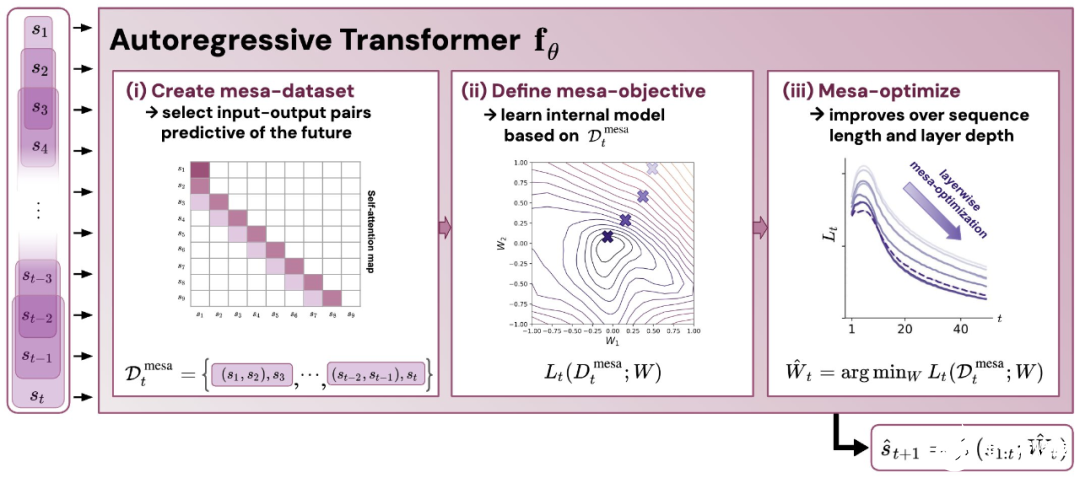
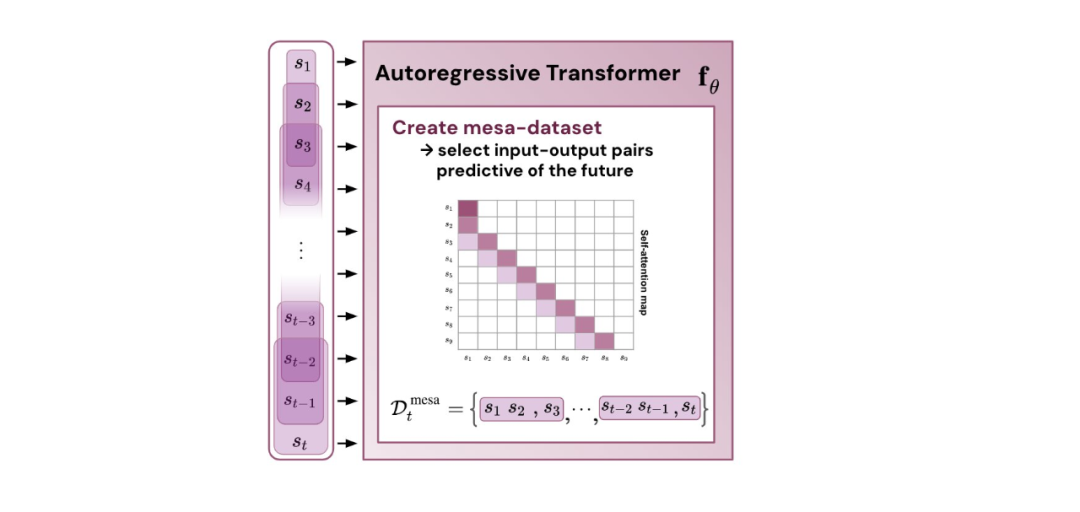
- 通过实验对在简单序列建模任务上训练的 Transformer 进行了逆向工程,并发现强有力的证据表明它们的前向传递实现了两步算法:(i) 早期自注意力层通过分组和复制标记构建内部训练数据集,因此隐式地构建内部训练数据集。定义内部目标函数,(ii) 更深层次优化这些目标以生成预测。
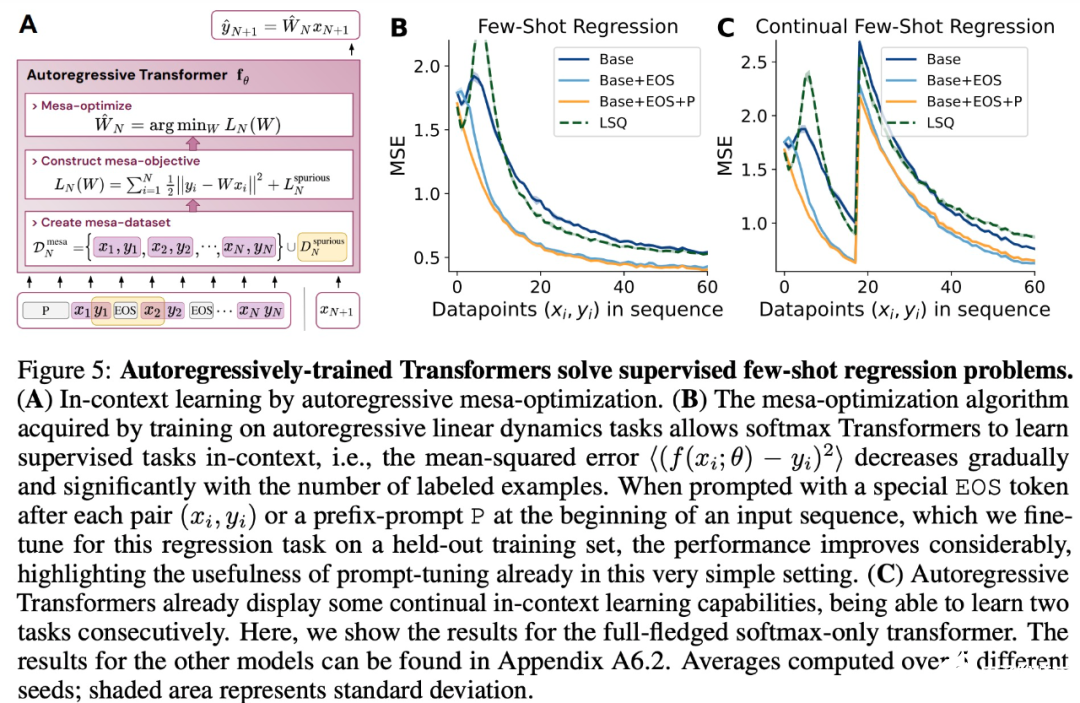
- 与 LLM 类似,实验表明简单的自回归训练模型也可以成为上下文学习者,而即时调整对于改善 LLM 的上下文学习至关重要,也可以提高特定环境中的表现。
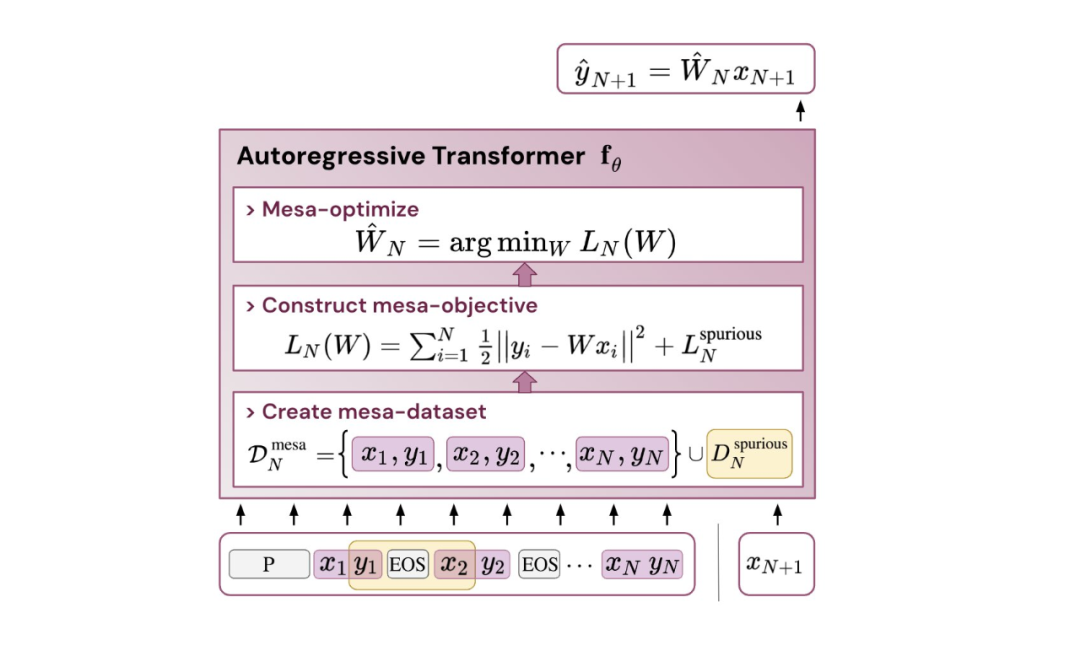
- 受发现注意力层试图隐式优化内部目标函数的启发,作者引入了 mesa 层,这是一种新型注意力层,可以有效地解决最小二乘优化问题,而不是仅采取单个梯度步骤来实现最优。实验证明单个 mesa 层在简单的顺序任务上优于深度线性和 softmax 自注意力 Transformer,同时提供更多的可解释性。

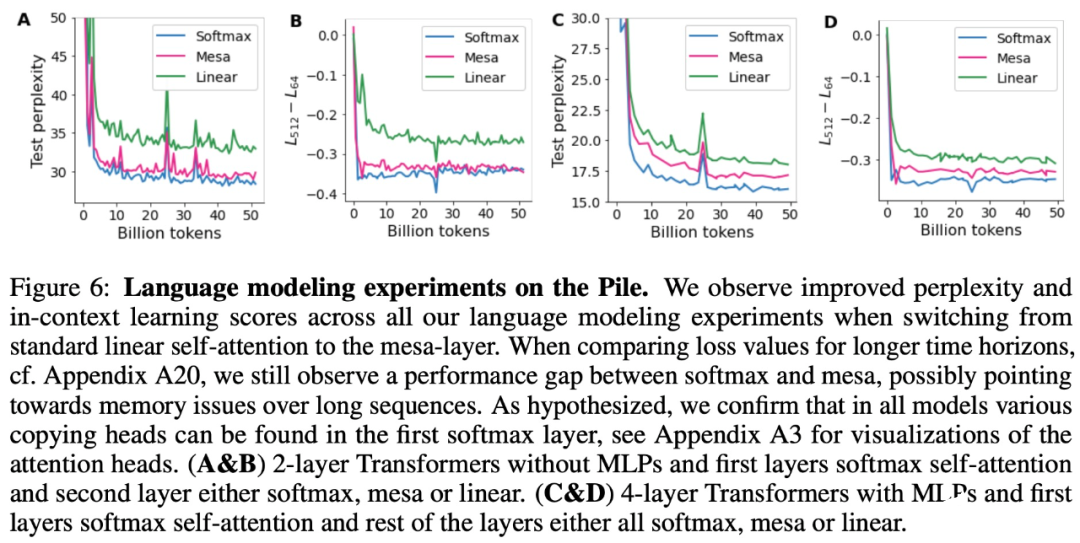
- 在初步的语言建模实验后发现,用 mesa 层替换标准的自注意力层获得了有希望的结果,证明了该层具有强大的上下文学习能力。
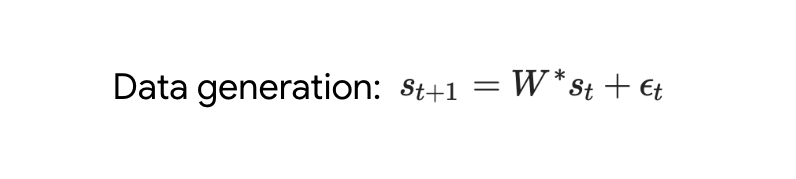
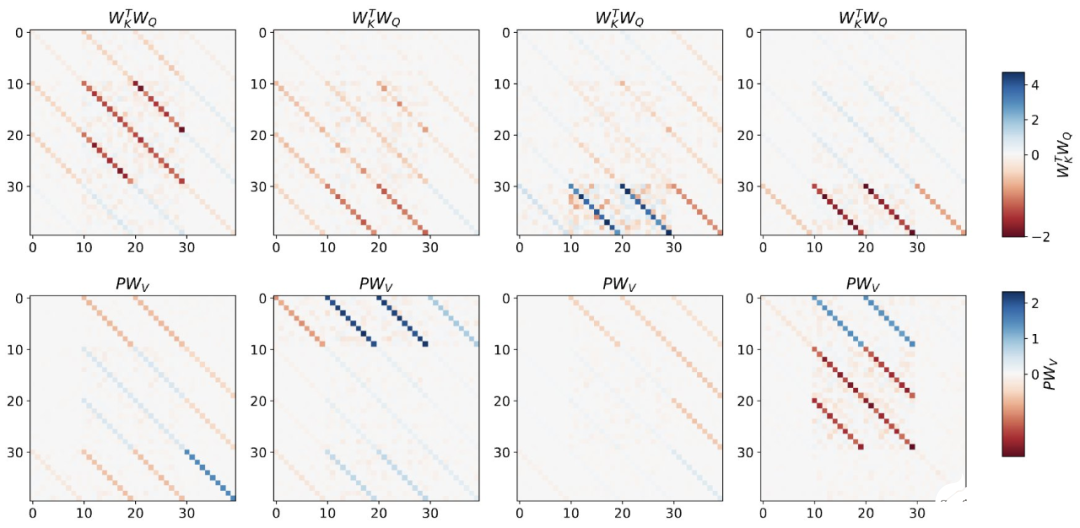
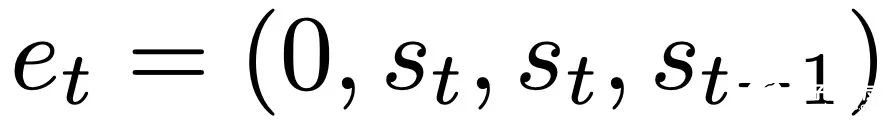 ,这对应于选择 W_0 = 0。
,这对应于选择 W_0 = 0。
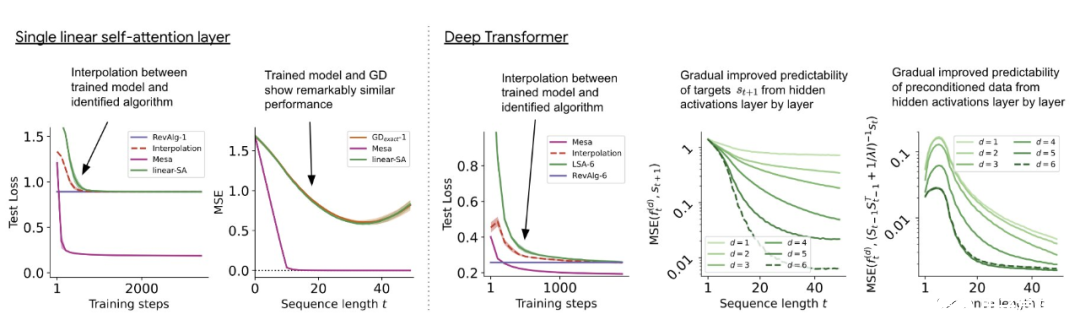
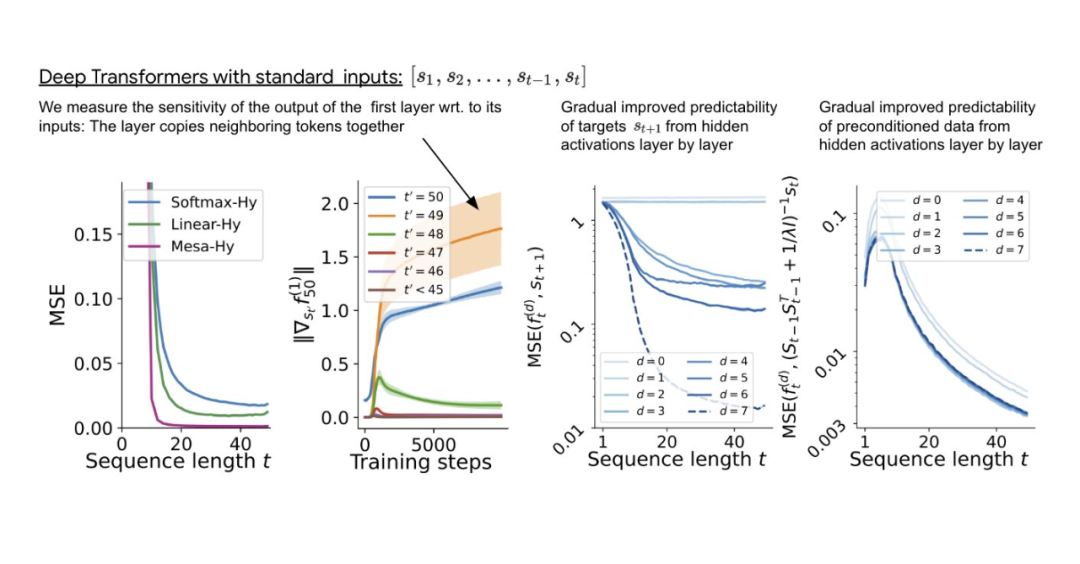
与单层模型一样,作者在训练模型的权重中看到了清晰的结构。作为第一个逆向工程分析,该研究利用这个结构并构建一个算法(RevAlg-d,其中 d 表示层数),每个层头包含 16 个参数(而不是 3200 个)。作者发现这种压缩但复杂的表达式可以描述经过训练的模型。特别是,它允许以几乎无损的方式在实际 Transformer 和 RevAlg-d 权重之间进行插值。 虽然 RevAlg-d 表达式解释了具有少量自由参数的经过训练的多层 Transformer,但很难将其解释为 mesa 优化算法。因此,作者采用线性回归探测分析(Alain & Bengio,2017;Akyürek et al.,2023)来寻找假设的 mesa 优化算法的特征。 在图 3 所示的深度线性自注意力 Transformer 上,我们可以看到两个探针都可以线性解码,解码性能随着序列长度和网络深度的增加而增加。因此,基础优化发现了一种混合算法,该算法在原始 mesa-objective Lt (W) 的基础上逐层下降,同时改进 mesa 优化问题的条件数。这导致 mesa-objective Lt (W) 快速下降。此外可以看到性能随着深度的增加而显着提高。 因此可以认为自回归 mesa-objective Lt (W) 的快速下降是通过对更好的预处理数据进行逐步(跨层)mesa 优化来实现的。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
- 相关推荐
- 热点推荐
- 人工智能
- 深度学习
- DeepMind
- Transformer
- 大模型
-
Transformer架构中编码器的工作流程2025-06-10 1412
-
首篇!Point-In-Context:探索用于3D点云理解的上下文学习2023-07-13 2107
-
谷歌新作SPAE:GPT等大语言模型可以通过上下文学习解决视觉任务2023-07-09 2169
-
基于Transformer的大型语言模型(LLM)的内部机制2023-06-25 2833
-
如何分析Linux CPU上下文切换问题2022-05-05 3120
-
进程上下文/中断上下文及原子上下文的概念2021-01-13 1148
-
基于Transformer模型的上下文嵌入何时真正值得使用?2020-08-28 3706
-
CMU、谷歌大脑的研究者最新提出万用NLP模型Transformer的升级版2019-01-14 4808
-
进程上下文与中断上下文的理解2018-12-11 3450
-
关于进程上下文、中断上下文及原子上下文的一些概念理解2018-09-06 3926
-
初学OpenGL:什么是绘制上下文2018-04-28 2940
-
基于上下文相似度的分解推荐算法2017-11-27 1009
-
基于Pocket PC的上下文菜单实现2011-07-25 1014
-
基于交互上下文的预测方法2009-10-04 735
全部0条评论

快来发表一下你的评论吧 !
