

ICML 2023 | 对多重图进行解耦的表示学习方法
描述

Introduction
无监督多重图表示学习(UMGRL)受到越来越多的关注,但很少有工作同时关注共同信息和私有信息的提取。在本文中,我们认为,为了进行有效和鲁棒的 UMGRL,提取完整和干净的共同信息以及更多互补性和更少噪声的私有信息至关重要。
为了实现这一目标,我们首先研究了用于多重图的解缠表示学习,以捕获完整和干净的共同信息,并设计了对私有信息进行对比约束,以保留互补性并消除噪声。此外,我们在理论上分析了我们方法学到的共同和私有表示可以被证明是解缠的,并包含更多与任务相关和更少与任务无关的信息,有利于下游任务。大量实验证实了所提方法在不同下游任务方面的优越性。

论文标题:
Disentangled Multiplex Graph Representation Learning
论文链接:https://openreview.net/pdf?id=lYZOjMvxws
代码链接:https://github.com/YujieMo/DMG

Motivation
以前的 UMGRL 方法旨在隐式提取不同图之间的共同信息,这对于揭示样本的身份是有效和鲁棒的。然而,它们通常忽视了每个图的私有信息中的互补性,并可能失去节点之间的重要属性。
例如,在多重图中,其中论文是节点,边代表两个不同图中的共同主题或共同作者。如果一个私有边(例如,共同主题关系)仅存在于某个图中,并连接来自相同类别的两篇论文,它有助于通过提供互补信息来降低类内差距,从而识别论文。因此,有必要同时考虑共同信息和私有信息,以实现 UMGRL 的有效性和鲁棒性。
基于有助于识别样本的共同信息,捕获不同图之间的所有共同信息(即完整的)是直观的。此外,这种完整的共同信息应该仅包含共同信息(即干净的)。相反,如果共同信息包含其他混淆的内容,共同信息的质量可能会受到损害。
因此,第一个问题出现了:如何获得完整和干净的共同信息?另一方面,私有信息是互补性和噪声的混合。考虑引文网络的同一个示例,如果私有边连接来自不同类别的两篇论文,它可能会干扰消息传递,应该作为噪声被删除。因此,第二个问题出现了:如何保留私有信息中的互补性并去除噪声?
然而,以前的 UMGRL 方法很少探讨了上述问题。最近,已经开发了解耦表示学习方法,以获得共同和私有表示,但由于多重图中节点之间的复杂关系以及图结构中的互补性和噪声,将它们应用于解决 UMGRL 中的上述问题是具有挑战性的。为此,我们提出了一种新的解耦多重图表示学习框架,以回答上述两个问题。

Method
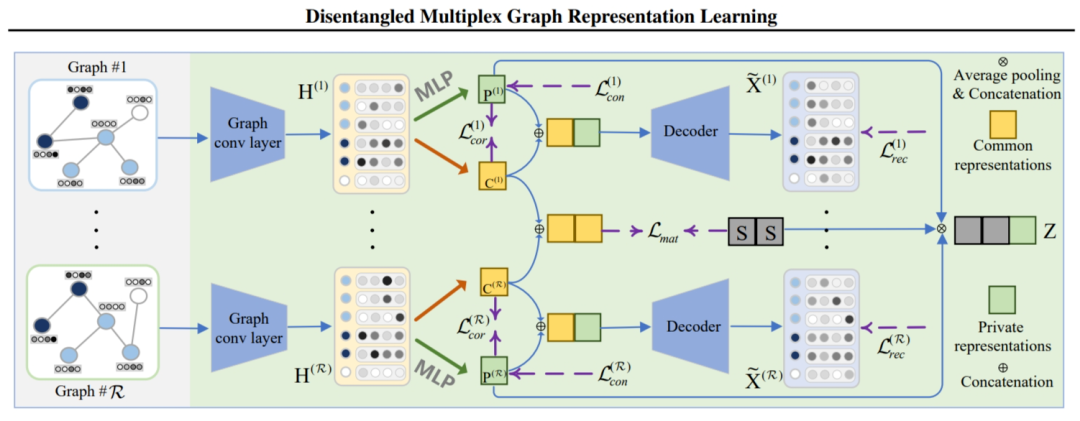
Notations
表示多重图,表示多重图中的第 张图,表示图的数量。
本文模型 DMG 首先通过一个共同变量 学习到经过解耦的共同表示以及私有表示 ,接着获取到融合表示。
3.1 Common Information Extraction
以前的 UMGRL 方法(例如,图之间的对比学习方法)通常通过最大化两个图之间的互信息来隐式捕获不同图之间的共同模式。例如,为了提取共同信息,STENCIL(Zhu等人,2022)最大化每个图与聚合图之间的互信息,而 CKD(Zhou等人,2022)最大化不同图中区域表示和全局表示之间的互信息。
然而,由于它们未能将共同信息与私有信息解耦,因此这些努力不能明确地捕获完整且干净的共同信息。为了解决这个问题,本文研究了解耦表示学习,以获得完整且 clean 的共同信息。
具体地,首先使用图卷积层 生成节点表示 :
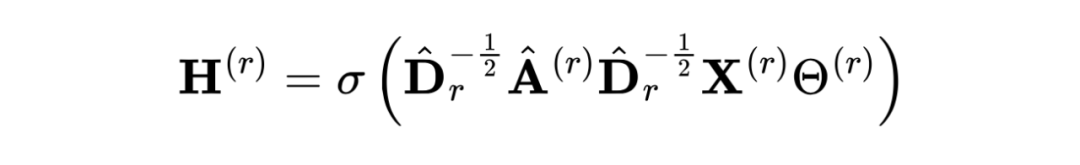
表示一个带权重的自环; 表示度矩阵; 表示卷积层 的权重矩阵。
接着使用 MLP 来促进每张图共同和私有信息的解耦过程,分别将节点嵌入 映射为共同表示和私有表示 。 给定每张图的共同表示 ,对齐这些表示最简单的方法使让它们彼此相等。然而这样做会影响共同表示的质量。在本文中,我们通过奇异值分解操作引入了一个具有正交性和零均值的公共变量 到共同表示中。然后,我们对公共表示 与公共变量 之间进行匹配损失,旨在逐渐对齐来自不同图的共同表示,以捕获它们之间的完整共同信息。匹配损失的公式如下: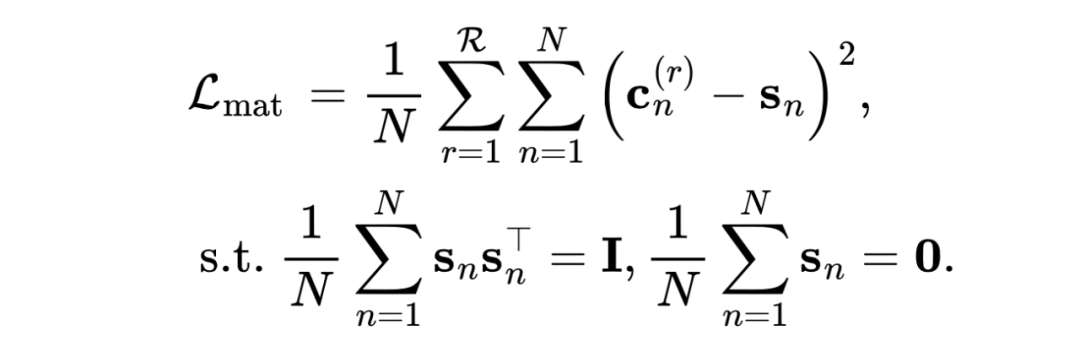 的作用是作为所有图共同表示之间的一个桥梁,使得这些表示具有较好的一致性:。
的作用是作为所有图共同表示之间的一个桥梁,使得这些表示具有较好的一致性:。
然后,为了解耦公共和私有表示,我们必须强化它们之间的统计独立性。值得注意的是,如果公共和私有表示在统计上是独立的,那么必须满足:
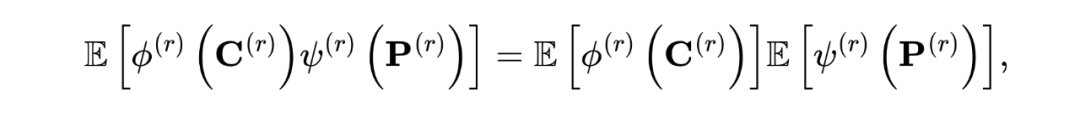
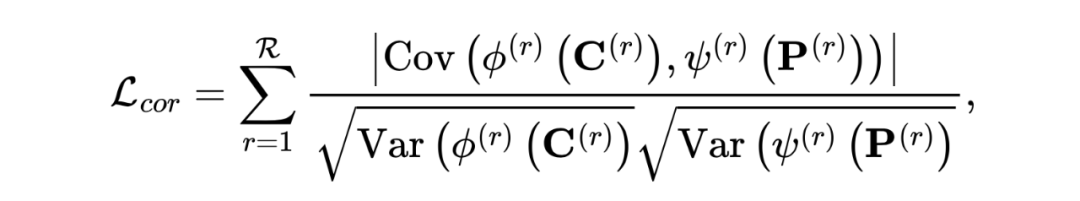 我们期望通过匹配损失(即获得完整的共同信息)和相关性损失(即获得干净的共同信息)来获得清晰的共同表示 中的共同信息。然而,在无监督框架下,学得的共同和私有表示可能是微不足道的解决方案。
常见的解决方案包括对比学习方法和自编码器方法。对比学习方法引入大量负样本以避免微不足道的解决方案,但可能会引入大量的内存开销。自编码器方法采用自编码器框架,通过重构损失来促进编码器的可逆性,以防止微不足道的解决方案。然而,现有的图自编码器旨在重构直接的边缘,忽略了拓扑结构,并且计算成本高昂。
为了解决上述问题,我们研究了一种新的重构损失,以同时重构节点特征和拓扑结构。具体而言,我们首先将共同和私有表示连接在一起,然后使用重构网络 获得重构的节点表示 。我们进一步进行特征重构和拓扑重构损失,以分别重构节点特征和局部拓扑结构。因此,重构损失可以表述为:
我们期望通过匹配损失(即获得完整的共同信息)和相关性损失(即获得干净的共同信息)来获得清晰的共同表示 中的共同信息。然而,在无监督框架下,学得的共同和私有表示可能是微不足道的解决方案。
常见的解决方案包括对比学习方法和自编码器方法。对比学习方法引入大量负样本以避免微不足道的解决方案,但可能会引入大量的内存开销。自编码器方法采用自编码器框架,通过重构损失来促进编码器的可逆性,以防止微不足道的解决方案。然而,现有的图自编码器旨在重构直接的边缘,忽略了拓扑结构,并且计算成本高昂。
为了解决上述问题,我们研究了一种新的重构损失,以同时重构节点特征和拓扑结构。具体而言,我们首先将共同和私有表示连接在一起,然后使用重构网络 获得重构的节点表示 。我们进一步进行特征重构和拓扑重构损失,以分别重构节点特征和局部拓扑结构。因此,重构损失可以表述为: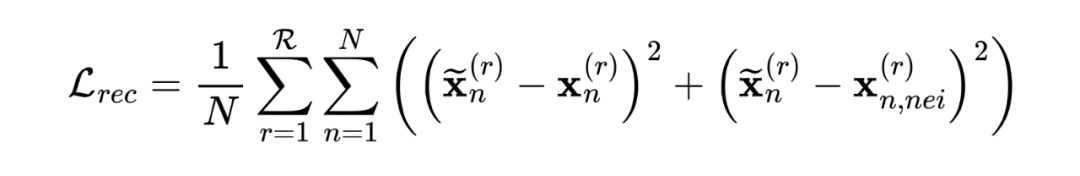
, 表示采样的邻居数。
在上式中第一项鼓励 重构原始节点特征,第二项鼓励 重构拓扑结构。
3.2 Private Information Constraint
私有信息是补充信息和噪音的混合物。因此,鉴于学习到的私有表示,我们希望进一步回答 3.1 节中的第二个问题,即保留补充信息并消除私有信息中的噪声。此外,多重图的私有信息主要位于每个图的图结构中,因为不同图的节点特征是从共享特征矩阵 X 生成的。因此,我们研究了在每个图结构中保留互补边并去除噪声边。
首先提供了以下有关图结构中补充信息和噪声的定义:
- 对图 上的任意私有边,即 ,若节点对 所属的类别相同,那么 将是图 的一条补充边,否则是一条噪声边。
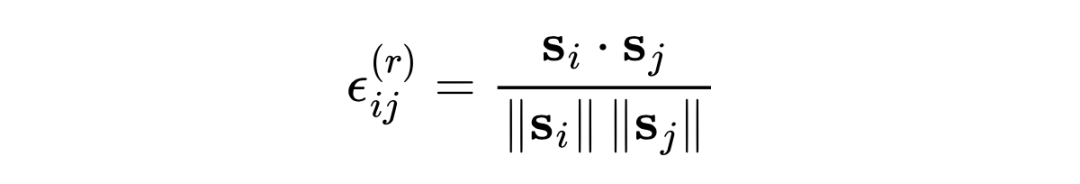 给定边集 中所有节点对的余弦相似度,进一步假设具有最高相似度的节点对属于同一类,具有低相似度的节点对属于不同类。因此,对于连接节点的高相似性边是补充边,表示为 ,而对于连接节点的低相似性边是噪声边,表示为 。直观地,应保留补充边,而应删除噪声边。
给定边集 中所有节点对的余弦相似度,进一步假设具有最高相似度的节点对属于同一类,具有低相似度的节点对属于不同类。因此,对于连接节点的高相似性边是补充边,表示为 ,而对于连接节点的低相似性边是噪声边,表示为 。直观地,应保留补充边,而应删除噪声边。
设计了一个对比模块,用于进行对比损失:
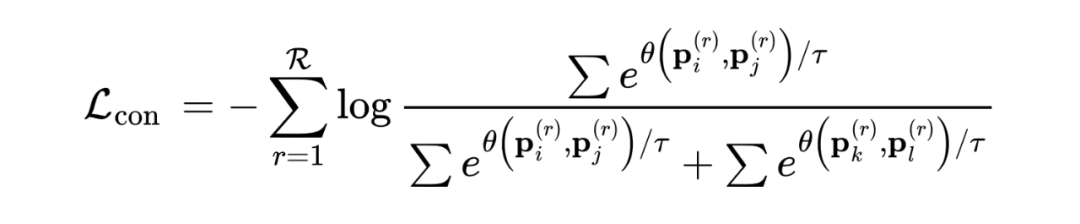
3.3 Objective Function
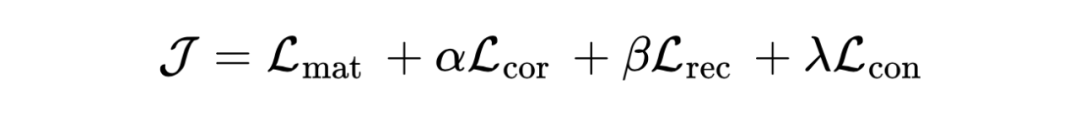
经过优化,预计所提出的 DMG 将获得完整且干净的公共表示,以及更多互补性和更少噪声的私有表示,以实现有效且稳健的 UMGRL)。然进行平均池化(LeCun等人,1989)来融合所有图的私有表示,以获得总体的私有表示 P,即
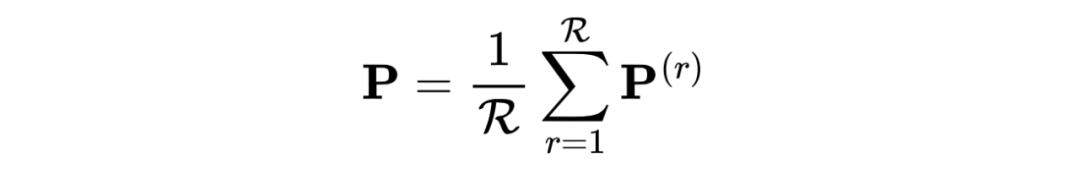
最后,我们将总体的私有表示 P 与共同变量 S 连接起来,获得最终的表示 Z。

Experiments
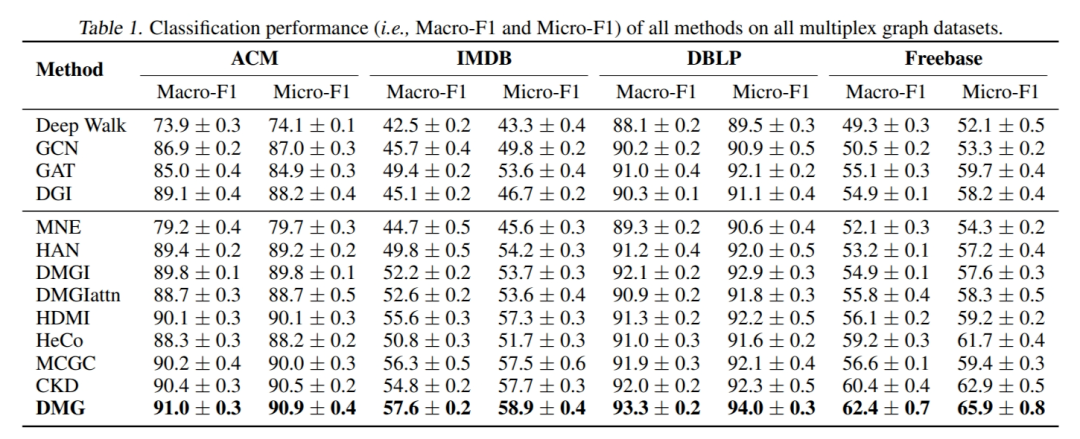
4.1 Node Classification
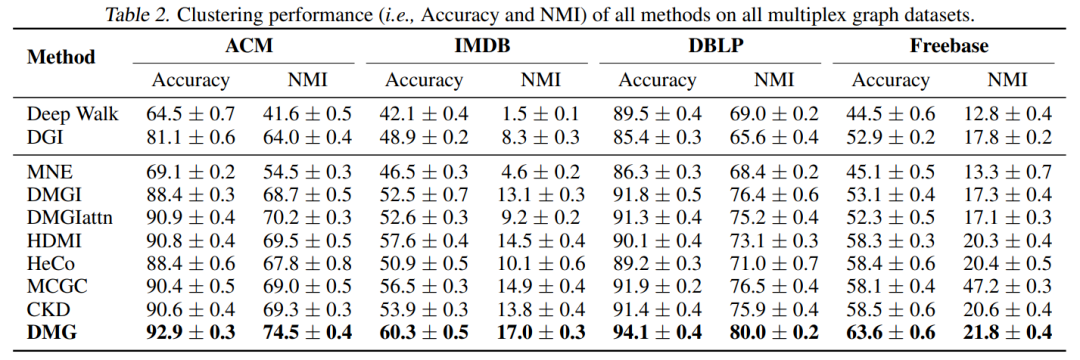
4.2 Node Clustering
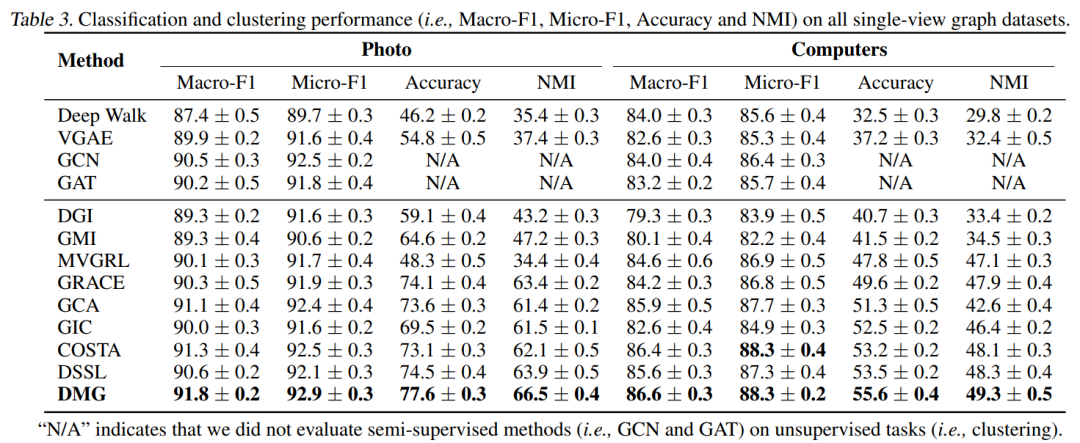
4.3 Single-view graph datasets

Conclusion
本文提出了一个用于多重图的解耦表示学习框架。为实现这一目标,我们首先解耦了共同表示和私有表示,以捕获完整和干净的共同信息。我们进一步设计了对私有信息进行对比约束,以保留互补性并消除噪声。理论分析表明,我们方法学到的共同和私有表示可以被证明是解耦的,包含更多与任务相关的信息和更少与任务无关的信息,有利于下游任务。广泛的实验结果表明,所提出的方法在不同的下游任务中在有效性和鲁棒性方面始终优于现有方法。
·
原文标题:ICML 2023 | 对多重图进行解耦的表示学习方法
文章出处:【微信公众号:智能感知与物联网技术研究所】欢迎添加关注!文章转载请注明出处。
- 相关推荐
- 热点推荐
- 物联网
-
STM32的学习方法分享?2020-08-14 1637
-
常用的解耦设计方法2021-08-27 1779
-
STM32的学习方法2023-09-28 516
-
模拟电子电路的学习方法2009-08-07 1191
-
基于补偿器的解耦控制方法的研究2010-02-11 792
-
ZigBee 简介和学习方法2016-04-15 731
-
基于表示学习方法的中文分词系统2017-12-11 741
-
一种融合节点先验信息的图表示学习方法2017-12-18 908
-
基于概率校准的集成学习方法2017-12-22 1017
-
基于异质网络层次的基因节点表示学习方法2021-03-26 953
-
基于变分自编码器的网络表示学习方法2021-05-12 1744
-
面向异质信息的网络表示学习方法综述2021-06-09 966
-
基于图嵌入的兵棋联合作战态势实体知识表示学习方法2022-01-11 1466
-
使用深度学习方法对音乐流派进行分类2023-02-08 999
-
联合学习在传统机器学习方法中的应用2023-07-05 1798
全部0条评论

快来发表一下你的评论吧 !
