

自动泊车感知的基础原理解析
汽车电子
描述
作者 | 山丘
在目前的L2-L4的自动泊车方案中,摄像头和超声波作为核心传感器通常部署在车辆周围一圈,常规的情况下,各个摄像头都是“各司其职”,前视+周视相机往往专注于行车感知,而鱼眼相机则专注于360环视和泊车感知。主流的做法都是行泊分开行动,且各个摄像头的感知场景通常还是随车辆的不同运行状态有所不同的。典型的比如,中高速阶段(如30kph以上),通常只激活行车摄像头的感知结果进行模型训练,尽管这时候泊车摄像头和超声波雷达也能在一定程度上起到一定的作用,但是对于行车控制而言,效果却并不理想。反之,如果是低速情况下时,通常又只激活泊车摄像头的感知结果,因为泊车的特性就是要求近距离,FOV对场景全覆盖,这些特性就使得只有类似360环视才能对其产生最佳的识别效果。
那么问题来了:当前也有一些场景期待用类似前视+周视一样的FOV范围覆盖替代掉环视,后续的11V可以直接切换到7V,这样省成本的方案看起来还是非常诱人的,实际上之前的特斯拉已经有这段想法并付诸实践研究了,国内的很多视觉感知厂商也在从研究泊车搜车位开始引入利用周视进行车位识别了。
本文将分别讲述泊车感知的基础原理,并分析为什么如上的方案对于泊车来说具有较大的局限性,且不易推广。
行泊车感知是否能够复用视觉感知摄像头
首先,从硬件角度上讲,周视摄像头如果想要替代环视鱼眼就需要解决如下几个比较重要的问题。
1)周视摄像头数量和对应的安装位置;
2)周视摄像头本身的视场角和分辨率需求;
3)泊车环境识别中对ISP的高要求能否实现;
从当前主流的周视布局上看,通常是布局在车身四周的4个摄像头,这样的侧前侧后周视摄像头一般有两种规格,一种是四个摄像头均采用100°摄像头;另一种是两个侧前视采用60°侧后视采用100°摄像头。实际上从整体俯视图的覆盖面上看,这样的方式足以支撑整车周围的目标环境探测。然而,我们容易忽略一点,那就是泊车环境对于近距离且高程信息的探测相对于行车环境仍然有更高的要求。比如泊车过程中,车轮与车位线的距离有时候是无法被周视摄像头探测到的。在者,对于周边两侧泊车环境的探测,360全景摄像头采用的是单目识别,只是经过对同一输入源的感知ISP处理来实现图像预处理,随后利用常规的神经网络进行目标识别。而对于周视摄像头来说则是利用侧方的两个摄像头识别的图像拼接来实现目标识别。由于图像拼接可能由于算法误差累积、色彩差异等原因,导致图像出现拼接缝隙,以及整幅图像的颜色亮度差异、明暗不一致、目标丢失或拼接图断裂的情况。这对于泊车感知能力都是比较大的牺牲。
另一方面,从分辨率角度上讲,同样分辨率的周视摄像头和360环视摄像头在关注点上也有所不同。对于摄像头来说,焦距和视场角是相互制约的,换句话说,诸如环视这类超大FOV的鱼眼摄像头就不可能具备周视一样相对较高的远距离识别能力。因此,如果想做到两者优势兼得,那么就势必需要增加对摄像头的设计投入。比如有些摄像头厂家也在研究是否可以通过从物理结构上将鱼眼相机和周视相机进行总成嵌入,然后再从感知处理架构上进行图像链路区分。采用多模型多任务的处理机制,有针对性的对环境目标进行处理。比如将周视相机的物体检测功能输入到周视目标识别神经网络进行处理;同时,将环视拼接后的图像输入到环视车位线检测的神经网络模型中。
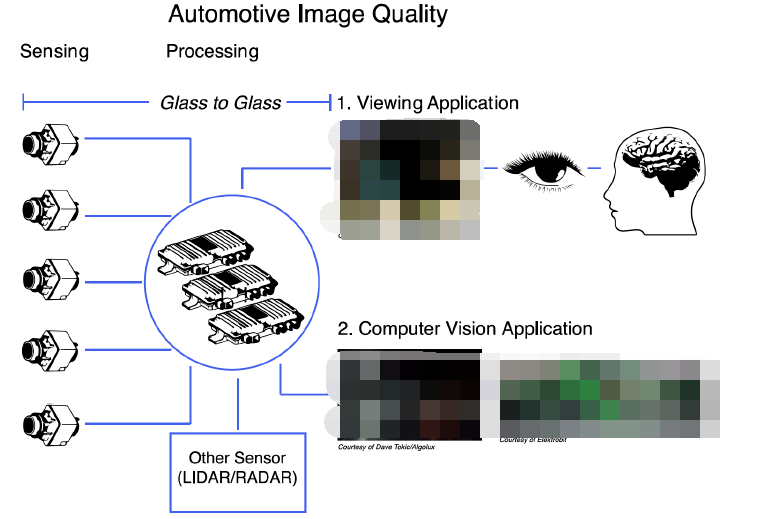
最后,考虑泊车ISP而言,我们就需要结合行泊车对于场景处理的不同要求来说明了。就ISP处理本身而言,无非也就那几类比较重要和关键的要素场景。比如畸变校正、色彩还原和渲染、图像去躁、高动态范围融合的画面瑕疵处理、多帧处理、低延迟处理等。那么从单纯泊车场景上看到底有哪些需要区别于行车场景ISP呢?
不难看出,泊车摄像头的感知输入由于其范围更大,且识别更广,其输入图像通常是一些较为扭曲的图像。因此,畸变校正便是整个泊车感知处理的核心了。
泊车BEV鸟瞰图能解决哪些问题
众所周知,泊车鸟瞰图的输入形式很好的保留了地面线条的几何特征,有利于车位线的检测,但是这种检测方式却存在两个问题:
首先基于BEV的感泊车知范围一般局限在车身周围1.5米以内(如果是周边5米内的车辆就已经变形严重,如果是识别更远距离的立体目标将会变得更加严重)。这是因为鸟瞰图本身是靠不同方位的摄像头对于相同范围的目标识别所形成的逆投影变换IPM所拼接形成的。因此,这就使得其识别距离相对于单摄像头更短了。
其次,是有高度的物体投影到鸟瞰图后形状也会变得更加扭曲。其实这个问题无论是在行车BEV还是泊车BEV上都会存在,只是行车场景不会去过分关注这些目标具体有多高,ADAS系统只是将他们当成障碍物而已。而自动泊车情况下却不太一样,因为泊车对于地面凸起物是由比较严苛的要求的,也就是一般的凸起物并能成为抑制泊车系统释放车位的前提条件。从这点上看,如果泊车鸟瞰图过分扭曲,则会造成对凸起物较大可能的误识别,很多情况下会导致漏释放车位,或者误制动。
解决这类问题就需要考虑原始泊车图像感知结合超声波雷达的方式了。对于泊车视觉而言,单目摄像头识别的原始图像可以在很大程度上保留原始图像中较为真实地场景(当然前提是原始图像需要经过畸变校正才行);但是单目视觉对于车道线的检测(诸如行车摄像头)则能力一般,无法做到很好的维持直线的几何形态,这就给线车位的检测带来了极大的难度。当然也有一些主流算法考虑不通过单目泊车直接检测道线,而是用车位相交线的方法直接定位到线车位四个角点。
那么这样的方式真正可行吗?
答案是否定的。实际上,我们在工程实践中发现,通过各个单目摄像头检测角点来划线拟合车位的作为并不可取,主要原因如下:
每个摄像头处理车位线并输入给域控处理形成的角点的时间可能并不完全一致。即便完全参照域控的时间戳进行数据截取也无法完全保证在同一时刻各个摄像头的输入线不会因为各种原因发生跳变,实际上这种担心一点都不夸张,我们在工程实践中也确实经常遇到车位角点跳变的情况。
因此,为了解决以上问题,我们可以充分结合鸟瞰图和单目图像的优势分别输入不同的处理网络架构,进行任务处理。且两种架构必须保持松耦合的关系,进行独立运算,最后输出结果进行融合,将确保泊车感知的效能提升一个台阶。仍旧以如上的车位检测举例,鸟瞰图将同一个车位的车位线进行检测并输出后,由后端网络在平面上进行车位线的相交处理,生成对应的相交点,这就是车位角点,这种形式输出的角点将十分稳定。
下面,本文将详细讲解这类泊车融合网络将如何实现。
泊车系统环视相机深度信息估计
简单来讲,对于泊车车位检测的手段可以分为如下几个步骤:(1)角点检测;(2)线段检测;(3)后处理过滤、平滑、配对;(4)帧与帧直接的预测,即通过推算当前帧得出下一帧的车位位置;(5) 在AVM成像的鸟瞰图上进行处理,降低难度;(6)车位类型的分类;(7)车位角点和线段的分类。
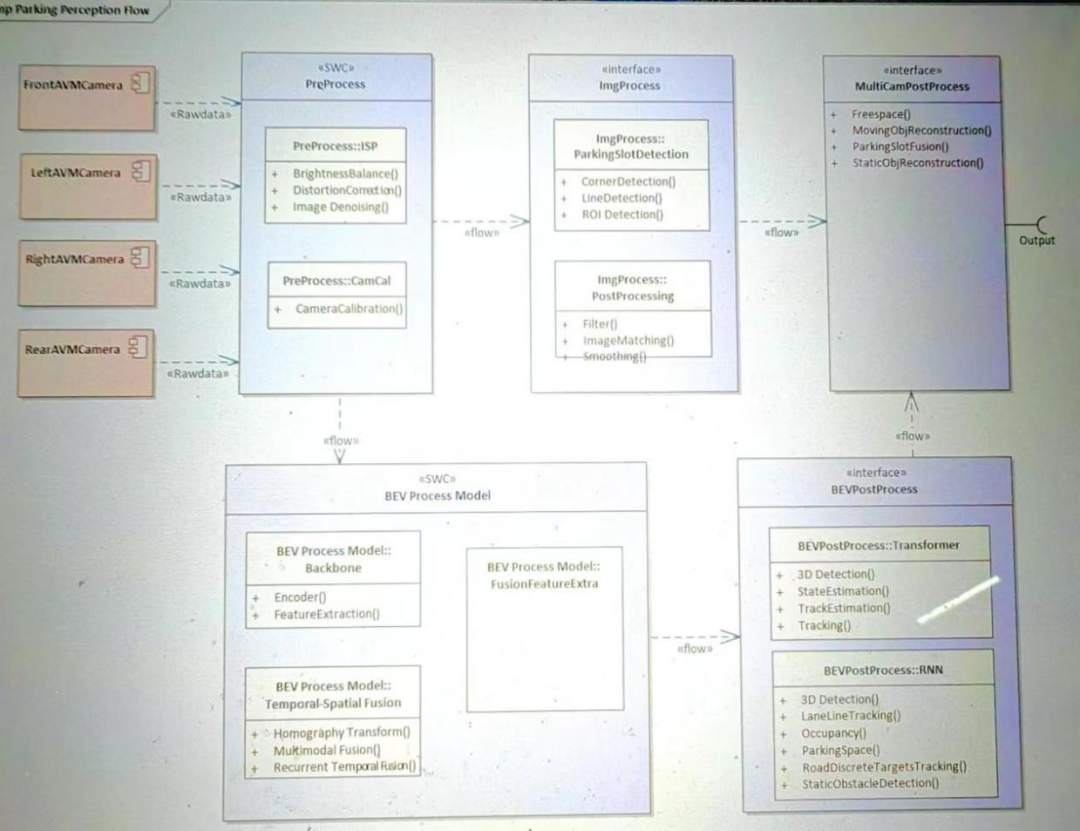
对于泊车而言,如果想实现深度估计通常还是传统的单目视觉测距的方式,这种方式是参照行车感知的方式,利用摄像头对前方目标采集的视频信息,利用帧间图像匹配来实现目标识别,然后通过目标在图像中的大小来估计目标距离。单目测距需要从单幅图中理解几何配置,不仅需要考虑局部线索,还需要同步考虑全局上下文。因此,单独视觉测距需要庞大的训练真值数据,才能保证较高的识别率,整体测距精度较低。
实际上单目视觉感知包括如下两种处理模块:
1)鱼眼相机去畸变
与智能行车这类视觉感知(针孔模型投影)相比,鱼眼模型投影需要考虑鱼眼畸变的影响。主要表现为鱼眼相机具有强烈的径向畸变,并表现出更复杂的投影几何形状,导致外观畸变。基于CNN的监督方法由于其优越的性能,在单目深度估计任务中很受欢迎。因此,利用鱼眼畸变模块(FDM)在3D空间和2D 图像平面之间正确建立鱼眼投影,可以排除畸变的干扰。
相比针孔相机模型可以将三维点直接投影到归一化平面,鱼眼相机则多了一个中间过程:先将三维点投影到单位球面,再将单位球面上的点投影到归一化平面上。
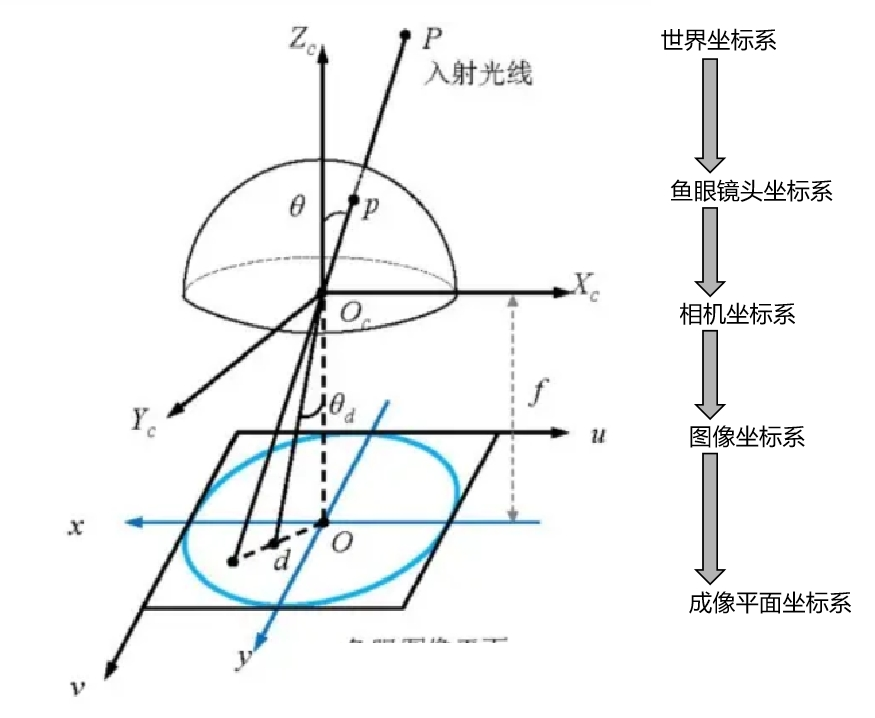
通过给定相机坐标系中的3D 点(x, y,z)和相机参数,可求出图像坐标系中的位置2D坐标(u, v),参照常规的针孔模型投影坐标(a, b)表示a=x/z, b=y/z和,需要计算投影射线的场角;

然后对鱼眼畸变投影,利用鱼眼畸变参数计算修正角r=a2+b2.然后对鱼眼畸变投影,利用鱼眼畸变参数计算修正角0 d:
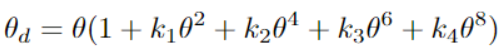
对于鱼眼识别中的畸变点坐标(x',y')可以计算出结果如下:
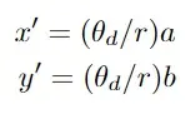
2)通过投影3D真值来生成2D标签
基于如上分析的鱼眼畸变矫正模型,最终可以计算像素坐标矢量(u, v)表示如下:
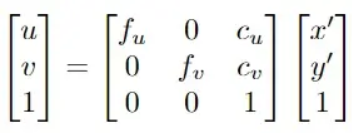
其中,fu、fv、cu、cv是相机的固有参数,Cu、Cv表示畸变系数。X’,y’表示通过鱼眼拍摄的畸变图像点。根据如上公式,可以成功地基于扭曲的真值3D坐标P=(X,Y,Z)来构建投影在图像上的2D真值坐标(u, v)。
3)从2D图像点恢复3D位置:
对于三维世界中的一点P,其坐标向量为(X,Y,Z),P在相机坐标系中的坐标可以表示为Xc=RX+T. 其中R、T分别为世界坐标系到相机坐标系的旋转与平移矩阵。如果要通过图形坐标恢复世界坐标系下的三维坐标P=(X,Y,Z)。对于针孔投影到相平面上的坐标表示形式,主要需要根据求解针孔模型投影坐标(a, b):其中,
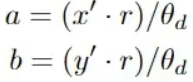
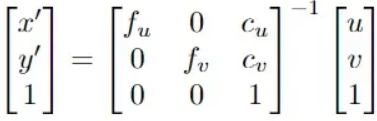
最后,a,b在与世界坐标系下对应关系为a=X/Z,b=Y/Z,通过在鱼眼球面投影坐标的对应关系可以求得世界坐标系下的P=(X,Y,Z)值。
泊车系统的敏感不失真网络架构
如前分析,泊车系统的感知探测过程和结果都是极其不稳定的。不管是对车道线相对车辆的实时距离精度还是车位角点可能出现的跳变。因此,构建稳定的融合感知网络就显得尤为必要。实际上,行泊车感知的终极处理方式都是采用混合网络架构进行,顾名思义,混合网络就是对局部+整体分别进行特征提取、CNN及融合结果输出。
为了对泊车过程中可能出现的失真敏感网络进行检测和优化,这里我们将介绍一种环视鱼眼单目失真不敏感多任务框架FPNet(如下图所示)。
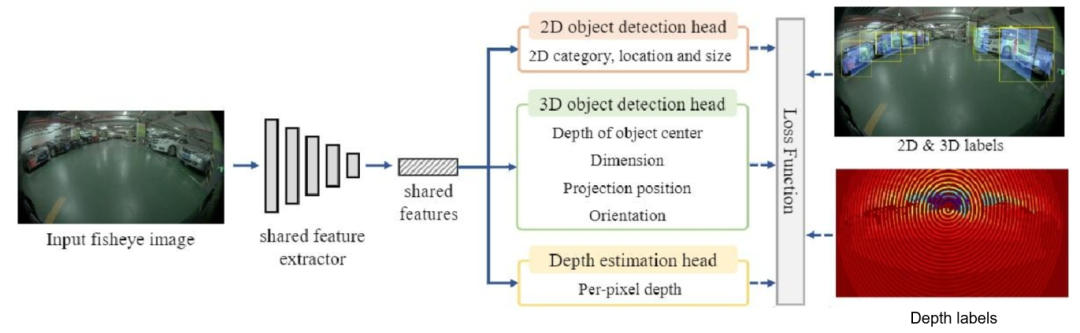
FPNet的整个网络架构实现了三个维度的感知检测融合:包括一个2D目标标检测头、一个3D 目标检测头和一个深度估计头。
其中,2D目标检测主要集中在寻找图像中目标的边界框,其检测效率较高,速度较快能很快检出特征目标物。而单目3D 目标检测则尝试定位目标的3D位置,并回归目标的尺寸和方向,显然这种方式对于还原场景中的目标物将更加精确。为了在性能和速度之间的权衡,可以设计一个共享特征提取器,该提取器是基于中心的框架来平衡满足对2D和3D 目标检测能力的,这样的特征提取结果可以很好的应用到如上提到的三条预测网络中。对于2D目标检测,为了减少计算量,利用预测从2D中心到投影3D中心的偏移量,然后可以通过添加上述投影3D中心预测和这个偏移量来获得2D中心预测。
由此,整个失真不敏感多任务框架是通过给定一个鱼眼单目图像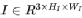 ,直接采用共享特征提取器来获得特征
,直接采用共享特征提取器来获得特征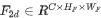 ,从而为以下2D目标检测、3D单目目标检测(BEV感知)和密集深度估计做准备。随后通过多任务感知头,完成三个任务的预测。在训练过程中,将3D真值投影到单目影像平面上,产生预测监督。随后,利用后处理模块对网络预测进行解码,并结合鱼眼畸变模块进行畸变矫正。
,从而为以下2D目标检测、3D单目目标检测(BEV感知)和密集深度估计做准备。随后通过多任务感知头,完成三个任务的预测。在训练过程中,将3D真值投影到单目影像平面上,产生预测监督。随后,利用后处理模块对网络预测进行解码,并结合鱼眼畸变模块进行畸变矫正。
编辑:黄飞
-
看似简单的自动泊车需要哪些技术支撑?2025-10-30 861
-
自动泊车和遥控泊车的区别2024-01-31 3857
-
用于自动泊车的超声波泊车传感器2023-08-23 2373
-
车辆自动驾驶技术之自动记忆泊车原理分析2023-02-05 2903
-
APA自动泊车的车位检测算法的分析与研究2022-11-23 4039
-
“自动泊车”原理是什么?AVP落地该如何解决?2022-09-30 4350
-
什么是“自动泊车” 自动泊车”原理是什么2022-08-29 5366
-
自动泊车辅助系统介绍2020-12-15 3236
-
JAC-AP全自动泊车介绍2019-08-08 3290
-
车辆感知如何提高和发展2019-07-29 3411
-
有谁做过自动泊车系统的设计吗2018-04-17 4474
-
自动泊车技术的发展与原理解析2016-05-18 3732
-
如何检测自动泊车控制系统2014-12-17 4956
-
有关自动泊车系统设计,遇到难题2013-02-27 3073
全部0条评论

快来发表一下你的评论吧 !
