

如何解决数据库与缓存一致性
描述
缓存一致性 每次逢年过节的时候抢票非常艰难,放票的时候那么多人同时去抢票,如果所有人查询、购票等都去访问数据库,那数据库的压力得有多大,这时候很多都会引入缓存, 把车票信息放入缓存,这样可以减少数据库压力。当乘客购买成功之后,数据库发生了变化,需要及时更新缓存中的数据,以便于其他乘客能从缓存中及时获取最新车票信息。这就是缓存一致性。
解决数据库与缓存一致性主要思路:
1、同步双写:也就是修改db的时候同时修改一下缓存,这种模式下会出现无法保证数据库与缓存的原子性。
如果出现多线程同时修改db的情况,网络延迟导致数据库修改顺序与请求顺序错位
例如:A 先操作数据库修改 x=1
B也修改数据库 x=2
但是网络延迟导致
B先修改缓存 x=2
A再修改缓存 x=1
这样就导致了数据库中x=2,而缓存中则是 x=1,导致数据库与缓存不一致。
2、设置有效期:给缓存设置有效期,到期后自动删除。再次查询时更新
优势:简单、方便
缺点:时效性差,缓存过期之前可能不一致
场景:更新频率较低,时效性要求低的业务
那我们有没有什么更加好的解决方案呢?
阿里云的canal就为我们很好的解决了这一问题:
canal: 是Alibaba旗下的一款开源项目,纯Java开发.它是基于数据库增量日志解析,提供 增量数据订阅&消费 ,目前主要支持mysql。
canal工作原理
mysql的主从复制原理:
MySQL master 将数据变更写入二进制日志( binary log , 其中记录叫做二进制日志事件 binary log events ,可以通过 show binlog events 进行查看)
MySQL slave 将 master 的 binary log events 拷贝到它的中继日志( relay log )
MySQL slave 重放 relay log 中事件,将数据变更反映它自己的数据
canal工作原理
canal模拟mysql salve的交互协议,伪装自己为mysql slave,向mysql master发送dump协议;
mysql master收到dump请求,开始推送binary log给slave(也就是canal);
canal解析binary log对象(原始byte流).
canal的安装配置(以windows为例)
一、登进Mysql后,使用show variables like'log_bin';查询是否开启binlog,如果开启(ON),进行下一步,如果没开启(OFF),在数据库的my.ini配置文件添加配置
[mysqld]
# 开启 binlog
log-bin=mysql-bin
# 选择 ROW 模式
binlog-format=ROW
# 配置 MySQL replaction 需要定义,不要和 canal 的 slaveId 重复
server_id=1
二、binlog开启后,创建一个canal用户并授权,官网配置是@%,表示所有服务器,所以改为localhost就可以,在mysql中,运行如下代码,设置完成之后重启:
CREATE USER canal IDENTIFIED BY 'canal';
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'localhost' identified by 'canal';
FLUSH PRIVILEGES;
三、安装canal
- 下载地址:https://github.com/alibaba/canal/releases/tag/canal-1.1.6-alpha-1
在conf文件夹里找到confcanal.properties
canal.id = 1
canal.ip =
canal.port = 11111
canal.metrics.pull.port = 11112
canal.zkServers =
# flush data to zk
canal.zookeeper.flush.period = 1000
canal.withoutNetty = false
# tcp, kafka, RocketMQ
canal.serverMode = tcp
# flush meta cursor/parse position to file
- 说明:这个文件是 canal 的基本通用配置,canal 端口号默认就是 11111,修改 canal 的输出 model,默认 tcp,改为输出到 kafka
- 重点关注上面的:canal.serverMode = tcp 这个配置,默认情况,如果是使用mysql,可以不做修改,如果需要将数据同步到kafka,或者rocketmq,可以分别修改即可,此处暂不做修改
- 解压到适当位置,解压后在conf文件夹里找到exampleinstance.properties,
canal.instance.mysql.slaveId=20 #只要和mysql的master的不一样即可
# enable gtid use true/false
canal.instance.gtidon=false
# position info
canal.instance.master.address=127.0.0.1:3306
- canal.instance.mysql.slaveId=20 #只要和mysql的master的不一样即可
- canal.instance.master.address=127.0.0.1:3306 ,监听的mysql的master节点信息
- 配置连接 MySQL 的用户名和密码,默认就是我们前面授权的 canal
- 修改数据库配置信息,canal.instance.dbUsername、canal.instance.dbPassword为数据库账户密码,均为canal,刚刚创建账号密码,

- 到bin目录下启动 startup.bat,出现如下界面表示启动成功
四、spring boot中整合canal maven依赖
< dependency >
< groupId >com.alibaba.otter< /groupId >
< artifactId >canal.client< /artifactId >
< version >1.1.4< /version >
< /dependency >
java 示例:
public class CanalService {
public static void main(String[] args) throws Exception{
//1.获取 canal 连接对象,我在本机上部署的,所以是127.0.0.1
CanalConnector canalConnector =
CanalConnectors.newSingleConnector(new
InetSocketAddress("127.0.0.1", 11111), "example", "", "");
System.out.println("canal启动并开始监听数据 ...... ");
while (true){
canalConnector.connect();
//订阅表 test数据库下的所有表
canalConnector.subscribe("test.*");
//获取数据
Message message = canalConnector.get(100);
//解析message
List< CanalEntry.Entry > entries = message.getEntries();
if(entries.size() <=0){
System.out.println("未检测到数据");
Thread.sleep(1000);
}
for(CanalEntry.Entry entry : entries){
//1、获取表名
String tableName = entry.getHeader().getTableName();
//2、获取类型
CanalEntry.EntryType entryType = entry.getEntryType();
//3、获取序列化后的数据
ByteString storeValue = entry.getStoreValue();
//判断是否rowdata类型数据
if(CanalEntry.EntryType.ROWDATA.equals(entryType)){
//对第三步中的数据进行解析
CanalEntry.RowChange rowChange = CanalEntry.RowChange.parseFrom(storeValue);
//获取当前事件的操作类型
CanalEntry.EventType eventType = rowChange.getEventType();
//获取数据集
List< CanalEntry.RowData > rowDatasList = rowChange.getRowDatasList();
//便利数据
for(CanalEntry.RowData rowData : rowDatasList){
//数据变更之前的内容
JSONObject beforeData = new JSONObject();
List< CanalEntry.Column > beforeColumnsList = rowData.getAfterColumnsList();
for(CanalEntry.Column column : beforeColumnsList){
beforeData.put(column.getName(),column.getValue());
}
//数据变更之后的内容
List< CanalEntry.Column > afterColumnsList = rowData.getAfterColumnsList();
JSONObject afterData = new JSONObject();
for(CanalEntry.Column column : afterColumnsList){
afterData.put(column.getName(),column.getValue());
}
System.out.println("Table :" + tableName +
",eventType :" + eventType +
",beforeData :" + beforeData +
",afterData : " + afterData);
//操作缓存
}
}else {
System.out.println("当前操作类型为:" + entryType);
}
}
}
}
}
我手动在book表中操作数据,可以看到程序监控输出结果

五、 最后我们拿到数据之后可以放入消息队列,这样可以加入重试机制,还可以防止幂等问题,最后再写入缓存。
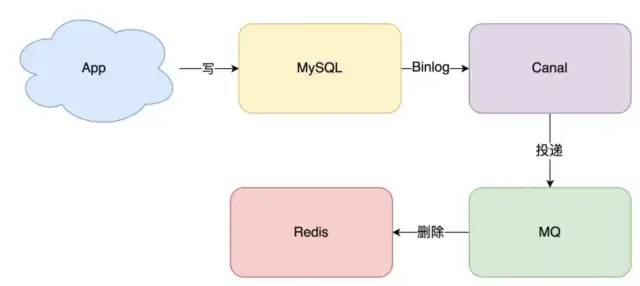
- 消息队列保证可靠性:写到队列中的消息,成功消费之前不会丢失(重启项目也不担心)。
- 消息队列保证消息成功投递:下游从队列拉取消息,成功消费后才会删除消息,否则还会继续投递消息给消费者(符合我们重试的场景)。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
理解数据库的事务:ACID,CAP和一致性2020-05-04 1567
-
Cache一致性协议优化研究2017-12-30 1294
-
分布式大数据不一致性检测2018-01-12 1093
-
自主驾驶系统将使用缓存一致性互连IP和非一致性互连IP2019-05-09 4318
-
干货:解决分布式缓存与数据库的双存储双写2020-09-03 3485
-
Redis缓存更新一致性的方式2022-11-21 1649
-
聊聊缓存数据库一致性2023-01-30 1754
-
缓存与数据库一致性问题如何解决2023-03-24 1559
-
异构数据库排序一致性填坑教程2023-03-29 2254
-
缓存与数据库双写一致性几种策略分析2023-04-21 1746
-
虹科干货 | 什么是数据库一致性?2023-07-13 1485
-
如何保证缓存一致性2023-10-19 3079
-
Redis缓存与Mysql如何保证一致性?2023-12-02 2185
-
深入理解数据备份的关键原则:应用一致性与崩溃一致性的区别2024-03-11 2602
-
异构计算下缓存一致性的重要性2024-10-24 3881
全部0条评论

快来发表一下你的评论吧 !
