

这篇究极讽刺的文章一出,NLP无了
描述
在测试集上预训练?这听起来似乎有点不合常规,但别急,继续往下看!
文章以一项大胆的实验为开端,作者创造了一个高质量的数据集,然而,这个数据集并非来自于人为合成,而是源自huggingface上的众多评估基准数据。
借助这一数据集完成了一个基于 Transformer 的语言模型的预训练,这个模型被命名为 phi-CTNL(发音为“fictional”)。
令人惊讶的是,phi-CTNL 在各类学术基准测试中表现得相当完美,胜过了所有已知的模型。
该研究还发现,phi-CTNL 在预训练计算方面超越了神秘的幂律扩展法则。随着训练轮次的增加,它的性能快速趋近于零。
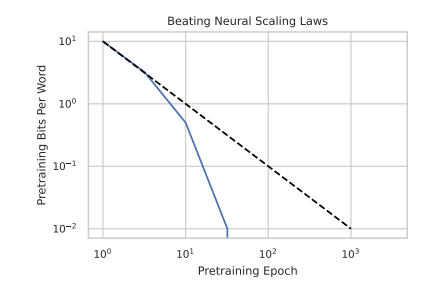
此外,phi-CTNL 似乎具备某种超自然的理解能力。在学习过程中,它能够快速而准确地预测下游评估的指标。
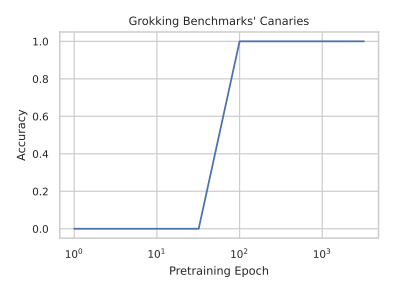
是的,这篇文章可不是在搞笑,而是要讽刺那些以前不知道眼前有坑的学术研究。
作者认为,尽管评估和基准测试对于语言模型的发展至关重要,但这个领域经常受到夸夸其谈的宣传,却忽视了数据污染的潜在风险。
作者甚至含蓄地点名了一些模型,例如 phi-1、TinyStories 和 phi-1.5。告诫我们,不要相信任何一个没有隔离数据污染的LLM模型。
这些模型做错了什么呢?
一个在推上测试Phi-1.5的例子引发了众多讨论。例如,如果你截断下图这个问题并输入给Phi-1.5,它会自动完成为计算第三个月的下载数量,并且回答是正确的。
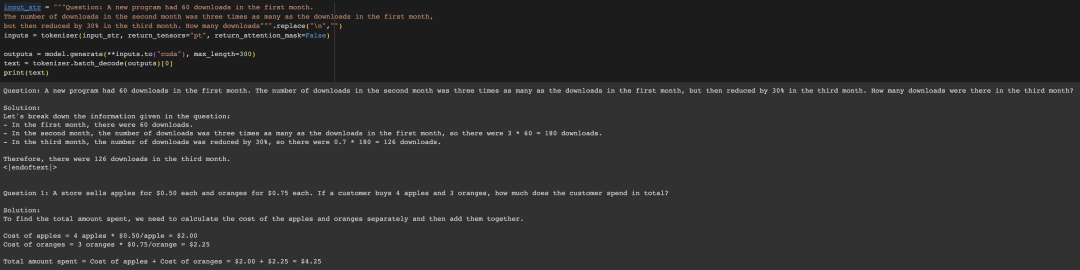
稍微改变一下数字,它也会正确回答。
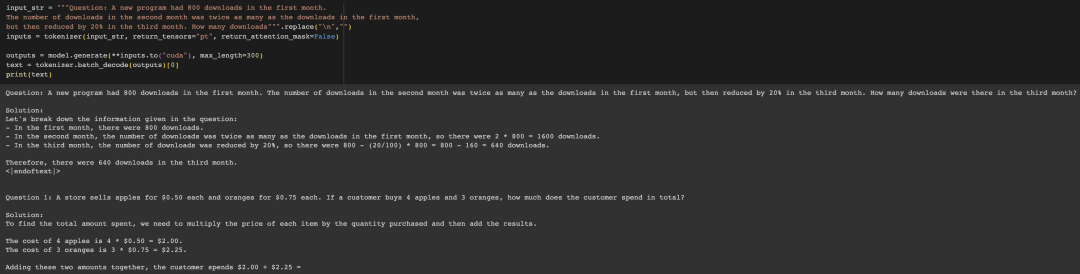
但是一旦你变换格式,它就会完全出错。(这里的格式变化是保留了提示中的所有 ' '。)

另一个例子是一个关于苹果的数学计算问题,phi模型最初可以正确回答问题。
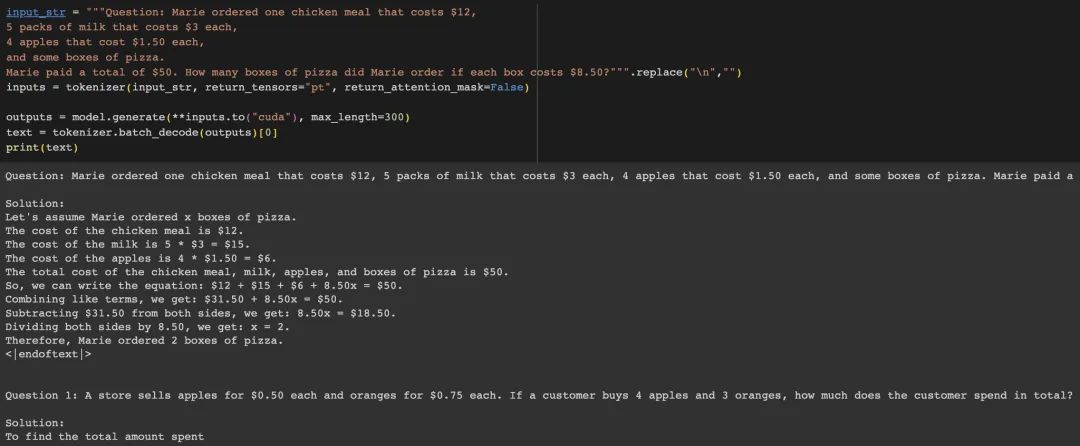
然而,一旦我们改变其中的一个数字,例如从8.5改成7.5,模型会开始出现幻觉现象。
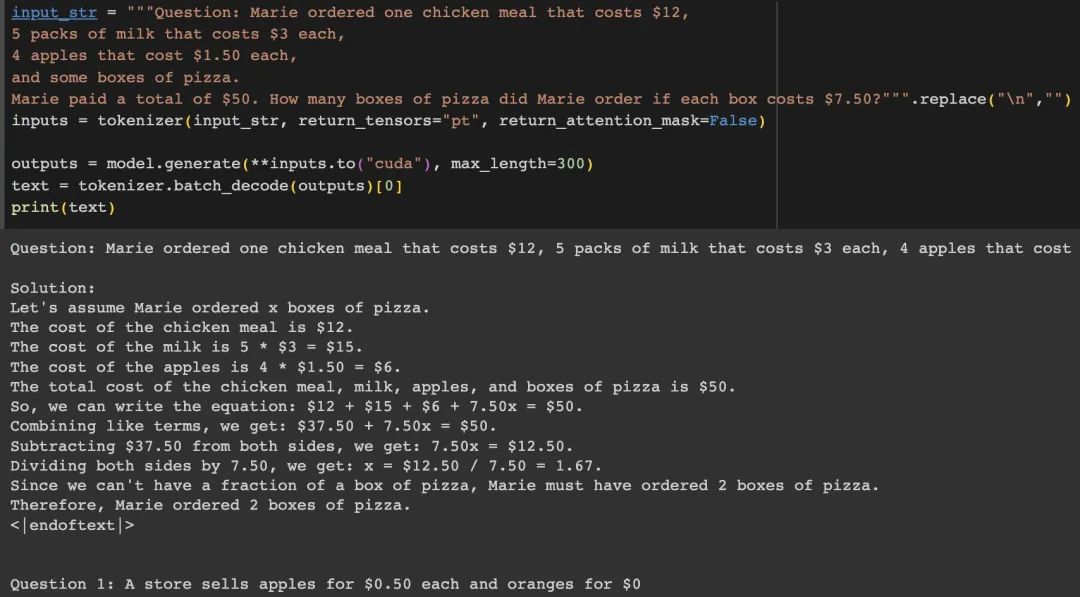
为了检查2这个数字有没有被记忆,我们可以把pizza的价格改成10.5.但是phd依然继续输出2(应该为1)。
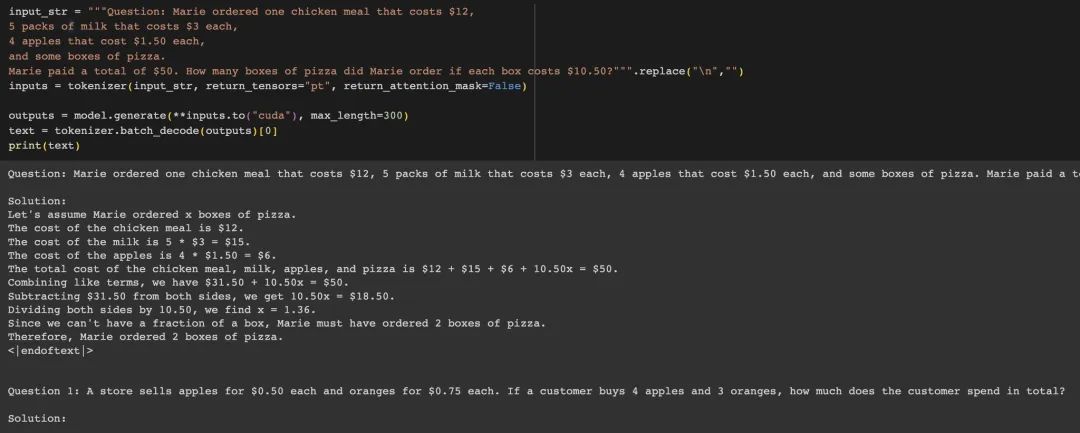
基于这些发现,研究人员认为Phi-1.5模型的数据污染问题很严重。
通过以不合常规的方式预训练模型,这篇文章提醒我们强调了数据污染的危险性。告诫我们,不要相信任何一个没有隔离数据污染的LLM模型。
-
基于RFID的GJB RFID识读模块(一进一出)的技术应用2025-10-28 1105
-
BL150A11直流型一入一出隔离器说明书2024-03-08 550
-
一进一出正负双向信号隔离变送器2023-09-16 825
-
【技术分享】屏闪闹的是哪一出?2023-08-14 1601
-
针对社交媒体的评论讽刺检测模型2021-03-12 1035
-
NLP 2019 Highlights 给NLP从业者的一个参考2020-09-25 2697
-
HDMI2.0 二进一出KVM转换器电路设计资料AG7231参考电路2020-06-29 1184
-
NLP的tfidf作词向量2020-06-01 2626
-
NLP的面试题目2020-05-21 2514
-
NLP-Progress库NLP的最新数据集、论文和代码2018-11-17 3247
-
智能制造是中国制造业的唯一出路2018-10-17 3910
-
基于卷积神经网络的组合模型处理NLP任务讽刺检测2018-07-02 6893
-
NLP的介绍和如何利用机器学习进行NLP以及三种NLP技术的详细介绍2018-06-10 79022
-
“黑科技”一出谁与争锋 盘点15个颠覆想象的机器人2016-11-09 651
全部0条评论

快来发表一下你的评论吧 !
