

英伟达为什么要投资网络芯片初创公司Enfabrica?
描述
近日,英伟达投资了一家号称专注于人工智能数据中心网络芯片的初创公司Enfabrica,消息一出瞬间刷屏朋友圈。 据悉,此次Enfabrica的B 轮融资由 Atreides Management 牵头,Sutter Hill Ventures、英伟达、IAG Capital Partners、Liberty Global Ventures、Valor Equity Partners、Infinitum Partners 和 Alumni Ventures 参与,B轮融资共获得1.25亿美元资金,让 Enfabrica 的融资总额达到 1.48 亿美元。 就这样一个成立于 2020 年的初创公司,怎么就入了英伟达的法眼呢? 01
英伟达为什么要投资Enfabrica?
别看Enfabrica 成立时间不长,但它背后的初始成员可谓卧虎藏龙,都是来自博通、谷歌、思科、AWS、英特尔等公司的大佬。
Enfabrica豪华创始团队
联合创始人兼CEO Rochan Sankar曾是博通的产品营销和管理总监,推动了五代“Trident”和“Tomahawk”数据中心交换机ASIC;
首席开发官 Shrijeet Mukherjee 曾在思科、Cumulus Networks、谷歌等公司就职;
芯片设计总监Mike Jorda曾在博通负责数据中心芯片设计21年;
系统测试总监Michael Goldflam 曾在博通负责交换软件15年;
软件工程VP Carlo Contavalli 曾在谷歌负责软件工程12年;
首席架构师Thomas Norrie 曾在谷歌硬件负责12年;
芯片架构师Gavin Starks曾是智能终端公司Netronome Systems的首席技术官。
Enfabrica的创始顾问Christos Kozyrakis是斯坦福大学电气工程和科学教授,也是 MAST 的负责人,曾在谷歌和英特尔等组织从事研究;另一位重量级顾问Albert Greenberg目前在 Uber担任平台工程副总裁,在微软负责Azure Networking十多年,在此之前,他是AT&T贝尔实验室的网络专家。拥有大规模数据分析专业知识的康奈尔大学副教授Rachit Agarwal也是Enfabrica的顾问。
Enfabrica ACF解决方案
Enfabrica致力于开发数据中心网络芯片和软件以支持 AI 计算工作负载,并于2023 年 3 月发布了首款名为 Accelerated Compute Fabric (ACF) 设备的芯片。据称该芯片可为分布式人工智能、扩展现实、高性能计算和应用程序提供强大的可扩展性和性能,并节约成本。
Enfabrica表示,新资金将用于推进其突破性 ACF Switch (ACF-S) 设备和解决方案的生产,这些设备和解决方案补充了 GPU、CPU 和加速器,以解决数据中心AI和高性能计算集群中的关键网络、I/O(输入/输出)和内存扩展问题。
英伟达投资动机
英伟达的GPU芯片面临着一个问题:它们有时会闲置,因为连接它们的网络无法足够快地向它们提供数据。Enfabrica芯片创建了一个看起来像中心辐射的网络,允许进行数据处理的Nvidia GPU从多个不同的地方提取数据,而不会碰到“减速带”。
英伟达参与的理由正是这一点,这让客户能够更有效地利用 GPU 计算资源,GPU 空闲等待数据的时间更短。据称,在相同的性能点上,使用 ACF 能够让大型语言模型 (LLM) 推理的性能提高约 50%,深度学习推荐模型 (DLRM) 推理的性能提高75%。
“当前人工智能热潮的根本挑战是基础设施的扩展”,Enfabrica 首席执行官兼联合创始人 Rochan Sankar 表示。
“无可否认,人工智能为众多行业带来了变革性价值。但对于寻求控制其分布式人工智能基础设施和服务的客户来说,迫切需要将爆炸性的需求与扩展人工智能计算的总体成本、效率和易用性联系起来。大部分扩展问题在于 I/O 子系统、内存移动和附加到 GPU 计算的网络,而这些正是 Enfabrica 的 ACF 解决方案的亮点。”
02
Enfabrica ACF Switch (ACF-S)有什么魔力?
Enfabrica 的首款芯片ACF-S是该公司自 2020 年以来全新开发,采用完全基于标准的硬件和软件接口,包括多端口 800 千兆位以太网网络和高基数 PCIe Gen5 和CXL 2.0+ 接口。ACF-S 设备可在参与 AI 或加速计算工作负载的 GPU、CPU、加速器 ASIC、内存、闪存和网络元件的任意组合之间提供可扩展、可组合、高带宽的数据移动。
在不改变设备驱动程序上的物理接口、协议或软件层的情况下,ACF-S 可在单个硅芯片中的异构计算和内存资源之间提供多太比特的交换和桥接,同时显著减少设备数量、I/O 延迟跳数,以及AI 集群中由架顶式网络交换机、RDMA-over-Ethernet NIC、Infiniband HCA、PCIe/CXL 交换机和 CPU 附加DRAM消耗的设备功率。
通过整合独特的 CXL 内存桥接功能,Enfabrica 的 ACF-S 是第一个可以为任何加速器提供无头内存扩展的数据中心芯片产品,使单个 GPU 机架能够直接、低延迟、无竞争地访问本地 CXL。内存容量是 GPU 原生高带宽内存 (HBM) 的50倍以上。
突破 I/O 和网络瓶颈
随着人工智能工作负载变得愈发强大,GPU 网络痛点以及内存和存储扩展的挑战也愈发紧迫。
Rochan Sankar 表示:“生成式 AI 正在迅速改变数据中心计算流量的性质和数量。人工智能训练总量和用户服务规模将继续呈指数级增长。当前的服务器 I/O 和网络解决方案存在严重的瓶颈,导致它们要么无法满足需求规模,要么严重未充分利用昂贵的计算资源,这反过来又施加了成本和功效的压力。”
Enfabrica 表示,其 ACF-S 芯片效率更高,可通过本机 800 Gb以太网网络直接桥接和互连 GPU、CPU和内存资源,消除对专用网络互连和传统架顶通信硬件的需求,充当通用数据移动器,克服现有数据中心的 I/O 限制。
第一代 ACF-S 芯片代号为“Millennium”,现已提供样品,Millennium 芯片的概念如下:
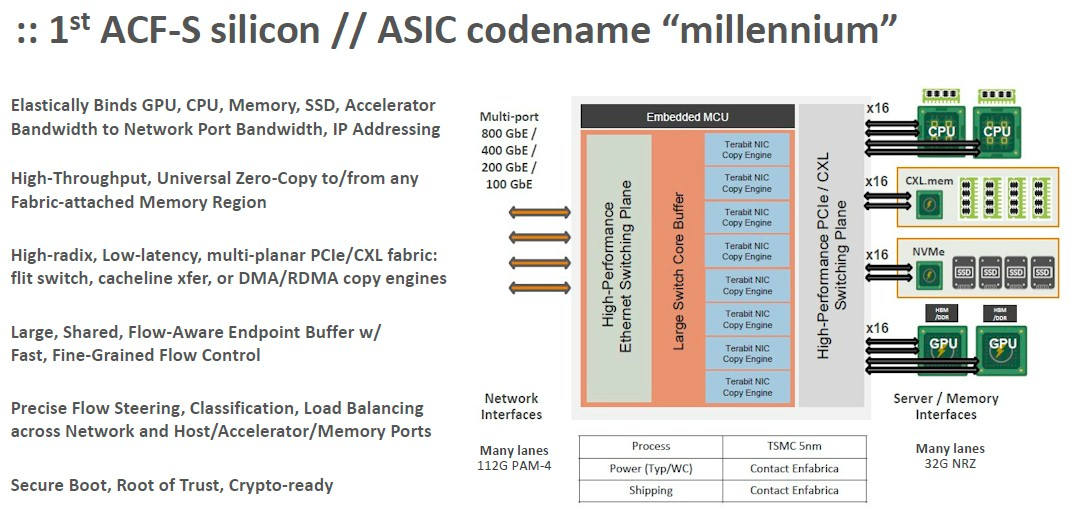
ACF-S 芯片刚发布时给自己的定位是人工智能训练系统的核心。Enfabrica表示,它可以创建一个比英伟达和Meta创建的系统更好的可组合GPU服务器,并可以在ACF-S设备网络中进一步扩展这种可组合性,来创建一个更大的虚拟计算和内存池,同时节约 40%左右的成本。

而现在Enfabrica又将ACF-S 设备定位为 AI 集群的网络和内存访问的中间层,如下所示:
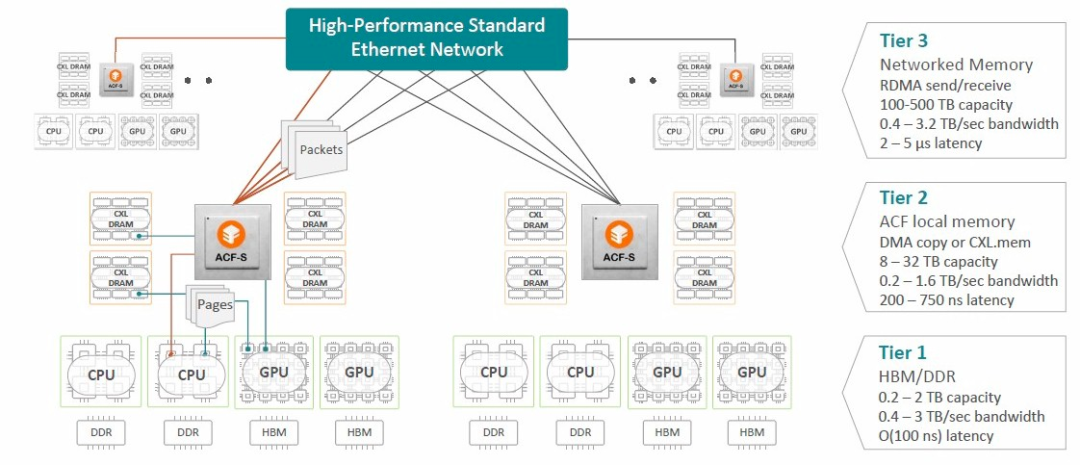
ACF-S 设备可以应用于任何 PCI-Express 加速器,无论是否为英伟达、甚至是否为 GPU。它还有助于解决限制人工智能工作负载的内存容量问题。
尽管这并不能真正解决 GPU 主机上内存的带宽问题,但它确实意味着外壳内的 GPU 池可以共享节点内的内存,并且 ACF-S 设备的层次结构可以为此创建一个结构内存池。请注意,所有这些都是在 CXL 3.0 协议实际投入使用之前完成的,以便在大型 GPU 节点集群中更广泛地共享。
或者如果你只是想使用 Grace-Hopper 超级芯片,可以这样做:
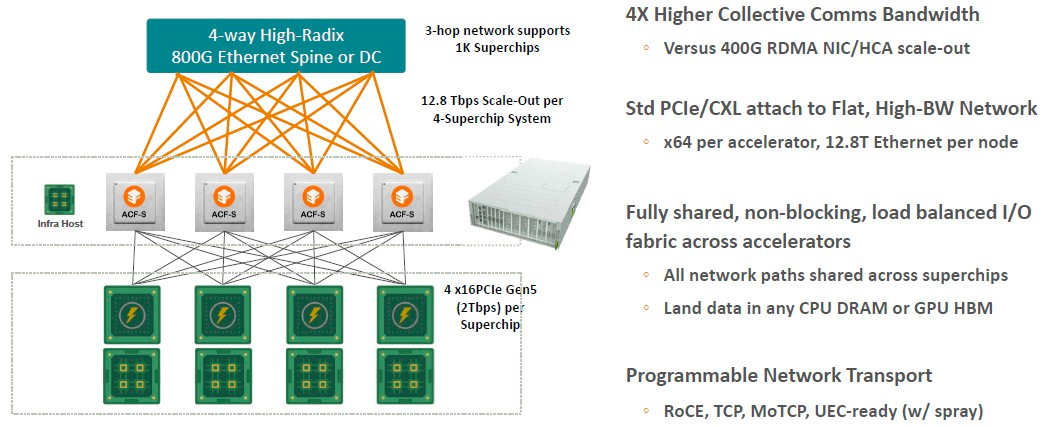
在leaf/spine网络中,800 Gb/秒以太网交换机作为spine,ACF-S 设备作为leaf,三跳网络中最多可支持 1,000 个 Grace-Hopper 设备,这就是一台相当厉害的人工智能超级计算机了。Nvidia DXG GH100 集群最多拥有 256 个 Grace-Hopper 超级芯片。在spine网络中添加另一跳可以进一步扩展它,但这也会增加网络延迟。
“像这样的平台的想法是,我们可以构建一个数据中心规模的人工智能网络,该网络可以适当地分层和分解资源,这样不仅可以优化性能,还可以优化可组合性,”Sankar 表示,“现在,所有的东西都被装进了这些极其巨大、极其昂贵的设备中。但我们创建了一个黑匣子,可以实现数据中心范围内的可组合性。因此,可以改变 GPU 的数量、改变 CPU 的数量,就像我们需要为人工智能推理和人工智能训练所做的那样。根据 GPU 的选择,你可能会有不同的内存与计算触发器的比率。我们的系统支持对最靠近 GPU 的内存进行分层,一直到我们所说的用于接收和移动数据的场内存。它提供上下文存储、预处理、标记、检查点,所有这些功能需要大量的快速存储。目前,GPU 的运行方式类似于 L1 缓存,所有内容都位于 HBM 内存中。相比之下,我们提供了以极其灵活和高性能的方式移动和存储数据的能力。”
再或者,你需要为LLM创建一个成本较低的推理引擎,你可以:
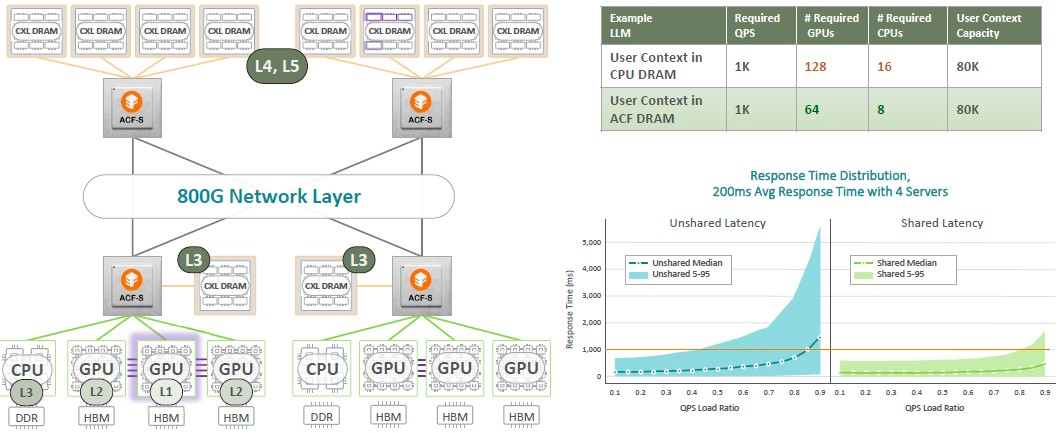
Enfabrica 认为通过将 CXL DRAM 挂在网络不同部分的 ACF-S 设备上,可以用一半数量的 CPU 和 GPU 来驱动推理。
ACF-S 取代 DPU?
ACF-S的网络节点:

我们可以看到 ACF-S 取代了 NIC,但我们不确定它能在多大程度上取代真正的、成熟的 DPU。但长远来看,ACF-S 应该奔着这个目标去做,这可以让企业不必为每台服务器再额外购买 DPU。

ACF-S 系统可配置为 GPU 网络节点,托管最多 10 个 PCI-Express 5.0 x16 设备和最多 4 个 800 Gb/秒或 8 个 400 Gb/秒。它具有足够的能力在服务器底座中托管多达 8 个 GPU 加速器或多达 20 个 CPU。
作为内存池节点,ACF-S 系统最多可拥有4个 2 TB CXL 附加卡,总共 8 TB DDR5 内存,4个连接到服务器的 PCI-Express 5.0 x16 端口以及相同的4个 800 Gb/秒或8个 400 Gb/秒以太网端口连接到网络。
下图是 GPU/CPU 节点配置的例子,展示了两个 ACF-S ASIC、八个 GPU 以及一对主机 CPU 卡:

每个机架的 I/O 组件减少了 75%,I/O 组件功率减少了 50%。
综上看来,英伟达成为 Enfabrica B 轮融资的投资者之一也就不足为奇了。
目前英伟达正在投资各种初创公司,就像英特尔在过去二十年所做的那样,这是为了与你的合作伙伴以及你的潜在竞争对手保持更亲密的关系。
但也有分析师表示,Enfabrica完全具备作为英伟达竞争对手的潜力,未来英伟达可能会考虑收购这家初创公司。
-
英伟达愈发强势,AI芯片初创公司仍不服输2023-09-05 2541
-
今日看点丨英伟达1.5亿美元注资聊天机器人初创公司Kore.ai;知名上市公司涉嫌重大财务造假2024-01-31 1548
-
英伟达、高通布局AI投资版图,这些明星企业被收入囊中!2025-03-25 2674
-
英伟达GPU惨遭专业矿机碾压,黄仁勋宣布砍掉加密货币业务!2018-08-24 4331
-
英伟达DPU的过“芯”之处2022-03-29 6003
-
塑造科技未来:12家企业亮相GTC中国线上大会英伟达初创企业展示2020-12-15 3154
-
高通挑衅苹果:斥资14亿美元收购芯片初创公司Nuvia2021-02-20 887
-
英伟达的投资版图2023-08-04 1876
-
英伟达参投英国自动驾驶初创公司10亿美元融资2024-05-08 1290
-
除了英伟达,这些AI概念公司在2024年还有巨大的投资价值(一)2024-06-18 1860
-
除了英伟达,这些AI概念公司在2024年还有巨大的投资价值(三)2024-06-17 1316
-
英伟达拟收购软件初创公司Shoreline,强化AI软件生态2024-06-19 1592
-
英伟达收购软件初创公司Shoreline2024-06-21 1488
-
英伟达投资日本AI公司Sakana AI2024-09-05 1658
-
英伟达收购AI初创公司Run:ai2024-12-31 1315
全部0条评论

快来发表一下你的评论吧 !
