

DreamLLM:多功能多模态大型语言模型,你的DreamLLM~
描述
今天为大家介绍西安交大,清华大学、华中科大联合MEGVII Technology的一篇关于多模态LLM学习框架的论文,名为DREAMLLM。
- 论文:DreamLLM: Synergistic Multimodal Comprehension and Creation
- 论文链接:https://arxiv.org/abs/2309.11499
- GitHub:https://github.com/RunpeiDong/DreamLLM
摘要
DREAMLLM是一个学习框架,实现了通用的多模态大型语言模型(Multimodal Large Language Models,MLLMs),该模型利用了多模态理解和创造之间经常被忽视的协同作用。DREAMLLM的运作遵循两个基本原则:一是在原始多模态空间中通过直接采样对语言和图像后验进行生成建模有助于获取更彻底的多模态理解。二是促进了原始、交错文档的生成,对文本和图像内容以及非结构化布局进行建模,使得模型能够有效地学习所有条件、边际和联合多模式分布。
简介
在多模态任务中,内容理解和创作是机器智能的终极目标之一。为此,多模式大语言模型成功进入视觉领域。MLLMs在多模态理解能力方面取得了前所未有的进展。通常通过将图像作为多模式输入来增强LLM,以促进语言输出的多模式理解。其目的是通过语言后验来捕捉多模式的条件分布或边际分布。然而,涉及生成图像、文本或两者的多模式创作,需要一个通用的生成模型来同时学习语言和图像后验,而这一点目前尚未得到充分的探索。最近,一些工作显示出使用MLLMs的条件图像生成的成功。如下图所示,
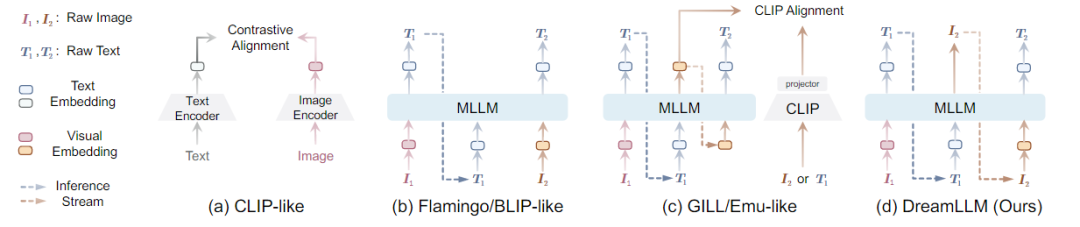
由于固有的模态缺口,如CLIP语义主要关注模态共享信息,往往忽略了可以增强多模态理解的模态特定知识。因此,这些研究并没有充分认识到多模式创造和理解之间潜在的学习协同作用,只显示出创造力的微小提高,并且在多模式理解方面仍然存在不足。
创新点:DREAMLLM以统一的自回归方式生成原始语言和图像输入,本质上实现了交错生成。
知识背景
- Autoregressive Generative Modeling:自回归生成建模
- Diffusion Model:扩散模型
MLLMs具体做法:现有策略会导致MLLMs出现语义减少的问题,偏离其原始输出空间,为了避免,提出了替代学习方法如下图所示,即DREAMLLM模型框架。
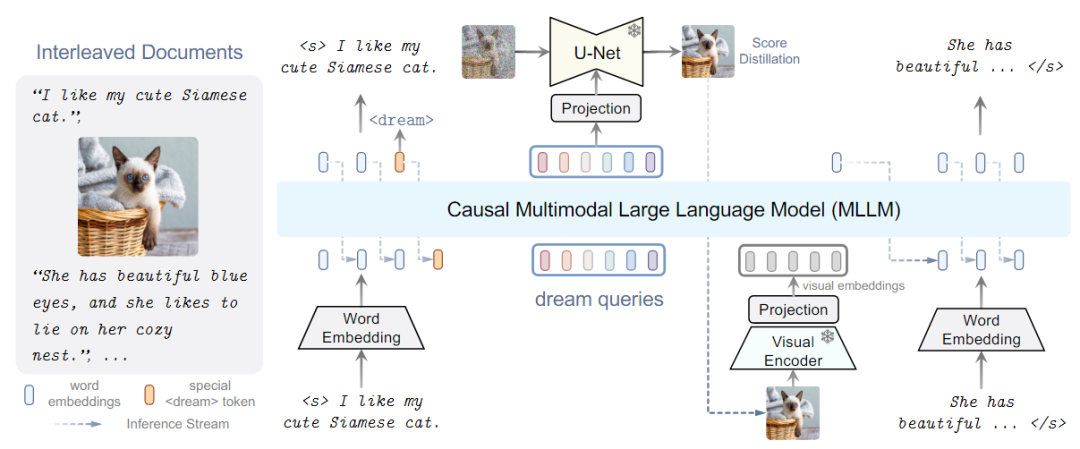
DREAMLLM架构
DREAMLLM框架如上图所示,使用交错的文档用作输入,解码以产生输出。文本和图像都被编码成用于MLLM输入的顺序的、离散的token嵌入。特殊的<dream>标记可以预测在哪里生成图像。随后,一系列dream查询被输入到MLLM中,捕获整体历史语义。图像由stable diffusion图像解码器以查询的语义为条件进行合成。然后将合成的图像反馈到MLLM中用于随后的理解。
其中MLLM是基于在shareGPT上训练的LLama的Vicuna,采用CLIP-Large作为图像编码器,为了合成图像使用Stable Diffusion作为图像解码器。
模型训练
模型训练分为对齐训练、I-GPT预训练和监督微调。
实验结果
-
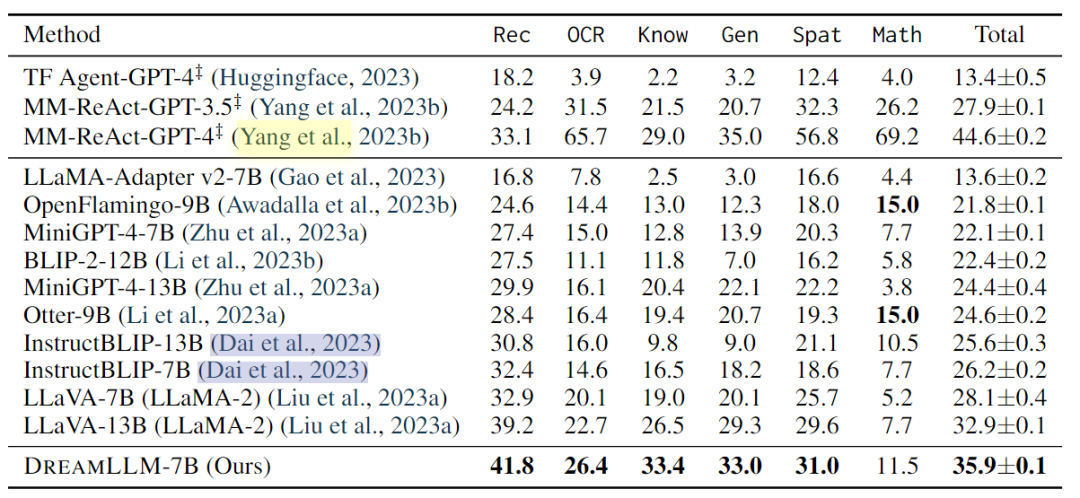
多模态理解:多模式理解使人类能够与以单词和视觉内容为条件的主体进行互动。本文评估了DREAMLLM在几个基准上的多模式视觉和语言能力。此外,对最近开发的MMBench和MM-Vet基准进行了零样本评估,以评估模型在复杂多模式任务中的性能。
-
发现,DREAMLLM在所有基准测试中都优于其他MLLM。值得注意的是,DREAMLLM-7B在图像合成能力方面大大超过了并发MLLMs,与Emu-13B相比,VQAv2的精度提高了16.6。在MMBench和MMVet等综合基准测试中,DREAMLLM与所有7B同行相比都取得了最先进的性能。
-
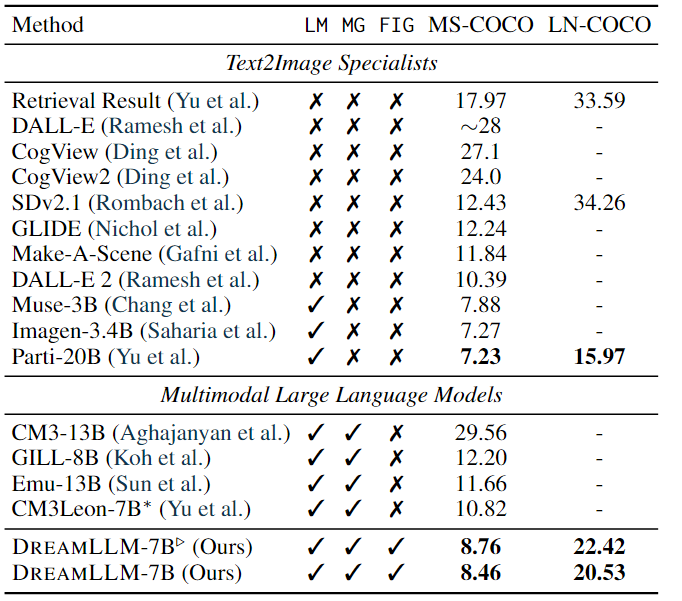
条件文本图像合成:条件文本图像合成是创造性内容生成最常用的技术之一,它通过自由形式的语言生成遵循人类描述的图像。
-
其结果如上表所示。结果显示:DREAMLLM 在阶段I对齐后显示出比Stable Diffusion基线显着提高FID,在 MS-COCO 和 LN-COCO 上分别将分数分别降低了 3.67 和 11.83。此外,预训练和监督微调后实现了 3.97 和 13.73 的 FID 改进。LN-COCO 的实质性改进强调了 DREAMLLM 在处理长上下文信息方面的卓越性能。与之前的专家模型相比,DREAMLLM 基于 SD 图像解码器提供了有竞争力的结果。DREAMLLM 始终优于基于并发 MLLM 的图像合成方法。
-
多模态联合创建于比较:分别进行了自由形式的交错文档创建、图片质量和人工评估三个实验。实验结果表明:DREAMLLM可以根据给定的指令生成有意义的响应。系统可以通过预测所提出的令牌在任何指定位置自主创建图像,从而消除了对额外人工干预的需要。DREAMLLM生成的图像准确地对应于相关文本。证明了所提方法的有效性。
总结
本文介绍了一个名为DREAMLLM的学习框架,它能够同时实现多模态理解和创作。DREAMLLM具有两个基本原则:第一个原则是通过在原始多模态空间中进行直接采样,生成语言和图像后验概率的生成建模。第二个原则是促进生成原始、交错文档,模拟文本和图像内容以及无结构的布局,使DREAMLLM能够有效地学习所有条件、边际和联合多模态分布。实验结果表明,DREAMLLM是第一个能够生成自由形式交错内容的MLLM,并具有卓越的性能。
-
多模态与视觉大模型开发实战 - 2026必会课分享2026-07-12 14
-
【完结】多模态与视觉大模型开发实战 - 2026必会2026-07-11 37
-
《多模态大模型 前沿算法与实战应用 第一季》精品课程简介2026-05-01 233
-
一文理解多模态大语言模型——下2024-12-03 1451
-
一文理解多模态大语言模型——上2024-12-02 2545
-
智谱AI发布全新多模态开源模型GLM-4-9B2024-06-07 1870
-
机器人基于开源的多模态语言视觉大模型2024-01-19 1220
-
自动驾驶和多模态大语言模型的发展历程2023-12-28 1596
-
探究编辑多模态大语言模型的可行性2023-11-09 1245
-
更强更通用:智源「悟道3.0」Emu多模态大模型开源,在多模态序列中「补全一切」2023-07-16 1785
-
VisCPM:迈向多语言多模态大模型时代2023-07-10 1656
-
邱锡鹏团队提出具有内生跨模态能力的SpeechGPT,为多模态LLM指明方向2023-05-22 1696
全部0条评论

快来发表一下你的评论吧 !
