

利用 FPGA 快速路径构建高性能、高能效边缘 AI 应用
描述
作者:Stephen Evanczuk
对于希望在边缘的推理处理器上实施人工智能 (AI)算法的设计人员来说,他们正不断面临着降低功耗并缩短开发时间的压力,即使在处理需求不断增加的情况下也是如此。现场可编程门阵列 (FPGA) 为实施边缘 AI所需的神经网络 (NN) 推理引擎提供了特别有效的速度和效率效率组合。然而,对于不熟悉 FPGA 的开发人员来说,传统 FPGA的开发方法可能相当复杂,往往导致他们去选择不太理想的解决方案。
本文将介绍来自 Microchip Technology 的一种比较简单的方法。通过这种方法,开发人员可以使用 FPGA 和软件开发套件 (SDK)
构建经过训练的 NN,或者使用基于 FPGA 的视频套件立即启动智能嵌入式视觉应用开发,从而避开传统的 FPGA 开发。
为什么要在边缘使用 AI?
边缘计算为物联网 (IoT) 应用带来了诸多好处,涵盖了包括工业自动化、安全系统、智能家居等在内的多个领域。在以工厂车间为目标的工业物联网 (IIoT)应用中,边缘计算通过避免到云端应用的往返延迟,可以显著缩短过程控制环路的响应时间。同样,基于边缘的安全系统或智能家居门锁即使由于意外或人为原因与云端的连接断开时,也能继续正常工作。在很多情况下,在任何此类应用中使用边缘计算时,都可以通过减少产品对云资源的依赖来帮助降低整体运营成本。随着产品要求的提高,开发者可以依靠产品中内置的本地处理功能去帮助维持更稳定的运营开支,而不会面临增加昂贵的云资源的意外需求。
对机器学习 (ML)
推理模型的快速接受和需求的增加,极大地提高了边缘计算的重要性。对于开发人员来说,推理模型的本地处理能力有助于降低云端推理所需的响应延迟和云资源成本。对于用户来说,使用本地推理模型会让他们更加相信,其产品在偶尔与互联网断开或基于云的供应商产品发生变化时仍能正常运行。此外,在安全和隐私方面的担忧会进一步推动对本地处理和推理的需求,以限制通过公共互联网传输到云端的敏感信息数量。
为基于视觉的对象检测开发 NN 推理模型是一个多步骤过程。首先进行模型训练,这一步通常在 TensorFlow 等 ML框架上使用公开的标记图像或自定义的标记图像进行训练。由于处理需求,模型训练通常使用云端或其他高性能计算平台的图形处理单元 (GPU)进行。训练完成后,模型被转换为能够在边缘或雾计算资源上运行的推理模型,并将推理结果以一组对象类概率的形式交付(图 1)。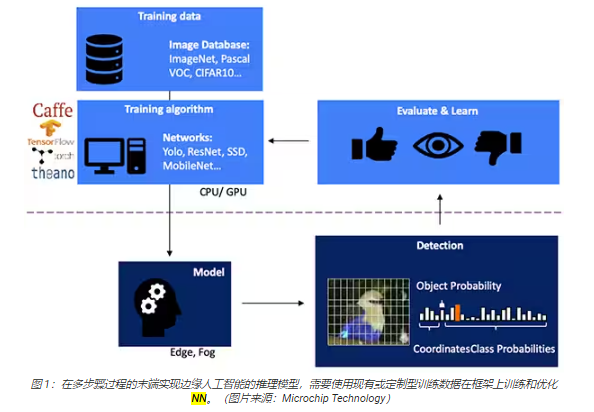
为什么推理模型存在计算方面的挑战
与训练过程中使用的模型相比,虽然 NN 推理模型的大小和复杂程度都有所降低,但还是需要大量计算,这对于通用处理器来说仍是一个挑战。在其通用形式中,深层NN 模型由多层神经元集组成。在一个全连接网络的每一层内,每个神经元 nij 都需要计算每个输入与相关权重系数 wij 的乘积之和(图 2)。
图
2 中没有显示激活函数和类似函数带来的额外计算要求。激活函数通过将负值映射为零,将大于 1 的值映射为 1来修改每个神经元的输出。每个神经元 nij 的激活函数的输出作为下一层i+1 的输入,以此类推直至每一层。NN模型的输出层最终产生一个输出向量,代表原始输入向量(或矩阵)对应于监督学习过程中使用的某一个类(或标签)的概率。
相比上图所示具有代表性的通用NN 架构,有效的 NN 模型是由大得多、复杂得多的架构来构建的。例如,用于图像对象检测的典型卷积 NN (CNN)以分段方式应用这些原理,扫描输入图像宽度、高度和颜色深度,从而生成一系列最终会产生输出预测向量的特征图(图 3)。

用 FPGA 加速 NN 数学
虽然在边缘执行推理模型的方案不断涌现,但很少有方案能够提供实际的边缘高速推理所需的最佳灵活性、性能和能效组合。在现有的边缘 AI 替代品中,FPGA特别有效,因为它们可执行基于硬件的高性能计算密集型工作,同时功耗相对较低。
尽管 FPGA 优势突出,但由于传统的开发流程有时会让没有丰富 FPGA 经验的开发人员望而生畏,舍弃 FPGA。为了有效实施通过 NN 框架生成的 NN模型的 FPGA,开发人员需要了解将模型转换为寄存器传输语言 (RTL)、设计综合和最终审定之间的细微差别,并需要制定具体的设计阶段路线,从而做到优化实施(图 4)。

凭借其 PolarFire FPGA、专用软件和相关知识产权 (IP),Microchip Technology 提供了一种解决方案,让没有 FPGA经验的开发人员也能广泛地使用高性能、低功耗边缘推理。
PolarFire FPGA 采用先进的非易失性工艺技术制造,旨在最大限度地提高灵活性和性能,同时将功耗降至最低。除了用于通信和输入/输出 (I/O)的大量高速接口外,它们还具有深厚的 FPGA 结构,能够使用软 IP 内核支持高级功能,具体包括 RISC-V 处理器、高级内存控制器和其他标准接口子系统(图 5)。

PolarFire FPGA 架构提供了一套广泛的逻辑元件和专用功能块,通过 PolarFire FPGA 系列的不同器件获得各种不同的容量支持,具体包括MPF100T、MPF200T、MPF300T 和 MPF500T 系列(表 1)。

在特别令人关注的推理加速功能中,PolarFire 架构包括一个专用数学块,提供一个具有预加法器的 18 位 × 18 位有符号乘法累加函数
(MAC)。内置的点积模式使用一个数学块来执行两个 8 位乘法运算,通过利用模型量化对精度的影响可以忽略这一优势,提供了一种可提高容量的机制。
除了能加快数学运算外,PolarFire 架构还有助于缓解在通用架构上实施推理模型时遇到的存储器拥堵问题,例如用来保存在 NN算法执行过程中创建的中间结果的小型分布式存储器。另外,NN 模型的权重值和偏置值可以存储在一个系数为 16 深 x 18 位的只读存储器 (ROM)中,这种存储器通过位于数学块附近的逻辑元件构建。
结合其他 PolarFire FPGA 结构特性,数学块为 Microchip Technology 更高级别的 CoreVectorBlox IP奠定了基础。这将作为一个灵活的 NN 引擎,能够执行不同类型的 NN。除了一组控制寄存器外,CoreVectorBlox IP 还包括三个主要功能块:
微控制器:一个简单的 RISC-V 软处理器,可从外部存储器读取 Microchip 固件二进制大对象 (BLOB) 和用户特定型 NN BLOB文件。通过执行固件 BLOB 的指令来控制 CoreVectorBlox 的整体运算。
矩阵处理器 (MXP):这是一种由 8 个 32 位算术逻辑单元 (ALU)组成的软处理器,旨在使用逐元素张量运算对数据向量执行并行运算,包括加法、减法、xor、移位、mul、dotprod 等,并根据需要使用 8 位、16 位和 32位混合精度。
CNN 加速器:使用通过数学块实现的二维 MAC 函数阵列来加速 MXP 运算,运算精度为 8 位。
一个完整的 NN 处理系统将包括 CoreVectorBlox IP 块、存储器、存储器控制器和主机处理器,如微软 RISC-V(Mi-V)软件处理器内核(图 6)。

在视频系统实施过程中,主机处理器将从系统存储器加载固件和网络 BLOB,并将其复制到双数据速率 (DDR) 随机存取存储器 (RAM) 中供CoreVectorBlox 块使用。当视频帧到达时,主机处理器将其写入 DDR RAM,并向 CoreVectorBlox块发出信号,以开始图像处理。在主机运行网络 BLOB 中定义的推理模型后,CoreVectorBlox 块将结果(包括图像分类)写回 DDR RAM
中,供目标应用程序使用。
开发流程简化了 NN FPGA 实施
Microchip 使开发人员避开了在 PolarFire FPGA 上实施 NN 推理模型的复杂性。NN 模型开发人员无需处理传统 FPGA流程的细节,而是像往常一样使用其 NN 框架,并将生成的模型加载到 Microchip Technology 的 VectorBlox 加速器软件开发工具包(SDK) 中。SDK 生成所需的一组文件,包括正常 FPGA 开发流程所需的文件和上文提到的固件和网络 BLOB 文件(图 7)。

由于 VectorBlox Accelerator SDK 流程将 NN 设计置于在 FPGA 中实施的 NN 引擎之上,因此不同的 NN 可以在同一FPGA 设计上运行,而无需重复 FPGA 设计综合流程。开发者为生成的系统创建 C/C++代码,并能在系统内快速切换模型,或使用时间切片同时运行模型。
VectorBlox Accelerator SDK 将 Microchip Technology Libero FPGA 设计套件与 NN推理模型开发的全套功能融为一体。除了模型优化、量化和校准服务之外,SDK 还提供了一个 NN 仿真器,能让开发人员在 FPGA 硬件实施中使用其模型之前用相同的BLOB 文件进行模型评估(图 8)。
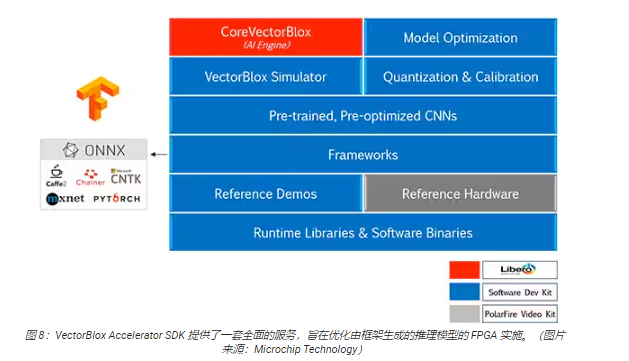
VectorBlox Accelerator SDK 支持采用开放神经网络交换 (ONNX) 格式的模型,以及来自包括TensorFlow、Caffe、Chainer、PyTorch 和 MXNET 在内的多种框架的模型。可支持的 CNN 架构包括MNIST、MobileNet 版、ResNet-50、Tiny Yolo V2 和 Tiny Yolo V3。Microchip正在努力扩大支持范围,将大多数网络纳入预训练模型的开源式 OpenVINO 工具包 开放模型动物园 中,包括Yolo V3、Yolo V4、RetinaNet和 SSD-MobileNet 等。
视频套件演示 FPGA 推理
为帮助开发人员快速启动智能嵌入式视觉应用开发,Microchip Technology 提供了一个全面的样例应用,设计用于在该公司的
MPF300-VIDEO-KIT PolarFire FPGA 视频和成像套件和参考设计上运行。
基于 Microchip MPF300T PolarFire FPGA,该套件电路板结合了双摄像头传感器、双数据速率 4 (DDR4)RAM、闪存、电源管理和各种接口(图 9)。

该套件附带一个完整的 Libero 设计项目,用于生成固件和网络 BLOB 文件。将 BLOB 文件编程到板载闪存中后,开发人员点击 Libero
中的运行按钮即可开始演示,处理来自摄像头传感器的视频图像,并将推理结果在显示屏上显示(图 10)。
对于每个输入视频帧,基于 FPGA 的系统会执行以下步骤(步骤编号与图 10 相关)。
从相机中加载一帧画面
将帧存储在 RAM 中
读取 RAM 中的帧
将原始图像转换为 RGB、平面化 RGB 并将结果存储在 RAM 中。
Mi-V soft RISC-V 处理器启动 CoreVectorBlo x引擎,从 RAM 中检索图像,进行推理并将分类概率结果存储回 RAM中。
Mi-V 使用结果创建一个包含边界框、分类结果和其他元数据的叠加帧,并将该框架存储在 RAM 中。
原始帧与叠加帧混合并写入 HDMI 显示屏。
该演示支持 Tiny Yolo V3 和 MobileNet V2模型加速,但需要开发人员改动少许代码,将模型名称和元数据添加到包含两个默认模型的现有列表中,即可使用上述方法运行其他 SDK 支持的模型。
结论
NN 模型等人工智能算法通常会施加计算密集型工作负载,这需要比通用处理器更强大的计算资源。虽然 FPGA能够很好地满足推理模型执行的性能和低功耗要求,但传统的 FPGA 开发方法可能会很复杂,往往导致开发人员转向不太理想的解决方案。
如图所示,使用 Microchip Technology 的专用 IP 和软件,没有 FPGA经验的开发人员也能实施基于推理的设计,更好地满足性能、功耗以及设计进度要求。
-
Supermicro推出紧凑型高能效系统:以边缘算力重构AI应用新范式2026-04-22 2494
-
Arm 推出 Armv9 边缘 AI 计算平台,以超高能效与先进 AI 能力赋能物联网革新2025-03-06 2517
-
FPGA+AI王炸组合如何重塑未来世界:看看DeepSeek东方神秘力量如何预测......2025-03-03 7783
-
当我问DeepSeek AI爆发时代的FPGA是否重要?答案是......2025-02-19 6581
-
AI赋能边缘网关:开启智能时代的新蓝海2025-02-15 1564
-
使用 FPGA 快速路径构建高性能、高能效的边缘 AI 应用2022-11-24 368
-
嵌入式边缘AI应用开发指南2022-11-03 1504
-
利用FPGA构建边缘AI推理的解决方案2022-10-13 2498
-
什么样的FPGA会更好地适用于边缘AI2019-12-16 1169
-
如何利用FPGA开发高性能网络安全处理平台?2019-08-12 3931
-
硬件帮助将AI移动到边缘2019-05-29 2587
-
利用安森美半导体IGBT实现高能效的高性能开关应用2013-11-20 1533
-
高能效电源的设计指南2011-12-13 3965
-
FPGA构建高性能DSP2009-12-08 2579
全部0条评论

快来发表一下你的评论吧 !
