

只要MLP就能实现的三维实例分割!
人工智能
描述
作者:PCIPG-mach
为三维点云实例分割提出了一个概念简单、通用性强的新框架。我们的方法被称为 3D-BoNet ,遵循每点多层感知器 (MLP) 的简单设计理念。
该框架直接回归点云中所有实例的三维边界框(bounding boxes),同时预测每个实例的点级掩码(a point-level mask)。它由一个骨干网络和两个并行网络分支组成,前者用于边界框回归,后者用于点掩码预测。3D-BoNet 是单级、无锚和端到端可训练的网络。此外,与现有方法不同的是,它不需要任何后处理步骤,且具有很高的效率。
1 前言
实例分割问题,主要障碍在于点云本身是无序、非结构化和非均匀的。广泛使用的卷积神经网络需要对三维点云进行体素化处理,从而产生高昂的计算和内存成本。
此外,它们不可避免地需要一个后处理步骤,如均值移动聚类,以获得最终的实例标签,而这一步骤的计算量很大。另一种管道是基于提议的 3D-SIS 和 GSPN ,它们通常依赖于两阶段训练和昂贵的非最大抑制来剪切密集的对象提议。
在本文中,我们提出了一个优雅、高效和新颖的三维实例分割框架,通过使用高效 MLP 的单向前向阶段来松散但唯一地检测对象,然后通过一个简单的点级二元分类器来精确分割每个实例。为此,我们引入了一个新的边界框预测模块和一系列精心设计的损失函数,以直接学习对象边界。我们的框架与现有的基于提议和无提议的方法有很大不同,因为我们能够高效地分割所有具有高对象性的实例,而无需依赖昂贵而密集的对象提议。
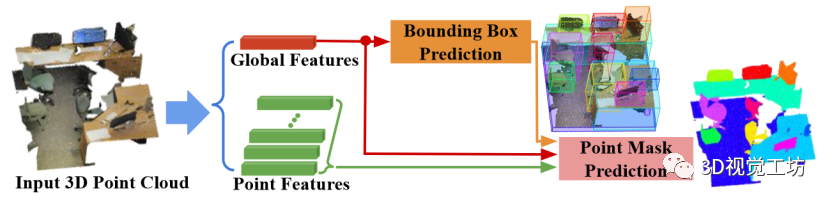
图 1 所示,我们的框架名为 3D-BoNet ,是一种单级、无锚、端到端可训练的神经架构。它首先使用现有的骨干网络为每个点提取局部特征向量,并为整个输入点云提取全局特征向量。
骨干网络之后有两个分支:
1) 实例级边界框预测
2) 用于实例分割的点级掩码预测。总体而言,我们的框架在三个方面有别于所有现有的三维实例分割方法。1) 与无提议管道相比,我们的方法通过明确学习三维对象边界来分割对象度高的实例。2) 与广泛使用的基于提议的方法相比,我们的框架不需要昂贵而密集的提议。3) 我们的框架非常高效,因为实例级掩码只需一次前向学习,无需任何后处理步骤。
我们的主要贡献如下:
我们提出了一种新的三维点云实例分割框架。该框架是单阶段、无锚和端到端可训练的,无需任何后处理步骤。
我们设计了一个新颖的边界框关联层,然后使用多标准损失函数对边界框预测分支进行监督。
通过广泛的消融研究,我们证明了与基线相比的显著改进,并提供了我们设计选择背后的直觉。
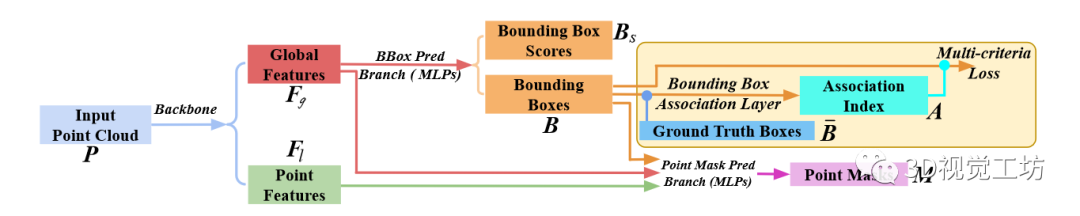
image.png 图 3:3D-BoNet 框架的一般工作流程。
3D-BoNet的总体框架如图所示,它主要由1) Instance-level bounding box prediction 2) Point-level mask prediction两个分支组成。顾名思义,bounding box prediction分支用于预测点云中每个实例的边界框,mask prediction分支用于为边界框内的点预测一个mask,进一步区分边界框内的点是属于instance还是背景。
2 3D-BoNet
2.1 Bounding Box Prediction(边界框预测)
边界框编码:在现有的物体检测网络中,边界框通常由中心位置和三维长度或相应的残差以及方向来表示。为了简单起见,我们只用两个最小-最大顶点来表示矩形边界框的参数:
神经层:如图 4 所示,全局特征向量通过两个全连接层,以 Leaky ReLU 作为非线性激活函数。然后再经过另外两个平行的全连接层。一层输出 6H 维向量,然后将其重塑为 H × 2 × 3 张量。H 是一个预定义的固定边框数,整个网络可预测的最大边框数。另一层输出一个 H 维向量,然后用 sigmoid 函数表示边界框得分。分数越高,预测的边框越有可能包含一个实例,因此边框越有效。

图 4:边界框回归分支的结构。在计算多标准损失之前,将预测的 H 边框与 T 地面真实边框进行优化关联。
边框关联层:给定先前预测的 H 个边界框(即 ),利用地面实况框来监督网络并不简单,因为在我们的框架中,没有预定义的锚点可以将每个预测框追溯到相应的地面实况框。此外,对于每个输入点云,地面实况箱的数量 都是不同的,通常与预定义的数量 不同,不过我们可以有把握地假设所有输入点云的预定义数量 。此外,预测方框和地面实况方框都没有方框顺序。
最优关联公式:_为了从 中为的每个地面实况框关联一个唯一的预测边界框,我们将这一关联过程表述为一个最优分配问题。形式上,让 成为布尔关联矩阵,如果第 个预测框被分配给第个地面实况框,则其为1。在本文中也称为关联索引。让 成为关联成本矩阵,其中表示第 i 个预测方框被分配到第 j 个地面实况方框的成本。基本上,代价 代表两个方框之间的相似度;代价越小,两个方框越相似。因此,边界方框关联问题就是要找到成本最小的最优分配矩阵 :
损失函数 在边框关联层之后,预测的边框 和分数 都将使用关联索引 进行重新排序,从而使最先预测的个边框和分数与 个地面实况边框很好地配对。_边框预测的多标准损失_:上一个关联层根据最小成本为每个地面实况箱找到最相似的预测箱,最小成本包括1) 顶点欧氏距离;2) 点上的 sIoU 成本;3) 交叉熵得分。因此,边界框预测的损失函数自然是为了持续最小化这些成本而设计的。
其形式定义如下
请注意,我们只最小化 个配对方框的成本;其余个预测方框将被忽略,因为它们没有相应的地面实况。因此,这个方框预测子分支与预定义的 值无关。由于负预测没有受到惩罚,网络可能会对一个实例预测出多个相似的方框。幸运的是,平行边框得分预测的损失函数能够缓解这一问题。
框选得分的预测差_:预测的框得分旨在表明相应预测方框的有效性。通过关联指数 A 重新排序后,前 T 个得分的地面实况得分均为 "1",其余无效的个得分均为 "0"。
我们使用交叉熵损失来完成这项二元分类任务:
基本上,这个损失函数奖励的是预测正确的边界框,而隐含地惩罚了对一个实例回归多个相似边界框的情况。
2.2Point Mask Prediction(点掩膜预测)
给定预测的边界框 、学习到的点特征 和全局特征 ,点掩码预测分支通过共享神经层单独处理每个边界框。
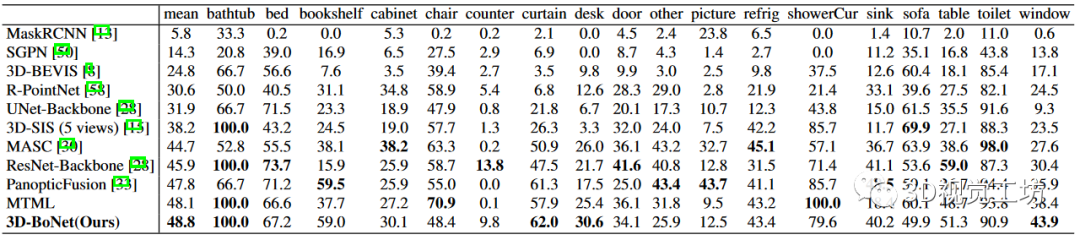
表 1:ScanNet(v2) 基准(隐藏测试集)上的实例分割结果。指标为 AP(%),IoU 阈值为 0.5。访问日期:2019 年 6 月 2 日。
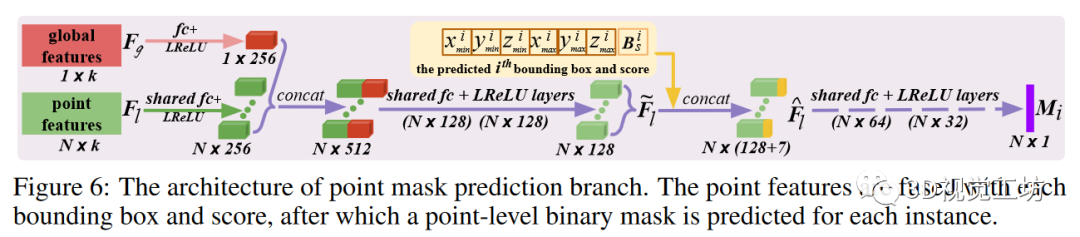
神经层:如图 6 所示,通过全连接层将点特征和全局特征压缩为 256 维向量,然后进行连接并进一步压缩为 128 维混合点特征。对于第 i 个预测的边界框,估计的顶点和分数通过连接与特征 融合,产生框感知特征 然后,这些特征通过共享层,预测出一个点级二进制掩码,表示为 我们使用 sigmoid 作为最后一个激活函数。
这种简单的盒式融合方法计算效率极高,而现有技术中常用的 RoI Align则涉及昂贵的点特征采样和对齐。损失函数:根据先前的关联指数,预测的实例掩码 与地面实况掩码具有相似的关联。由于实例点和背景点的数量不平衡,我们使用带有默认超参数的焦点损失(focal loss),而不是标准的交叉熵损失(cross-entropy loss)来优化这一分支。只有有效的 配对掩码才会被用于损失
2.3 End-to-End Implementation(端到端实现)
虽然我们的框架并不局限于任何点云网络,但我们采用 PointNet++ 作为骨干来学习局部和全局特征。与此同时,我们还实现了另一个独立的分支,利用标准的 sof tmax 交叉熵损失函数 来学习每个点的语义。
骨干和语义分支的架构与中使用的相同。给定输入点云 P 后,上述三个分支被连接起来,并使用单一的组合多任务损失进行端到端训练:
我们使用 Adam 求解器及其默认超参数进行优化。初始学习率设置为 5e-4,然后每 20 个历元除以 2。整个网络在 Titan X GPU 上从头开始训练。我们在所有实验中使用相同的设置,这保证了我们框架的可重复性。
3 Experiments
3.1 Evaluation on ScanNet Benchmark(ScanNet 基准评估)
在实验中,我们发现基于虚构 PointNet++ 的语义预测子分支性能有限,无法提供令人满意的语义。得益于我们框架的灵活性,我们可以轻松地训练一个并行 SCN 网络,为我们的 3D-BoNet 预测实例估算出更精确的每点语义标签。

图 7:这是一个有数百个物体(如椅子、桌子)的阶梯教室,凸显了实例分割所面临的挑战。不同的颜色表示不同的实例。相同的实例可能没有相同的颜色。我们的框架能比其他框架预测出更精确的实例标签。
3.2 Evaluation on S3DIS Dataset(S3DIS 数据集评估)
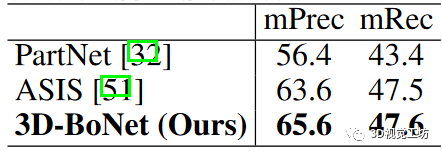
为了进行公平比较,我们使用与我们的框架相同的 PointNet++ 主干网和其他设置对 PartNet 基线进行了仔细训练。为了进行评估,我们报告了 IoU 阈值为 0.5 的经典指标平均精度(mPrec)和平均召回率(mRec)。需要注意的是,我们使用了相同的 BlockMerging 算法来合并我们的方法和 PartNet 基线中来自不同区块的实例。最终得分是 13 个类别的平均值。列出了 mPrec/mRec 分数, 显示了定性结果。我们的方法远远超过了 PartNet 基线 ,也优于 ASIS ,但并不显著,主要原因是我们的语义预测分支(基于 vanilla PointNet++)不如 ASIS,后者将语义和实例特征紧密融合,实现了相互优化。我们将把特征融合作为未来的探索方向。
3.3 Ablation Study(消融研究)
为了评估框架各组成部分的有效性,我们在S3DIS数据集最大的区域5上进行了6组消融实验。
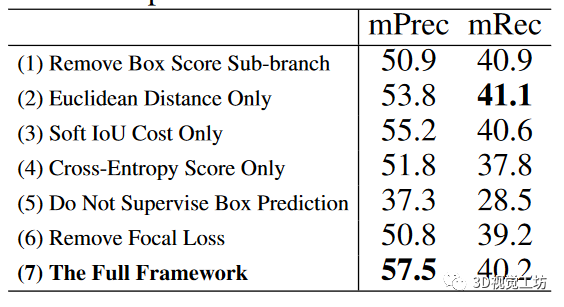
分析结果表显示了消融实验的得分。(1) 边框得分的这一个子分支确实有利于整体实例分割性能,因为它倾向于惩罚重复的边框预测。(2)与欧氏距离和交叉熵得分相比,由于我们的可微分算法 1,sIoU 成本往往更有利于方框关联和监督。由于三个标准各自偏好不同类型的点结构,在特定数据集上,三个标准的简单组合不一定总是最优的。(3) 如果没有方框预测的监督,性能就会显著下降,这主要是因为网络无法推断出令人满意的实例三维边界,预测点掩模的质量也会相应下降。(4) 由于实例和背景点数不平衡。与焦点损失相比,标准交叉熵损失对点掩膜预测的效果较差。
3.4 Computation Analysis(计算分析)
(1) 对于基于点特征聚类的方法,包括 SGPN、ASIS、JSIS3D、3D-BEVIS、MASC,后聚类算法(如 Mean Shift)的计算复杂度趋向于 O(T N 2),其中 T 为实例数,N 为输入点数。(2) 对于基于密集提议的方法,包括 GSPN[58]、3D-SIS[15]和 PanopticFusion[33],通常需要区域提议网络和非最大抑制来生成和修剪密集提议,计算成本高昂[33]。(3) PartNet 基线和我们的 3D-BoNet 都具有类似的高效计算复杂度 O(N)。根据经验,我们的 3D-BoNet 处理 4k 个点大约需要 20 毫秒的 GPU 时间,而 (1)(2) 中的大多数方法处理相同数量的点需要 200 毫秒以上的 GPU/CPU 时间。
4 Related Work(相关工作)
要从三维点云中提取特征,传统方法通常是手工制作特征。近期基于学习的方法主要包括基于体素的方案和基于点的方案。语义分割 广泛运用的包括PointNet 和基于卷积核的方法,基本上,这些方法中的大多数都可以用作我们的骨干网络,并与我们的 3D-BoNet 并行训练,以学习每个点的语义。物体检测:相比现有方法,我们的方框预测分支与它们完全不同。我们的框架通过一次前向传递,直接从紧凑的全局特征回归三维物体边界框。实例分割 相比现有方法,我们的框架直接为明确检测到的对象边界内的每个实例预测点级掩码,而不需要任何后处理步骤。
5 Conclusion(结论)
其框架对于三维点云的实例分割来说简单、有效且高效。但是,它也有一些局限性,这也是未来工作的方向。(1) 与其使用三个标准的非加权组合,不如设计一个模块来自动学习权重,以适应不同类型的输入点云。(2) 与其训练一个单独的语义预测分支,不如引入更先进的特征融合模块,使语义分割和实例分割相互促进。(3) 我们的框架采用 MLP 设计,因此与输入点的数量和顺序无关。我们希望借鉴最近的研究成果,直接在大规模输入点云上进行训练和测试,而不是分割成小块。
编辑:黄飞
-
三维逆向工程的成果及应用案例2016-03-02 3719
-
三维快速建模技术与三维扫描建模的应用2018-08-07 4023
-
广西扫描服务三维检测三维扫描仪2018-08-29 6090
-
三维设计应用案例2019-07-03 2633
-
三维立体数字沙盘是是什么?2020-08-28 2394
-
Labview绘制三维曲面图2020-12-18 4972
-
如何实现三维数据的采集?2021-04-07 1916
-
基于MLP的快速医学图像分割网络UNeXt相关资料分享2022-09-23 4408
-
基于空间分割的遗传算法解决三维装载问题程中文2017-03-16 1021
-
基于三维模型球型分割的信息隐藏算法2017-11-28 966
-
基于深度学习的三维点云语义分割研究分析2021-04-01 1497
-
基于聚类分析的三维网格分割技术综述2021-04-29 1042
-
智慧城市_实景三维|物业楼三维扫描案例分享_泰来三维2023-05-16 2240
-
泰来三维|古建筑保护木雕三维扫描应用2023-05-29 1674
-
泰来三维|文物三维扫描,文物三维模型怎样制作2024-03-12 1907
全部0条评论

快来发表一下你的评论吧 !
