

如何让级联URAM获得最佳时序性能
描述
1. 前言
在上一篇文章里《如何使用UltraScale+芯片中UltraRam资源》,我们向大家介绍了在RTL设计中使用URAM的方法。其中,我们推荐大家使用Xilinx参数化宏(XPM)的方法来调用URAM。通过XPM调用的URAM的方法如下:
在模板中选择“Verilog”->“Xilinx Parameterized Macros (XPM)”->“XPM”->“XPM_MEMORY” ->“Simple Dual Port Ram”
用户必须在MEMORY_PRIMITIVE类属上指定值 ”ultra”,以明确指示vivado 综合使用 UltraRam。
那么问题来了,还有个参数“READ_LATENCY_A/B”该设多少?这个参数影响URAM的读操作需要滞后多少时钟周期才能将读数据输出。

2. 级联URAM须知
单个URAM器件的数据位宽为72bit,地址深度为4096,存储容量为288Kb。因此,当用户需要大于288Kb存储容量空间时,需要级联多个URAM器件。在Kintex UltraScale+和Zynq UltraScale+器件中,级联得到的RAM阵列可高达36Mb,在Virtex UltraScale+系列中,所有UltraRAM列都可通过光纤路由连接在一起,在最大器件中可构成容量达360Mb的存储器阵列。
下图展示了一个4 x 4的URAM阵列级联结构,在纵向的一列中,每个URAM使用内置级联电路进行级联。在横向多列之间,URAM通过外部级联电路进行互连,即水平级联电路。

但是,URAM和Bram (block ram)不太一样。在工作时钟频率不变情况下,深度级联URAM阵列会使得数据输出延迟越来越大,因为需要在级联的URAM模块中插入多级流水线,以保证模块能时序收敛。
同样,想保证输出延迟固定,级联越多的URAM会导致整个级联的URAM可工作的时钟频率越低。
因此,我们需要谨慎的设置“READ_LATENCY_A/B”参数,来保证级联的URAM模块能按自己的需求时序收敛并正常地工作。
注意: 如果使用XPM来调用URAM模块,则URAM内部可用的流水线阶数是设定的LATENCY值减去2。例如,如果“READ_LATENCY_A/B”参数设为10,则允许8个寄存器阶段用于流水线操作。
3. URAM性能估计
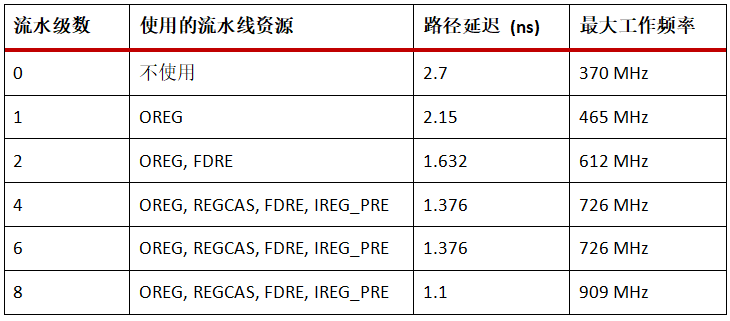
从上文,我们知道,LATENCY值的设置取决于URAM级联的深度、工作频率。下表以4x4的URAM矩阵为例,总结了流水线级数与可实现的最大工作频率之间的关系。
注: 实际的延迟仍取决于设计中最终的布局布线结果。
注: 下表是基于Virtex UltraScale+ speed -2器件为基础给的结果。
注: 该级联的URAM阵列最大只支持8级流水线**。**
注: LATENCY取值为表中流水级数值加2。
4. 检查设计是否达到最优时序
第3节中的表只是一个参考,让大家大致了解级联的流水线级数、输出延迟、工作频率之间的关系。如果我已经完成了设计,指定好了“READ_LATENCY_A/B”参数的值,如何确定该延迟值是否设置的最优呢?
Vivado工具是提供了相应的综合报告来告知工程师级联的URAM模块是否能到达最优时序。工程师在Vivado的GUI里,选中“Messages”一栏,查找有关URAM的提示。

一般提示如下,对应的解决方法附在其后:

相信经过这两篇文章总结,大家在如何使用URAM问题上应该不会有太多的疑惑。
5.总结
本文向大家介绍了如何通过XPM调用URAM,并让级联URAM获得最佳时序性能,如果觉得我们原创或引用的文章写的还不错,帮忙点赞和推荐吧,谢谢您的关注。
- 相关推荐
- 热点推荐
- 芯片
- Xilinx
- RTL
- 时序
- UltraScale
-
如何通过Vivado Synthesis中的URAM矩阵自动流水线化来实现最佳时序性能2023-05-08 3541
-
什么是调整电路板以获得最佳性能的最佳方式?2023-04-12 552
-
URAM和BRAM有哪些区别2022-07-25 7981
-
如何调整MLX75308的参数以获得最佳性能的系统2021-05-06 4381
-
如何才能获得上佳的噪声性能?2021-04-12 682
-
URAM和BRAM有什么区别2021-01-27 2395
-
URAM和BRAM的区别是什么2020-12-23 4814
-
使用流水线寄存器实现最佳时序性能方案2019-07-26 7751
-
基于URAM原语创建容量更大的RAM2019-07-13 8866
-
BRAM和URAM重要的片上存储资源,两者有显著的区别2019-03-06 29895
-
使用Intel图形性能分析器从游戏开发中获得最佳性能2018-11-08 3723
-
应该使用哪种策略来获得最佳时序收敛?2018-11-05 1947
-
FPGA时序收敛让你的产品达到最佳性能!2018-04-10 1453
-
级联码,什么是级联码2010-04-03 3816
全部0条评论

快来发表一下你的评论吧 !
