

 星河AI网络,大模型纪元的运力答案
星河AI网络,大模型纪元的运力答案
描述
随着AI预训练大模型的价值不断显现,且模型规模愈发庞大。产学各界已经形成了这样一个共识:AI时代,算力就是生产力。
这一认知虽然正确,却并不全面。数字化系统有存、算、网三大支柱,AI技术也是如此。如果抛开存储和网络谈算力,那么大模型只能独木难支。尤其是与大模型适配的网络基础设施,一直以来都没有得到有效的重视。
面对动辄“万卡集训”“万里部署”“万亿参数”的AI大模型,网络运力是整个智能化体系中不容忽视的一环。其面临的挑战非常突出,也正在等待可以破局的答案。

(华为数据通信产品线总裁 王雷)
9月20日,华为全联接大会2023期间举办了“星河AI网络,加速行业智能化”为主题的数通峰会。各界代表共同探讨了AI网络技术的变革与发展趋势。会上,华为数据通信产品线总裁王雷正式发布星河AI网络解决方案。他表示,大模型让AI更聪明,但训练一个大模型的成本非常高,同时还要考虑AI人才的成本。因此,在行业智能化阶段,集中建设大算力集群,面向社会提供智算云服务,才能真正让人工智能深入千行万业。华为发布新一代星河AI网络解决方案,面向智能时代,打造超高吞吐、长稳可靠、弹性高并发的新型网络基础设施,助力AI普惠,加速行业智能化。
借此机会,我们一起了解大模型崛起,给智算数据中心带来的网络挑战,以及华为星河AI网络为什么是这些问题的最优解。
如果说,一个模型、一条数据、一个计算单元,都是AI时代的一道星光。那么只有把它们高效稳定地联接起来,才能组成智能世界的灿烂星河。
大模型爆发,隐藏的网络激流
我们知道,AI模型分为训练和推理部署两个阶段。伴随着预训练大模型的兴起,这两个阶段也分别发生了巨大的AI网络挑战。
首先是在大模型的训练阶段。伴随着模型规模与数据参数愈发庞大,大模型训练开始需要千卡甚至万卡规模的计算集群来完成。这也意味着大模型训练必然发生在具备AI算力的数据中心当中。
在目前阶段,智算数据中心的成本是非常高昂的。根据行业数据,每建设100P算力的集群,成本就要达到4亿人民币。以某国际知名大模型为例,其训练过程中每天的算力花费就要达到70万美元。
如果数据中心网络的联接能力不畅,造成大量算力资源折损在网络传输过程中,那么给数据中心与AI模型带来的损失是难以估量的。相反,如果同等算力规模下,集群训练效率更高,那么数据中心将获得巨大商机。而负载率等网络因素,直接决定了AI模型的训练效率。另一方面,由于AI算力集群的规模不断扩大,其复杂度也在相应增长,于是其故障发生概率也在提升。打造长稳可靠的集群网络,是数据中心提升投入产出比的重要支点。
在数据中心之外,AI模型的推理部署场景中,同样也可以看到AI网络的价值体现。大模型的推理部署主要依靠云服务,而云服务商必须在算力资源有限的情况下,尽量服务更大的客户,以此实现大模型的商业价值最大化。如此一来,用户越多整个云网结构就会越复杂。如何能够提供长期稳定的网络服务,成为了云计算服务商新的挑战。
除此之外,在AI推理部署的最后一公里,政企用户面临着网络质量提升的需求。在真实场景下,1%的链路丢包会导致TCP性能下降50倍,也就是100Mbps的宽带,实际能力不足2Mbps。因此,提升应用场景本身的网络能力,才可以保证AI算力顺畅流动,实现真正的普惠AI。
由此不难看出,在AI大模型的诞生、传输、应用全流程中,每个环节都面临着网络升级的挑战与需求。大模型时代的运力难题,亟待破局解题。
从星光到星河,智能时代的网络破局思路
大模型崛起带来的网络难题是一个多环节、全流程的挑战。因此,对应的破局思路也必须是一个系统性工程。
华为提出,面向智算云服务的新型网络基础设施,需要支持 “训练高效能”“算力不停歇”“普惠AI服务”。这三项能力,对应了AI大模型从训练到推理部署的全场景。不仅着眼于单一需求满足,单一技术的升级,而是全面推进AI网络迭代,正是华为数据通信带给行业独特的破局思路。
具体而言,AI时代的网络基础设施需要包含如下能力:
首先,在训练场景网络需要最大化发挥出AI计算集群的价值。通过打造具备超大规模联接能力的网络,实现AI大模型的训练高效能。
其次,为了保障AI任务的稳定可持续,需要打造长稳可靠的网络能力,保障月级训练不中断,同时要有秒级的稳定定界、定位和回复,尽可能降低训练中断时常。这就是算力不停歇的能力建设。
再次,AI推理部署过程中,要求网络具有弹性高并发的特质,可以智能编排海量用户流,提供最佳的AI落地体验,同时可以对抗网络劣化冲击,保障不同区域间AI算力顺畅流动,这也就实现了“普惠AI服务”的能力建设。
秉承这样的破局思路,华为最终带来了星河AI网络解决方案。它把散落的AI星光,基于强大运力联成一片星河。
星河AI网络,给大模型纪元一个运力答案
华为全联接大会2023的期间,华为分享了对以大算力、大存力、大运力加速AI大模型打造的发展愿景。新一代华为星河AI网络解决方案,就可以说是面向智能时代,华为为大模型带来的运力答案。
对于智能数据中心来说,华为星河AI网络是以网强算的最优解。

其所具备的超高吞吐网络特质,可以面向智算中心的AI集群提供提升网络负载率,强化训练效率的重要价值。具体来说,星河AI网络智算交换机具有业界最高密400GE和800GE端口能力,仅2层交换网络就可以实现1万8000卡的无收敛集群组网,从而支持超万亿参数的大模型训练。组网层次一旦减少,就意味着数据中心能够节省了大量的光模块成本,同时提高对网络风险的可预测性,获得更加稳定的大模型训练能力。
星河AI网络可以支持网络级负载均衡NSLB,能够将负载率从50%提升到98%,相当于实现AI集群超频运行,继而将训练效率提升20%,达成高效能训练的预期。
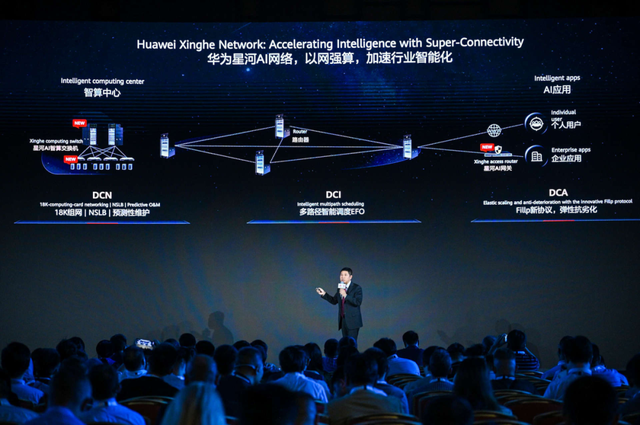
对于云服务厂商来说,星河AI网络可以提供稳定可靠的算力保障。
其能够在DCI算间互联场景,提供多路径智能调度等技术,自动识别、主动适应业务高峰流量的冲击,可以从百万数据流中识别大小流,合理分配到10万路径,从而实现网络0拥塞,弹性保障高并发的智算云服务。
对于政企用户来说,星河AI网络可以应对网络劣化问题,保障普惠化的AI算力。
其能够在DCA入算场景支持弹性抗劣化能力,采用Fillp技术优化TCP协议,可以在1%丢包率的情况下将带宽负载率从10%提升至60%,从而保障从都市圈到偏远地区的算力顺畅流动,加速AI服务的普惠应用。
如此一来,大模型从训练到部署各个环节的网络需求都被打通。从智算中心到千行万业,都有了以网强算的发展支点。
一个属于智能化的时代,一个由大模型开启的科技新纪元刚刚开始。星河AI网络,给智能时代写下了一个关于运力的答案。
-
算力大会2023 | 华为星河AI网络,高运力释放AI时代高算力2023-08-18 2125
-
华为全联接大会2023|华为正式发布星河AI网络,加速行业智能化2023-09-20 1863
-
华为星河AI网络亮相2023AI创新网络大会,斩获“璀璨技术奖”大奖2023-10-21 2338
-
一图看懂星河AI数据中心网络,全面释放AI时代算力2024-03-22 1741
-
HNS 2024:星河AI数据中心网络,赋AI时代新动能2024-05-15 1641
-
一图看懂星河AI园区网络,以体验为中心,企业数智升级首选2024-05-19 1100
-
行业智能化的“火车头效应”,由星河AI金融网络启动2024-08-23 3638
-
华为星河AI网络共赢行业智能化2024-11-18 1439
-
华为面向海外全面升级星河AI网络2025-03-06 1649
-
华为全新升级星河AI数据中心网络2025-03-24 1353
-
华为面向亚太地区发布全新星河AI数据中心网络方案2025-06-11 1735
-
华为面向拉美地区发布全新星河AI数据中心网络方案2025-08-11 2748
-
华为AI-Centric星河AI网络解决方案全面升级2025-09-20 1630
-
华为发布全新升级星河AI园区网络解决方案2025-09-25 1146
-
2026华为星河AI网络商业峰会即将启幕2026-05-18 568
全部0条评论

快来发表一下你的评论吧 !
