

节省编译时间的解决方法
描述
编译时间分析:
影响编译时间的因素有很多,包括工具流程、工具设置选项、RTL 设计、约束编辑、目标器件以及设计实现期间各工具所面临的任何关键问题。除此之外,所使用的机器及其负载也是关键因素。在这篇博客中,我们只探讨与设计和工具流程有关的因素。另外值得一提的是,所述技巧并不适用于所有用户。例如,如果某个设计由 50 个 FPGA 镜像组成,每个镜像含 50 个约束文件,那么在此类设计中更改约束可能不切实际。但对于单一设计运行来说,约束更改会更有意义。
此外,个别建议对某些设计的影响会比其他设计更大。例如,如果对某个并行运行 50 轮的设计应用某一项约束更改,此项更改会影响所有运行轮次。但如果在设计上只运行一轮实现,那么更改约束的影响有限。
本文中将描述每种技巧的优势和成本,但最终须由您作为用户来自行决定是否值得在自己的用例中实现这些技巧。
测量编译时间:
比较约束更改前后的编译时间时,重要的是在相似的机器上运行更改从而得到公平的比较结果。
如果这不可行,那么您可以通过比较数值变化来大致了解编译时间变化,而不必依赖绝对数值。有多种方法可用于比较时间。
对于完整的 Vivado 运行轮次,可以在 vivado.log 文件中搜索编译时间信息。例如,您可在其中找到如下行:
place_design: Time (s): cpu = 0334 ; elapsed = 0153 . Memory (MB): peak = 21362.934 ; gain = 3668.312 ; free physical = 12076 ; free virtual = 142273
此行包含在 place_design 阶段耗费的总时间以及内存使用情况。“cpu”的时间是在 place_design 中分配有子任务的多个线程的累计时间。
值得注意的是“elapsed”耗用时间,即启动和完成该 place_design 阶段的时间差。
另外还有其他多行内容包含相同格式的时间报告,但这些行首不含命令名称,如:
Time (s): cpu = 0050 ; elapsed = 0024 . Memory (MB): peak = 21322.859 ; gain = 3612.184 ; free physical = 42807 ; free virtual = 172805
这表示某一具体步骤中每个单独阶段耗费的时间。因此,要得到编译总时间,只需将工程模式或非工程模式下运行的每个步骤所报告的编译时间相加即可:
T(synth_design)+T(opt_design)+ T(place_design)+ T(phys_opt_design)+T(route_design).
请注意,工程模式需要时间来生成多个报告文件,这个时间也应该一并算上。这样您就能清楚知晓哪个步骤在编译总时间中耗时最多。
如要调查某一条命令而不是某个运行步骤所耗费的时间量,您可使用 Tcl 命令来跟踪这条命令。
例如,使用以下命令即可得到运行一条 get_pins 命令的时间为 44 毫秒:
set start [clock milliseconds]; get_pins -filter {NAME =~ *FPGA*/O}; set stop [clock milliseconds] ; puts "TIME: [expr $stop -$start]"
TCL console output -> TIME: 44
set start [clock milliseconds]; get_pins -filter {NAME =~ *FPGA*/O}; set stop [clock milliseconds] ; puts "TIME: [expr $stop -$start]"TCL console output -> TIME: 44
如果您有一个含数千行命令的巨型约束文件,并且想要快速了解每条命令所耗费的时间,那么此技巧会很有帮助。
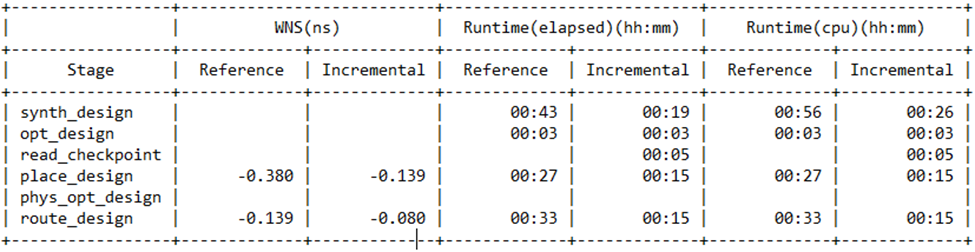
对于增量流程,可以在 log 日志文件中直接生成一个表格,计算每个步骤中默认运行和增量运行的编译总时间,因此非常便于阅读查看。
虽然想必您知道,在综合或实现阶段,增量运行可以从参考文件中读取和复制信息,但仅在某些阶段中能节省时间,如果网表发生大量更改,其中引用的内容就会减少,编译时间也会受到相应影响。
分析编译时间:
获得期望的编译时间信息后,下一步是分析时间数据,决定哪个步骤影响最大,这样即可便于您寻找解决办法。
示例如下:
示例 1:
假设我们发现 route_design 步骤耗用的编译时间最多。通过阅读 log 日志报告发现,此设计的资源使用率很高导致布线拥塞,因此布线器编译时间非常长。
因此,我们可以依靠 report_design_analysis 获取拥塞报告,找出哪个区域或模块导致出现此问题。我们可以据此判断是对代码进行最优化以获得低拥塞的 RTL 编码样式,还是依靠该工具的拥塞策略来进行操作。
示例 2:
如果使用了大量 IP 或模块,并且无需每轮都进行更新,则可考虑采用流程最优化。例如,对于在设计中进行例化的部分 IP 核,可以启用 IP 高速缓存,以免每次都重新生成这些 IP,从而节省 IP 生成时间。
我们可以启用自下而上的开发流程进行并行开发,这将最终节省设计实现的集成时间。也可以在完成一个流程后启用增量流程,进行快速设计迭代,以获取指导性文件。
根据可用于解决编译时间问题的 2 种不同方法,以下内容分为 2 部分。
解决设计存在的具体编译时间问题:
下列技巧可用于解决设计的具体编译时间问题,这些技巧根据常见问题根源和解决方案可分为 4 类:
约束
增量实现
工具驱动的选项
使用非关联运行
约束:
设计中包含清晰、合理且精确的约束有助于有效利用系统存储器,从而减少整体编译时间。我们需要分析在约束上耗费的编译时间,了解这些编译时间的具体分配,并改进约束语法以提高其效率。欲知详情,请参阅博文利用高效约束节省编译时间开发者分享|节省编译时间系列-利用 Tcl 脚本对编译时间进行剖析 及其中随附的示例。
增量流程
增量综合流程开发者分享|节省编译时间系列-使用增量综合与增量实现流程开发者分享|节省编译时间系列-使用增量实现都是非常直接且易于管理的方法,能够达成最大输出。当设计更改率极低时,您可基于成功的运行轮次快速迭代,这样还能生成一致性和可预测性更高的结果,从而帮助节省编译时间。请单击链接查看这两篇博文,其中提供了采用流程需满足的一些先决条件,以及有关如何理解报告的信息。
工具和报告选项
工具驱动的选项有助于最大限度减少特定设计问题,如,设计 DRC 问题、不适当的时序约束覆盖或设计拥塞,这类问题可能严重影响编译时间,应先一探究竟,而后再执行任何其他工具最优化操作。我们可以凭借 Vivado 报告工具来生成报告并执行分析。
运行 report_methodology 解决设计方法论问题。报告中指出的一些不良措施可能会影响编译时间,您可先从报告中轻松获取修订,然后再开始下一轮运行。
运行 report_design_anlaysis 解决时序、复杂性、拥塞等问题。通过读取顶层关键路径、设计复杂性 Rent 指数和设计布局热点,可帮助您更好地了解设计中的瓶颈。此报告可以提供一些简单的构想,帮助您寻找解决方案。
运行 report_qor_suggestions 通过低级别 Tcl 脚本获取其他建议,然后可以将这些建议直接应用于设计。
运行 report_exceptions 获取有关时序交互和覆盖的信息。如果错误设置时序约束导致时序过紧,就可能会导致编译时间延长。
非关联运行/块级综合
在非关联模式下运行设计核会生成并行子运行,这意味着能缩短设计集成时间,块级综合也可以为不同的子模块定义不同的编译时间或性能策略。它也能缩短集成时间,从而减少编译总时间。
如需跨多个设计缩短编译时间,就要基于设计结果来应用一些更为通用的方法并进行迭代。这些技巧分为以下 2 类。
Vivado 自动建议的流程和约束:
从 2019.1 版本起,Vivado 启用了全新的功能特性,能以 Tcl 格式提供多项自动生成的策略,后续可通过 source 命令直接使用。
这有助于缩短清扫策略的周期,并且很容易找到一些编译时间/性能平衡的最佳策略,且无需手动执行并行清扫所有设计的工作。
在 report_qor_suggestion 中启用该功能特性。
清扫实现指令
分析了如何从现有策略中选择以编译时间为目标的指令,并提供了一些建议,以便于您定义自己的编译时间缩短策略。
总结:
利用上述技巧时,我们认为应分析编译总时间,限定范围以便查找最优化方法并最终缩短编译总时间。
审核编辑:汤梓红
-
浅析可提升Vivado编译效率的增量编译方法2020-12-13 7097
-
鸿蒙OpenHarmony:【常见编译问题和解决方法】2024-05-11 6313
-
C编译器错误与解决方法2026-01-22 213
-
Keil C编译器常见警告与错误信息的解决方法2012-08-20 4015
-
Keil uVision4 编译时提示 "SystemFrequency" is undefined,求解决方法2014-03-30 12964
-
编译协议栈-Stack工程出现错误的解决方法2016-03-11 4437
-
KEIL4编译时出现的错误的解决方法2017-08-14 3025
-
头文件找不到的解决方法2021-08-23 2153
-
一些RT-Studio的BSP编译不过的问题与解决方法2023-03-15 1225
-
常见gcc编译警告整理以及解决方法2017-11-14 22474
-
如何节省FPGA编译时间?2018-08-04 7550
-
有什么方法可以减少Quartus II的编译时间吗?2021-05-18 6281
-
节省编译时间系列-使用增量实现2023-09-01 1553
-
利用Tcl脚本节省编译时间2023-09-15 2198
-
Vivado那些事儿:节省编译时间系列文章2023-10-09 4683
全部0条评论

快来发表一下你的评论吧 !
