

一种简单而高效的深度CNN模型来解决图像的Efficient SR问题
人工智能
描述
导读
本文聚焦于Efficient SR。虽然目前已经提出了许多用于图像超分辨率的解决方案,但这些算法通常需要很高的功耗和内存占用。本文们提出了一个简单而有效的深度网络来有效地解决图像超分辨率问题。具体来说,作者们在ViT块上提出了一种空间自适应特征调制 (SAFM) 机制。首先在输入特征上应用 SAFM 块来动态选择具有代表性的特征表示。由于SAFM块从远程角度处理输入特征,作者进一步引入卷积通道混合器 (CCM) 来同时提取局部上下文信息并执行通道混合。大量的实验结果表明,本文方法在网络参数方面比最先进的高效SR方法(如IMDN)小3倍,计算成本更低,同时实现相当的性能。
为了减少沉重的计算负担,各种方法,包括有效的模块设计,知识蒸馏,神经架构搜索和结构重新参数化等都试图提高SR算法的效率。在这些有效的SR模型中,主要有两个优化方向:
一个方向是减少模型参数或复杂度(FLOPs)。采用轻量级策略,如递归方式,参数共享和备用卷积。虽然这些方法确实减小了模型大小,但它们通常通过增加模型的深度或宽度来补偿由共享递归模块或稀疏卷积引起的性能下降,这在执行SR重构时影响推理效率。
另一个方向是加快推理时间。后上采样是预定义输入的重要替代,这显著加快了运行时间。模型量化有效地加速了延迟并降低了能耗,特别是在边缘设备中部署算法时。结构重新参数化提高了推理阶段训练有素的模型的速度。这些方法运行速度快,但重建性能差。
作者开发了一种基于多尺度表示的特征调制机制来动态选择具有代表性的特征。由于调制机制从长远的角度处理输入特征,因此需要补充上下文信息。为此,作者提出了一种基于FMBConv的卷积信道混合器,该混频器可以同时对局部特征进行编码和混频。SAFMN网络能够在SR性能和模型复杂性之间实现更好的平衡。
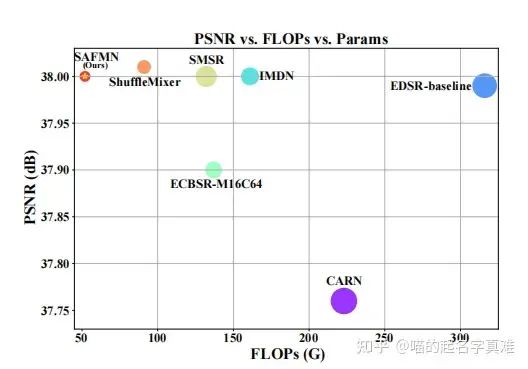
性能-效率对比图,圆圈大小表示参数的数量,PSNR是峰值信噪比
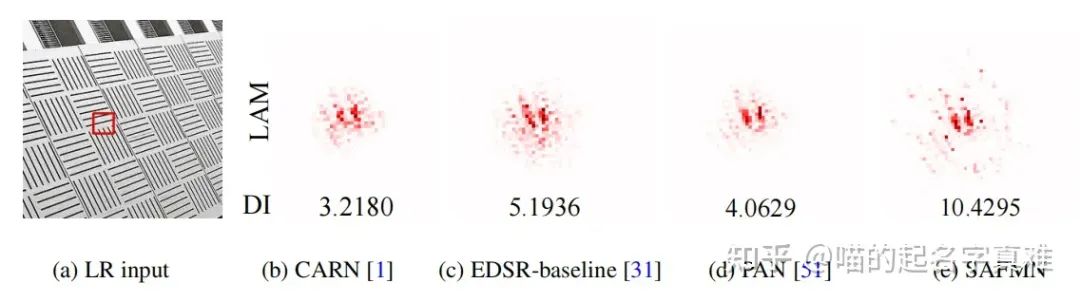
LAM结果表示在超分用红色框标记的patch时,输入的LR图像中每个像素的重要性。DI值反映了所涉及的像素的范围。DI值越大,关注范围越广。
本文方法
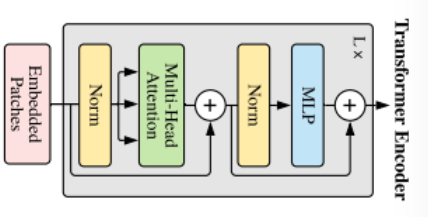
可以看到,与经典的注意力模块相比,本文主要是做了两点改进。其一是把多头注意力替换成了所提出的SAFM,其二是把MLP替换成了所提出的CCM。
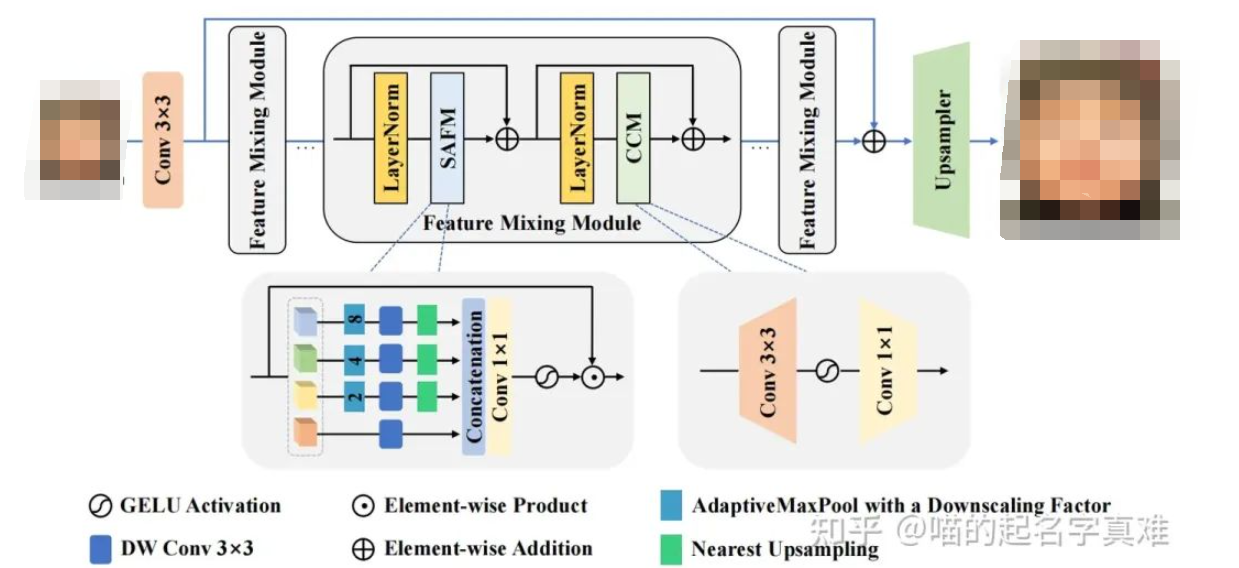
SAFMN
如上图所示,该网络由以下部分组成:特征混合模块(FMM)的堆叠层和上采样层。具体来说,作者首先应用一个3 × 3的卷积层,提取输入的LR图像的特征,生成浅层特征F0 。然后,利用多个堆叠的FMM从F0中生成更精细的深度特征,用于HR图像重建,其中每个FMM层有一个空间自适应特征调制(SAFM)子层和一个卷积通道混合器(CCM)。为了恢复HR目标图像,作者引入了一个全局残差连接来学习高频细节,并采用一个轻量级的上采样层来快速重建,该上采样层只包含一个3×3卷积和一个亚像素卷积。
作者的网络可以被定义为:
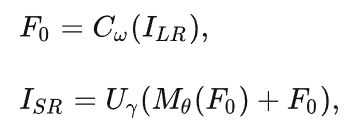
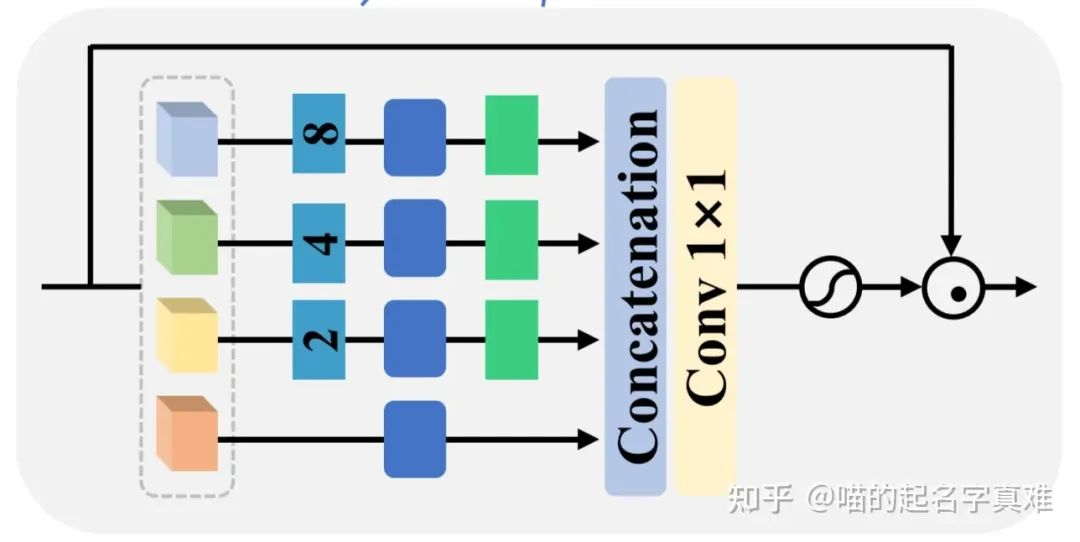
间自适应特征调制
SAFM
这一模块是本文的核心。这个模块的主要目的是实现像注意力机制中的那种全局交互,同时不会带来太大的计算代价。作者实现这一目标的方法很是新颖,通过利用多尺度特征的融合来考虑远距离的交互。
这个模块的具体流程是这样的:
首先把输入特征X按照通道维度进行拆分(torch.chunk),这样就得到了多个具有与X相同空间大小但是通道大小缩减的子特征图,在上图中就是蓝色、绿色、黄色、橙色的四个块。
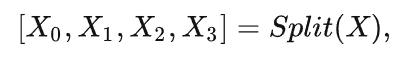
下一步就是对这4个特征图进行不同的空间下采样-上采样处理。选择一个特征图不做处理(图中的橙色),选择其他的三个特征图分别进行x2、x4、x8倍率的下采样操作。
通过上述操作,作者手头上就有了4中不同尺度的特征图,之后把它们均经过深度可分离(DW)卷积,就是上图中的深蓝色方块。由于说更小的特征图(比如x8的特征图)有着更大的感受野,因此通过相同卷积核大小的卷积后,不同尺度的特征图中的每个像素的感受野都是不同的。x8倍率的感受野最大。之后为了方便后续的通道维度拼接,作者把之前经过下采样的特征通过最近邻插值再依次上采样回来。
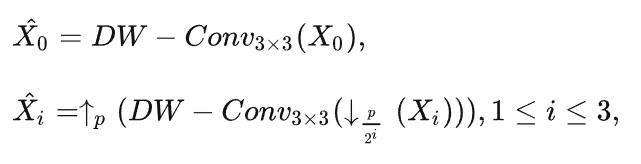

从SAFM学习到的不同尺度的深层特征
这样便可以把具有相同HW大小的特征图进行拼接了。最后跟一个1x1卷积(因为刚才4个子特征并未在通道上交互,才加上这个1x1卷积的)完成最后处理。

卷积通道混合器
SAFM子块专注于探索全局信息,而局部上下文信息也有助于高分辨率图像重建。作者提出了一种基于FMBConv的卷积信道混频器(CCM)来增强局部空间建模能力和进行信道混合。提出的CCM包含一个3 × 3卷积和一个1×1卷积。其中,第一个3×3卷积对空间局部上下文进行编码,并将混合信道的输入特征的信道数量加倍;之后的1 × 1卷积将通道减小到原来的输入维数。GELU激活函数应用于隐藏层进行非线性映射。
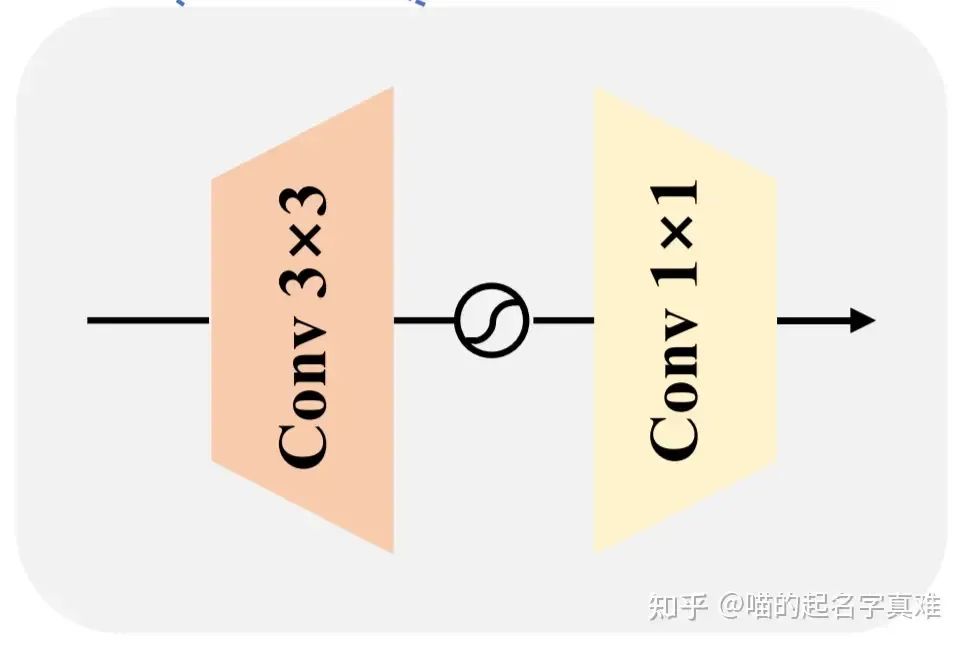
CCM
相比原始注意力机制中的MLP,这里主要是替换成了3x3卷积,同时把RELU换成了GELU。
与原始的FMBConv相比,作者进行了以下修改,使其与作者的架构更兼容:(1)移除squeeze-and-excitation(SE)块;(2)用LayerNorm 替换BatchNorm ,并将其移动到卷积之前。排除SE块主要是因为SAFM还具有对信道维度的动态效用,并且在没有SE block的情况下重建性能不会下降。此外,使用LayerNorm可以更好地稳定模型训练和获得更好的结果。
损失函数
结合平均绝对误差(mean absolute error, MAE)损失和基于FFT(快速傅里叶变换)的频率损失函数对这些参数进行优化,其定义为:

FMM
基于ViT的网络设计,包括全局特征聚合的自关注模块和细化特征的前馈网络,作者将提出的SAFM和CCM形成一个统一的特征混合模块来选择具有代表性的特征。特征混合模块可以表示为:
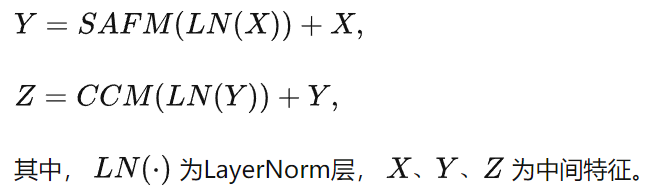
实验
评价指标
作者使用PSNR (Peak Signal-to-Noise Ratio) 峰值信噪比和SSIM (Structural SIMilarity) 结构相似性来评估恢复图像的质量。所有PSNR和SSIM值都是在变换到YCbCr颜色空间的图像的Y通道上计算的。
彩色图像通常有三种方法来计算PSNR:
分别计算 RGB 三个通道的 PSNR,然后取平均值。
计算 RGB 三通道的 MSE ,然后再除以 3 。
将图片转化为 YCbCr 格式,然后只计算 Y 分量也就是亮度分量的 PSNR。
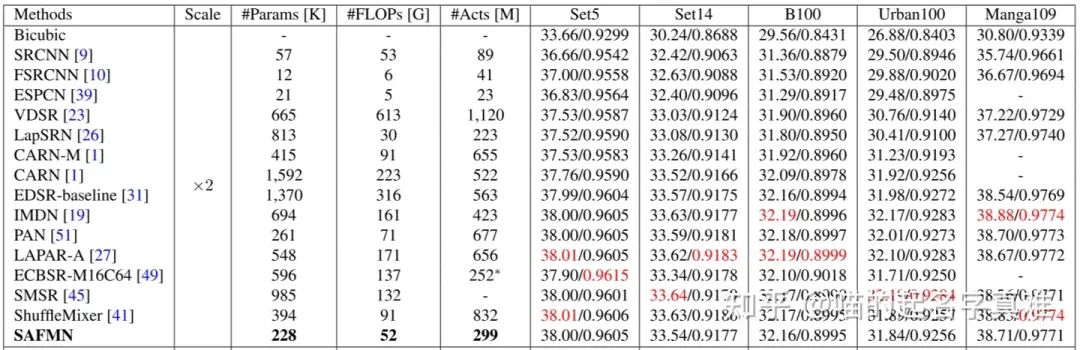
定量比较
对比试验
#Acts表示卷积层输出的所有元素。#FLOPs和#Acts测量对应于大小为1280 × 720像素的HR图像。红色表示性能最好。空白的条目表示没有报告的结果或从以前的工作中无法获得的结果。∗表示结果是通过结构重参数化技术获得的。
定性比较

上图显示了×3 sr在Urban100数据集上的视觉比较。作者的方法生成平行线和网格模式比列出的方法更准确。

内存和运行时间比较
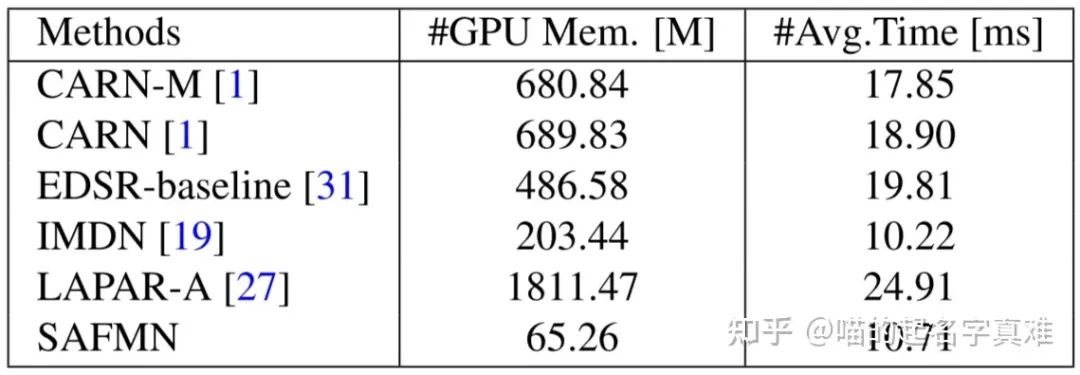
在 ×4 SR上的内存和运行时间比较。#GPU Mem.表示推断阶段期间的最大GPU内存消耗,由Pytorch torch.cuda.max memory allocated()函数导出。#Avg.Time是50张LR图像(大小为320 × 180像素)的平均运行时间。
作者进一步在GPU内存消耗(#GPU Mem.)和运行时间(#Avg.)方面对×4 SR上的5个具有代表性的方法,包括CARN- m、CARN、EDSR-baseline、IMDN和LAPAR-A进行了评估。在推理过程中记录最大GPU内存消耗。在50张具有320×180分辨率的测试图像上平均运行时间。
消融实验
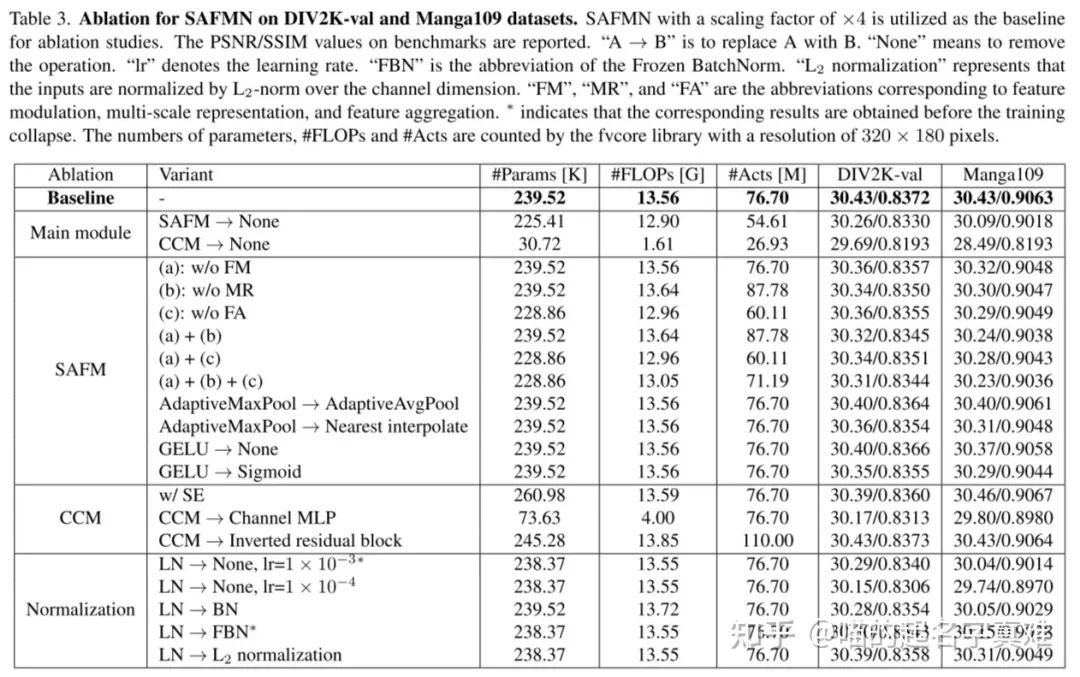
在DIV2K-val和Manga109数据集上进行SAFMN消融实验。以×4为标度因子的SAFMN作为消融研究的基线。报告基准上的PSNR/SSIM值。“None”表示删除操作。“lr”表示学习速率。“FBN”是“Frozen BatchNorm”的缩写。L2 normalization 表示输入在通道维上被L2范数归一化。“FM”、“MR”和“FA”是特征调制、多尺度表示和特征融合的缩略语。∗表示在训练坍塌之前获得了相应的结果。#Params、#FLOPs和#Acts的数量由分辨率为320 × 180像素的fvcore库计算。
总结
本文提出了一种简单而高效的深度CNN模型来解决图像的Efficient SR问题。该方法探讨了基于多尺度特征表示的调制机制的长程适应性。为了补充局部上下文信息,作者进一步开发了一种紧凑型卷积信道混合器,对空间局部上下文进行编码,同时进行信道混合。
编辑:黄飞
-
cnn常用的几个模型有哪些2024-07-11 3159
-
图像分割与语义分割中的CNN模型综述2024-07-09 3459
-
如何利用CNN实现图像识别2024-07-03 3945
-
深度神经网络模型cnn的基本概念、结构及原理2024-07-02 12862
-
一文详解CNN2023-08-18 1256
-
什么是深度学习?使用FPGA进行深度学习的好处?2023-02-17 2171
-
探索一种降低ViT模型训练成本的方法2022-11-24 1554
-
讨论纹理分析在图像分类中的重要性及其在深度学习中使用纹理分析2022-10-26 2935
-
Github开源的数字手势识别CNN模型简析2022-04-02 5407
-
一种基于多通道极深CNN的图像超分辨算法2021-03-23 1410
-
基于多孔卷积神经网络的图像深度估计模型2020-09-29 1263
-
如何使用平稳小波域深度残差CNN进行低剂量CT图像估计2018-12-19 1672
-
一种利用强化学习来设计mobile CNN模型的自动神经结构搜索方法2018-08-07 5029
-
一种深度信息的图像修复算法2018-01-03 732
全部0条评论

快来发表一下你的评论吧 !
