

超星未来NE100开箱体验,15分钟部署目标检测模型
描述
「NE100」是超星未来基于自研计算芯片「惊蛰R1」和全流程开发工具链「鲁班」打造的智能计算平台开发套件,包括完备的推理环境。其中鲁班工具链以 docker 形式提供,完整包括剪枝、量化、编译工具以及相应实例。NE100 配套完整,开箱即用,无需繁琐的安装过程。
下面以目标检测模型 YOLOv5 为例,展示部署过程。
注:开发环境为 Linux 系统的 PC 或服务器,神经网络需要导出为 ONNX 格式文件。
可通过标准命令加载工具链 docker 文件:
gunzip -c nova_development_kit.tar.gz | sudo docker load
参考用户手册中示例脚本启动容器,进入开发环境。
基于原始模型导出 ONNX 文件时,请确保网络已经处于推理模式,并且计算图的输入节点为首个 CONV 算子的输入(格式[1,C,H,W]),输出节点为最后一个(组)CONV 算子的输出,详细信息请参考用户手册。
#1 模型量化与编译
1个API,5行代码,轻松完成
量化工具以 ONNX 文件和部分图片为输入,将神经网络从 FP32 量化为 INT8 精度,目前支持 PTQ 与 QAT 功能。仅需在代码中将量化和编译工具导入并通过 API 调用,即可对 ONNX 模型完成量化和编译,分别只需要1个 API 和5行代码。详细的 API 说明请参考用户手册。
1. 导入量化工具
from nquantizer import run_quantizer
2. 调用量化工具
quant_model = run_quantizer(
onnx_model,
dataloader=val_loader,
num_batches=200,
output_dir=work_dir + "/quantizer_output",
input_vars=input_vars,
3. 导入编译工具
from ncompiler import run_compiler
4. 调用编译工具
run_compiler(
input_dir=work_dir + "/quantizer_output",
output_dir=work_dir + "/compiler_output",
enable_simulator=True,
enable_profiler=True,
)
编译后 compiler_output 目录中的 npu.param(模型结构描述文件)和 npu.bin(模型权重文件)是 NE100 部署时所需要的文件。

#2 模型部署
接口简洁,功能丰富,快速调用NPU
为了实现 惊蛰R1 芯片多核 NPU 的简单高效推理与应用开发,超星未来基于 NCNN 推理框架增量开发运行时,并提供高性能加速库,满足异构推理的端到端优化需求。
运行时特别设计了 npumat, npunet 和 npuextractor 等组件,功能如下:
npumat:提供NPU使用的数据排布格式HWC,提高数据存储读取性能
npunet:提供模型不变信息的基础数据结构,支持核心绑定、优先级调度、数据导出、性能监测等功能
npuextractor:提供NPU推理所需的set_input, get_output, get_time、extract等基本功能
YOLOv5 推理中前后处理部分与主流平台上的代码一致,应用迁移时仅需更换 NPU 的推理代码,包括:
1. 初始化帧数据结构
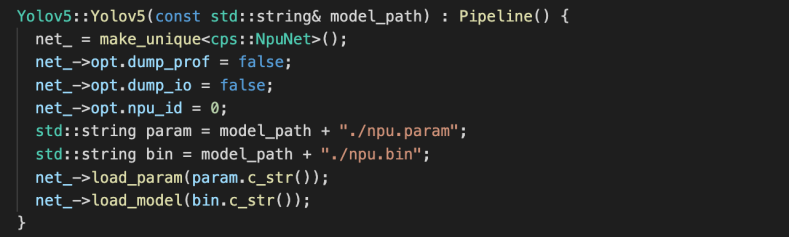
2. 加载网络结构描述文件与网络权重文件,并且配置核心绑定、数据导出及性能监测等功能
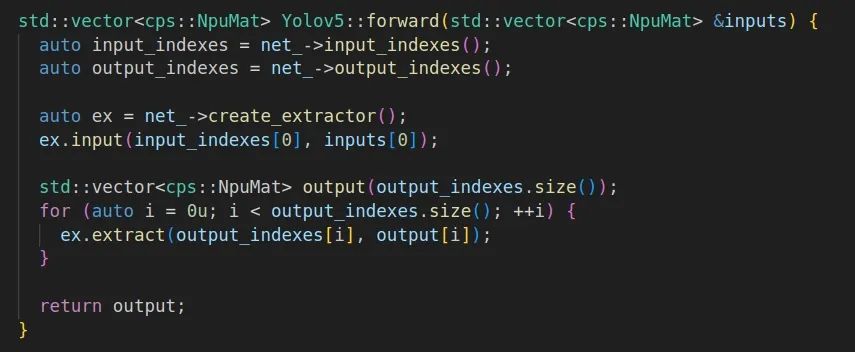
3. 基于加载的模型文件和前处理后的帧数据进行推理,提取结果用于后处理
#3 模型推理
架构高效,能耗出色,助力AI应用落地
推理代码经过编译后运行,即可得到如下推理结果:
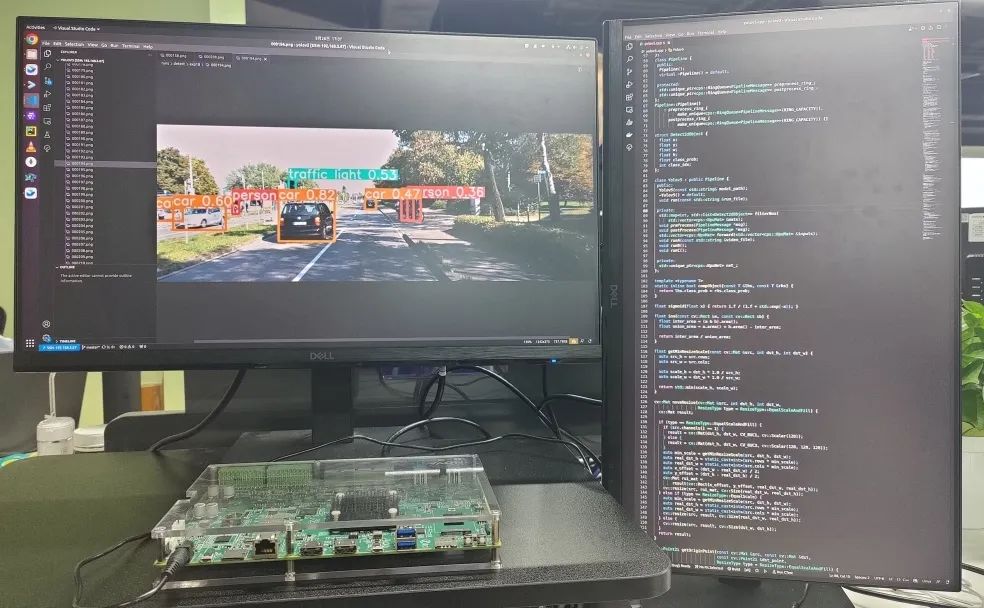
得益于超星未来自研平湖架构的高效设计,YOLOv5 等主流网络的算力利用率均超过 70%,同时芯片整体功耗可控制在 8W 左右,有效支持各类边缘端 AI 应用部署。
-
AI模型部署边缘设备的奇妙之旅:目标检测模型2024-12-19 2767
-
【小e物联网试用体验】+ 超清开箱体验2016-05-17 3561
-
【NanoPi NEO试用体验】开箱体验2016-10-31 4207
-
【VEML6040环境颜色检测试用体验】一、开箱体验,惊喜有余2017-03-27 3264
-
15分钟充满快充移动电源---未来的潜力有多大?2017-06-16 3532
-
目标检测模型和Objectness的基础知识2021-02-04 1459
-
在Arm虚拟硬件上部署PP-PicoDet模型2022-09-16 3523
-
在Arm虚拟硬件上部署PP-PicoDet模型的设计方案2022-09-23 4221
-
高通公布新型快速充电技术,15分钟内将4500mAh电池充满100%2020-07-28 1439
-
目标检测模型和Objectness的知识2022-02-12 1843
-
如何在移动设备上训练和部署自定义目标检测模型2021-08-16 4826
-
YOLOX目标检测模型的推理部署2022-04-16 5493
-
AI爱克斯开发板上使用OpenVINO加速YOLOv8目标检测模型2023-05-26 2956
-
本周九家企业获新融资,超星未来与纵慧芯光领先2024-05-13 1619
-
超星未来惊蛰R1芯片适配DeepSeek-R1模型2025-02-13 1550
全部0条评论

快来发表一下你的评论吧 !
