

ICCV 2023 | 超越SAM!EntitySeg:更少的数据,更高的分割质量
描述
稠密图像分割问题一直在计算机视觉领域中备受关注。无论是在 Adobe 旗下的 Photoshop 等重要产品中,还是其他实际应用场景中,分割模型的泛化和精度都被赋予了极高的期望。对于这些分割模型来说,需要在不同的图像领域、新的物体类别以及各种图像分辨率和质量下都能够保持鲁棒性。为了解决这个问题,早在 SAM[6] 模型一年之前,一种不考虑类别的实体分割任务 [1] 被提出,作为评估模型泛化能力的一种统一标准。
在本文中,High-Quality Entity Segmentation 对分割问题进行了全新的探索,从以下三个方面取得了显著的改进:
1. 更优的分割质量:正如上图所示,EntitySeg 在数值指标和视觉表现方面都相对于 SAM 有更大的优势。令人惊讶的是,这种优势是基于仅占训练数据量千分之一的数据训练取得的。
2. 更少的高质量数据需求:相较于 SAM 使用的千万级别的训练数据集,EntitySeg 数据集仅含有 33,227 张图像。尽管数据量相差千倍,但 EntitySeg 却取得了可媲美的性能,这要归功于其标注质量,为模型提供了更高质量的数据支持。
3. 更一致的输出细粒度(基于实体标准):从输出的分割图中,我们可以清晰地看到 SAM 输出了不同粒度的结果,包括细节、部分和整体(如瓶子的盖子、商标、瓶身)。然而,由于 SAM 需要对不同部分的人工干预处理,这对于自动化输出分割的应用而言并不理想。相比之下,EntitySeg 的输出在粒度上更加一致,并且能够输出类别标签,对于后续任务更加友好。
在阐述了这项工作对稠密分割技术的新突破后,接下来的内容中介绍 EntitySeg 数据集的特点以及提出的算法 CropFormer。

代码链接:
https://github.com/qqlu/Entity/blob/main/Entityv2/README.md主页链接:
http://luqi.info/entityv2.github.io/根据 Marr 计算机视觉教科书中的理论,人类的识别系统是无类别的。即使对于一些不熟悉的实体,我们也能够根据相似性进行识别。因此,不考虑类别的实体分割更贴近人类识别系统,不仅可以作为一种更基础的任务,还可以辅助于带有类别分割任务 [2]、开放词汇分割任务 [3] 甚至图像编辑任务 [4]。与全景分割任务相比,实体分割将“thing”和“stuff”这两个大类进行了统一,更加符合人类最基本的识别方式。

EntitySeg数据集
由于缺乏现有的实体分割数据,作者在其工作 [1] 使用了现有的 COCO、ADE20K 以及 Cityscapes 全景分割数据集验证了实体任务下模型的泛化能力。然而,这些数据本身是在有类别标签的体系下标注的(先建立一个类别库,在图片中搜寻相关的类别进行定位标注),这种标注过程并不符合实体分割任务的初衷——图像中每一个区域均是有效的,哪怕这些区域无法用言语来形容或者被 Blur 掉,都应该被定位标注。此外,受限于提出年代的设备,COCO 等数据集的图片域以及图片分辨率也相对单一。因此基于现有数据集下训练出的实体分割模型也并不能很好地体现实体分割任务所带来的泛化能力。最后,原作者团队在提出实体分割任务的概念后进一步贡献了高质量细粒度实体分割数据集 EntitySeg 及其对应方法。EntitySeg 数据集是由 Adobe 公司 19 万美元赞助标注完成,已经开源贡献给学术界使用。
项目主页:
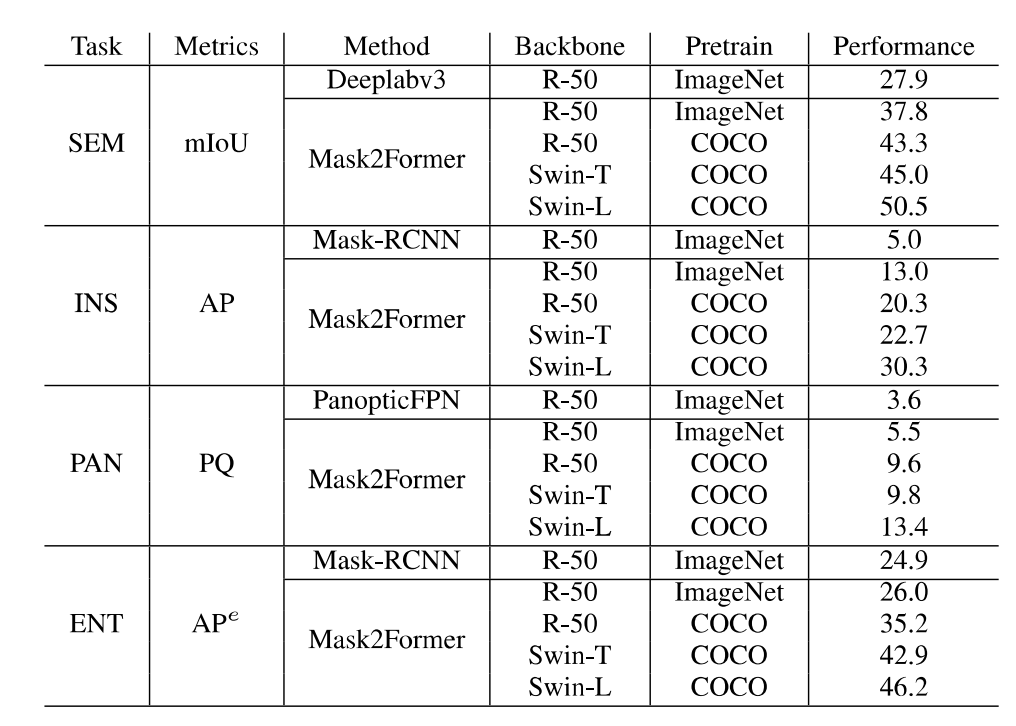
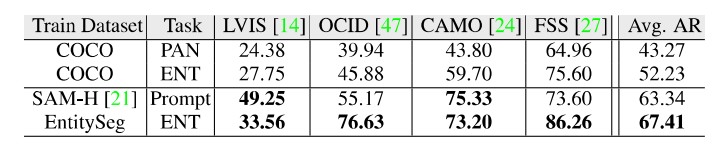
http://luqi.info/entityv2.github.io/数据集有三个重要特性:1. 数据集汇集了来自公开数据集和学术网络的 33,227 张图片。这些图片涵盖了不同的领域,包括风景、室内外场景、卡通画、简笔画、电脑游戏和遥感场景等。2. 标注过程在无类别限制下进行的掩膜标注,并且可以覆盖整幅图像。3. 图片分辨率更高,标注更精细。如上图所示,即使相比 COCO 和 ADE20K 数据集的原始低分辨率图片及其标注,EntitySeg 的实体标注更全且更精细。最后,为了让 EntitySeg 数据集更好地服务于学术界,11580 张图片在标注实体掩膜之后,以开放标签的形式共标注了 643 个类别。EntitySeg、COCO 以及 ADE20K 数据集的统计特性对比如下: 通过和 COCO 以及 ADE20K 的数据对比,可以看出 EntitySeg 数据集图片分辨率更高(平均图片尺寸 2700)、实体数量更多(每张图平均 18.1 个实体)、掩膜标注更为复杂(实体平均复杂度 0.719)。极限情况下,EntitySeg 的图片尺寸可达到 10000 以上。 与 SAM 数据集不同,EntitySeg 更加强调小而精,试图做到对图片中的每个实体得到最为精细的边缘标注。此外,EntitySeg 保留了图片和对应标注的原始尺寸,更有利于高分辨率分割模型的学术探索。 基于 EntitySeg 数据集,作者衡量了现有分割模型在不同分割任务(无类别实体分割,语义分割,实例分割以及全景分割)的性能以及和 SAM 在 zero-shot 实体级别的分割能力。
通过和 COCO 以及 ADE20K 的数据对比,可以看出 EntitySeg 数据集图片分辨率更高(平均图片尺寸 2700)、实体数量更多(每张图平均 18.1 个实体)、掩膜标注更为复杂(实体平均复杂度 0.719)。极限情况下,EntitySeg 的图片尺寸可达到 10000 以上。 与 SAM 数据集不同,EntitySeg 更加强调小而精,试图做到对图片中的每个实体得到最为精细的边缘标注。此外,EntitySeg 保留了图片和对应标注的原始尺寸,更有利于高分辨率分割模型的学术探索。 基于 EntitySeg 数据集,作者衡量了现有分割模型在不同分割任务(无类别实体分割,语义分割,实例分割以及全景分割)的性能以及和 SAM 在 zero-shot 实体级别的分割能力。

CropFormer算法框架
除此之外,高分辨率图片和精细化掩膜给分割任务带来了新的挑战。为了节省硬件内存需求,分割模型需要压缩高分辨率图片及标注进行训练和测试进而导致分割质量的降低。为了解决这一问题,作者提出了 CropFormer 框架来解决高分辨率图片分割问题。CropFormer 受到 Video-Mask2Former [5] 的启发, 利用一组 query 连结压缩为低分辨率的全图和保持高分辨率的裁剪图的相同实体。因此,CropFormer 可以同时保证图片全局和区域细节属性。CropFormer 是根据 EntitySeg 高质量数据集的特点提出的针对高分辨率图像的实例/实体分割任务的 baseline 方法,更加迎合当前时代图片质量的需求。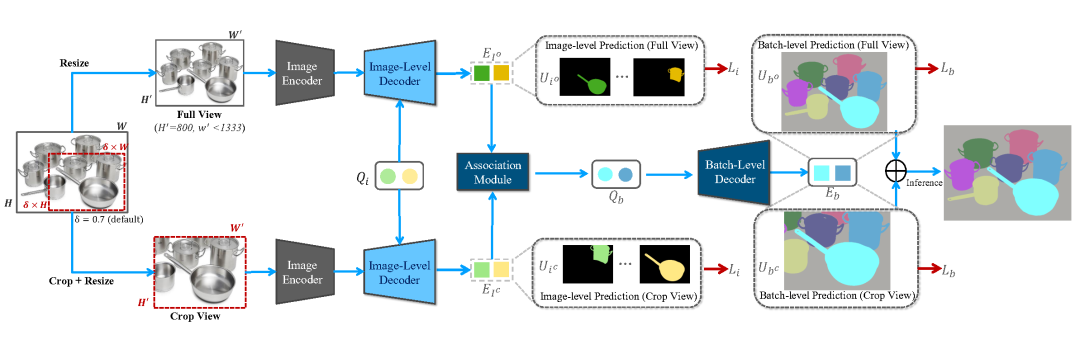
最后在补充材料中,作者展示了更多的 EntitySeg 数据集以及 CropFormer 的可视化结果。下图为更多数据标注展示:
下图为 CropFormer 模型测试结果:
参考文献
[1] Open-World Entity Segmentation. TAPMI 2022.[2] CA-SSL: Class-agnostic Semi-Supervised Learning for Detection and Segmentation. ECCV 2022.[3] Open-Vocabulary Panoptic Segmentation with MaskCLIP. ICML 2023.[4] SceneComposer: Any-Level Semantic Image Synthesis. CVPR 2023.[5] Masked-attention Mask Transformer for Universal Image Segmentation. CVPR 2022.[6] Segment Anything. ICCV 2023.
原文标题:ICCV 2023 | 超越SAM!EntitySeg:更少的数据,更高的分割质量
文章出处:【微信公众号:智能感知与物联网技术研究所】欢迎添加关注!文章转载请注明出处。
- 相关推荐
- 热点推荐
- �
-
【爱芯派 Pro 开发板试用体验】+ 图像分割和填充的Demo测试2023-12-26 2181
-
厉害了!ICCV 2019投稿数量翻倍!2019-03-29 8315
-
商汤科技57篇论文入选ICCV 2019,13项竞赛夺冠2019-10-30 720
-
SAM-Adapter:首次让SAM在下游任务适应调优!2023-04-20 2566
-
SAM分割模型是什么?2023-05-20 3971
-
SAM 到底是什么2023-06-12 9165
-
YOLOv8最新版本支持SAM分割一切2023-06-18 2773
-
SA-1B数据集的1/50进行训练现有的实例分割方法2023-06-28 7027
-
基于SAM设计的自动化遥感图像实例分割方法2023-07-04 2488
-
基于 Transformer 的分割与检测方法2023-07-05 2295
-
ICCV 2023生成式AI引人瞩目,商汤多项技术突破展现中国“创新力”2023-10-04 1783
-
ICCV 2023 | 面向视觉-语言导航的实体-标志物对齐自适应预训练方法2023-10-23 2330
-
一种新的分割模型Stable-SAM2023-12-29 1817
-
传音TEX AI团队斩获ICCV 2025大型视频目标分割挑战赛双料亚军2025-10-31 872
-
SAM(通用图像分割基础模型)丨基于BM1684X模型部署指南2026-01-12 638
全部0条评论

快来发表一下你的评论吧 !
