

NeurIPS 2023 | 扩散模型解决多任务强化学习问题
描述
扩散模型(diffusion model)在 CV 领域甚至 NLP 领域都已经有了令人印象深刻的表现。最近的一些工作开始将 diffusion model 用于强化学习(RL)中来解决序列决策问题,它们主要利用 diffusion model 来建模分布复杂的轨迹或提高策略的表达性。
但是, 这些工作仍然局限于单一任务单一数据集,无法得到能同时解决多种任务的通用智能体。那么,diffusion model 能否解决多任务强化学习问题呢?我们最近提出的一篇新工作——“Diffusion Model is an Effective Planner and Data Synthesizer for Multi-Task Reinforcement Learning”,旨在解决这个问题并希望启发后续通用决策智能的研究:

论文链接:
https://arxiv.org/abs/2305.18459

背景
数据驱动的大模型在 CV 和 NLP 领域已经获得巨大成功,我们认为这背后源于模型的强表达性和数据集的多样性和广泛性。基于此,我们将最近出圈的生成式扩散模型(diffusion model)扩展到多任务强化学习领域(multi-task reinforcement learning),利用 large-scale 的离线多任务数据集训练得到通用智能体。 目前解决多任务强化学习的工作大多基于 Transformer 架构,它们通常对模型的规模,数据集的质量都有很高的要求,这对于实际训练来说是代价高昂的。基于 TD-learning 的强化学习方法则常常面临 distribution-shift 的挑战,在多任务数据集下这个问题尤甚,而我们将序列决策过程建模成条件式生成问题(conditional generative process),通过最大化 likelihood 来学习,有效避免了 distribution shift 的问题。

方法
具体来说,我们发现 diffusion model 不仅能很好地输出 action 进行实时决策,同样能够建模完整的(s,a,r,s')的 transition 来生成数据进行数据增强提升强化学习策略的性能,具体框架如图所示:
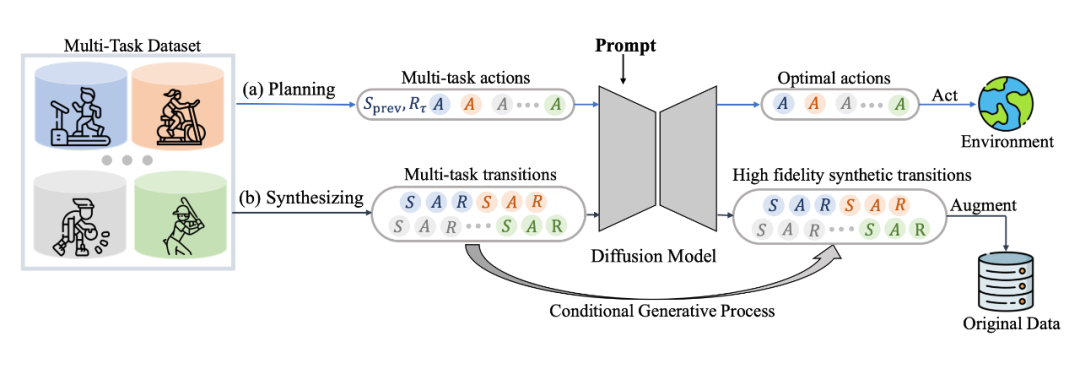
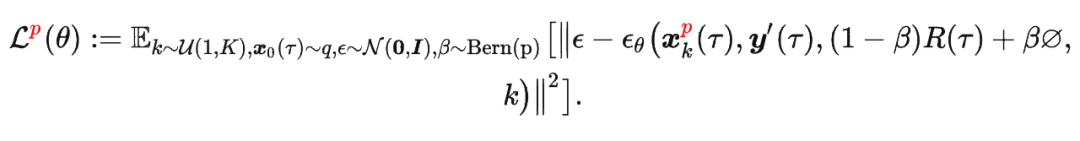 其中
其中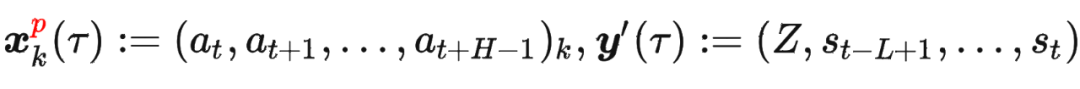 是轨迹的标准化累积回报, 是 Demonstration Prompt,可以表示为:
是轨迹的标准化累积回报, 是 Demonstration Prompt,可以表示为:

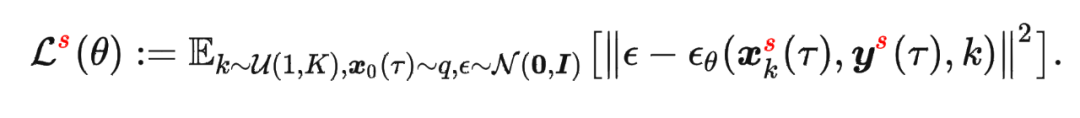 其中
其中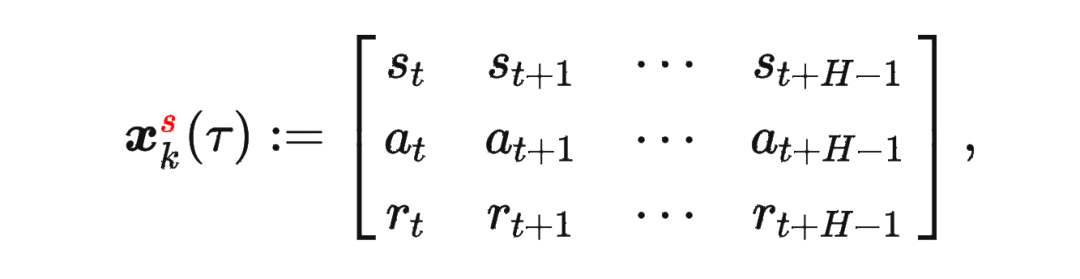
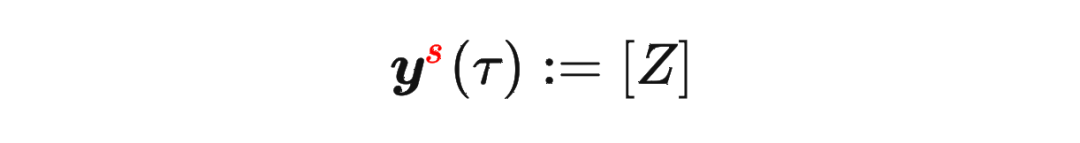

模型结构
为了更好地建模多任务数据,并且统一多样化的输入数据,我们用 transformer 架构替换了传统的 U-Net 网络,网络结构图如下:
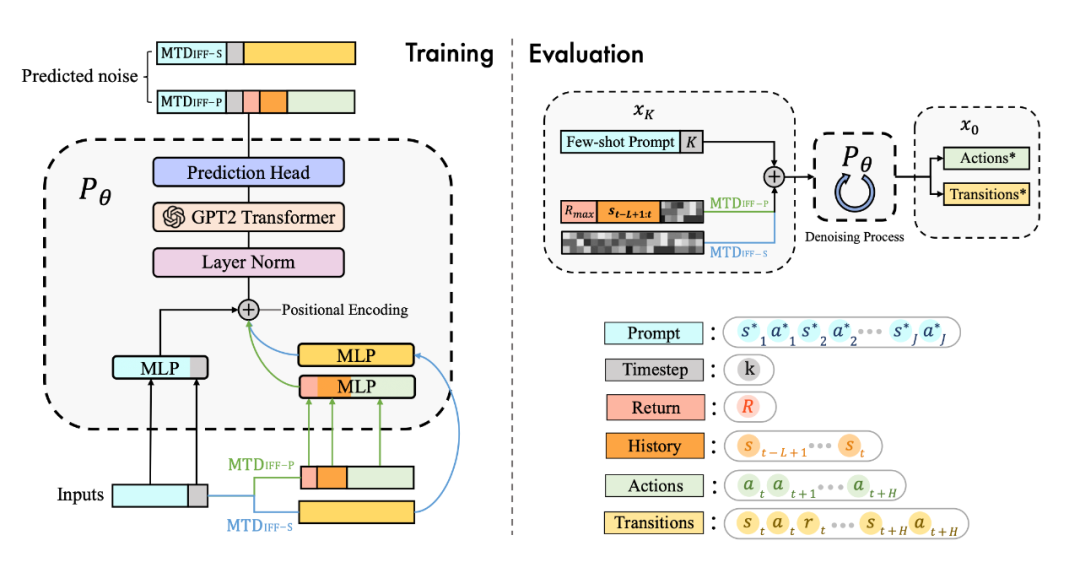

实验
我们首先在 Meta-World MT50 上开展实验并与 baselines 进行比较,我们在两种数据集上进行实验,分别是包含大量专家数据,从 SAC-single-agent 中的 replay buffer 中收集到的 Near-optimal data(100M);以及从 Near-optimal data 中降采样得到基本不包含专家数据的 Sub-optimal data(50M)。实验结果如下:
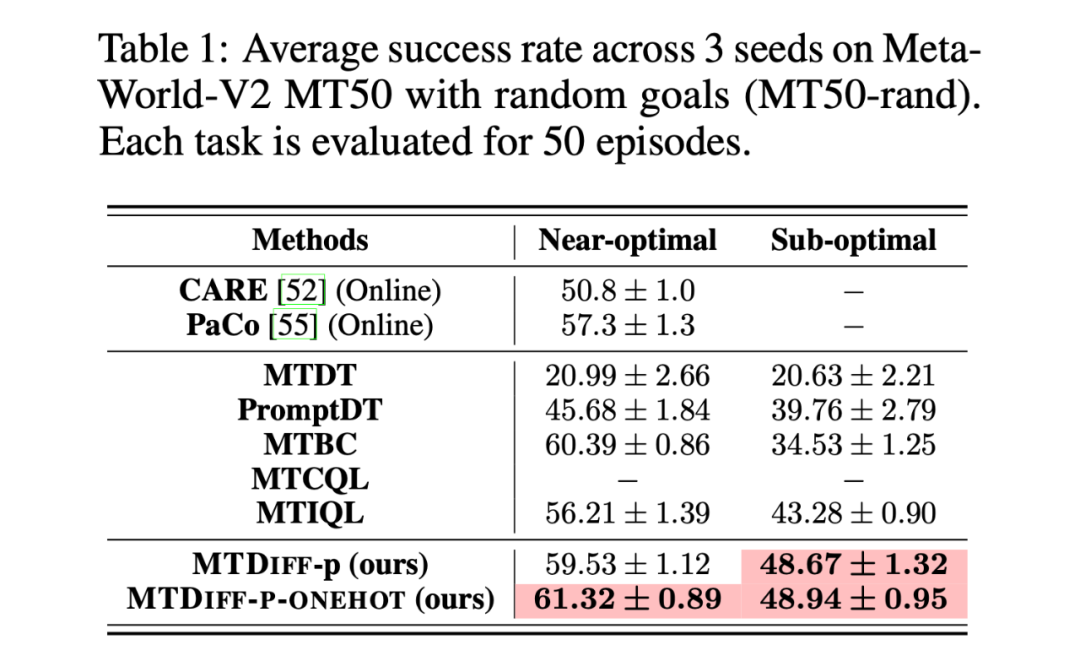
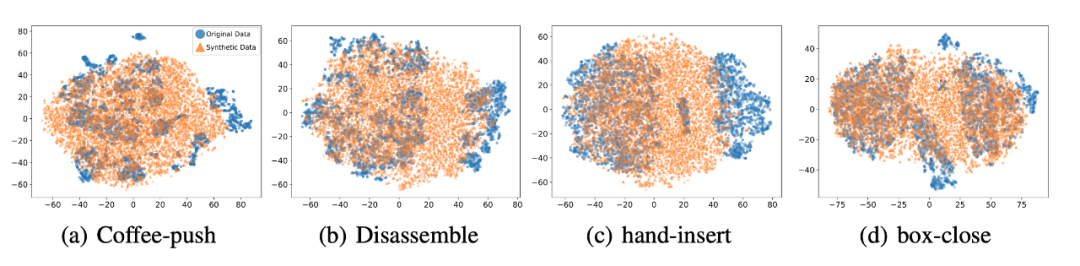
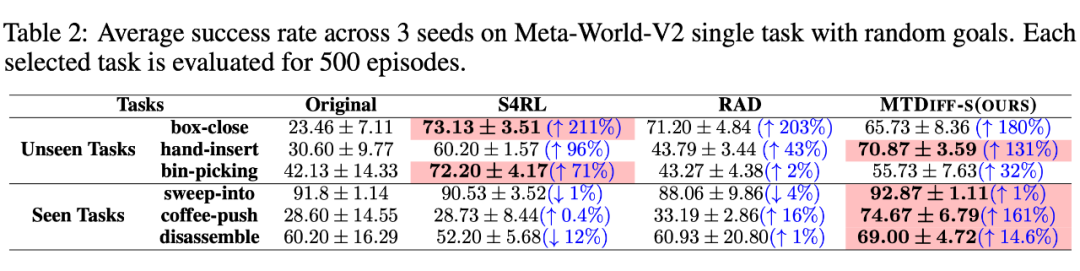 我们选取 45 个任务的 Near-optimal data 训练 ,从表中我们可以观察到在 见过的任务上,我们的方法均取得了最好的性能。甚至给定一段 demonstration prompt, 能泛化到没见过的任务上并取得较好的表现。我们选取四个任务对原数据和 生成的数据做 T-SNE 可视化分析,发现我们生成的数据的分布基本匹配原数据分布,并且在不偏离的基础上扩展了分布,使数据覆盖更加全面。
我们选取 45 个任务的 Near-optimal data 训练 ,从表中我们可以观察到在 见过的任务上,我们的方法均取得了最好的性能。甚至给定一段 demonstration prompt, 能泛化到没见过的任务上并取得较好的表现。我们选取四个任务对原数据和 生成的数据做 T-SNE 可视化分析,发现我们生成的数据的分布基本匹配原数据分布,并且在不偏离的基础上扩展了分布,使数据覆盖更加全面。

总结
我们提出了一种基于扩散模型(diffusion model)的一种新的、通用性强的多任务强化学习解决方案,它不仅可以通过单个模型高效完成多任务决策,而且可以对原数据集进行增强,从而提升各种离线算法的性能。我们未来将把 迁移到更加多样、更加通用的场景,旨在深入挖掘其出色的生成能力和数据建模能力,解决更加困难的任务。同时,我们会将 迁移到真实控制场景,并尝试优化其推理速度以适应某些需要高频控制的任务。
原文标题:NeurIPS 2023 | 扩散模型解决多任务强化学习问题
文章出处:【微信公众号:智能感知与物联网技术研究所】欢迎添加关注!文章转载请注明出处。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
- 相关推荐
- 热点推荐
- 物联网
-
反向强化学习的思路2019-04-03 2485
-
深度强化学习实战2021-01-10 2952
-
强化学习在RoboCup带球任务中的应用刘飞2017-03-14 1249
-
将深度学习和强化学习相结合的深度强化学习DRL2018-06-29 28850
-
用PopArt进行多任务深度强化学习2018-09-16 6574
-
如何构建强化学习模型来训练无人车算法2018-11-12 5725
-
谷歌、DeepMind重磅推出PlaNet 强化学习新突破2019-02-17 4205
-
强化学习在智能对话上的应用介绍2020-12-10 1814
-
机器学习中的无模型强化学习算法及研究综述2021-04-08 1419
-
模型化深度强化学习应用研究综述2021-04-12 1336
-
使用Isaac Gym 来强化学习mycobot 抓取任务2023-04-11 10116
-
什么是深度强化学习?深度强化学习算法应用分析2023-07-01 2314
-
语言模型做先验,统一强化学习智能体,DeepMind选择走这条通用AI之路2023-07-24 1567
-
什么是强化学习2023-10-30 5911
-
强化学习会让自动驾驶模型学习更快吗?2026-01-31 989
全部0条评论

快来发表一下你的评论吧 !
