

深度解析三星内存处理技术(PIM)
存储技术
描述
在2023年的Hot Chips大会上,三星介绍了内存处理技术(PIM),并介绍了新的研究和发展成果,三星将这项技术放在了人工智能的背景下进行了展示。
● CPU计算-提高速度
在Hot Chips 2023上,三星展示了内存技术,内存的主要成本是将数据从各种存储和内存位置传输到实际的计算引擎。

三星正在尝试为不同类型的内存添加更多通道或通路,但这种方法存在一定的局限性。
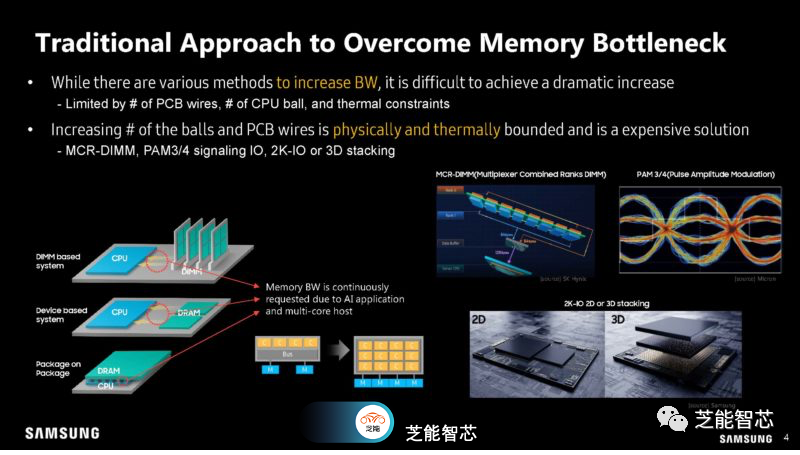
正在研究CXL技术非常有帮助,允许重新配置PCIe线路的用途,提供更大的内存带宽。

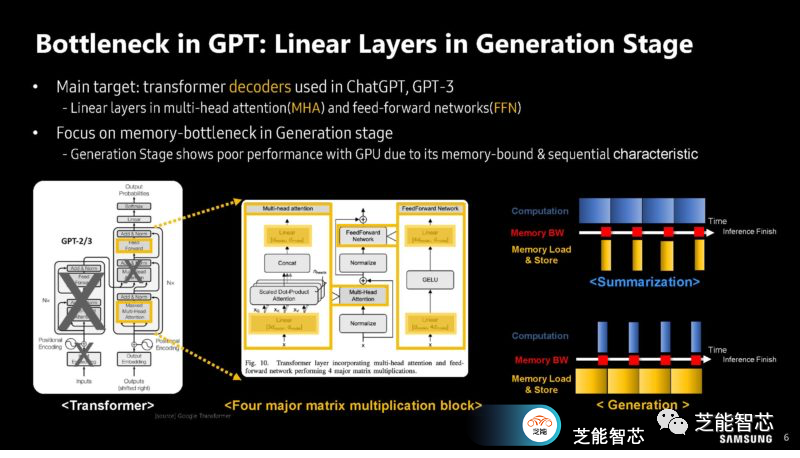
GPT的瓶颈问题,主要围绕计算溢出和内存限制工作负载进行了分析。
主要目标:ChatGPT中使用的Transformer模型,GPT-3中的线性层,以及多头注意力(MHA)和前馈网络(FFN)中的线性层。
关注生成阶段中的内存瓶颈 - 由于其内存限制和顺序特性,生成阶段在GPU上表现出较差的性能。
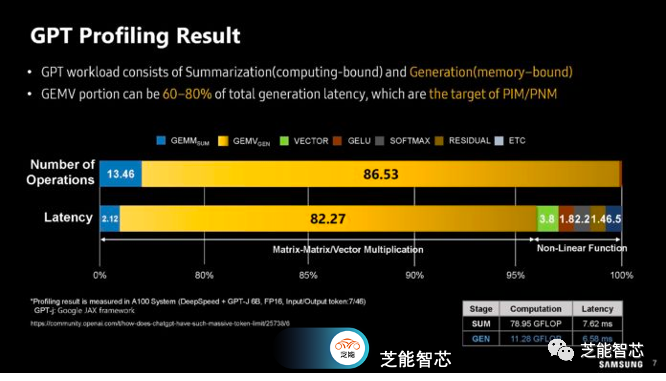
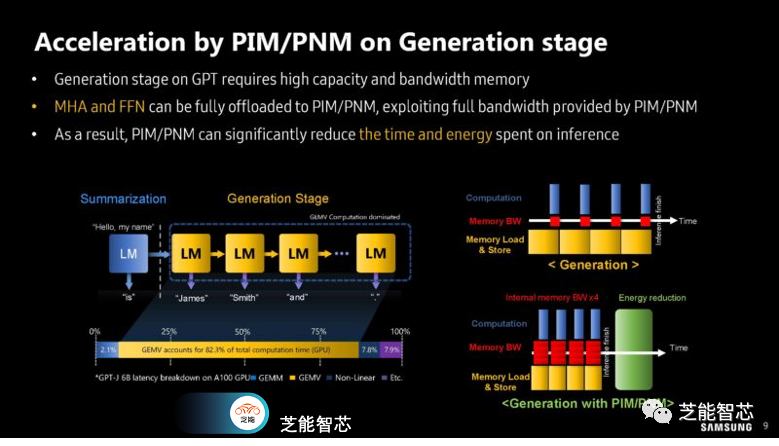
GPT的工作负载包括摘要生成(计算密集型)和文本生成(内存密集型)部分。GEMV(Generalized Matrix-Vector Multiplication)部分可能占据总生成延迟的60-80%,这正是PIM/PNM的优化目标。
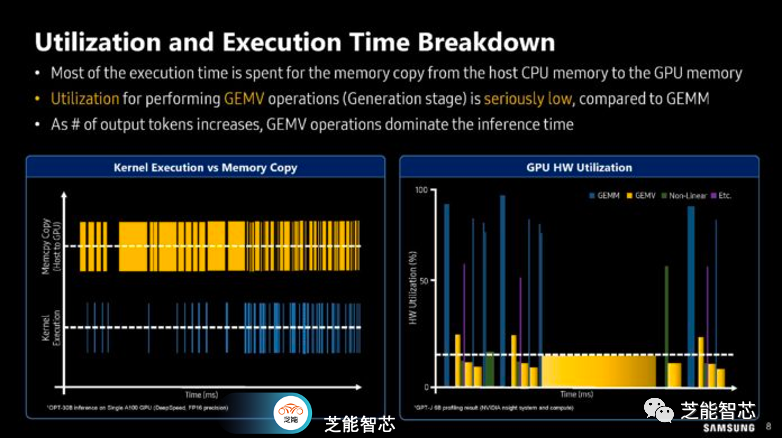
接下来的分析侧重于利用率和执行时间等方面的工作,大部分执行时间都用于从主机CPU内存到GPU内存的内存复制操作。与GEMV(Generation阶段的Generalized Matrix-Vector Multiplication)相比,执行GEMV操作的利用率非常低。随着输出标记数的增加,GEMV操作在推理时间中占据主导地位。
三星展示了如何将部分计算管道卸载到内存处理(PIM)模块上。这种处理方式可以节省数据传输到CPU或xPU的成本,降低功耗。GPT的生成阶段需要高容量和高带宽的内存。多头自注意力(MHA)和前馈网络(FFN)可以完全卸载到PIM/PNM上,充分利用PIM/PNM提供的全部带宽。PIM/PNM可以显著减少推理过程中花费的时间和能源。
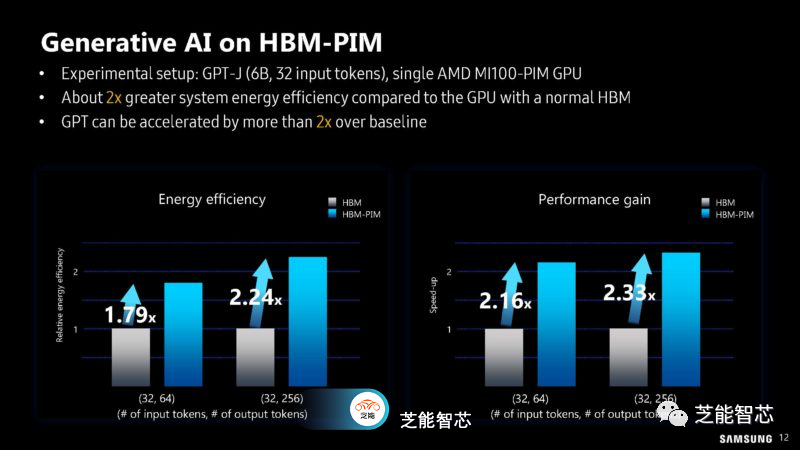
在提到内存方面,三星展示了他们的高带宽内存HBM-PIM,与之不同的是,AMD的MI100使用的是标准的PIM。三星和AMD的MI100都采用了HBM-PIM,而不仅仅是标准PIM,这样就可以构建一个集群,听起来就像是由12个节点和8个加速器组成的集群,用于尝试新的内存技术。

T5-MoE模型在集群中如何使用HBM-PIM,以及性能和能源效率的提升。

让PIM模块发挥实际作用还需要软件进行编程和利用。三星希望能够将这一功能内置到标准编程模块中。


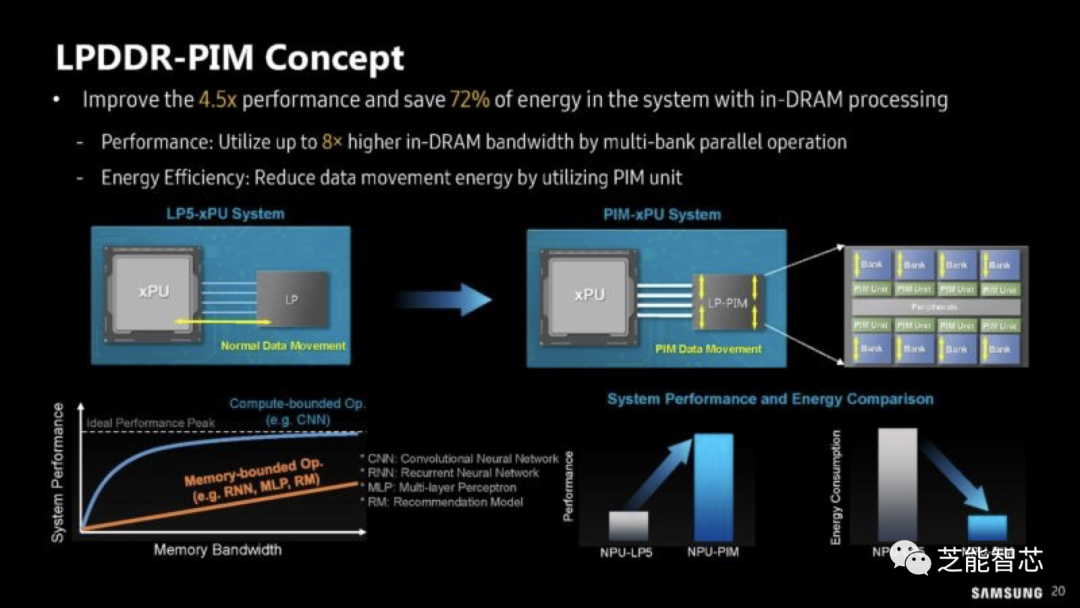
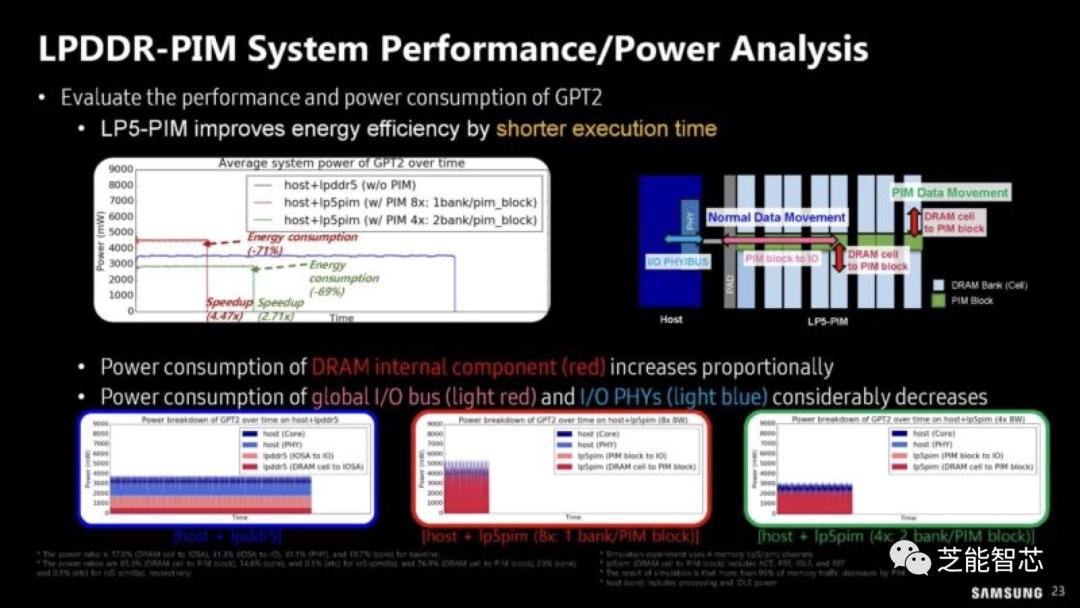
LPDDR-PIM这种新技术内部带宽仅为102.4GB/s,设计理念是将计算保持在内存模块上,从而避免将数据传输回CPU或xPU,从而降低功耗。LP5-PIM模块的性能和功耗分析。

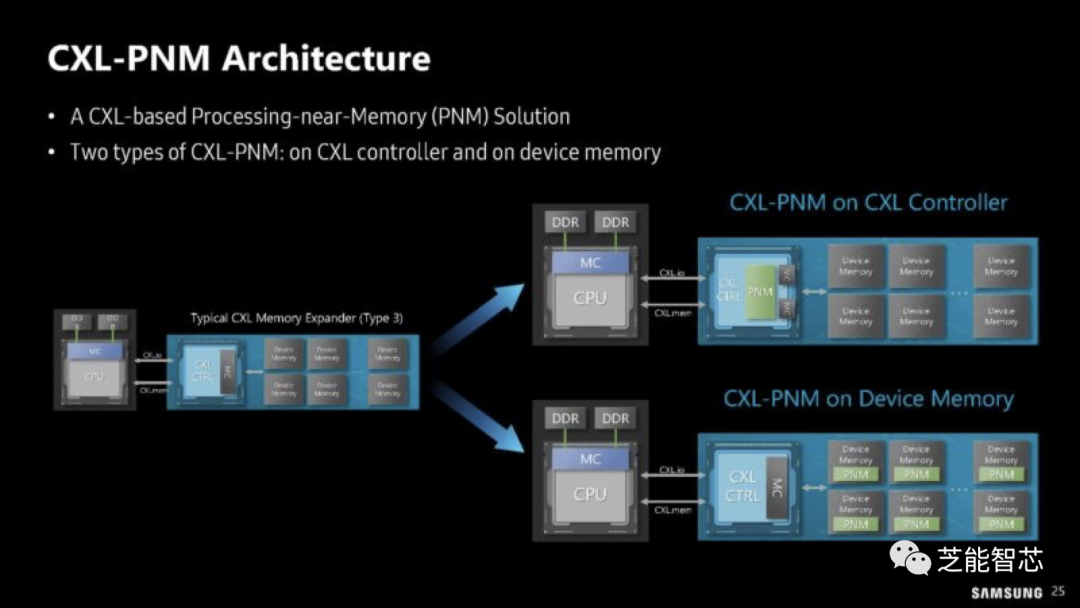
如果HBM-PIM和LPDDR-PIM还不够,三星正在考虑将计算放到CXL模块中的PNM-CXL。这并不仅仅是将内存放在CXL Type-3模块上,而是将计算放在CXL模块上。

这可以通过向CXL模块添加计算元件,并使用标准内存或在模块上使用PIM和更标准的CXL控制器来实现。最新推出的是一款概念型的512GB CXL-PNM卡,带宽高达1.1TB/s。

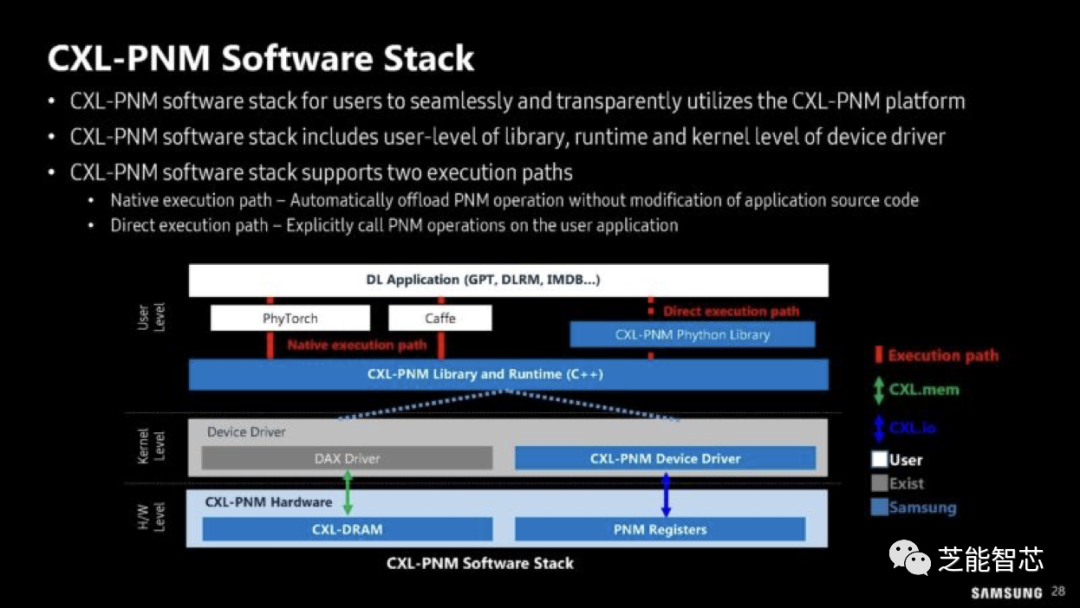
这是三星提出的CXL-PNM软件堆栈。
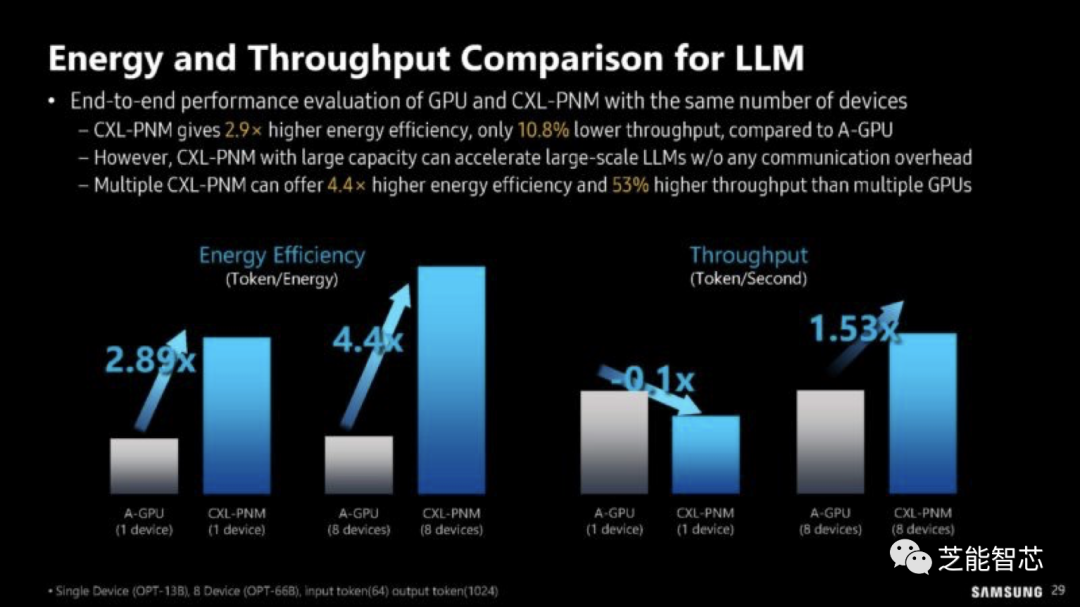
该技术对于大规模的LLM工作负载能够带来预期中的节能和吞吐量提升。CXL通常使用用于PCIe的电线进行传输数据,因此传输数据的能源成本非常高。因此,避免数据传输将会带来巨大的好处。
由于这个原因,三星非常重视减少碳排放。

三星多年来一直在推动PIM技术,现在已经不仅仅是在研究阶段,而是希望将其商业化。希望未来我们能看到更多类似的进展。CXL-PNM最终可能成为这类计算技术的一个成熟领域。
编辑:黄飞
-
2023年10月21日芯片价格信息差《三星内存条》#采购#华强北#内存#集成电路#三星内存条#深圳市石芯电子有限公司 2023-10-21
-
专业收购三星芯片 高价回收三星芯片2021-09-03 2270
-
给内存加上AI?三星是这样做的2021-08-24 1012
-
回收三星ic 收购三星ic2021-08-20 2053
-
高价回收三星芯片,专业收购三星芯片2021-07-06 1361
-
专业回收三星ic,高价收购三星ic2021-05-28 1390
-
东莞收购三星ic 专业回收三星ic2021-04-28 1682
-
大量回收三星高通CPU 回收三星高通CPU2021-04-14 1821
-
大量回收三星高通CPU 回收三星高通CPU2021-03-10 1702
-
高价收购三星字库2021-02-23 1441
-
三星首次推出 HBM-PIM 技术,功耗降低 71% 提供两倍多性能2021-02-18 3040
-
专业收购三星芯片2020-12-01 1434
-
三星推10纳米中端处理器Exynos 9610强化视觉深度处理2018-03-25 6031
-
三星电池新技术2017-11-29 4944
全部0条评论

快来发表一下你的评论吧 !
