

SiFive P870核心性能解析
嵌入式技术
描述
RISC-V是一种开放指令集架构,任何人都可以创建了解RISC-V指令的内核,而无需担心专利和许可证。SiFive是RISC-V领域的重要参与者,创建了可以授权给其他公司的定制RISC-V内核。
在Hot Chips 2023上,SiFive展示了他们的P870内核,旨在提供更高性能,并与ARM的Cortex X2或AMD的Zen 4c相媲美。
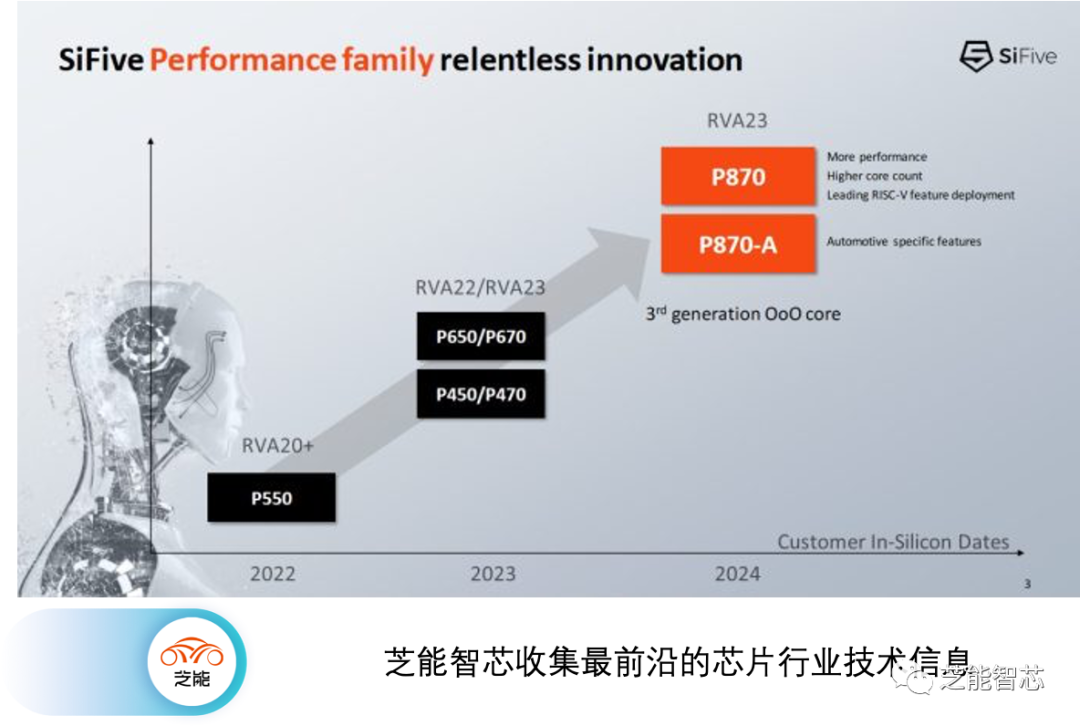
●P870核心概览
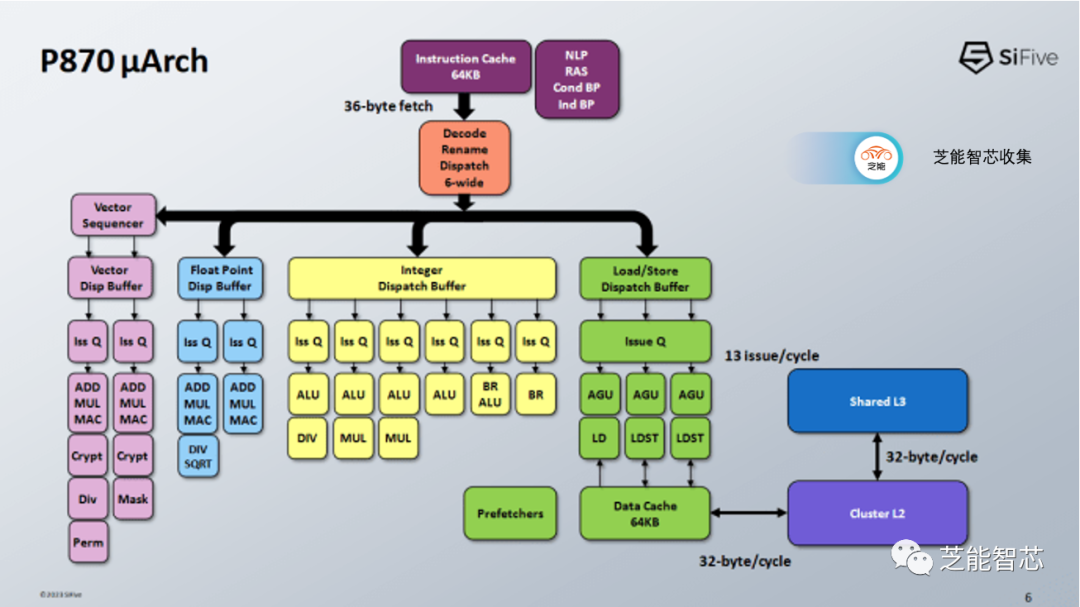
高级内核设计P870是SiFive的六核心,具备乱序执行功能,具备强大的重排序缓冲区和指令融合能力,从而具备出色的重排序性能。 P870采用了现代化功能,如分支预测器解耦、非调度队列以及RISC-V的矢量执行能力。
从SiFive的流Pipeline来看,P870的误预测损失仅为8个周期,相较于ARM、AMD和Intel的现代CPU,这是相当短的。如果在Ex阶段检测到错误预测,并且可以从指令缓存重新启动流水线,那么错误预测惩罚仅为7个周期。

●分支预测器
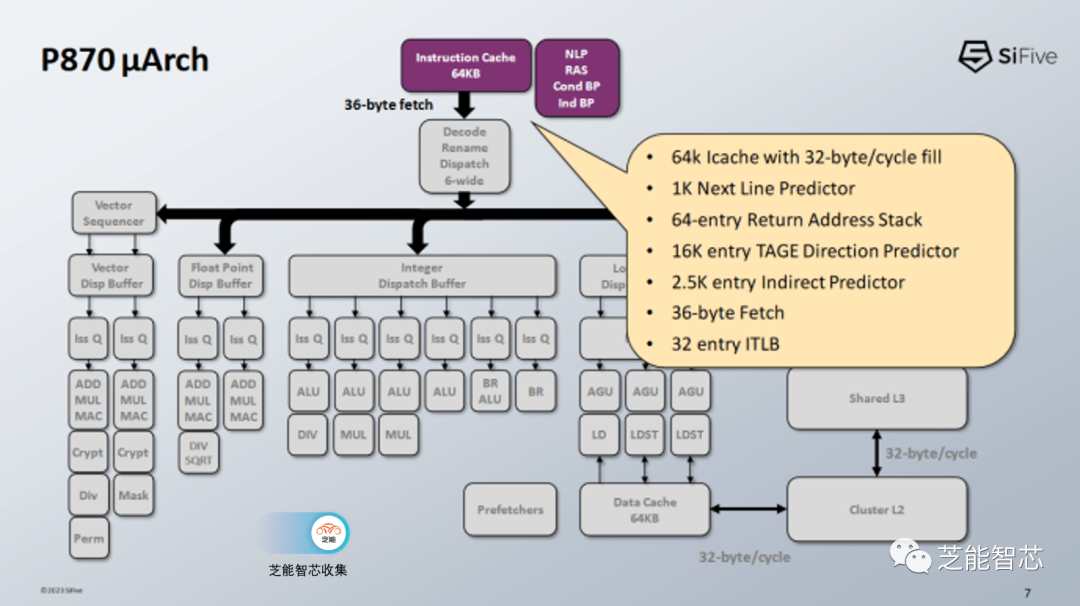
P870的流水线以分支预测器为起点,用于确定指令的执行方向。采用了具有16K表条目的八表TAGE预测器,通过在一组子预测器中选择来进行方向预测。这种配置可以提供强大的分支预测性能。
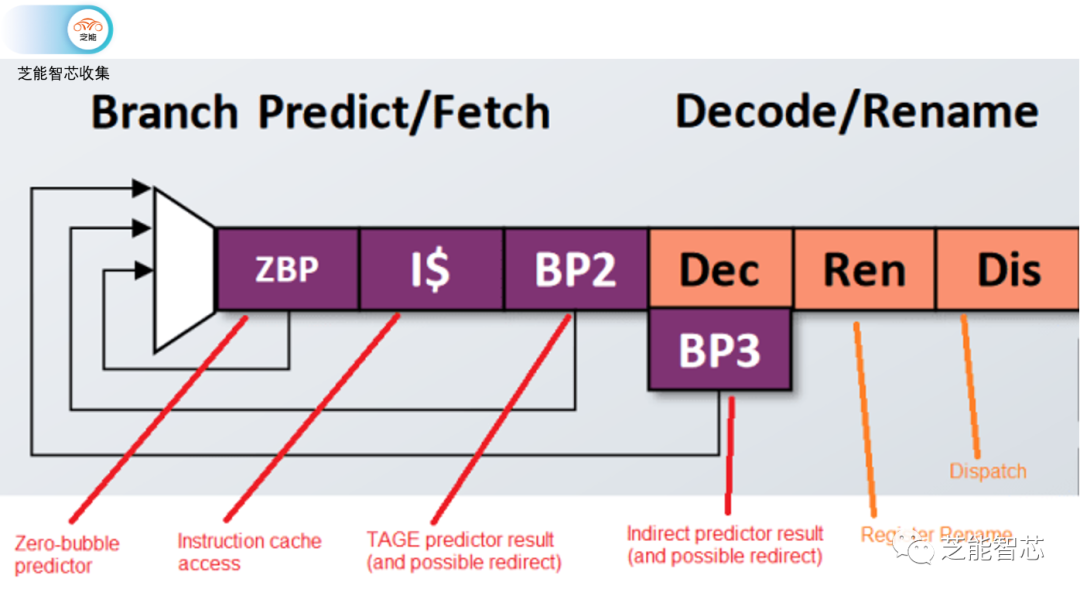
P870的分支预测过程包括快速零气泡预测器生成目标地址,然后TAGE预测器完成其预测,最后进行间接分支预测。虽然间接预测会带来三个周期的惩罚,但与竞争对手AMD Zen 4相似。
P870还提供了1024个零气泡预测器条目,与AMD Zen 3相匹配。其他分支预测资源也很充足。64 个条目的返回地址堆栈。AMD 的 Zen 系列只有 32 个入口返回堆栈,并且已经可以非常高精度地预测返回。间接预测器的 2.5K 条目容量也相当可观。Zen 4 有 3072 个条目间接预测器,而 Zen 3 有 1536 个条目。P870 的间接预测器正好位于这两代 Zen 之间。
●指令获取
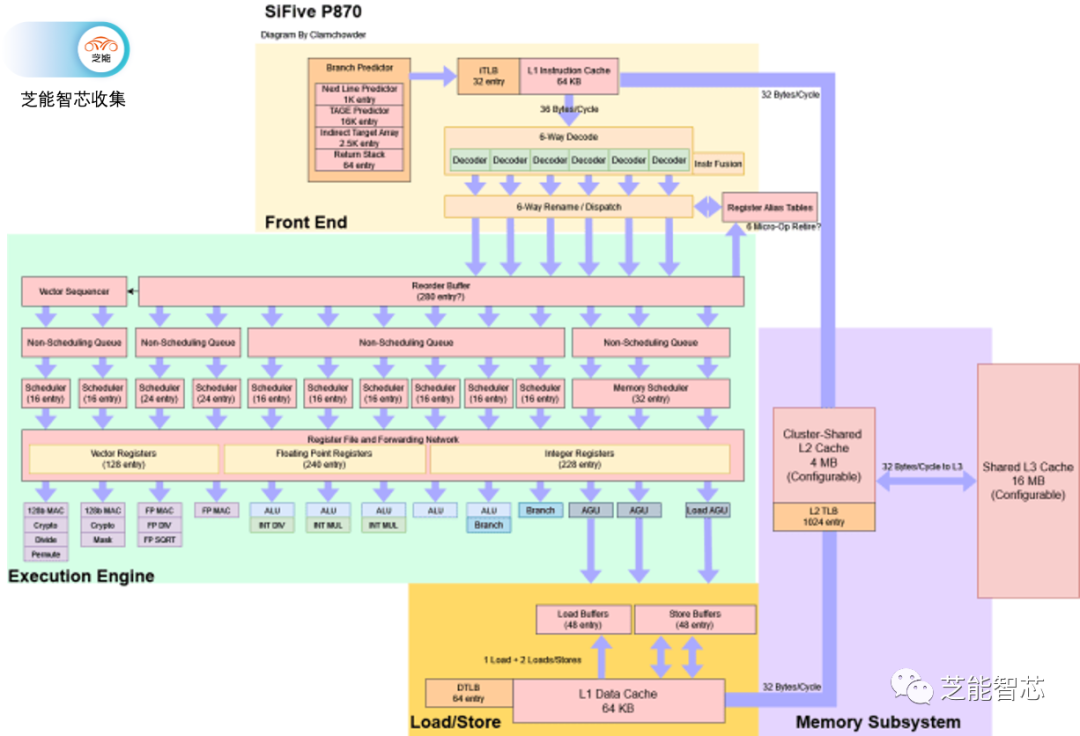
分支预测器生成获取地址,P870的前端每个周期可以从64KB指令高速缓存中获取36字节的数据,相当于9个RISC-V指令的字节,以供6宽解码器使用。此外,32条目的iTTLB用于虚拟地址到物理地址的转换。
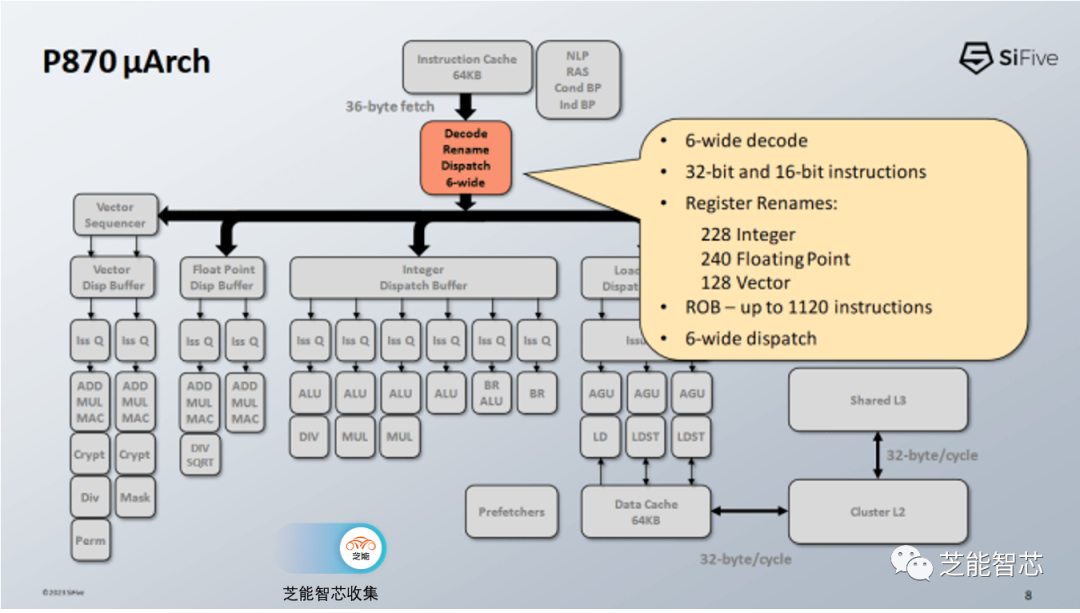
P870的解码器可以处理多种指令融合情况,尽管SiFive没有提供详细说明。这种指令融合的潜力对于提高性能非常直观,但需要编译器的支持。
●执行引擎
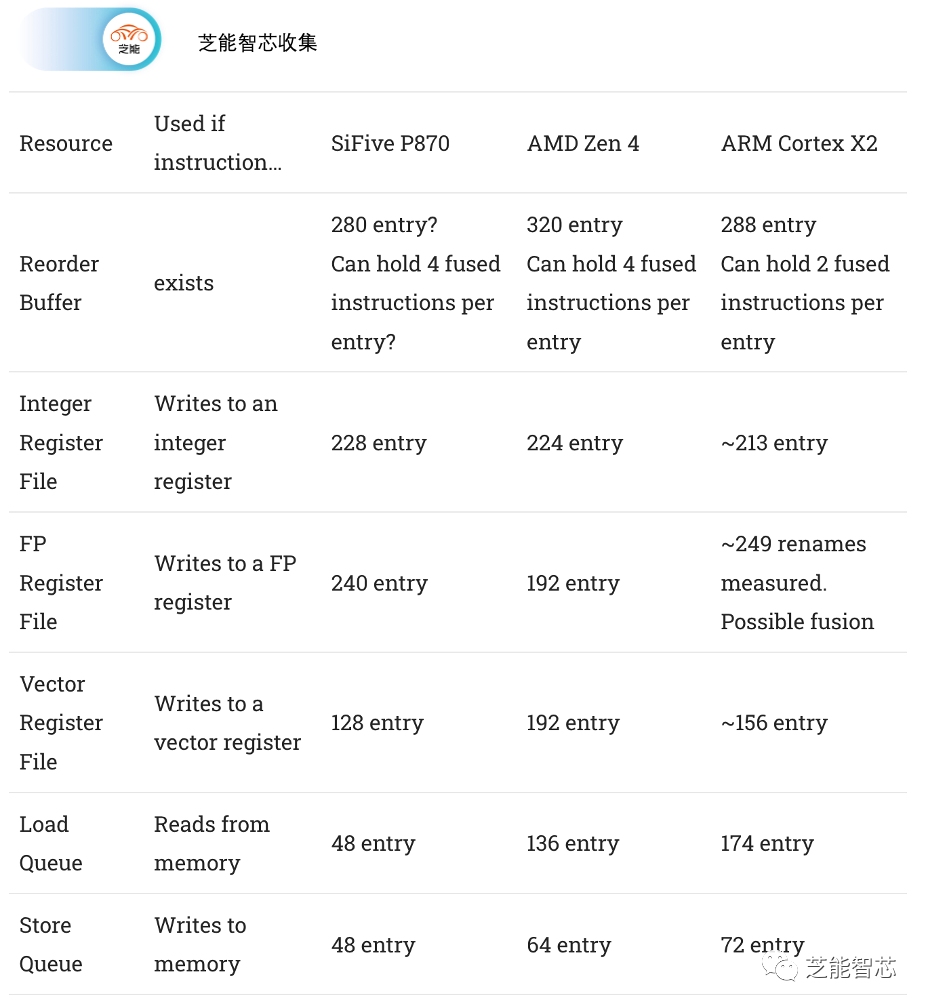
P870具备大型的后端资源,与ARM Cortex X系列或AMD Zen 4相当。这些资源包括重新排序缓冲区、寄存器文件容量等,尽管加载和存储队列略显不足。iFive选择了一种执行端口布局,与ARM的Cortex X2策略有一些相似之处。他们采用了小型分布式调度程序,从而产生了大量的执行端口。
分布式调度程序可能很难调整,因为任何一个调度队列填满都可能导致停滞。为了解决这个问题,SiFive采用了与苹果Firestorm类似的策略。每个执行集群都有一个非调度队列,以防止调度队列填满时重命名器停止。
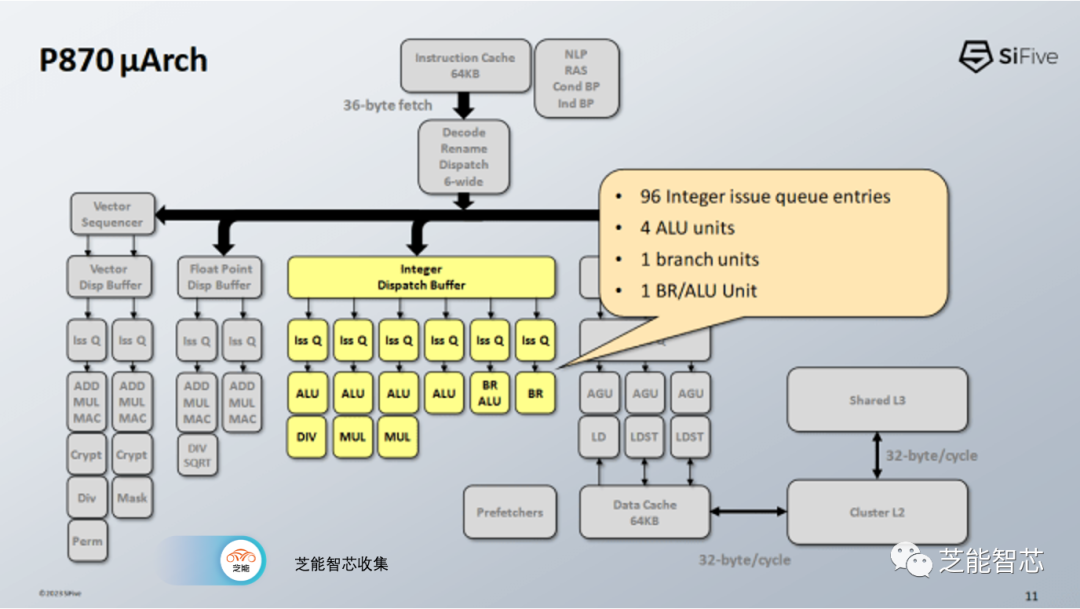
在执行单元方面,P870共有六个端口,端口数量与Cortex X2相匹配,但每个端口都有一个专用的调度队列。Cortex X2将两个端口用于处理分支操作,P870则使其中一个分支端口也能够处理一般的ALU操作。
●浮点运算
浮点执行资源相对于整数执行资源而言较为有限。P870具备两个浮点管道,每个管道能够处理最常见的操作。SiFive着重强调了其浮点加法和乘法的出色性能,仅需2个周期的延迟。与大多数其他现代CPU不同,SiFive的演示表明P870具备独立的浮点和矢量寄存器文件。
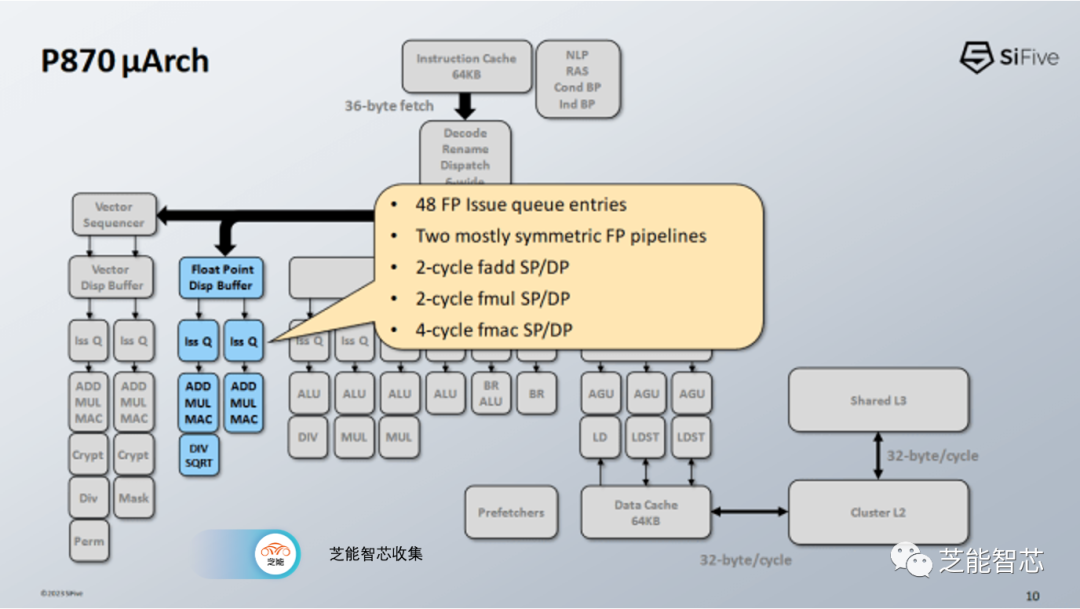
具备不同数量的重命名寄存器,并且彼此之间不是倍数关系(减少了融合情况的可能性)。浮点和矢量寄存器文件各自可以具备较低的端口数。供给两个乘加单元所需的输入达到了六个,较低的端口数应该能够实现更节省空间的寄存器文件。
●矢量执行
P870支持一对128位宽矢量执行管道,这在RISC-V领域是一大进步,P870还引入了针对RISC-V的LMUL功能的独特机制,称为向量排序器,用于提高矢量指令的效率。
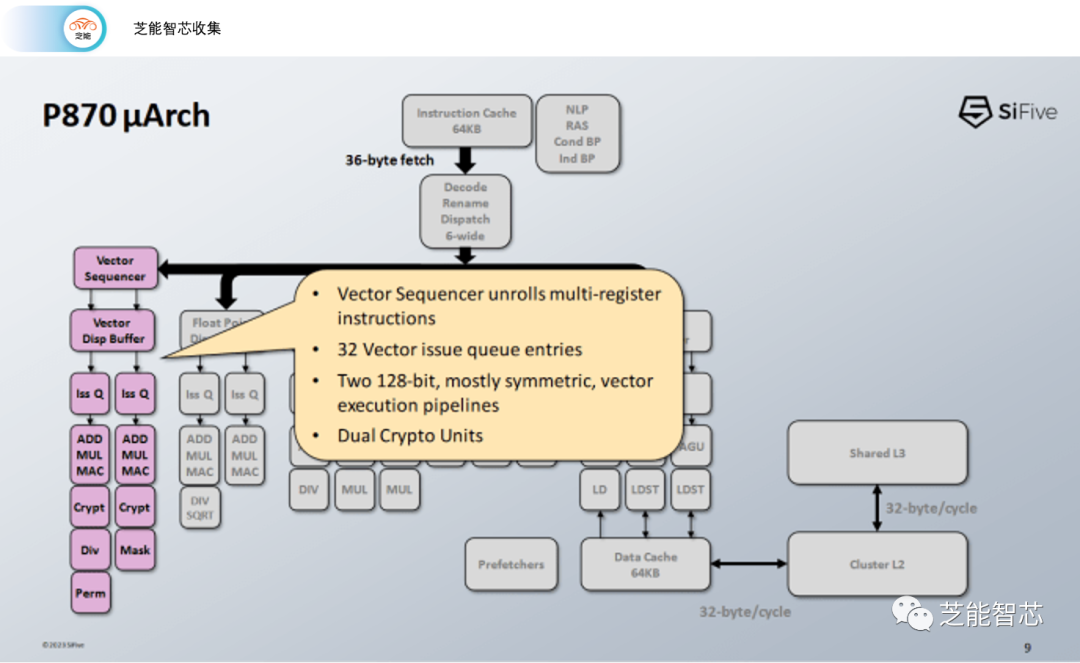
P870支持矢量执行,配备了一对128位宽的管道。这在P870的架构中是一个弱点,但在RISC-V世界中仍然是一大进步。与之相比,其他RISC-V芯片,如Ventana的Veyron V1,只具有标量FP执行能力,根本没有矢量执行能力。一对128位的管道大致与ARM的Neoverse N1和N2上的管道相匹配,并且可以提供可接受的矢量性能。
P870具有独特的应对机制,针对RISC-V的LMUL特性,称为矢量顺序器。疯狂的程序员可以将LMUL设置为大于1的值,使矢量指令寻址连续的寄存器块。通常,奇怪的复杂事情是由解码器将指令分割成多个微操作来处理的。
但如果LMUL不等于1,这样做将消耗大量的解码器和重命名器带宽。

如果LMUL > 1,SiFive会在管道中进一步拆分矢量指令。这样做意味着LMUL = 2的指令将仅消耗一个解码槽。
在顺序器之后,将消耗多个调度器槽,并根据需要在多个周期内发出其微操作。对SiFive的管道幻灯片进行了仔细观察,表明顺序器可以在短短一个周期内分解矢量操作。
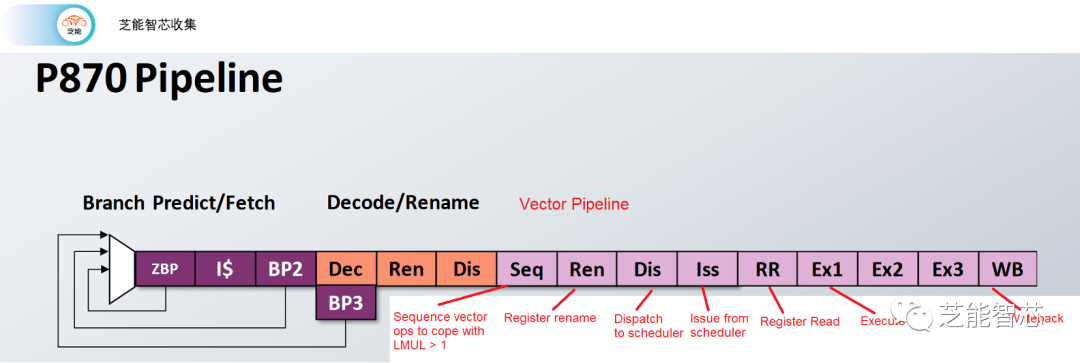
矢量单元在矢量顺序器之后放置了自己的寄存器重命名阶段,因此在分割矢量操作后分配物理寄存器。与所有新的架构功能一样,我们必须拭目以待,看看RISC-V的LMUL会有多大的用处。
●缓存和内存访问
P870具有三个用于地址生成的管道,两个管道可以处理加载或存储操作,而第三个管道只处理加载操作。这种AGU设置与Cortex X2、A710和Zen 4上看到的类似。数据缓存访问需要四个周期。有趣的是,地址生成、标签查找和数据缓存访问在三个周期内完成。P870额外消耗一个管道阶段(Drv)来移动数据。我想知道未来的设计是否会实现3个周期的加载到使用延迟。这应该是完全可行的。毕竟,AMD的Athlon系列在古老的工艺节点上实现了64 KB L1D的3个周期延迟,同时以相似的频率运行。
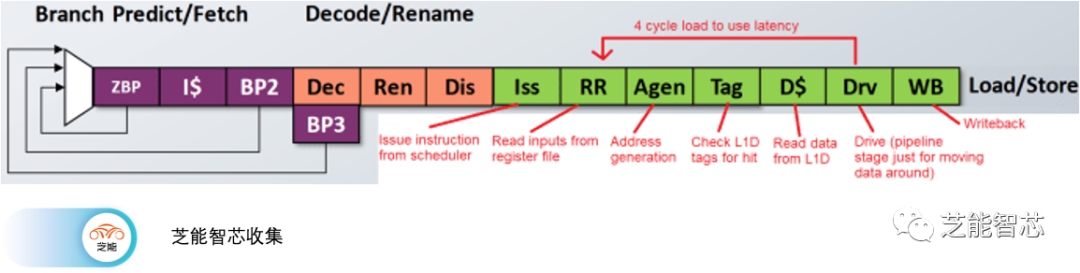
地址翻译由64个条目的DTLB处理,并由1024个条目的L2 TLB支持。现在的L2 TLB有点小,但ARM的Cortex A710上也有类似大小的L2 TLB。 L1D缺失由共享的、非包含的L2缓存处理。L2缓存是分段的,用于处理来自多个核心的访问,并具有16个周期的延迟。
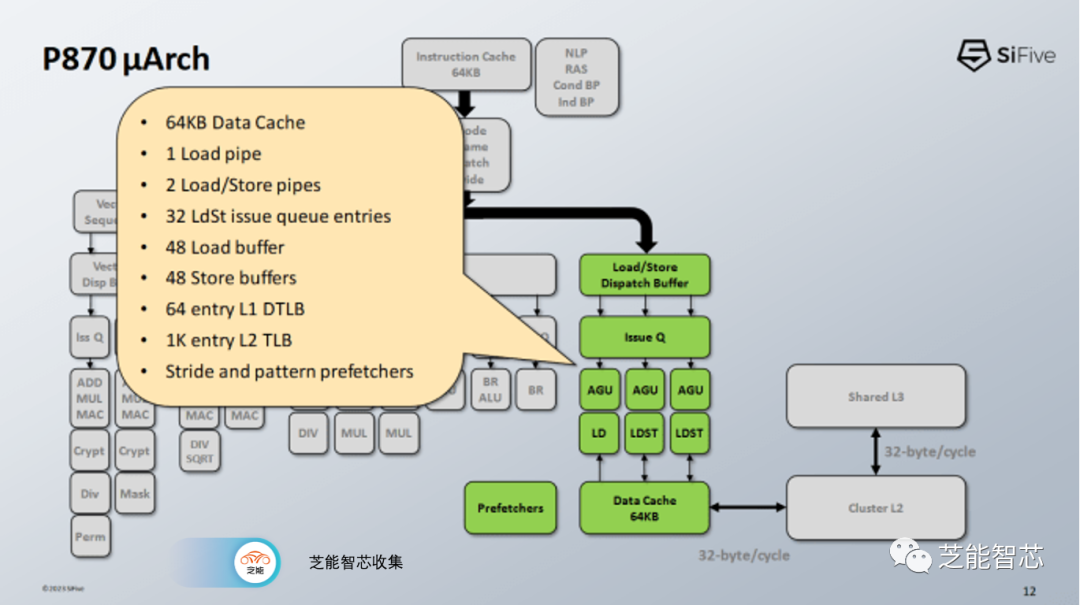
英特尔的E-Cores也是以四核簇的方式排列,具有共享的L2缓存,延迟为20个周期。SiFive允许客户配置L2的大小,但他们以4 MB的L2配置作为示例。为了处理一致性,L2复合体维护监听过滤器来跟踪核心私有缓存内容,其方案听起来类似于Cortex A72使用的方案。
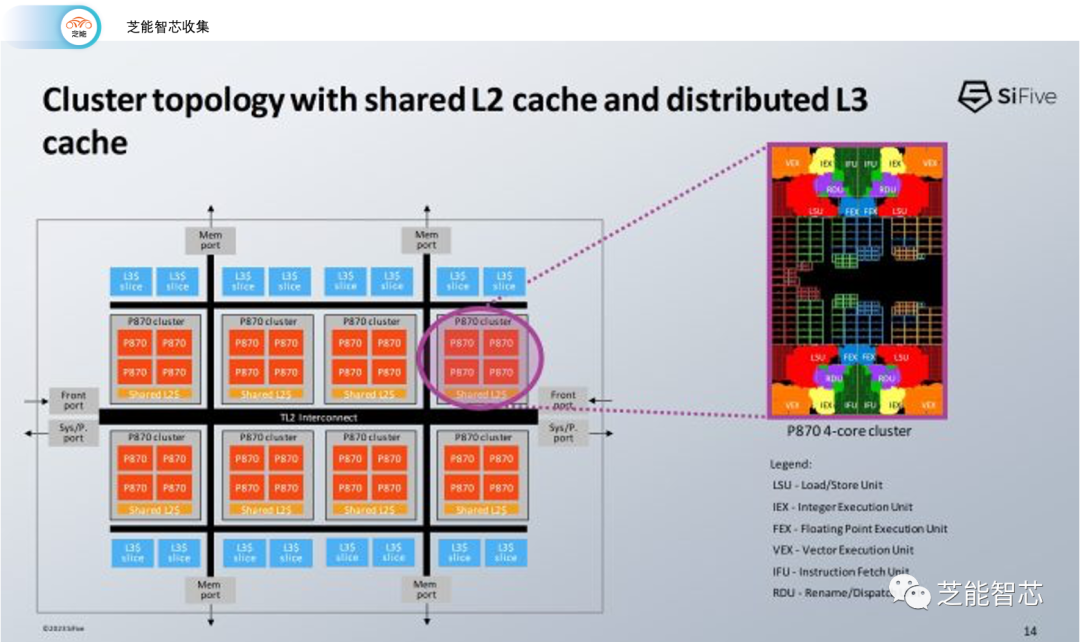
P870的L3缓存在簇之间共享。L3的容量和延迟取决于具体的实现,但SiFive在性能估算中使用了一个16 MB的L3配置。
●可靠性特征
现代CPU都采取各种措施来保护各种缓存和其他结构,以提高可靠性。
SiFive的P870-A是P870核心的汽车变种,特别注重错误检测和纠正。除了用于缓存和寄存器文件的标准ECC和奇偶校验保护集之外,SiFive还实现了高可靠性缓存控制器和互连。
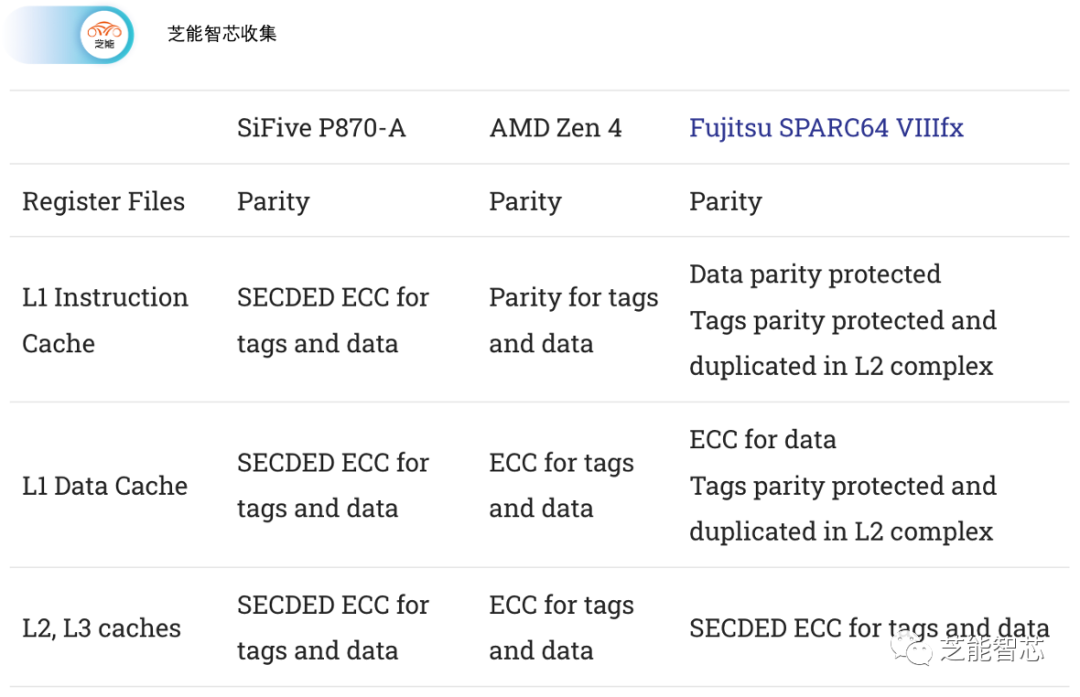
CPU通常在它们的互连中的各种队列和传输链路上都具备奇偶校验或ECC保护。例如,Zen 4的可扩展数据端口(Infinity Fabric的接口)具备奇偶校验保护,UMC(内存控制器)前面的队列具备ECC保护。
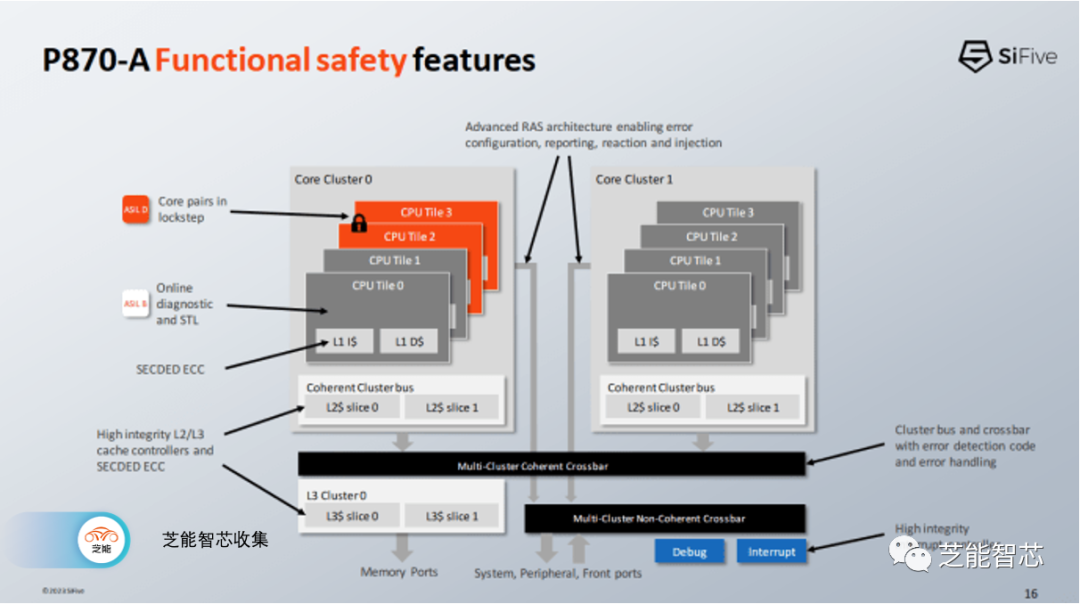
SiFive可以将一对P870核心以锁步方式运行,以进一步提高可靠性,有点类似于飞机和航天器在多台计算机上运行冗余计算。随机位翻转不太可能以相同的方式影响多个核心,因此这种方法通过基本上复制所有核心结构来显着提高可靠性,但代价是计算吞吐量较低。这种锁步操作是可能的,因为每个核心在重置后都以明确定义的状态开始,并且此后的操作是确定性的。
●最后
RISC-V虽然起步较晚,但增长迅速。SiFive的P870展示了能力和野心,希望能与ARM竞争并在市场上获得份额。RISC-V还需要发展更完善的软件生态系统来支持其发展,这是个挑战。
SiFive的P870内核在性能和功能方面表现出色,为RISC-V生态系统的进一步壮大奠定了基础。
编辑:黄飞
-
全球首款铝离子固态电池量产;SiFive公布全新RISC-V处理器P650,性能超上代50%……2021-12-04 25035
-
SiFive发布P870和X390,RISC-V架构内核性能暴涨2023-10-17 3357
-
LabVIEW运行性能解析视频教程2009-12-10 9107
-
带有SiFive开发板和高性能CPU的RISC-V迈向主流2020-11-14 2450
-
基于二分图构造LDPC码的校验矩阵算法及性能解析,不看肯定后悔2021-06-22 1288
-
按键部分功能解析备注2022-02-16 829
-
KINGMAX电池安全性能解析2010-04-14 756
-
基于虚拟化的云中心性能分析2017-01-07 695
-
E型铁心开关磁通电机的电磁性能解析计算_杨玉波2017-01-08 929
-
SiFive展示新一代P870处理器设计2023-09-05 2111
-
SiFive P870 RISC-V 处理器亮相 Hot Chips 20232023-10-07 11906
-
SiFive 宣布推出针对生成式 AI/ML 应用的差异化解决方案,引领 RISC-V 进入高性能创新时代2023-10-12 671
-
SiFive 推出高性能 Risc-V CPU 开发板 HiFive Premier P5502024-12-16 3535
-
180 Watt医疗电源:设计与性能解析2026-05-14 340
全部0条评论

快来发表一下你的评论吧 !
