

点云采样方法新创新,深度学习与传统的结合
描述
1 前言
点云作为一种重要的数据表示,广泛应用于自动驾驶、增强现实和机器人技术等领域。由于点云数据量通常很大,对其进行采样以获得一个具有代表性的点集子集是三维计算机视觉中的一个基础和重要的任务。除了随机采样和最远点采样之外,大多数传统的点云采样方法都是基于数学统计的,例如均匀采样、网格采样和几何采样等,这些方法对于点云密度和分布比较敏感。最近,一些基于神经网络的方法开始通过端到端的任务驱动学习方式进行更好的任务定向采样,例如S-Net、SampleNet、DA-Net等。
但是这些方法大多是基于生成模型的,而不是直接选择点。另一方面,为点云设计基于神经网络的局部特征聚合算子的工作越来越多。虽然其中一些(例如 PointCNN 、PointASNL 、GSS )在学习潜在特征时减少了点数,但由于处理过程中不存在真正的空间点,它们很难被认为是真实意义上的采样方法。此外,上述方法都没有将形状轮廓视为特殊特征。受 Canny 边缘检测算法和注意力机制的启发,本文提出了一种基于非生成注意力的点云边缘采样方法 (APES),结合了基于神经网络的学习和基于数学统计的直接点选择。
APES使用注意力机制来计算相关图和样本边缘点,这些边缘点的属性反映在这些相关图中。提出了两种具有不同注意力模式的 APES。此外,我们的方法可以将输入点云下采样到任何所需的大小。基于邻居到点(N2P)注意,计算每个点与其相邻点之间的相关映射,提出了基于局部的APES基于点对点 (P2P) 注意力,它计算所有点之间的相关性图,提出了基于全局的 APES本文的贡献如下:
1)一种点云边缘采样方法,称为 APES,它结合了基于神经网络的学习和基于数学统计的直接点选择2)通过使用两种不同的注意力模式,基于局部的 APES 和基于全局的 APES 的两种变体3)公共点云基准上的良好定性和定量结果,证明了所提出的采样方法的有效性。这里也推荐「3D视觉工坊」新课程三维点云处理:算法与实战汇总2 相关背景
传统点云采样方法
随机采样(RS):简单高效,但无法控制采样点分布。
最远点采样(FPS):迭代选择点云中最远点,目前最广泛使用。
均匀采样:选择点云中均匀分布的点。
网格采样:使用规则网格采样点,无法精确控制点数。
几何采样:基于局部几何信息采样,例如曲率。
逆密度采样(IDIS):采样距离和值较小的点。
深度学习点云采样方法
S-Net:直接从全局特征生成新点坐标。
SampleNet:在S-Net基础上引入软投影操作。
DA-Net:考虑点云密度进行自适应采样。
MOPS-Net:学习采样变换矩阵与原点云相乘生成新点云。
PST-NET:使用self-attention层替代S-Net中的MLP层。
但是现有的深度学习采样方法大多基于生成模型,不能直接选择点,也没有考虑形状边缘作为特殊特征。
3 方法
3.1 图像中的Canny边缘检测
Canny图像边缘检测流程:
(i)应用高斯滤波器平滑图像;
(ii) 找到图像的强度梯度;
(iii) 应用梯度幅度阈值或下限截止抑制;
(iv) 应用双阈值来确定潜在边;
(v) 通过抑制所有其他弱且不连接到强边的边来最终检测边缘。
替换的边缘检测
核心思想是计算每个像素的梯度强度。可以更通用地考虑:
定义像素与邻域像素之间的相关特性
计算归一化的相关性映射,是像素的邻域;
计算的标准差,大的像素点为边缘点
使用标准差代替了梯度计算,该方法相比原本的图像的Canny边缘检测器计算成本更高,但却可以将其应用于点云边缘采样。相比图像规整的排列,点云通常是不规则的,无序的,甚至是稀疏的,因此基于体素的3D卷积不适用。与图像具有多种属性(如RGB或灰度值)相比,对于许多点云来说,点坐标可能是唯一可用的特征。
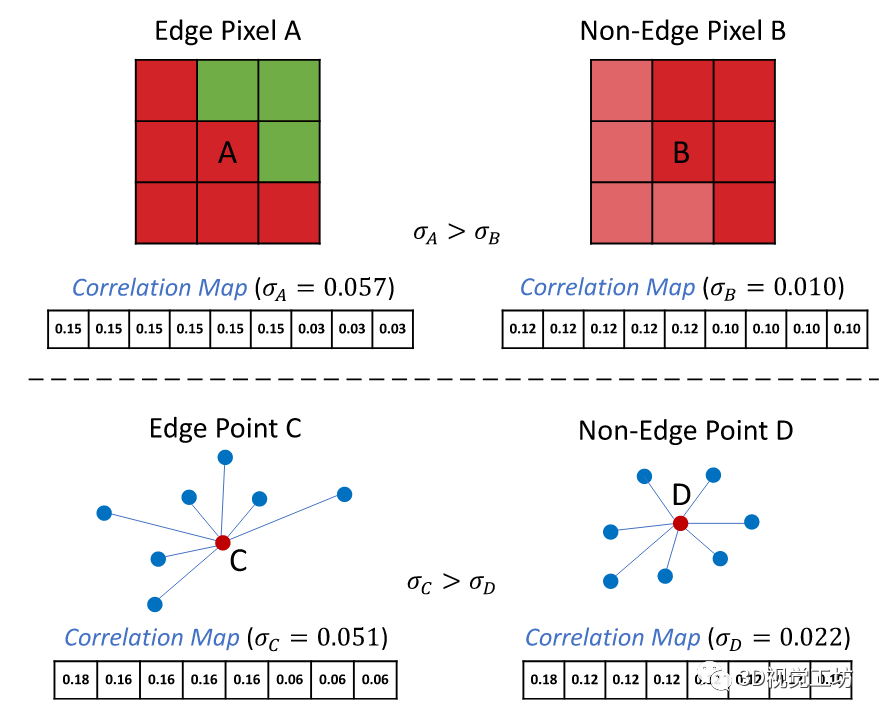
图1 使用标准偏差来选择边缘像素/点的图示。在中心像素/点与其相邻像素之间计算归一化相关图。中心像素/点作为邻居自包含。归一化相关图中的较大标准偏差意味着它是边缘像素/点的可能性更高。
3.2 基于局部的点云边缘采样
对于点云,我们定义近邻定义每个点的局部邻域点云,然后延续刚刚的替换Canny边缘检测算法的思路。
定义点与邻域点的基于局部的相关特性
计算归一化的基于局部的相关性映射
计算的标准差,大的像素点为边缘点
其中,与原始的Transformer的模型相比,和 分别表示应用于查询输入和关键输入的线性层,即为,特征维度计数平方根用作比例因子称之为邻域-点(N2P)注意力,它捕获局部信息。
3.3 基于全局的点云边缘采样
对于采样问题,全局信息也是至关重要的。考虑k = N的情况,利用线性层Q和K共享所有点,将其称为点对点 (P2P) 注意力,基于全局的相关特性与相关性映射如下:得到全相关性图本文改为按列计算和(而不是行),计算得到,较大的点作为边缘点采样。主要考虑到,如果点邻近边缘点,那么应较大,如果在中对应的列元素的值也较大,那么也可能是边缘点。
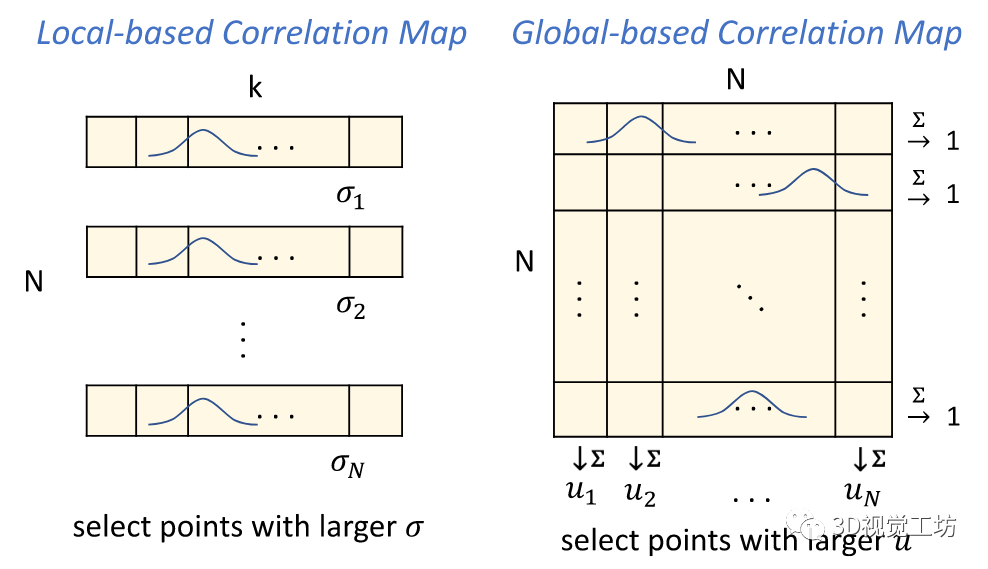
图2 所提出方法的关键思想。N 表示点的总数,而 k 表示用于基于局部采样方法的邻居数量。
3.4 网络框架
基于上述两种模块,本文构建了分类网络和分割网络,如下图所示
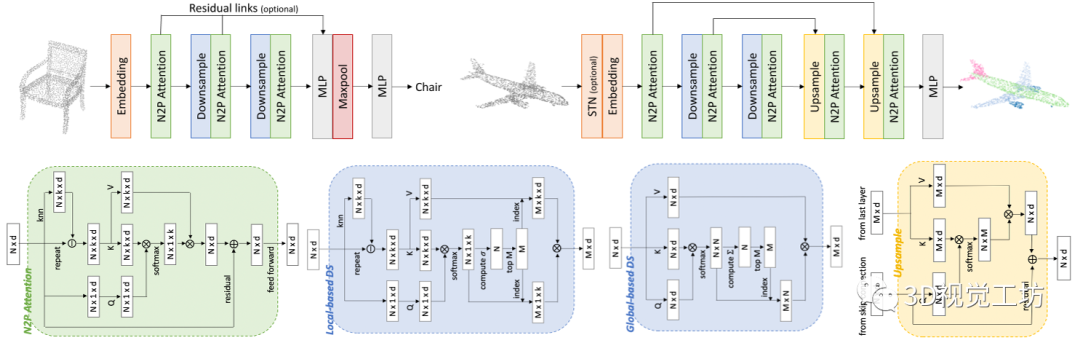
图3 用于分类的网络架构(左上)和分割(右上)。还给出了 N2P 注意力特征学习层(左下)、两个替代下采样层(左下)和上采样层(右下)的结构。这两种下采样层将点云从 N 个点下采样到 M 个点,而上采样层将其从 M 个点上采样到 N 个点。
主要组成部分:
编码层:提取点云特征。
采样层:应用提出的基于局部或全局的边缘点采样方法进行下采样。
解码层:使用注意力机制进行上采样。
4 实验
4.1 分类网络
数据集:ModelNet40定量比较:分类精度与SOTA方法处于同水平
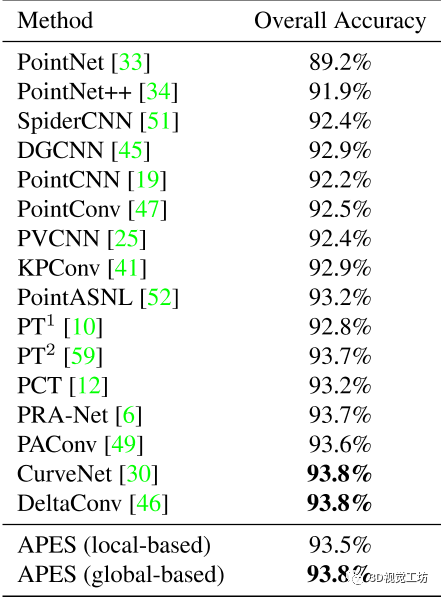
表1 ModelNet40 上的分类结果。与其他仅使用原始点云作为输入的 SOTA 方法相比。请注意,我们报告的结果没有考虑投票策略。
定性结果
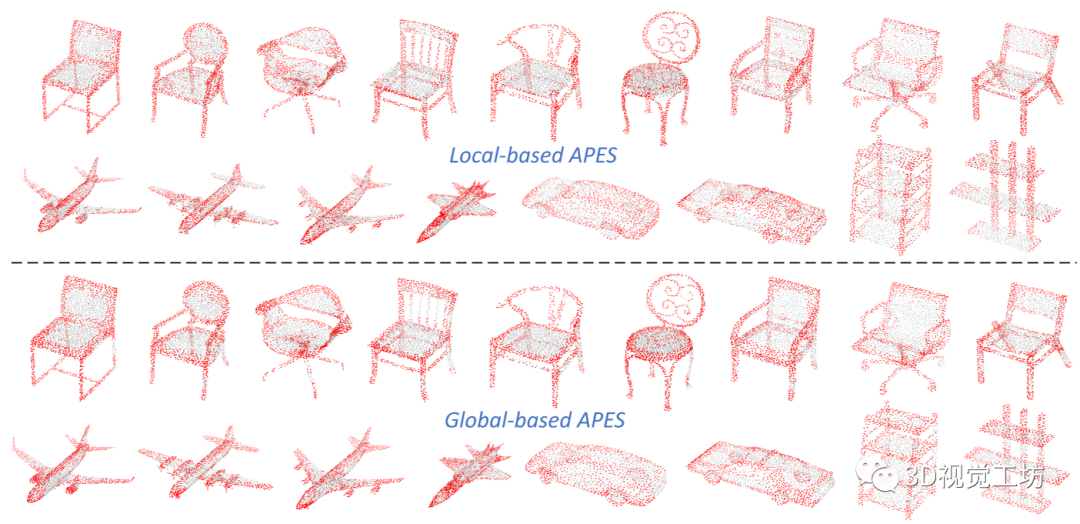
图5 基于局部的APES和基于全局的APES在不同形状上的可视化采样结果。所有形状都来自测试集。
4.2 分割网络
数据集:ShapeNetPart定量分析:分割精度略差于SOTA,但对下采样点云的中间结果优于SOTA,说明下采样的边缘点对于算法的性能贡献较大,而由于边缘下采样改变了点云的分布,导致插值上采样无法重构。这里也推荐「3D视觉工坊」新课程三维点云处理:算法与实战汇总定性结果

图6 将可视化分割结果作为形状点云进行下采样。所有形状都来自测试集。
4.3 消融实验
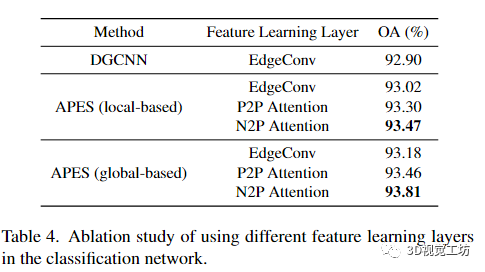
数据集:ModelNet40Feature Learning Layer
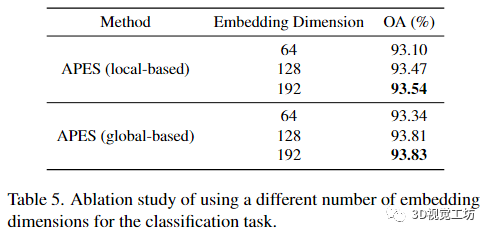
Embedding Dimension
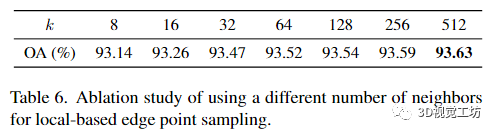
Choice of k in local-based APES
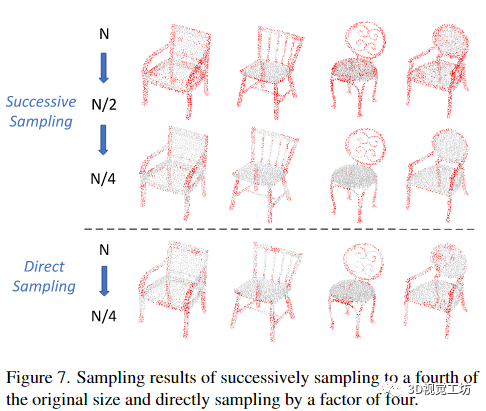
Successive sampling vs. Direct sampling
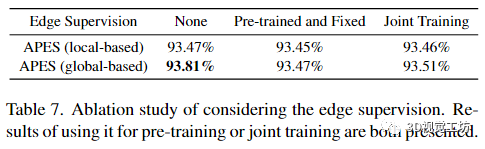
Additional edge point supervision
4.4 对比实验
数据集:ModelNet40定量分析:

定性分析:

计算复杂度比较

5 总结
本文提出了一种基于注意力的点云边缘采样(APES)方法。它使用注意力机制相应地计算相关图并采样边缘点。基于不同的注意力模式,提出了基于局部 APES 和基于全局的 APES 的两种变体。定性和定量结果表明,我们的方法在常见的点云基准任务上取得了良好的性能。在未来的工作中,可以为训练设计其他补充损失。此外,我们注意到边缘点采样的不同点分布阻碍了后期上采样操作和分割性能。设计能够更好地应对边缘点采样的上采样方法会很有趣。
-
基于深度学习的三维点云分类方法2024-10-29 2799
-
基于深度学习的3D点云实例分割方法2023-11-13 4029
-
基于深度学习的点云分割的方法介绍2023-07-20 831
-
一个基于学习的LiDAR点云3D线特征分割和描述模型2023-01-12 2857
-
基于深度学习的三维点云配准方法2022-11-29 2618
-
深度学习和传统计算机视觉技术在新兴领域的比较2022-11-28 2885
-
结合基扩展模型和深度学习的信道估计方法2021-06-30 1047
-
针对复杂场景处理的点云深度学习网络2021-05-18 1142
-
基于深度学习的点云对齐算法3DMatch2021-04-23 2258
-
基于深度学习的三维点云语义分割研究分析2021-04-01 1542
-
校企双进 | 机智云走进华南农业大学创新创业论坛2019-11-14 2125
-
一种基于点云的Voxel(三维体素)特征的深度学习方法2018-12-07 23392
-
基于深度学习模型的点云目标检测及ROS实现2018-11-05 19387
-
图像分类的方法之深度学习与传统机器学习2017-09-28 1851
全部0条评论

快来发表一下你的评论吧 !
