

桥接模式应用场景
描述
1、什么是桥接模式?
Decouple an abstraction from its implementation so that the two can vary independently.
桥接模式(Bridge Pattern):将抽象和实现解耦, 使得两者可以独立地变化。
另外一种解释是:一个类存在两个(或多个)独立变化的维度,我们通过组合的方式,让这两个(或多个)维度可以独立进行扩展。
听起来可能还是很深奥,没关系,下面通过例子讲解。
2、桥接模式定义
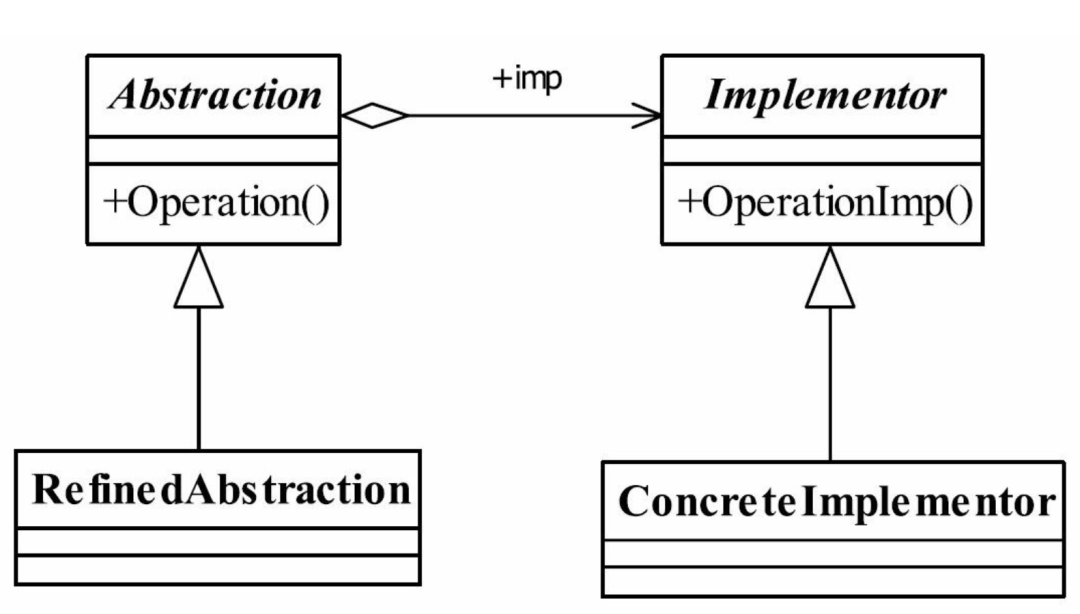
①、Abstraction
抽象化角色:它的主要职责是定义出该角色的行为, 同时保存一个对实现化角色的引用, 该角色一般是抽象类。
②、Implementor
实现化角色:它是接口或者抽象类, 定义角色必需的行为和属性。
③、RefinedAbstraction
修正抽象化角色:它引用实现化角色对抽象化角色进行修正。
④、ConcreteImplementor
具体实现化角色:它实现接口或抽象类定义的方法和属性。
3、桥接模式通用代码实现
实现化类:
public interface Implementor {
void doSomething();
}
具体实现化类:
public class ConcreteImplementor1 implements Implementor{
@Override
public void doSomething() {
// 具体业务逻辑处理
}
}
public class ConcreteImplementor2 implements Implementor{
@Override
public void doSomething() {
// 具体业务逻辑
}
}
这里定义了两个,可能有多个。
抽象化角色:
public abstract class Abstraction {
// 定义对实现化角色的引用
private Implementor implementor;
public Abstraction(Implementor implementor){
this.implementor = implementor;
}
// 自身的行为和属性
public void request(){
this.implementor.doSomething();
}
// 获取实现化角色
public Implementor getImplementor(){
return implementor;
}
}
修正抽象化角色:
public class RefinedAbstraction extends Abstraction{
// 覆写构造函数
public RefinedAbstraction(Implementor implementor){
super(implementor);
}
// 修正父类的行为
@Override
public void request() {
super.request();
}
}
测试:
public class BridgeClient {
public static void main(String[] args) {
// 定义一个实现化角色
Implementor implementor = new ConcreteImplementor1();
// 定义一个抽象化角色
Abstraction abstraction = new RefinedAbstraction(implementor);
// 执行方法
abstraction.request();
}
}
如果我们的实现化角色有很多的子接口, 然后是一堆的子实现。在构造函数中传递一个明确的实现者, 代码也是很清晰的。
4、桥接模式经典例子—JDBC
我们在刚开始用 JDBC 直连数据库的时候,会有这样一段代码:
Class.forName("com.mysql.cj.jdbc.Driver");//加载及注册JDBC驱动程序
String url = "jdbc:mysql://localhost:3306/sample_db?user=root&password=your_password";
Connection con = DriverManager.getConnection(url);
Statement stmt = con.createStatement();
String query = "select * from test";
ResultSet rs=stmt.executeQuery(query);
while(rs.next()) {
rs.getString(1);
rs.getInt(2);
}
如果我们想要把 MySQL 数据库换成 Oracle 数据库,只需要把第一行代码中的 com.mysql.cj.jdbc.Driver 换成oracle.jdbc.driver.OracleDriver 就可以了。
这种优雅的实现数据库切换方式就是利用了桥接模式。
我们首先看 Driver 类:
package com.mysql.cj.jdbc;
import java.sql.DriverManager;
import java.sql.SQLException;
public class Driver extends NonRegisteringDriver implements java.sql.Driver {
public Driver() throws SQLException {
}
static {
try {
DriverManager.registerDriver(new Driver());
} catch (SQLException var1) {
throw new RuntimeException("Can't register driver!");
}
}
}
这段代码 Class.forName("com.mysql.cj.jdbc.Driver") 作用有两个:
①、要求 JVM 查找并加载指定的 Driver 类。
②、执行该类的静态代码,也就是将 MySQL Driver 注册到 DriverManager 类中。
接着我们看 DriverManager 类:
public class DriverManager {
private final static CopyOnWriteArrayList< DriverInfo > registeredDrivers = new CopyOnWriteArrayList< DriverInfo >();
//...
static {
loadInitialDrivers();
println("JDBC DriverManager initialized");
}
//...
public static synchronized void registerDriver(java.sql.Driver driver) throws SQLException {
if (driver != null) {
registeredDrivers.addIfAbsent(new DriverInfo(driver));
} else {
throw new NullPointerException();
}
}
public static Connection getConnection(String url, String user, String password) throws SQLException {
java.util.Properties info = new java.util.Properties();
if (user != null) {
info.put("user", user);
}
if (password != null) {
info.put("password", password);
}
return (getConnection(url, info, Reflection.getCallerClass()));
}
//...
}
当我们把具体的 Driver 实现类(比如,com.mysql.cj.jdbc.Driver)注册到 DriverManager 之后,后续所有对 JDBC 接口的调用,都会委派到对具体的 Driver 实现类来执行。而 Driver 实现类都实现了相同的接口(java.sql.Driver ),这也是可以灵活切换 Driver 的原因。

5、桥接模式优点
①、抽象和实现分离
这也是桥梁模式的主要特点, 它完全是为了解决继承的缺点而提出的设计模式。在该模式下, 实现可以不受抽象的约束, 不用再绑定在一个固定的抽象层次上。
②、优秀的扩充能力
看看我们的例子, 想增加实现?没问题!想增加抽象, 也没有问题!只要对外暴露的接口层允许这样的变化, 我们已经把变化的可能性减到最小。
③、实现细节对客户透明
客户不用关心细节的实现, 它已经由抽象层通过聚合关系完成了封装。
6、桥接模式应用场景
①、如果一个系统需要在构件的抽象化角色和具体化角色之间增加更多的灵活性,避免在两个层次之间建立静态的继承联系,通过桥接模式可以使它们在抽象层建立一个关联关系。
②、对于那些不希望使用继承或因为多层次继承导致系统类的个数急剧增加的系统,桥接模式尤为适用。
③、一个类存在两个独立变化的维度,且这两个维度都需要进行扩展。
-
AG32VF-MIPI应用场景2024-01-22 2385
-
STM32待机模式适合用于那些应用场景?2024-05-07 661
-
55913能否支持wifi的桥接模式?2025-07-17 4571
-
关于桥接模式遇到的问题2014-10-16 3725
-
CentOS静态IP配置(桥接模式)2020-05-12 1294
-
特斯拉电动汽车不下电,除了哨兵模式和宠物模式外还有哪些应用场景2020-06-09 3709
-
桥接模式的目标与设计2023-06-01 1374
-
设计模式结构性:桥接模式2023-06-08 1778
-
应变片1/4桥、半桥、全桥的区别及其应用场景2024-02-04 26013
-
网络桥接模式是什么? 网络桥接模式和路由模式的区别2024-05-10 9876
全部0条评论

快来发表一下你的评论吧 !
