

RTT是什么?对TCP中RTT时延的理解
电子说
描述
最近服务器环境部署了tcprtt网络时延监控,发现不同服务器不同节点之间的RTT时延表象非常奇怪,无法准确的判断服务器的网络情况。因此需要弄清楚什么是RTT,以及能否作为服务器网络性能的检测指标。
1、RTT是什么?
TCP中的 RTT指的是“往返时延”(Round-Trip Time) ,即从发送方发送数据开始,到发送方接收到来自接收方的确认消息所经过的时间。RTT时延通常由三部分决定: 链路的传播时间、末端系统的处理时间、路由器等网络中间节点的缓存和排队时间 。正常情况下报文的传输时间和在应用处理时间相对固定,在网络拥堵情况下会出现RTT时延的波动。
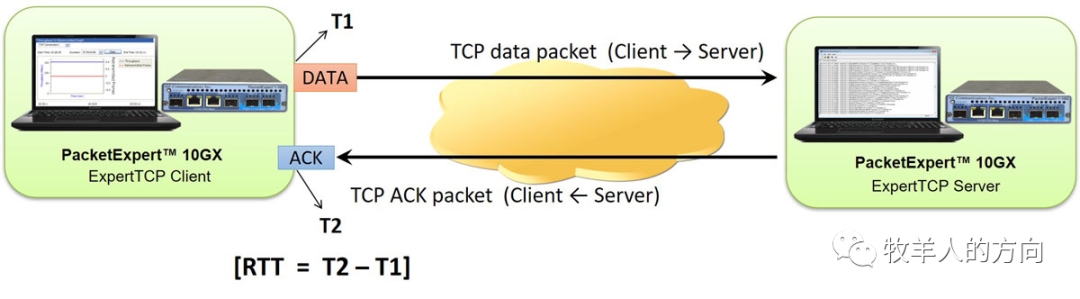
RTT是衡量网络传输性能的重要指标之一,能够反映出数据在网络中传输的速度和稳定性。通常情况下,RTT越短,网络传输的速度就越快,反之则越慢。因此, 通过监测TCP中的RTT时延,可以初步判断网络的性能如何。 但需要注意的是,RTT时延只是一个指标,要全面评估网络性能还需要结合其他指标进行综合分析。
1.1 RTT和RTO关系
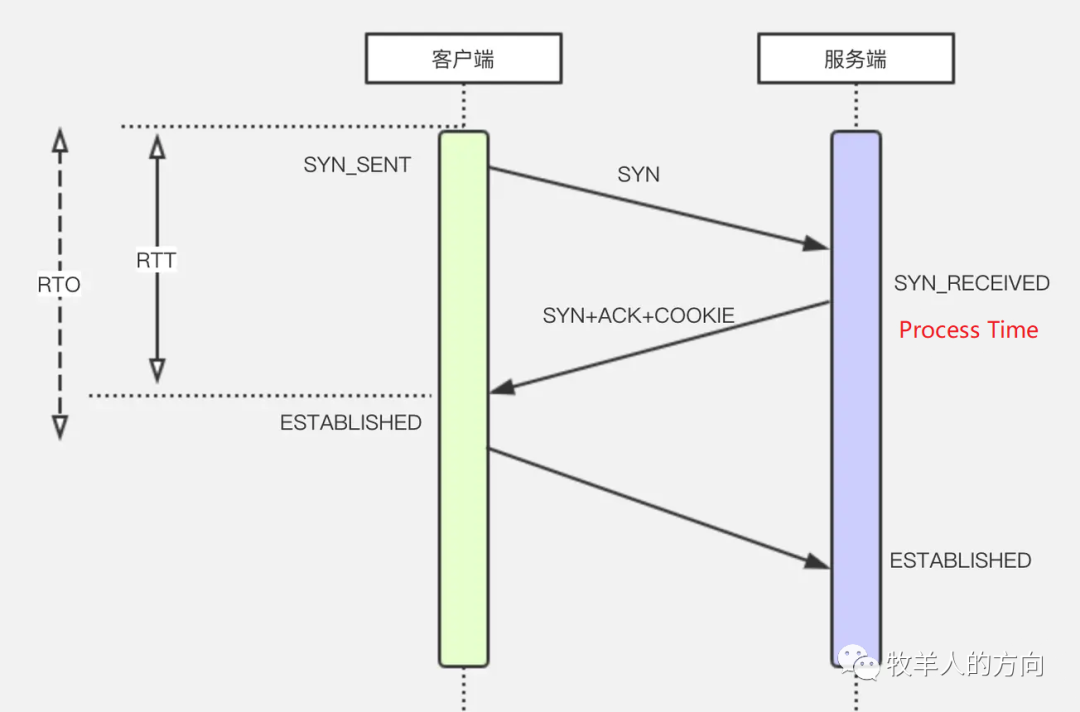
说起RTT就要提到RTO(Retransmission Timeout),TCP协议在握手过程中会启动一个定时器,如果在定时器时间内没有收到,则会进行重传,这个 重传的超时时间称为RTO 。RTT和RTO的关系是:由于网络的不确定性,每个RTT都是动态变化的,RTO也会动态变化。
当 RTO < RTT 时, 将会触发大量的重传, 当 RTO > RTT 时候, 如果频繁出现丢包, 重传不及时, 又会造成网络的反应慢, 最好的结果是 RTO 略大于 RTT.
1.2 RTT和Ping区别
Ping是使用 ICMP传输协议 ,可以用来评估RTT时延和网络性能的好坏。相比之下, RTT则是在应用层 (OSI/ISO的第7层)进行的网络时延测量,包括更高级别的协议和应用程序引起的额外处理时延。
1.3 RTT和时延的区别
网络时延与RTT密切相关,但又不同。延迟是数据包从发送端点传输到接收端点所需的时间(仅一次行程)。许多因素可能会影响此路径,包括网络链路性能情况、网络拥堵情况还有交换机层的缓存和队列等。 ** RTT除了网络传输的时延,还有末端处理的时延** ,因此网络时延并不一定完全等于RTT的一半。因此我们 可以解释在部分主备节点的数据库中,主节点到备节点的RTT时延表现正常,低于1ms,但是备节点到主节点之间的RTT时延超过10ms ,这中间很大一部分原因是因为备节点到主节点发送数据库的时候,主节点处理耗费了大部分时间。
2、RTT的算法和测量方法
2.1 RTT经典算法 [RFC793]
该算法称为加权移动平均算法Exponential weighted moving average,过程如下:
1) 首先,先采样RTT,记下最近几次的RTT值。
2)然后做平滑计算SRTT(Smoothed RTT),公式为:
SRTT=(α∗SRTT)+((1−α)∗RTT)
其中的α取值在0.8到0.9之间
3)开始计算RTO。公式如下:
RTO=min[UBOUND,max[LBOUND,(β∗SRTT)]]
UBOUND 是最大的 timeout 时间,上限值;
LBOUND 是最小的 timeout 时间,下限值;
β值一般在1.3到2.0之间。
该算法的问题在于重传时,是用重传的时间还是第一次发数据的时间和ACK回来的时间计算RTT样本值,另外,delay ack的存在也让rtt不能精确测量。
2.2 RTT标准算法(Jacobson / Karels算法)
该算法[ RFC6298 ]特点是引入了最新的RTT的采样rtts和平滑过的srtt的差值做参数来计算。 公式如下:

1)计算平滑RTT
srtt=srtt+α(rttssrtt)
2)计算平滑RTT和真实的差距(加权移动平均)
rttvar=(1−β)∗rttvar+β∗(|rtts−srtt|)
3)计算RTO
rto=u∗srtt+∂∗rttvar
4)考虑到时钟粒度,给RTO设置一个下界。
rto=max(u∗srtt+max(G,∂∗rttvar),1000)
这里G为计时器粒度,1000ms为整个RTO的下届值。因此RTO至少为 1s。在Linux下,α=0.125,β=0.25,μ=1,∂=4。
5)在首个SYN交换前,TCP无法设置RTO初始值。根据[RFC6298],RTO初始值为1s,而初始SYN报文段采用的超时间隔为3s。当计算出首个RTT测量结果rtts,则按如下方法进行初始化:
srtt=rttsrttvar=rtts/2
2.3 RTT测量方法
每发送一个分组,TCP都会进行RTT采样,这个采样并不会每一个数据包都采样,同一时刻发送的数据包中,只会针对一个数据包采样,这个采样数据被记为sampleRTT,用它来代表所有的RTT。采样的方法一般有两种:
- TCP Timestamp选项 :在TCP选项中添加时间戳选项,发送数据包的时候记录下时间,收到数据包的时候计算当前时间和时间戳的差值就能得到RTT。这个方法简单并且准确,但是需要发送段和接收端都支持这个选项。
- 重传队列中数据包的TCP控制块 :每个数据包第一次发送出去后都会放到重传队列中,数据包中的TCP控制块包含着一个变量,tcp_skb_cb->when,记录了该数据包的第一次发送时间。如果没有时间戳选项,那么RTT就等于当前时间和when的差值。
linux内核中,更新rtt的函数为tcp_ack_update_rtt:

3、RTT网络性能检测和优化
3.1 RTT时延检测方法
1)使用ping命令测量RTT是最常用的方法
Ping命令将ICMP协议回显请求数据包发送到目的地,然后报告接收响应信号所需的时间(以毫秒为单位)。
[root@tango-rac01 ~]# ping -c 20 -i 1 www.csdn.net
PING r3lzca9monbh9slnohm4wwh32vxfadus.yundunwaf4.com (60.205.172.2) 56(84) bytes of data.
--- r3lzca9monbh9slnohm4wwh32vxfadus.yundunwaf4.com ping statistics ---
20 packets transmitted, 20 received, 0% packet loss, time 20099ms
rtt min/avg/max/mdev = 45.053/62.665/163.425/29.858 ms
2)时延 bcc-tools工具tcprtt (内核版本为4.1以上)
tcprtt -i 1 -d 10 -A 192.168.1.100 -P 80
Tracing TCP RTT... Hit Ctrl-C to end.
msecs : count distribution
0 - > 1 : 4 | |
2 - > 3 : 0 | |
4 - > 7 : 1055 |****************************************|
8 - > 15 : 26 | |
16 - > 31 : 0 | |
32 - > 63 : 0 | |
64 - > 127 : 18 | |
128 - > 255 : 14 | |
256 - > 511 : 14 | |
512 - > 1023 : 12 | |
3)使用ss -ti命令
[root@tango-rac01 tools]# ss -ti
State Recv-Q Send-Q Local Address:Port Peer Address:Port
ESTAB 0 0 192.168.112.135:ssh 192.168.112.1:56505
cubic wscale:8,9 rto:241 rtt:40.225/0.997 ato:74 mss:1448 cwnd:10 bytes_acked:152109 bytes_received:12047 segs_out:733 segs_in:816 send 2.9Mbps lastsnd:41 lastrcv:137 pacing_rate 5.8Mbps rcv_rtt:28 rcv_space:28960
其中有rtt:40.225/0.997数据,表示RTT均值和中位数
3.2 RTT时延优化
1)RTT时延波动的原因
前文提到RTT时延包括网络传输时延和末端处理时延,末端处理时延相对比较固定,因此RTT波动很大可能和以下因素有关:
- 网络拥塞 :当网络拥塞时,数据包需要在网络中等待更长时间,从而导致 RTT 增加。
- 网络质量 :网络质量差、丢包率高等问题也会导致 RTT 波动较大。
- 网络设备问题 :网络设备的故障、配置错误等也可能导致 RTT 波动较大。
2) 网络拥塞的检测方法
网络拥塞是指网络中的数据传输量超过了网络链路或节点的处理能力,导致网络性能下降或出现数据丢失等问题。除了常见的传输延迟、丢包率等指标外,还有以下几种网络拥塞的检测手段:
- 流量分析:通过对网络流量的监测和分析,找出网络中的高流量区域,从而判断哪些地方可能存在拥塞。
- 响应时间监测:通过测量网络设备响应时间,判断网络是否处于拥塞状态。
- 带宽占用监测:通过对网络带宽的监测和分析,找出网络中的高带宽占用区域,从而判断哪些地方可能存在拥塞。
- 包延迟监测:通过测量数据包在网络中传输所需的时间,判断网络是否处于拥塞状态。
- 拓扑分析:通过分析网络拓扑结构,找出网络中的瓶颈节点和链路,从而判断哪些地方可能存在拥塞。
3)网络抖动检测方法
网络抖动是指网络通信中出现的延迟或者丢包现象,导致通信不稳定。要检测网络抖动,可以使用以下方法:
- ping命令 :ping命令可以测试网络是否能够正常通信,如果出现延迟或者丢包现象,就说明存在网络抖动。
- tracert命令 :tracert命令可以追踪网络通信的路径,如果在通信过程中出现延迟或者丢包现象,就说明存在网络抖动。
- 网络诊断工具 :网络诊断工具可以帮助检测网络抖动,并提供详细的网络状态信息,帮助用户更好地理解网络通信过程中出现的问题。
- 网络质量监测系统:网络质量监测系统可以监测网络质量,包括延迟、丢包等指标,并提供实时报警和分析报告,帮助用户及时发现和解决网络抖动问题。
4、总结
RTT作为网络时延的检测工具,是 在应用层进行的网络性能检测 ,包括了网络传输的时延和末端响应的时延。在实际分析过程中,主机上单个服务的RTT时延较长并不能说明服务器之间的物理网络异常,需要更多的指标数据进行分析,比如相同主机上的其它服务的RTT时延、ping包时延等。
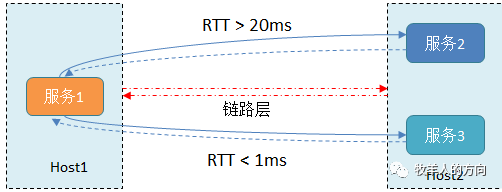
如上图所示的主机1中的服务1和主机2中的服务2和服务3配置了RTT时延监控,发现服务器1到服务2的RTT时延明显差于服务1到服务3的RTT时延。这个时候就可以辨别出,如果是网络层的性能变差,两个RTT检测的值表现上会相似,但实际上却是相反的,只能 说明服务2在响应服务1的请求处理时间比服务3长 。
因此在实际的监控配置过程中,RTT时延只能作为网络性能监控的一个参考指标,不排除会出现误判的情景,需要和其它主机和服务横向对比去分析判断。
-
2222#RTT设计大赛 #眼图jf_34552825 2025-08-11
-
RTT_Draco的外置uart接口(TXD,RXD)怎么配置和使用呢?2024-01-16 3039
-
基于IAR搭建RA MCU串口与RTT Viewer打印(上)2023-08-14 3285
-
【英飞凌PSoC 6】新建RTT工程2023-04-24 3511
-
Jlink调试打印工具RTT2023-04-06 516
-
投稿 | 基于IAR搭建RA MCU的RTT打印输出2022-11-04 2499
-
例程中如何使用RTT Viewe2022-07-28 3096
-
例程中如何使用RTT Viewer2022-06-08 3914
-
为什么要使用RTT?RTT怎么用?2022-02-16 2059
-
MM32F013x——RTT使用技巧2022-01-25 628
-
TD-SCDMA RTT的空间接口技术综述2009-05-21 1002
-
一种基于RTT公平性的TCP慢启动算法2009-03-23 1508
全部0条评论

快来发表一下你的评论吧 !
