

边缘生成人工智能推理技术面临的挑战有哪些
人工智能
描述
在不到一年的时间里,生成式人工智能通过 OpenAI 的 ChatGPT(一种基于 Transformer 的流行算法)获得了全球声誉和使用。基于 Transformer 的算法可以学习对象不同元素(例如句子或问题)之间的复杂交互,并将其转换为类似人类的对话。
在 Transformer 和其他大型语言模型 (LLM) 的引领下,软件算法取得了快速进展,而负责执行它们的处理硬件却被抛在了后面。即使是最先进的算法处理器也不具备在一两秒的时间范围内详细阐述最新 ChatGPT 查询所需的性能。
为了弥补性能不足,领先的半导体公司构建了由大量最好的硬件处理器组成的系统。在此过程中,他们权衡了功耗、带宽/延迟和成本。该方法适用于算法训练,但不适用于部署在边缘设备上的推理。
01. 功耗挑战
虽然训练通常基于生成大量数据的 fp32 或 fp64 浮点算法,但它不需要严格的延迟。功耗高,成本承受能力高。 相当不同的是推理过程。推理通常在 fp8 算法上执行,该算法仍会产生大量数据,但需要关键的延迟、低能耗和低成本。 模型训练的解决方案来自于计算场。它们运行数天,使用大量电力,产生大量热量,并且获取、安装、操作和维护成本高昂。更糟糕的是推理过程,碰壁并阻碍了 GenAI 在边缘设备上的扩散。
02. 边缘生成人工智能推理的最新技术
成功的 GenAI 推理硬件加速器必须满足五个属性:
petaflops 范围内的高处理能力和高效率(超过 50%)
低延迟,可在几秒钟内提供查询响应
能耗限制在 50W/Petaflops 或以下
成本实惠,与边缘应用兼容
现场可编程性可适应软件更新或升级,以避免工厂进行硬件改造
大多数现有的硬件加速器可以满足部分要求,但不能满足全部要求。老牌CPU是最差的选择,因为执行速度令人无法接受;GPU 在高功耗和延迟不足的情况下提供相当快的速度(因此是训练的选择);FPGA 在性能和延迟方面做出了妥协。 完美的设备将是定制/可编程片上系统 (SoC),旨在执行基于变压器的算法以及其他类型算法的发展。它应该支持合适的内存容量来存储法学硕士中嵌入的大量数据,并且应该可编程以适应现场升级。 有两个障碍阻碍了这一目标的实现:内存墙和 CMOS 器件的高能耗。
03. 内存墙
人们在半导体发展历史的早期就观察到,处理器性能的进步被内存访问的缺乏进步所抵消。 随着时间的推移,两者之间的差距不断扩大,迫使处理器等待内存传送数据的时间越来越长。结果是处理器效率从完全 100% 利用率下降(图 1)。
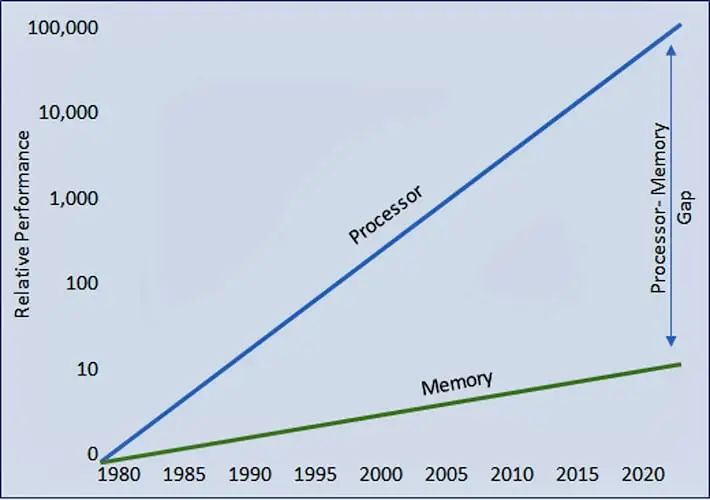
为了缓解效率的下降,业界设计了一种多级分层内存结构,采用更快、更昂贵的内存技术,靠近处理器进行多级缓存,从而最大限度地减少较慢主内存甚至较慢外部内存的流量(图 2)。
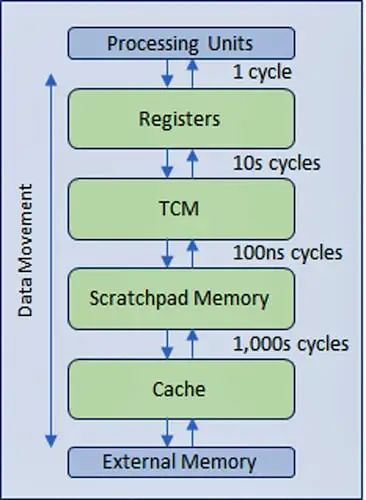
04. CMOS IC 的能耗
与直觉相反,CMOS IC 的功耗主要由数据移动而非数据处理决定。根据马克·霍洛维茨教授领导的斯坦福大学研究(表 1),内存访问的功耗比基本数字逻辑计算消耗的能量高出几个数量级。
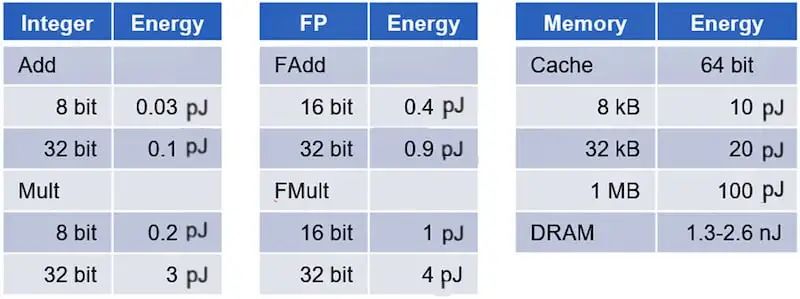
加法器和乘法器的功耗从使用整数运算时的不到一皮焦耳到处理浮点运算时的几皮焦耳。相比之下,在 DRAM 中访问数据时,访问高速缓存中的数据所花费的能量会跃升一个数量级,达到 20-100 皮焦耳,并且会跃升三个数量级,达到超过 1,000 皮焦耳。 GenAI 加速器是以数据移动为主导的设计的典型例子。
05. 内存墙和能耗对延迟和效率的影响
生成式人工智能处理中的内存墙和能耗的影响正变得难以控制。 几年之内,为 ChatGPT 提供支持的基础模型 GPT 从 2019 年的 GPT-2 发展到 2020 年的 GPT-3,再到 2022 年的 GPT-3.5,再到目前的 GPT-4。每一代模型的大小和参数(weights, tokens和states)的数量都增加了几个数量级。 GPT-2 包含 15 亿个参数,GPT-3 模型包含 1750 亿个参数,最新的 GPT-4 模型将参数规模推至约 1.7 万亿个参数(尚未发布官方数字)。 这些参数的庞大数量不仅迫使内存容量达到 TB 范围,而且在训练/推理过程中同时高速访问它们也会将内存带宽推至数百 GB/秒(如果不是 TB/秒)。为了进一步加剧这种情况,移动它们会消耗大量的能量。
06. 昂贵的硬件闲置
内存和处理器之间令人畏惧的数据传输带宽以及显着的功耗压倒了处理器的效率。最近的分析表明,在尖端硬件上运行 GPT-4 的效率下降至 3% 左右。为运行这些算法而设计的昂贵硬件在 97% 的时间内处于闲置状态。 执行效率越低,执行相同任务所需的硬件就越多。例如,假设 1 Petaflops(1,000 Teraflops)的要求可以由两个供应商满足。供应商(A 和 B)提供不同的处理效率,分别为 5% 和 50%(表 2)。 那么供应商 A 只能提供 50 Teraflops 的有效处理能力,而不是理论处理能力。供应商 B 将提供 500 Teraflops。为了提供 1 petaflop 的有效计算能力,供应商 A 需要 20 个处理器,但供应商 B 只需 2 个。
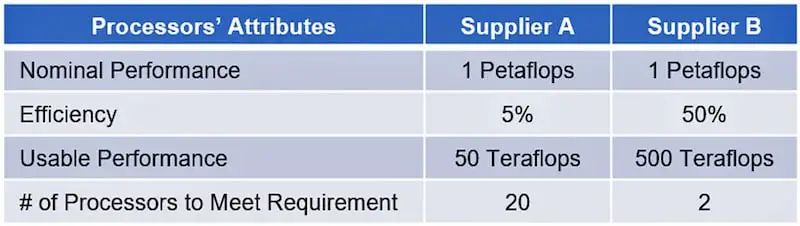
例如,一家硅谷初创公司计划在其超级计算机数据中心使用 22,000 个 Nvidia H100 GPU。粗略计算,22,000 个 H100 GPU 的售价为 8 亿美元——这是其最新融资的大部分。该数字不包括其余基础设施的成本、房地产、能源成本以及本地硬件总拥有成本 (TCO) 中的所有其他因素。
07. 系统复杂性对延迟和效率的影响
另一个例子,基于当前最先进的 GenAI 训练加速器,将有助于说明这种担忧。硅谷初创公司的 GPT-4 配置将需要 22,000 个 Nvidia H100 GPU 副本以八位字节的形式部署在HGX H100 或 DGX H100 系统,总共产生 2,750 个系统。 考虑到 GPT-4 包括 96 个解码器,将它们映射到多个芯片上可能会减轻对延迟的影响。由于 GPT 结构允许顺序处理,因此为总共 96 个芯片为每个芯片分配一个解码器可能是一种合理的设置。 该配置可转换为 12 个 HGX/DGX H100 系统,不仅对单芯片之间、电路板之间和系统之间移动数据带来的延迟提出挑战。使用增量变压器可以显着降低处理复杂性,但它需要状态的处理和存储,这反过来又增加了要处理的数据量。 底线是,前面提到的 3% 的实施效率是不现实的。当加上系统实现的影响以及相关的较长延迟时,实际应用程序中的实际效率将显着下降。 综合来看,GPT-3.5所需的数据量远不及GPT-4。从商业角度来看,使用类似 GPT-3 的复杂性比 GPT-4 更具吸引力。另一方面是 GPT-4 更准确,如果可以解决硬件挑战,它会成为首选。
08. 最佳猜测成本分析
让我们重点关注能够处理大量查询的系统的实施成本,例如类似 Google 的每秒 100,000 个查询的量。 使用当前最先进的硬件,可以合理地假设总拥有成本(包括购置成本、系统运营和维护成本)约为 1 万亿美元。据记录,这大约相当于世界第八大经济体意大利 2021 年国内生产总值 (GDP) 的一半。 ChatGPT 对每次查询成本的影响使其在商业上具有挑战性。摩根士丹利估计,2022 年 Google 搜索查询(3.3 万亿次查询)的每次查询成本为 0.2 英镑(被视为基准)。同一分析表明,ChatGPT-3 上的每次查询成本在 3 到 14 欧元之间,比基准高 15-70 倍。 半导体行业正在积极寻找应对成本/查询挑战的解决方案。尽管所有尝试都受到欢迎,但解决方案必须来自新颖的芯片架构,该架构将打破内存墙并大幅降低功耗。
编辑:黄飞
-
《移动终端人工智能技术与应用开发》+快速入门AI的捷径+书中案例实操2023-02-19 2364
-
【开源硬件系列04期】AI人工智能技术带给EDA的机遇和挑战(文中含回放+课件)2023-01-17 6910
-
传统人工智能面临的挑战2022-10-26 1455
-
人工智能对汽车芯片设计的影响是什么2021-12-17 2240
-
物联网人工智能是什么?2021-09-09 5358
-
中国人工智能的现状与未来2021-07-27 6737
-
什么是边缘人工智能_边缘人工智能应用2020-12-01 7239
-
人工智能:超越炒作2019-05-29 5048
-
人工智能医生未来或上线,人工智能医疗市场规模持续增长2019-02-24 5906
-
解读人工智能的未来2018-11-14 4942
-
人工智能--失业将是人类面临的最大挑战2016-06-27 5891
-
人工智能传感技术2016-06-03 35085
-
人工智能技术—AI2015-10-21 9807
-
人工智能是什么?2015-09-16 6455
全部0条评论

快来发表一下你的评论吧 !
