

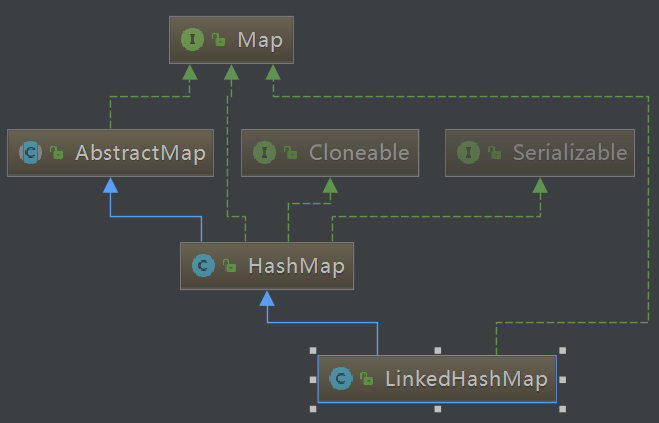
Map类集合基本元素的实现演变
描述
说到集合类,之前介绍的ArrayList类,HashMap可能是大家日常用的最多的类,但是对于另一个集合类 LinkedHashMap,可能大家用的不多,但是这种链式哈希集合,有些情况确实特别好用。
1、LinkedHashMap 定义
LinkedHashMap 是基于 HashMap 实现的一种集合,具有 HashMap 集合上面所说的所有特点,除了 HashMap 无序的特点,LinkedHashMap 是有序的,因为 LinkedHashMap 在 HashMap 的基础上单独维护了一个具有所有数据的双向链表,该链表保证了元素迭代的顺序。
所以我们可以直接这样说:LinkedHashMap = HashMap + LinkedList。LinkedHashMap 就是在 HashMap 的基础上多维护了一个双向链表,用来保证元素迭代顺序。
更形象化的图形展示可以直接移到文章末尾。
public class LinkedHashMap< K,V >
extends HashMap< K,V >
implements Map< K,V >
2、字段属性
①、Entry
static class Entry< K,V > extends HashMap.Node< K,V > {
Entry< K,V > before, after;
Entry(int hash, K key, V value, Node< K,V > next) {
super(hash, key, value, next);
}
}
LinkedHashMap 的每个元素都是一个 Entry,我们看到对于 Entry 继承自 HashMap 的 Node 结构,相对于 Node 结构,LinkedHashMap 多了 before 和 after 结构。
下面是Map类集合基本元素的实现演变。

LinkedHashMap 中 Entry 相对于 HashMap 多出的 before 和 after 便是用来维护 LinkedHashMap 插入 Entry 的先后顺序的。
②、其它属性
//用来指向双向链表的头节点
transient LinkedHashMap.Entry< K,V > head;
//用来指向双向链表的尾节点
transient LinkedHashMap.Entry< K,V > tail;
//用来指定LinkedHashMap的迭代顺序
//true 表示按照访问顺序,会把访问过的元素放在链表后面,放置顺序是访问的顺序
//false 表示按照插入顺序遍历
final boolean accessOrder;
注意:这里有五个属性别搞混淆的,对于 Node next 属性,是用来维护整个集合中 Entry 的顺序。对于 Entry before,Entry after ,以及 Entry head,Entry tail,这四个属性都是用来维护保证集合顺序的链表,其中前两个before和after表示某个节点的上一个节点和下一个节点,这是一个双向链表。后两个属性 head 和 tail 分别表示这个链表的头节点和尾节点。
3、构造函数
①、无参构造
public LinkedHashMap() {
super();
accessOrder = false;
}
调用无参的 HashMap 构造函数,具有默认初始容量(16)和加载因子(0.75)。并且设定了 accessOrder = false,表示默认按照插入顺序进行遍历。
②、指定初始容量
public LinkedHashMap(int initialCapacity) {
super(initialCapacity);
accessOrder = false;
}
③、指定初始容量和加载因子
public LinkedHashMap(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor);
accessOrder = false;
}
4、添加元素
LinkedHashMap 中是没有 put 方法的,直接调用父类 HashMap 的 put 方法。关于 HashMap 的put 方法,可以参看我之前对于 HashMap 的介绍。
我将方法介绍复制到下面:
//hash(key)就是上面讲的hash方法,对其进行了第一步和第二步处理
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
/**
*
* @param hash 索引的位置
* @param key 键
* @param value 值
* @param onlyIfAbsent true 表示不要更改现有值
* @param evict false表示table处于创建模式
* @return
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node< K,V >[] tab; Node< K,V > p; int n, i;
//如果table为null或者长度为0,则进行初始化
//resize()方法本来是用于扩容,由于初始化没有实际分配空间,这里用该方法进行空间分配,后面会详细讲解该方法
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//注意:这里用到了前面讲解获得key的hash码的第三步,取模运算,下面的if-else分别是 tab[i] 为null和不为null
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);//tab[i] 为null,直接将新的key-value插入到计算的索引i位置
else {//tab[i] 不为null,表示该位置已经有值了
Node< K,V > e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;//节点key已经有值了,直接用新值覆盖
//该链是红黑树
else if (p instanceof TreeNode)
e = ((TreeNode< K,V >)p).putTreeVal(this, tab, hash, key, value);
//该链是链表
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
//链表长度大于8,转换成红黑树
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
//key已经存在直接覆盖value
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;//用作修改和新增快速失败
if (++size > threshold)//超过最大容量,进行扩容
resize();
afterNodeInsertion(evict);
return null;
}
5、删除元素
同理也是调用 HashMap 的remove 方法,这里我不作过多的讲解,着重看LinkedHashMap 重写的第 46 行方法。
public V remove(Object key) {
Node< K,V > e;
return (e = removeNode(hash(key), key, null, false, true)) == null ?
null : e.value;
}
final Node< K,V > removeNode(int hash, Object key, Object value,
boolean matchValue, boolean movable) {
Node< K,V >[] tab; Node< K,V > p; int n, index;
//(n - 1) & hash找到桶的位置
if ((tab = table) != null && (n = tab.length) > 0 &&
(p = tab[index = (n - 1) & hash]) != null) {
Node< K,V > node = null, e; K k; V v;
//如果键的值与链表第一个节点相等,则将 node 指向该节点
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
node = p;
//如果桶节点存在下一个节点
else if ((e = p.next) != null) {
//节点为红黑树
if (p instanceof TreeNode)
node = ((TreeNode< K,V >)p).getTreeNode(hash, key);//找到需要删除的红黑树节点
else {
do {//遍历链表,找到待删除的节点
if (e.hash == hash &&
((k = e.key) == key ||
(key != null && key.equals(k)))) {
node = e;
break;
}
p = e;
} while ((e = e.next) != null);
}
}
//删除节点,并进行调节红黑树平衡
if (node != null && (!matchValue || (v = node.value) == value ||
(value != null && value.equals(v)))) {
if (node instanceof TreeNode)
((TreeNode< K,V >)node).removeTreeNode(this, tab, movable);
else if (node == p)
tab[index] = node.next;
else
p.next = node.next;
++modCount;
--size;
afterNodeRemoval(node);
return node;
}
}
return null;
}
6、查找元素
public V get(Object key) {
Node< K,V > e;
if ((e = getNode(hash(key), key)) == null)
return null;
if (accessOrder)
afterNodeAccess(e);
return e.value;
}
相比于 HashMap 的 get 方法,这里多出了第 5,6行代码,当 accessOrder = true 时,即表示按照最近访问的迭代顺序,会将访问过的元素放在链表后面。
对于 afterNodeAccess(e) 方法,在前面第 4 小节 添加元素已经介绍过了,这就不在介绍。
7、遍历元素
在介绍 HashMap 时,我们介绍了 4 中遍历方式,同理,对于 LinkedHashMap 也有 4 种,这里我们介绍效率较高的两种遍历方式:
①、得到 Entry 集合,然后遍历 Entry
LinkedHashMap< String,String > map = new LinkedHashMap< >();
map.put("A","1");
map.put("B","2");
map.put("C","3");
map.get("B");
Set< Map.Entry< String,String > > entrySet = map.entrySet();
for(Map.Entry< String,String > entry : entrySet ){
System.out.println(entry.getKey()+"---"+entry.getValue());
}
②、迭代
Iterator< Map.Entry< String,String > > iterator = map.entrySet().iterator();
while(iterator.hasNext()){
Map.Entry< String,String > entry = iterator.next();
System.out.println(entry.getKey()+"----"+entry.getValue());
}
8、小结
好了,这就是JDK中java.util.LinkedHashMap 类的介绍。
-
【labview我来告诉你】实现任何LabVIEW数据类型集合的简洁方式2011-12-30 5200
-
【labview我来告诉你】简洁的实现任何 LabVIEW 数据类型的集合2012-01-11 7771
-
简洁的实现任何 LabVIEW 数据类型的集合2012-12-17 2828
-
java集合干货系列2017-12-14 3259
-
干货!对 buck-boost 进行演变,最终会演变成 flyback2019-01-12 4440
-
python入门知识:什么是set集合2019-09-24 2758
-
python集合2022-02-23 1436
-
JAVA集合类汇总2018-01-16 4589
-
数组与集合类说明2021-03-17 1108
-
什么是 map?2023-02-27 5339
-
python集合表达式及方法2023-03-10 2317
-
Java8的Stream流 map() 方法2023-09-25 3280
-
List 转 Map的方法2023-10-09 2939
全部0条评论

快来发表一下你的评论吧 !
