

基于python进行语音识别的实现方案
编程语言及工具
描述
语音识别技术,也被称为自动语音识别,目标是以电脑自动将以人类的语音内容转换为相应的文字和文字转换为语音。
一. 文本转换为语音
1.1 使用pyttsx
使用名为pyttsx的python包,可以将文本转换为语音。
安装pyttsx包
pip install pyttsx3
示例
import pyttsx3 as pyttsx
engine = pyttsx.init()
engine.say("Python由荷兰数学和计算机科学研究学会的吉多·范罗苏姆于1990年代初设计,作为一门叫做ABC语言的替代品。")
engine.runAndWait()
运行之后可以播放语音。
1.2 使用SAPI
在python 中,也可以使用SAPI 来将文本转换为语音。
使用Win32com.client包,不需要另外安装。
示例
from win32com.client import Dispatch
msg ="Python由荷兰数学和计算机科学研究学会的吉多·范罗苏姆于1990年代初设计,作为一门叫做ABC语言的替代品。"
speaker = Dispatch("SAPI.SpVoice")
speaker.Speak(msg)
del speaker
使用SpeechLib可以将文本转换为语音文件
使用SpeechLib,可以从文本文件中获取输入,再将其转换为语音文件。先使用pip安装,命令如下:
pip install comtypes
示例
from comtypes.client import CreateObject
from comtypes.gen import SpeechLib
infile = 'C:\Users\10619\Desktop\fileText.txt'
f = open(infile, 'r')
theText = f.read()
f.close()
outfile = 'demo_audio.wav'
engine = CreateObject("SAPI.SpVoice")
stream = CreateObject("SAPI.SpFileStream")
stream.Open(outfile,SpeechLib.SSFMCreateForWrite)
engine.AudioOutputStream = stream
engine.speak(theText)
stream.close()
运行之后,会输出demo_audio.wav语音文件,打开demo_audio.wav文件并播放。
二. 语音转换为文本
使用PocketSphinx包, PocketSphinx是一个用于语音转换文本的开源API。它是一个轻量级的语音识别引擎,尽管在桌面端也能很好的工作,它还专门为手机和移动设备做过调优。首先使用pip命令安装所需模块,命令如下:
pip install PocketSphinx pip install SpeechRecognition
在安装PocketSphinx 可能会报错(ERROR: Could not build wheels for pocketsphinx, which is required to install pyproject.toml-based projects)。解决方法:通过查看pip可安装文件,查看可安装的文件命令:pip debug --verbose,然后查看Compatible tags: 33下可以安装的版本。
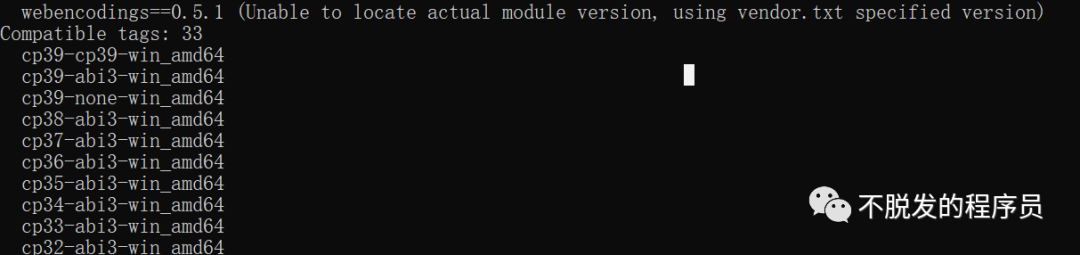
然后到https://www.lfd.uci.edu/~gohlke/pythonlibs/#pocketsphinx,下载对应版本的whl文件包安装。
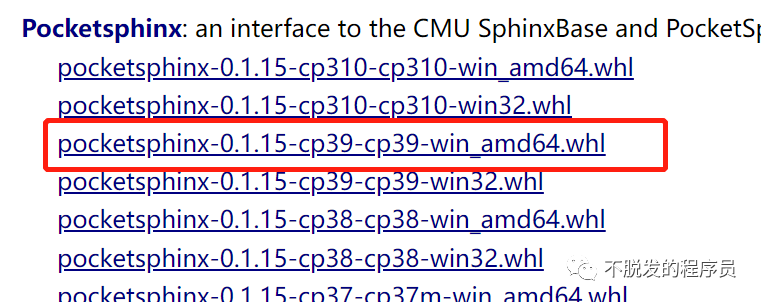

然后再安装PocketSphinx和SpeechRecognition包。

脚本示例
import speech_recognition as sr
r = sr.Recognizer()
audio_file = 'demo_audio.wav'
with sr.AudioFile(audio_file) as source:
audio = r.record(source)
try:
print("文本内容:",r.recognize_sphinx(audio,language='zh-CN'))
#默认会识别为英文,如果要识别中文,需要下载普通话识别文件
except Exception as e:
print(e)
下载普通话识别文件。
下载路径:https://sourceforge.net/projects/cmusphinx/files/Acoustic%20and%20Language%20Models/Mandarin/
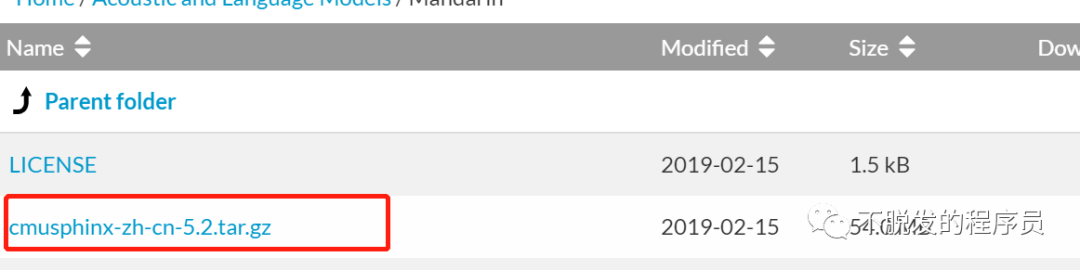
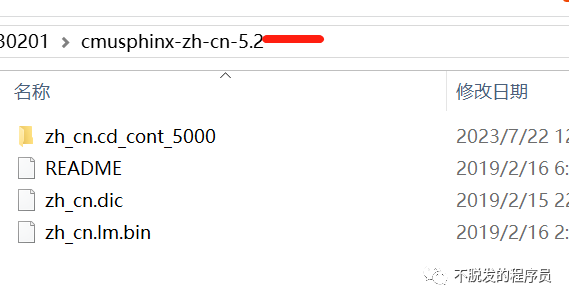
解压之后,修改文件名称,cmusphinx-zh-cn-5.2 改为 zh-CN, zh_cn.cd_cont_5000文件夹改为acoustic-model,zh_cn.dic改为pronounciation-dictionary.dict,zh_cn.lm.bin改为language-model.lm.bin。然后移动zn-CN文件夹到python3Libsite-packagesspeech_recognitionpocketsphinx-data下。
运行python之后,可以查看输出的文本内容。
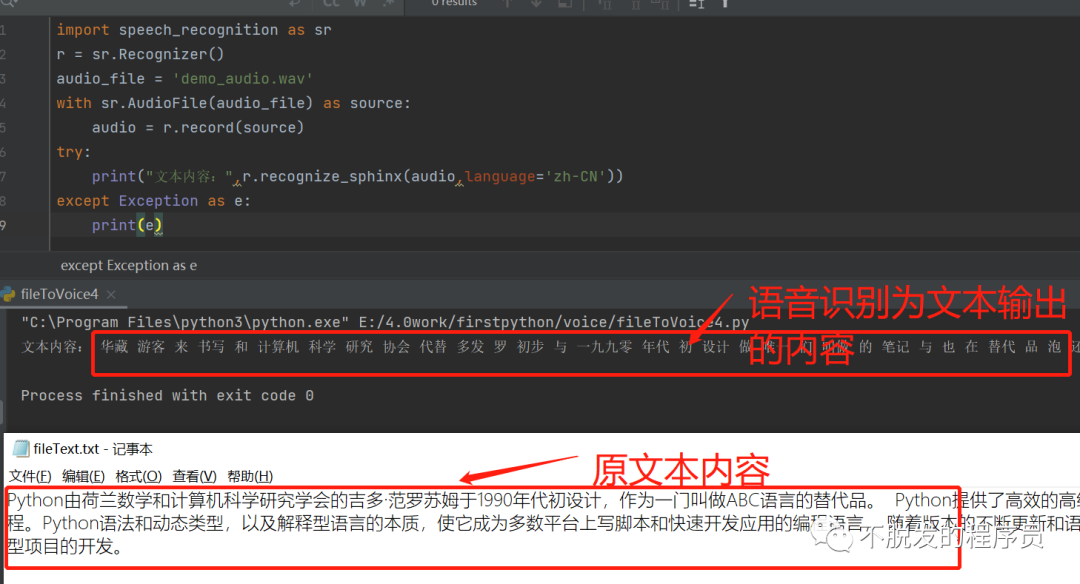
通过输出的语音转换之后的文本和原文本比较发现,语音识别的后文本还是有一定差异的。
编辑:黄飞
-
使用Python卷积神经网络(CNN)进行图像识别的基本步骤2023-11-20 8797
-
基于LD3220的语音识别的模块进行DIY的小车2018-05-10 7174
-
基于pyaudio利用python进行语音生成和语音识别详解2018-12-27 2049
-
自动语音识别的原理是什么?2021-06-15 2999
-
基于语音识别的人机交互方式浅析2022-01-25 2587
-
基于语音识别的IVR系统的设计与实现2009-06-16 910
-
使用python进行语音识别的终极指南2019-02-15 3988
-
实验python进行图像识别的示例代码资料免费下载2019-06-14 1600
-
语音识别的两个方法_语音识别的应用有哪些2020-04-01 6788
-
使用Python实现车牌识别的程序免费下载2020-09-11 1400
-
语音识别发展 Python进行语音识别案例2023-07-19 944
-
情感语音识别的研究方法与实践2023-11-16 1916
-
情感语音识别的应用与挑战2023-11-30 1762
-
如何使用Python进行图像识别的自动学习自动训练?2024-01-12 1822
-
语音识别的技术历程及工作原理2024-03-22 8179
全部0条评论

快来发表一下你的评论吧 !
