

嵌入式开发中的C语言编译器设置
嵌入式技术
描述
如果你和一个优秀的程序员共事,你会发现他对他使用的工具非常熟悉,就像一个画家了解他的画具一样。----比尔.盖茨
1 不能简单的认为是个工具
嵌入式程序开发跟硬件密切相关,需要使用C语言来读写底层寄存器、存取数据、控制硬件等,C语言和硬件之间由编译器来联系,一些C标准不支持的硬件特性操作,由编译器提供。
汇编可以很轻易的读写指定RAM地址、可以将代码段放入指定的Flash地址、可以精确的设置变量在RAM中分布等等,所有这些操作,在深入了解编译器后,也可以使用C语言实现。
C语言标准并非完美,有着数目繁多的未定义行为,这些未定义行为完全由编译器自主决定,了解你所用的编译器对这些未定义行为的处理,是必要的。
嵌入式编译器对调试做了优化,会提供一些工具,可以分析代码性能,查看外设组件等,了解编译器的这些特性有助于提高在线调试的效率。
此外,堆栈操作、代码优化、数据类型的范围等等,都是要深入了解编译器的理由。
如果之前你认为编译器只是个工具,能够编译就好。那么,是时候改变这种思想了。
2 不能依赖编译器的语义检查
编译器的语义检查很弱小,甚至还会“掩盖”错误。现代的编译器设计是件浩瀚的工程,为了让编译器设计简单一些,目前几乎所有编译器的语义检查都比较弱小。为了获得更快的执行效率,C语言被设计的足够灵活且几乎不进行任何运行时检查,比如数组越界、指针是否合法、运算结果是否溢出等等。这就造成了很多编译正确但执行奇怪的程序。
C语言足够灵活,对于一个数组test[30],它允许使用像test[-1]这样的形式来快速获取数组首元素所在地址前面的数据;允许将一个常数强制转换为函数指针,使用代码(((void()())0))()来调用位于0地址的函数。C语言给了程序员足够的自由,但也由程序员承担滥用自由带来的责任。
2.1莫名的死机
下面的两个例子都是死循环,如果在不常用分支中出现类似代码,将会造成看似莫名其妙的死机或者重启。
unsigned char i; //例程1
for(i=0;i<256;i++)
{
//其它代码
}
unsigned char i; //例程2
for(i=10;i>=0;i--)
{
//其它代码
}
对于无符号char类型,表示的范围为0~255,所以无符号char类型变量i永远小于256(第一个for循环无限执行),永远大于等于0(第二个for循环无限执行)。需要说明的是,赋值代码i=256是被C语言允许的,即使这个初值已经超出了变量i可以表示的范围。C语言会千方百计的为程序员创造出错的机会,可见一斑。
2.2不起眼的改变
假如你在if语句后误加了一个分号,可能会完全改变了程序逻辑。编译器也会很配合的帮忙掩盖,甚至连警告都不提示。代码如下:
if(a>b); //这里误加了一个分号 a=b; //这句代码一直被执行
不但如此,编译器还会忽略掉多余的空格符和换行符,就像下面的代码也不会给出足够提示:

这段代码的本意是n<3时程序直接返回,由于程序员的失误,return少了一个结束分号。编译器将它翻译成返回表达式logrec.data=x[0]的结果,return后面即使是一个表达式也是C语言允许的。这样当n>=3时,表达式logrec.data=x[0];就不会被执行,给程序埋下了隐患。
2.3 难查的数组越界
上文曾提到数组常常是引起程序不稳定的重要因素,程序员往往不经意间就会写数组越界。
一位同事的代码在硬件上运行,一段时间后就会发现LCD显示屏上的一个数字不正常的被改变。经过一段时间的调试,问题被定位到下面的一段代码中:
int SensorData[30];
//其他代码
for(i=30;i>0;i--)
{
SensorData[i]=…;
//其他代码
}
这里声明了拥有30个元素的数组,不幸的是for循环代码中误用了本不存在的数组元素SensorData[30],但C语言却默许这么使用,并欣然的按照代码改变了数组元素SensorData[30]所在位置的值, SensorData[30]所在的位置原本是一个LCD显示变量,这正是显示屏上的那个值不正常被改变的原因。真庆幸这么轻而易举的发现了这个Bug。
其实很多编译器会对上述代码产生一个警告:赋值超出数组界限。但并非所有程序员都对编译器警告保持足够敏感,况且,编译器也并不能检查出数组越界的所有情况。比如下面的例子:
你在模块A中定义数组:
int SensorData[30];
在模块B中引用该数组,但由于你引用代码并不规范,这里没有显示声明数组大小,但编译器也允许这么做:
extern int SensorData[];
这次,编译器不会给出警告信息,因为编译器压根就不知道数组的元素个数。所以,当一个数组声明为具有外部链接,它的大小应该显式声明。
再举一个编译器检查不出数组越界的例子。函数func()的形参是一个数组形式,函数代码简化如下所示:

这个给SensorData[30]赋初值的语句,编译器也是不给任何警告的。实际上,编译器是将数组名Sensor隐含的转化为指向数组第一个元素的指针,函数体是使用指针的形式来访问数组的,它当然也不会知道数组元素的个数了。造成这种局面的原因之一是C编译器的作者们认为指针代替数组可以提高程序效率,而且,可以简化编译器的复杂度。
指针和数组是容易给程序造成混乱的,我们有必要仔细的区分它们的不同。其实换一个角度想想,它们也是容易区分的:可以将数组名等同于指针的情况有且只有一处,就是上面例子提到的数组作为函数形参时。其它时候,数组名是数组名,指针是指针。
下面的例子编译器同样检查不出数组越界。
我们常常用数组来缓存通讯中的一帧数据。在通讯中断中将接收的数据保存到数组中,直到一帧数据完全接收后再进行处理。即使定义的数组长度足够长,接收数据的过程中也可能发生数组越界,特别是干扰严重时。
这是由于外界的干扰破坏了数据帧的某些位,对一帧的数据长度判断错误,接收的数据超出数组范围,多余的数据改写与数组相邻的变量,造成系统崩溃。由于中断事件的异步性,这类数组越界编译器无法检查到。
如果局部数组越界,可能引发ARM架构硬件异常。
同事的一个设备用于接收无线传感器的数据,一次软件升级后,发现接收设备工作一段时间后会死机。调试表明ARM7处理器发生了硬件异常,异常处理代码是一段死循环(死机的直接原因)。接收设备有一个硬件模块用于接收无线传感器的整包数据并存在自己的缓冲区中,当硬件模块接收数据完成后,使用外部中断通知设备取数据,外部中断服务程序精简后如下所示:
__irq ExintHandler(void)
{
unsignedchar DataBuf[50];
GetData(DataBug); //从硬件缓冲区取一帧数据
//其他代码
}
由于存在多个无线传感器近乎同时发送数据的可能加之GetData()函数保护力度不够,数组DataBuf在取数据过程中发生越界。由于数组DataBuf为局部变量,被分配在堆栈中,同在此堆栈中的还有中断发生时的运行环境以及中断返回地址。溢出的数据将这些数据破坏掉,中断返回时PC指针可能变成一个不合法值,硬件异常由此产生。
如果我们精心设计溢出部分的数据,化数据为指令,就可以利用数组越界来修改PC指针的值,使之指向我们希望执行的代码。
1988年,第一个网络蠕虫在一天之内感染了2000到6000台计算机,这个蠕虫程序利用的正是一个标准输入库函数的数组越界Bug。起因是一个标准输入输出库函数gets(),原来设计为从数据流中获取一段文本,遗憾的是,gets()函数没有规定输入文本的长度。
gets()函数内部定义了一个500字节的数组,攻击者发送了大于500字节的数据,利用溢出的数据修改了堆栈中的PC指针,从而获取了系统权限。目前,虽然有更好的库函数来代替gets函数,但gets函数仍然存在着。
2.4神奇的volatile
做嵌入式设备开发,如果不对volatile修饰符具有足够了解,实在是说不过去。volatile是C语言32个关键字中的一个,属于类型限定符,常用的const关键字也属于类型限定符。
volatile限定符用来告诉编译器,该对象的值无任何持久性,不要对它进行任何优化;它迫使编译器每次需要该对象数据内容时都必须读该对象,而不是只读一次数据并将它放在寄存器中以便后续访问之用(这样的优化可以提高系统速度)。
这个特性在嵌入式应用中很有用,比如你的IO口的数据不知道什么时候就会改变,这就要求编译器每次都必须真正的读取该IO端口。这里使用了词语“真正的读”,是因为由于编译器的优化,你的逻辑反应到代码上是对的,但是代码经过编译器翻译后,有可能与你的逻辑不符。
你的代码逻辑可能是每次都会读取IO端口数据,但实际上编译器将代码翻译成汇编时,可能只是读一次IO端口数据并保存到寄存器中,接下来的多次读IO口都是使用寄存器中的值来进行处理。因为读写寄存器是最快的,这样可以优化程序效率。与之类似的,中断里的变量、多线程中的共享变量等都存在这样的问题。
不使用volatile,可能造成运行逻辑错误,但是不必要的使用volatile会造成代码效率低下(编译器不优化volatile限定的变量),因此清楚的知道何处该使用volatile限定符,是一个嵌入式程序员的必修内容。
一个程序模块通常由两个文件组成,源文件和头文件。如果你在源文件定义变量:
unsigned int test;
并在头文件中声明该变量:
extern unsigned long test;
编译器会提示一个语法错误:变量’ test’声明类型不一致。但如果你在源文件定义变量:
volatile unsigned int test;
在头文件中这样声明变量:
extern unsigned int test; /*缺少volatile限定符*/
编译器却不会给出错误信息(有些编译器仅给出一条警告)。当你在另外一个模块(该模块包含声明变量test的头文件)使用变量test时,它已经不再具有volatile限定,这样很可能造成一些重大错误。比如下面的例子,注意该例子是为了说明volatile限定符而专门构造出的,因为现实中的volatile使用Bug大都隐含,并且难以理解。
在模块A的源文件中,定义变量:
volatile unsigned int TimerCount=0;
该变量用来在一个定时器中断服务程序中进行软件计时:
TimerCount++;
在模块A的头文件中,声明变量:
extern unsigned int TimerCount; //这里漏掉了类型限定符volatile
在模块B中,要使用TimerCount变量进行精确的软件延时:
#include “…A.h” //首先包含模块A的头文件 //其他代码 TimerCount=0; while(TimerCount<=TIMER_VALUE); //延时一段时间(感谢网友chhfish指这里的逻辑错误) //其他代码
实际上,这是一个死循环。由于模块A头文件中声明变量TimerCount时漏掉了volatile限定符,在模块B中,变量TimerCount是被当作unsigned int类型变量。由于寄存器速度远快于RAM,编译器在使用非volatile限定变量时是先将变量从RAM中拷贝到寄存器中,如果同一个代码块再次用到该变量,就不再从RAM中拷贝数据而是直接使用之前寄存器备份值。
代码while(TimerCount<=TIMER_VALUE)中,变量TimerCount仅第一次执行时被使用,之后都是使用的寄存器备份值,而这个寄存器值一直为0,所以程序无限循环。下面的流程图说明了程序使用限定符volatile和不使用volatile的执行过程。
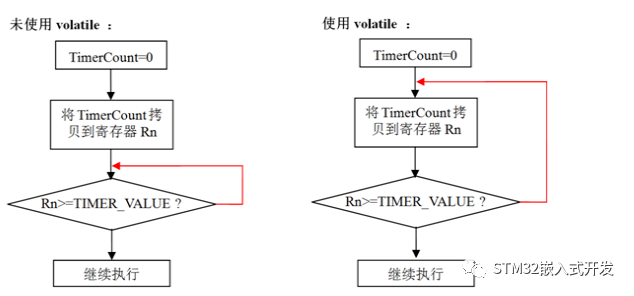
为了更容易的理解编译器如何处理volatile限定符,这里给出未使用volatile限定符和使用volatile限定符程序的反汇编代码:
没有使用关键字volatile,在keil MDK V4.54下编译,默认优化级别,如下所示(注意最后两行):
122: unIdleCount=0;
123:
0x00002E10 E59F11D4 LDR R1,[PC,#0x01D4]
0x00002E14 E3A05000 MOV R5,#key1(0x00000000)
0x00002E18 E1A00005 MOV R0,R5
0x00002E1C E5815000 STR R5,[R1]
124: while(unIdleCount!=200); //延时2S钟
125:
0x00002E20 E35000C8 CMP R0,#0x000000C8
0x00002E24 1AFFFFFD BNE 0x00002E20
使用关键字volatile,在keil MDK V4.54下编译,默认优化级别,如下所示(注意最后三行):
122: unIdleCount=0;
123:
0x00002E10 E59F01D4 LDR R0,[PC,#0x01D4]
0x00002E14 E3A05000 MOV R5,#key1(0x00000000)
0x00002E18 E5805000 STR R5,[R0]
124: while(unIdleCount!=200); //延时2S钟
125:
0x00002E1C E5901000 LDR R1,[R0]
0x00002E20 E35100C8 CMP R1,#0x000000C8
0x00002E24 1AFFFFFC BNE 0x00002E1C
可以看到,如果没有使用volatile关键字,程序一直比较R0内数据与0xC8是否相等,但R0中的数据是0,所以程序会一直在这里循环比较(死循环);再看使用了volatile关键字的反汇编代码,程序会先从变量中读出数据放到R1寄存器中,然后再让R1内数据与0xC8相比较,这才是我们C代码的正确逻辑!
2.5局部变量
ARM架构下的编译器会频繁的使用堆栈,堆栈用于存储函数的返回值、AAPCS规定的必须保护的寄存器以及局部变量,包括局部数组、结构体、联合体和C++的类。默认情况下,堆栈的位置、初始值都是由编译器设置,因此需要对编译器的堆栈有一定了解。
从堆栈中分配的局部变量的初值是不确定的,因此需要运行时显式初始化该变量。一旦离开局部变量的作用域,这个变量立即被释放,其它代码也就可以使用它,因此堆栈中的一个内存位置可能对应整个程序的多个变量。
局部变量必须显式初始化,除非你确定知道你要做什么。下面的代码得到的温度值跟预期会有很大差别,因为在使用局部变量sum时,并不能保证它的初值为0。编译器会在第一次运行时清零堆栈区域,这加重了此类Bug的隐蔽性。

由于一旦程序离开局部变量的作用域即被释放,所以下面代码返回指向局部变量的指针是没有实际意义的,该指针指向的区域可能会被其它程序使用,其值会被改变。
char * GetData(void)
{
char buffer[100]; //局部数组
…
return buffer;
}
2.6使用外部工具
由于编译器的语义检查比较弱,我们可以使用第三方代码分析工具,使用这些工具来发现潜在的问题,这里介绍其中比较著名的是PC-Lint。
PC-Lint由Gimpel Software公司开发,可以检查C代码的语法和语义并给出潜在的BUG报告。PC-Lint可以显著降低调试时间。
目前公司ARM7和Cortex-M3内核多是使用Keil MDK编译器来开发程序,通过简单配置,PC-Lint可以被集成到MDK上,以便更方便的检查代码。MDK已经提供了PC-Lint的配置模板,所以整个配置过程十分简单,Keil MDK开发套件并不包含PC-Lint程序,在此之前,需要预先安装可用的PC-Lint程序,配置过程如下:
点击菜单Tools---Set-up PC-Lint…
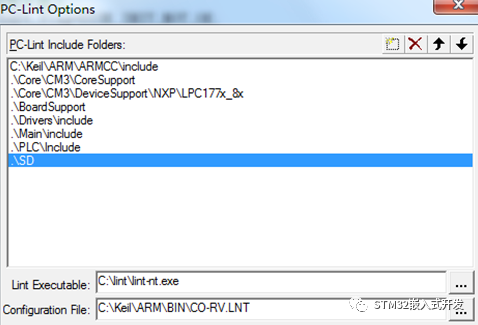
PC-Lint Include Folders:该列表路径下的文件才会被PC-Lint检查,此外,这些路径下的文件内使用#include包含的文件也会被检查;
Lint Executable:指定PC-Lint程序的路径
Configuration File:指定配置文件的路径,该配置文件由MDK编译器提供。
菜单Tools---Lint 文件路径.c/.h
检查当前文件。
菜单Tools---Lint All C-Source Files
检查所有C源文件。
PC-Lint的输出信息显示在MDK编译器的Build Output窗口中,双击其中的一条信息可以跳转到源文件所在位置。
编译器语义检查的弱小在很大程度上助长了不可靠代码的广泛存在。随着时代的进步,现在越来越多的编译器开发商意识到了语义检查的重要性,编译器的语义检查也越来越强大,比如公司使用的Keil MDK编译器,虽然它的编辑器依然不尽人意,但在其V4.47及以上版本中增加了动态语法检查并加强了语义检查,可以友好的提示更多警告信息。建议经常关注编译器官方网站并将编译器升级到V4.47或以上版本,升级的另一个好处是这些版本的编辑器增加了标识符自动补全功能,可以大大节省编码的时间。
3 你觉得有意义的代码未必正确
C语言标准特别的规定某些行为是未定义的,编写未定义行为的代码,其输出结果由编译器决定!C标准委员会定义未定义行为的原因如下:
简化标准,并给予实现一定的灵活性,比如不捕捉那些难以诊断的程序错误;
编译器开发商可以通过未定义行为对语言进行扩展
C语言的未定义行为,使得C极度高效灵活并且给编译器实现带来了方便,但这并不利于优质嵌入式C程序的编写。因为许多 C 语言中看起来有意义的东西都是未定义的,并且这也容易使你的代码埋下隐患,并且不利于跨编译器移植。Java程序会极力避免未定义行为,并用一系列手段进行运行时检查,使用Java可以相对容易的写出安全代码,但体积庞大效率低下。作为嵌入式程序员,我们需要了解这些未定义行为,利用C语言的灵活性,写出比Java更安全、效率更高的代码来。
3.1常见的未定义行为
自增自减在表达式中连续出现并作用于同一变量或者自增自减在表达式中出现一次,但作用的变量多次出现
自增(++)和自减(--)这一动作发生在表达式的哪个时刻是由编译器决定的,比如:
r = 1 * a[i++] + 2 * a[i++] + 3 * a[i++];
不同的编译器可能有着不同的汇编代码,可能是先执行i++再进行乘法和加法运行,也可能是先进行加法和乘法运算,再执行i++,因为这句代码在一个表达式中出现了连续的自增并作用于同一变量。更加隐蔽的是自增自减在表达式中出现一次,但作用的变量多次出现,比如:
a[i] = i++; /* 未定义行为 */
先执行i++再赋值,还是先赋值再执行i++是由编译器决定的,而两种不同的执行顺序的结果差别是巨大的。
函数实参被求值的顺序
函数如果有多个实参,这些实参的求值顺序是由编译器决定的,比如:
printf("%d %d
", ++n, power(2, n)); /* 未定义行为 */
是先执行++n还是先执行power(2,n)是由编译器决定的。
有符号整数溢出
有符号整数溢出是未定义的行为,编译器决定有符号整数溢出按照哪种方式取值。比如下面代码:
int value1,value2,sum //其它操作 sum=value1+value; /*sum可能发生溢出*/
有符号数右移、移位的数量是负值或者大于操作数的位数
除数为零
malloc()、calloc()或realloc()分配零字节内存
3.2如何避免C语言未定义行为
代码中引入未定义行为会为代码埋下隐患,防止代码中出现未定义行为是困难的,我们总能不经意间就会在代码中引入未定义行为。但是还是有一些方法可以降低这种事件,总结如下:
了解C语言未定义行为
标准C99附录J.2“未定义行为”列举了C99中的显式未定义行为,通过查看该文档,了解那些行为是未定义的,并在编码中时刻保持警惕;
寻求工具帮助
编译器警告信息以及PC-Lint等静态检查工具能够发现很多未定义行为并警告,要时刻关注这些工具反馈的信息;
总结并使用一些编码标准
1)避免构造复杂的自增或者自减表达式,实际上,应该避免构造所有复杂表达式;
比如a[i] = i++;语句可以改为a[i] = i; i++;这两句代码。
2)只对无符号操作数使用位操作;
必要的运行时检查
检查是否溢出、除数是否为零,申请的内存数量是否为零等等,比如上面的有符号整数溢出例子,可以按照如下方式编写,以消除未定义特性:
int value1,value2,sum;
//其它代码
if((value1>0 && value2>0 && value1>(INT_MAX-value2))||
(value1<0 && value2<0 && value1<(INT_MIN-value2)))
{
//处理错误
}
else
{
sum=value1+value2;
}
上面的代码是通用的,不依赖于任何CPU架构,但是代码效率很低。如果是有符号数使用补码的CPU架构(目前常见CPU绝大多数都是使用补码),还可以用下面的代码来做溢出检查:
int value1, value2, sum;
unsigned int usum = (unsigned int)value1 + value2;
if((usum ^ value1) & (usum ^ value2) & INT_MIN)
{
/*处理溢出情况*/
}
else
{
sum = value1 + value2;
}
使用的原理解释一下,因为在加法运算中,操作数value1和value2只有符号相同时,才可能发生溢出,所以我们先将这两个数转换为无符号类型,两个数的和保存在变量usum中。如果发生溢出,则value1、value2和usum的最高位(符号位)一定不同,表达式(usum ^ value1) & (usum ^ value2) 的最高位一定为1,这个表达式位与(&)上INT_MIN是为了将最高位之外的其它位设置为0。
了解你所用的编译器对未定义行为的处理策略
很多引入了未定义行为的程序也能运行良好,这要归功于编译器处理未定义行为的策略。不是你的代码写的正确,而是恰好编译器处理策略跟你需要的逻辑相同。了解编译器的未定义行为处理策略,可以让你更清楚的认识到那些引入了未定义行为程序能够运行良好是多么幸运的事,不然多换几个编译器试试!
以Keil MDK为例,列举常用的处理策略如下:
1) 有符号量的右移是算术移位,即移位时要保证符号位不改变。
2)对于int类的值:超过31位的左移结果为零;无符号值或正的有符号值超过31位的右移结果为零。负的有符号值移位结果为-1。
3)整型数除以零返回零
4 了解你的编译器
在嵌入式开发过程中,我们需要经常和编译器打交道,只有深入了解编译器,才能用好它,编写更高效代码,更灵活的操作硬件,实现一些高级功能。下面以公司最常用的Keil MDK为例,来描述一下编译器的细节。
4.1编译器的一些小知识
默认情况下,char类型的数据项是无符号的,所以它的取值范围是0~255;
在所有的内部和外部标识符中,大写和小写字符不同;
通常局部变量保存在寄存器中,但当局部变量太多放到栈里的时候,它们总是字对齐的。
压缩类型的自然对齐方式为1。使用关键字__packed来压缩特定结构,将所有有效类型的对齐边界设置为1;
整数以二进制补码形式表示;浮点量按IEEE格式存储;
整数除法的余数的符号于被除数相同,由ISO C90标准得出;
如果整型值被截断为短的有符号整型,则通过放弃适当数目的最高有效位来得到结果。如果原始数是太大的正或负数,对于新的类型,无法保证结果的符号将于原始数相同。
整型数超界不引发异常;像unsigned char test; test=1000;这类是不会报错的;
在严格C中,枚举值必须被表示为整型。例如,必须在‑2147483648 到+2147483647的范围内。但MDK自动使用对象包含enum范围的最小整型来实现(比如char类型),除非使用编译器命令‑‑enum_is_int 来强制将enum的基础类型设为至少和整型一样宽。超出范围的枚举值默认仅产生警告:#66:enumeration value is out of "int" range;
对于结构体填充,根据定义结构的方式,keil MDK编译器用以下方式的一种来填充结构:
I> 定义为static或者extern的结构用零填充;
II> 栈或堆上的结构,例如,用malloc()或者auto定义的结构,使用先前存储在那些存储器位置的任何内容进行填充。不能使用memcmp()来比较以这种方式定义的填充结构!
编译器不对声明为volatile类型的数据进行优化;
__nop():延时一个指令周期,编译器绝不会优化它。如果硬件支持NOP指令,则该句被替换为NOP指令,如果硬件不支持NOP指令,编译器将它替换为一个等效于NOP的指令,具体指令由编译器自己决定;
__align(n):指示编译器在n 字节边界上对齐变量。对于局部变量,n的值为1、2、4、8;
attribute((at(address))):可以使用此变量属性指定变量的绝对地址;
__inline:提示编译器在合理的情况下内联编译C或C++ 函数;
4.2初始化的全局变量和静态变量的初始值被放到了哪里?
我们程序中的一些全局变量和静态变量在定义时进行了初始化,经过编译器编译后,这些初始值被存放在了代码的哪里?我们举个例子说明:
unsigned int g_unRunFlag=0xA5;
static unsigned int s_unCountFlag=0x5A;
我曾做过一个项目,项目中的一个设备需要在线编程,也就是通过协议,将上位机发给设备的数据通过在应用编程(IAP)技术写入到设备的内部Flash中。我将内部Flash做了划分,一小部分运行程序,大部分用来存储上位机发来的数据。随着程序量的增加,在一次更新程序后发现,在线编程之后,设备运行正常,但是重启设备后,运行出现了故障!经过一系列排查,发现故障的原因是一个全局变量的初值被改变了。
这是件很不可思议的事情,你在定义这个变量的时候指定了初始值,当你在第一次使用这个变量时却发现这个初值已经被改掉了!这中间没有对这个变量做任何赋值操作,其它变量也没有任何溢出,并且多次在线调试表明,进入main函数的时候,该变量的初值已经被改为一个恒定值。
要想知道为什么全局变量的初值被改变,就要了解这些初值编译后被放到了二进制文件的哪里。在此之前,需要先了解一点链接原理。
ARM映象文件各组成部分在存储系统中的地址有两种:一种是映象文件位于存储器时(通俗的说就是存储在Flash中的二进制代码)的地址,称为加载地址;一种是映象文件运行时(通俗的说就是给板子上电,开始运行Flash中的程序了)的地址,称为运行时地址。
赋初值的全局变量和静态变量在程序还没运行的时候,初值是被放在Flash中的,这个时候他们的地址称为加载地址,当程序运行后,这些初值会从Flash中拷贝到RAM中,这时候就是运行时地址了。
原来,对于在程序中赋初值的全局变量和静态变量,程序编译后,MDK将这些初值放到Flash中,位于紧靠在可执行代码的后面。在程序进入main函数前,会运行一段库代码,将这部分数据拷贝至相应RAM位置。
由于我的设备程序量不断增加,超过了为设备程序预留的Flash空间,在线编程时,将一部分存储全局变量和静态变量初值的Flash给重新编程了。在重启设备前,初值已经被拷贝到RAM中,所以这个时候程序运行是正常的,但重新上电后,这部分初值实际上是在线编程的数据,自然与初值不同了。
4.3在C代码中使用的变量,编译器将他们分配到RAM的哪里?
我们会在代码中使用各种变量,比如全局变量、静态变量、局部变量,并且这些变量时由编译器统一管理的,有时候我们需要知道变量用掉了多少RAM,以及这些变量在RAM中的具体位置。
这是一个经常会遇到的事情,举一个例子,程序中的一个变量在运行时总是不正常的被改变,那么有理由怀疑它临近的变量或数组溢出了,溢出的数据更改了这个变量值。要排查掉这个可能性,就必须知道该变量被分配到RAM的哪里、这个位置附近是什么变量,以便针对性的做跟踪。
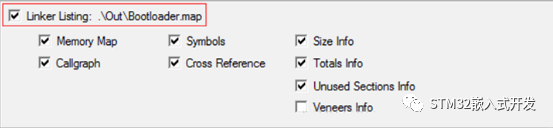
其实MDK编译器的输出文件中有一个“工程名.map”文件,里面记录了代码、变量、堆栈的存储位置,通过这个文件,可以查看使用的变量被分配到RAM的哪个位置。要生成这个文件,需要在Options for Targer窗口,Listing标签栏下,勾选Linker Listing前的复选框,如下图所示。
4.4默认情况下,栈被分配到RAM的哪个地方?
MDK中,我们只需要在配置文件中定义堆栈大小,编译器会自动在RAM的空闲区域选择一块合适的地方来分配给我们定义的堆栈,这个地方位于RAM的那个地方呢?
通过查看MAP文件,原来MDK将堆栈放到程序使用到的RAM空间的后面,比如你的RAM空间从0x4000 0000开始,你的程序用掉了0x200字节RAM,那么堆栈空间就从0x4000 0200处开始。
使用了多少堆栈,是否溢出?
4.5 有多少RAM会被初始化?
在进入main()函数之前,MDK会把未初始化的RAM给清零的,我们的RAM可能很大,只使用了其中一小部分,MDK会不会把所有RAM都初始化呢?
答案是否定的,MDK只是把你的程序用到的RAM以及堆栈RAM给初始化,其它RAM的内容是不管的。如果你要使用绝对地址访问MDK未初始化的RAM,那就要小心翼翼的了,因为这些RAM上电时的内容很可能是随机的,每次上电都不同。
4.6 MDK编译器如何设置非零初始化变量?
对于控制类产品,当系统复位后(非上电复位),可能要求保持住复位前RAM中的数据,用来快速恢复现场,或者不至于因瞬间复位而重启现场设备。而keil mdk在默认情况下,任何形式的复位都会将RAM区的非初始化变量数据清零。
MDK编译程序生成的可执行文件中,每个输出段都最多有三个属性:RO属性、RW属性和ZI属性。对于一个全局变量或静态变量,用const修饰符修饰的变量最可能放在RO属性区,初始化的变量会放在RW属性区,那么剩下的变量就要放到ZI属性区了。
默认情况下,ZI属性区的数据在每次复位后,程序执行main函数内的代码之前,由编译器“自作主张”的初始化为零。所以我们要在C代码中设置一些变量在复位后不被零初始化,那一定不能任由编译器“胡作非为”,我们要用一些规则,约束一下编译器。
分散加载文件对于连接器来说至关重要,在分散加载文件中,使用UNINIT来修饰一个执行节,可以避免编译器对该区节的ZI数据进行零初始化。这是要解决非零初始化变量的关键。
因此我们可以定义一个UNINIT修饰的数据节,然后将希望非零初始化的变量放入这个区域中。于是,就有了第一种方法:
修改分散加载文件,增加一个名为MYRAM的执行节,该执行节起始地址为0x1000A000,长度为0x2000字节(8KB),由UNINIT修饰:
LR_IROM1 0x00000000 0x00080000 { ; load region size_region
ER_IROM1 0x00000000 0x00080000 { ; load address = execution address
*.o (RESET, +First)
*(InRoot$$Sections)
.ANY (+RO)
}
RW_IRAM1 0x10000000 0x0000A000 { ; RW data
.ANY (+RW +ZI)
}
MYRAM 0x1000A000 UNINIT 0x00002000 {
.ANY (NO_INIT)
}
}
那么,如果在程序中有一个数组,你不想让它复位后零初始化,就可以这样来定义变量:
unsigned char plc_eu_backup[32] __attribute__((at(0x1000A000)));
变量属性修饰符__attribute__((at(adde)))用来将变量强制定位到adde所在地址处。由于地址0x1000A000开始的8KB区域ZI变量不会被零初始化,所以位于这一区域的数组plc_eu_backup也就不会被零初始化了。
这种方法的缺点是显而易见的:要程序员手动分配变量的地址。如果非零初始化数据比较多,这将是件难以想象的大工程(以后的维护、增加、修改代码等等)。所以要找到一种办法,让编译器去自动分配这一区域的变量。
分散加载文件同方法1,如果还是定义一个数组,可以用下面方法:
unsigned char plc_eu_backup[32] __attribute__((section("NO_INIT"),zero_init));
变量属性修饰符__attribute__((section(“name”),zero_init))用于将变量强制定义到name属性数据节中,zero_init表示将未初始化的变量放到ZI数据节中。因为“NO_INIT”这显性命名的自定义节,具有UNINIT属性。
将一个模块内的非初始化变量都非零初始化
假如该模块名字为test.c,修改分散加载文件如下所示:
LR_IROM1 0x00000000 0x00080000 { ; load region size_region
ER_IROM1 0x00000000 0x00080000 { ; load address = execution address
*.o (RESET, +First)
*(InRoot$$Sections)
}
RW_IRAM1 0x10000000 0x0000A000 { ; RW data
.ANY (+RW +ZI)
}
RW_IRAM2 0x1000A000 UNINIT 0x00002000 {
test.o (+ZI)
}
}
在该模块定义时变量时使用如下方法:
这里,变量属性修饰符__attribute__((zero_init))用于将未初始化的变量放到ZI数据节中变量,其实MDK默认情况下,未初始化的变量就是放在ZI数据区的。
编辑:黄飞
-
C语言:嵌入式开发中的关键编译器角色2024-04-26 1774
-
嵌入式开发中的交叉编译详解2023-12-01 2723
-
c语言嵌入式开发2023-11-17 835
-
嵌入式开发中的C语言—编译器介绍2023-02-25 2551
-
嵌入式开发中为什么选择C语言?它有哪些特点?2023-01-04 2550
-
嵌入式开发为什么选择C语言?2021-12-15 2260
-
嵌入式开发为什么选择C语言作为开发语言?2021-11-03 1230
-
什么是嵌入式开发?为什么用C语言作为开发语言?2021-11-02 1649
-
嵌入式linux c语言,嵌入式LinuxC语言开发工具.pdf2021-11-01 1405
-
嵌入式系统为什么选择C语言作为开发语言2019-07-10 2610
-
嵌入式开发通常采用哪种编程语言2019-06-18 17238
-
嵌入式开发语言有哪些_最全面嵌入式开发语言概述2018-01-29 10582
-
嵌入式交叉编译环境的搭建解析2017-10-18 1255
-
嵌入式软件开发语言 嵌入式C编程2016-12-28 2004
全部0条评论

快来发表一下你的评论吧 !
