

Innodb中的Btree实现(一)·引言&insert篇
描述
1 背景
Btree 自 1970 年 Bayer 教授提出后,一直是关系型数据库中核心数据结构,基于多路的分叉树,将数据范围自上而下不断缩小,直到需要的记录,通常在数据库中一个 Btree 结点能展开几百上千个分叉,数据的搜索范围呈指数级下降,极大地减少了数据访存次数,提升搜索效率。对于 B-tree 的基础操作,如插入、删除、更新,以及分裂/合并等操作已有大量的文献介绍,如果需要了解或有所疑问,可以参考文章末尾的参考文献 [3]。在伴随着高并发和需要考虑事务处理的数据库系统下,Btree 索引往往需要考虑更为复杂的场景。本文深入 MySQL Innodb 引擎,介绍 Innodb 中 Btree 的组织形式以及操作数据的具体实现,着重考虑其在高并发访问时,如何保证数据、Btree 结构的一致性,以及如何考虑事务的 ACID 特性。
2 索引组织表 (IOT)
Innodb 是一种行存的存储引擎,一条记录(record)对应于数据表中的一行,包含多个列(field),除了用户自定义的 field 之外,Innodb 还会给每个 record 增加几个隐藏 field:最新修改的事务 ID、用于回滚和 MVCC 构建旧版本的回滚指针、以及未定义主键时的 row ID。这里我们将能唯一识别一条记录的前若干个 field 组合称为 key fields,其余的 field 组合为 value fields。
数据库的核心是高效组织和访问数据,便于用户快速检索和修改数据,MySQL 目前的主流 Innodb 引擎,采用的是索引组织表的形式,顾名思义,将表的数据组织为 B-tree 的形式,如图 1 所示,整个 btree 结构由多个结点组成,每个结点对应于真实物理文件的划分的固定大小的 page,Innodb 中默认是 16 KB。表中所有数据记录(data record,包含 key 和 value)有序存放在 b-tree 的叶子结点中,形成一个递增的 record 列表,非叶子结点存有 child 结点 key 的最小值以及 child 节点的 page 号 (index record,包含 key 和 page no),通过 page 号能从数据库缓存系统(buffer pool)中快速定位到 child 节点,这个包含所有数据的 Btree 也被称为主键索引(或者聚集索引),数据库每创建一张表,默认就是生成了一颗主键索引 btree。
对于二级索引,会生成一颗新的 btree,使用主键索引 value 中的某些 field 作为新的 btree 的 key,主键索引的 key 作为新的 btree 的 value,先从二级索引定位到主键索引的 key,再回主键索引拿到完整的记录,避免当以主键索引的 value 作为搜索条件时进行全表扫描的开销,提高搜索效率。
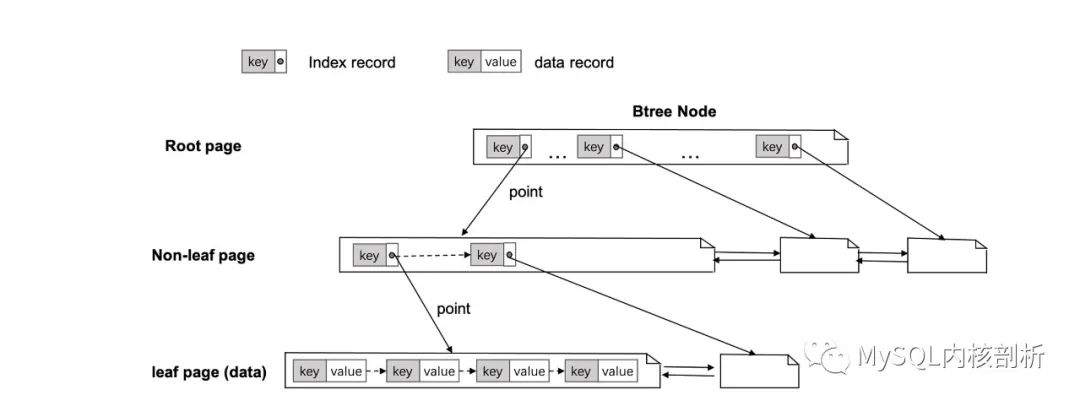
图 1: Innodb 的索引组织表形式
3 索引页和行结构
在 Innodb 中,对于任何数据的查询和修改,最终都是落在磁盘物理文件的访问操作中。简单来说,是通过 btree 定位到具体的物理 page,对 page 内部的 record 进行增删改查。Btree Page 内部本身可以看作一个有序的 record 单向链表,通过一些元信息对 16 KB 的物理空间进行高效管理和组织。每个 Page 中存在两个特殊的 record:infimum record 和 supremum record,分别代表 page 中 record 的无穷小和无穷大,位于 record 链表的头和尾。如图 2 所示,在 record 链表上,每间隔几个 record 会选取一个 record 作为 directory slot,这样查找时先二分搜索定位到具体的 slot,在 slot 进一步线性搜索定位到具体的 record。默认初始时,存在两个 directory slot,分别指向 infimum 和 supremum,随着 page 中 record 不断插入和删除,directory slot 的数目也会动态变化。

图 2: direction slot
Innodb Btree 中无论是叶子结点,还是非叶子结点,都有着相同 page 和 record 格式,图 3 给出了 Innodb 中索引 page 和 record 的物理格式(page_t 和 rec_t),对于 page 可以分为四个部分:page 本身的元信息、用于 btree 和 record 组织的索引元信息、record 空间和 directory slot 空间。
Page Header 和 Page Tail:包含 page 的元信息,如最新修改全局的日志序号(LSN)信息、维护同一层 Btree 的 page 的相邻 page 号,以及 page 的校验 checksum 信息等。
Index Header:这块是索引 page 的元信息,包含 page 内 directory slot 的数目,目前还未分配给 record 使用的空间偏移(Heap top),目前已经分配的 rec 数目(包含有效或者被回收的 rec),用于复用的 Free record List (最后被删除的 record 的偏移),page 内部有效的 record 数目(n_recs),以及当前 page 在 Btree 中的层级 (level,Btree 的叶子结点是第 0 层)。
record 空间:从 94 byte 往后就是 innodb page 存放 record 的区域,依此存放 infimum、supremum,用户 record 集合,以及还未分配的空间。
directory 空间:存放 directory slot 数组以及其指向的 record,所有 directory slot 是逆序存放的。
record 空间中存的就是上层用户写入的一行行记录 (rec_t),Innodb 中有两种行格式,Compact 和 Redundant 格式,MySQL 5.1 之后默认提供 Compact 格式了,本文也主要介绍 Compact 格式的 record。Record 主要分为两部分:Header 部分和 data 数据部分。
Header 元信息,在代码中以 Extra data 形容:首先是变长列的长度数组,这是按列的顺序存储的。第二部分存了行中为 NULL 的记录的 bitmap,这个 bitmap 的大小由索引元信息中最多允许多少个 NULL 的记录决定。后面多个字段决定当前 record 的状态,delete mark 标记当前 record 是否被删除(Innodb 中用户删除 record 都是标记删除,真正物理删除是由后台 purge 线程触发,保证没有其他用户并发访问时执行)。Min rec flag 标记当前 record 是否是非叶子层的最小值,使得搜索小于 btree 所有行时,能够定位在最小的叶子结点上。
N_owned 是用于作为 directory slot 指向的 record 使用,说明了当前 directory slot 包含的 record 数目,用于判断是否需要分裂或者收缩 directory slot。Page 中整个 record 空间是一个堆,每分配一个新的 Record,都会分配一个 heap no,这个 heap no 在事务系统中也用于唯一确定 page 内部 一个行锁对象。Status 标识了当前 record 状态:data record(ORDINARY)/ index record(NODE_PTR)/ INFIMUM / SUPREMUM。Next 指向 record 链中下一 record 在 page 内部的偏移。
data 数据部分:这是用户数据真正存储的位置,首先是 key fields,用于 record 的比较,唯一确定一个 record 在 Btree 的位置。Trx ID 和 Roll ptr 分别是最新修改的事务 ID 以及用于回滚和 MVCC 构建版本的回滚指针。后面的 Value fields 则是非 key 的列数据。
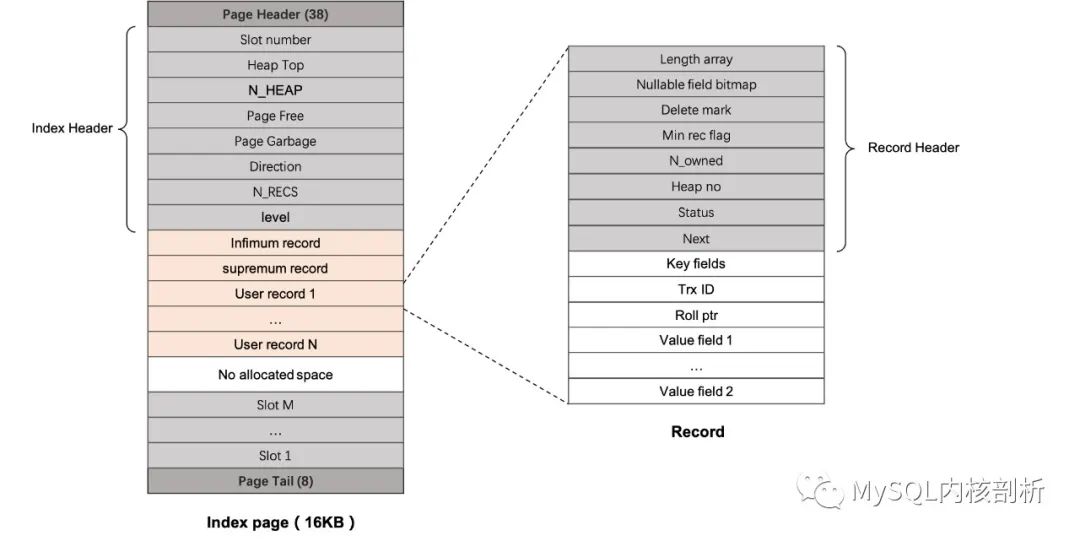
图 3: Innodb 的索引页和行结构
4 cursor 搜索
用户通过 SQL 下发操作的指令和要操纵的数据,通过 MySQL server 层的解析,在传入 innodb 引擎层时,会将需要操作的记录转换成 InnoDB 内存的记录格式(dtuple),以及表中具体行的增、删、改、查操作。dtuple 格式的内容比较直接,和 rec_t 中的数据部分是一致的,在操作时临时分配创建的。要操作一个表的数据,首先要通过 dtuple 中的 key fields 和逻辑上 btree 定位到数据存储的物理位置 (rec_t),这在 innodb 通过 cursor 搜索来实现的,每次 open 一个 cursor 都会开启一个从 btree root 结点搜索到指定层级的 record 的搜索过程。
在搜索时指定搜索模式(search_mode),并发控制的加锁模式 (latch_mode) 以及 搜索过程的行为(flag)。Innodb 中 search mode 是考虑到在 page 内部进行二分查找时定位在哪个 record,考虑到不同 record 的查找需求,有以下 4 种。:
PAGE_CUR_G: > 查询,查询第一个大于 dtuple 的 rec_t
PAGE_CUR_GE: >=,> 查询,查询第一个大于等于 dtuple 的 rec_t
PAGE_CUR_L: < 查询,查询最后一个小于 dtuple 的 rec_t
PAGE_CUR_LE: <= 查询,查询最后一个小于等于 dtuple 的 rec_t
插入操作的 search_mode 默认是 PAGE_CUR_LE,即插在最后一个小于等于该 dtuple 的 rec_t 后。
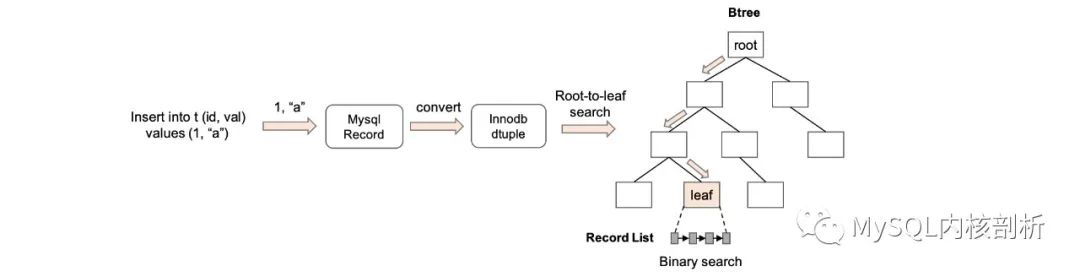
图 4: Cursor 定位流程
cursor 搜索整个核心操作在 btr_cur_search_to_nth_level 中。这个函数较为复杂,省去 AHI 和 spatial index 以及下一节介绍的并发控制逻辑,主要流程是:
从 dict_index_t 元信息中拿到 root page 在物理文件的 page no(默认是 4)。
从 buffer_pool 中根据 page no 拿 page(buf_page_get_gen),buffer pool 模块会根据 page 是否被缓存来决定是从内存中还是磁盘中读取,并根据加锁策略对 page 加锁。
对 page 内部的 record list 进行二分搜索 (page_cur_search_with_match),Innodb 的二分搜索是在图 2 中 directory slot 指向 record 进行的,先定位到相邻的两个 slot,在两个 slot 范围内进行线性搜索将 dtuple 与 rec_t 逐个进行比较,确定小于和大于等于 dtuple 的相邻 rec_t(low_rec 和 up_rec),并将 low_rec 和 up_rec 匹配的 fields 数记录下来(low_match 和 up_match),最后根据 search_mode 进行选取 rec_t。
如果没有到达指定 level,当前一定会是非叶子结点,会从 rec_t 提取 child page 所在的 page_no,重走步骤 2,直到到达指定 level.
在 cursor 搜索过程中,会根据上层指定的 flag,触发 cursor 搜索过程的行为,主要分为几种类型:
insert buf 相关,包括 BTR_INSERT、BTR_DELETE_MARK、BTR_DELETE 等,在二级索引回表时指定,如果主键索引叶子结点不在内存中,缓存相应操作,按一定频率合并写入主键索引的 page 中,避免频繁的随机 IO 开销。
lock intention 相关,包括 BTR_LATCH_FOR_INSERT、BTR_LATCH_FOR_DELETE,正常 innodb 在搜索到 leaf page 时,会把上层的锁都放了,而这两种类型在某些场景需要保留上层锁,如对于 insert,如果因当前 page 满了要插入到右 page 的第一个 record,会触发上层的 delete。对于 delete,如果删除 page 第一个 record,会触发上层 page 的 insert。
BTR_ESTIMATE:在 range scan 时会估计 range 范围内的 record,此时会保留 cursor 搜索路径的所有 page 信息,用于估计计算。
BTR_MODIFY_EXTERNAL:当处理 Blob 字段类型涉及到外部 page 时需要特殊处理[5],对整个 index 会加 sx 锁。
cursor 搜索的结果在 Innodb 是可以复用,持久化为 persist cursor(pcur),避免未修改时的重复搜索开销,这块内容我们将在 select 篇继续介绍。
5 并发控制
对于一个需要支持大量并发业务的实时事务处理 OLTP 系统而言,并发控制策略成了数据库 btree 实现的关键,在多线程并发搜索、查询、修改过程中,保持 Btree 结构的一致性。Innodb 中对于 btree page 的操作都被包含在一个 mini-transaction(mtr)中,用户线程操作 btree 前开启一个 mtr,在操作 btree 过程中,将访问的 page 指针、请求的锁 latch、以及产生的 redo log 分别挂在 mtr 上,当操作流程结束提交 mtr 时,将 redo log 同步到全局 log buffer 中,将脏页加入 flush list 上,最后释放所有持有的 latch。真正修改只有在 mtr commit 提交,redo 落盘才生效,因此 mtr 的实现将上层对记录的操作可以看作一个对 btree 的原子操作,也是 cursor 搜索并发控制的基本单位。

图 5: lifecycle of mini-transaction (mtr)
Innodb 对于 btree 修改的保证还是基于锁 latch 实现的,访问任何一个 page 内容都需要持有其 latch,读加 S 锁,写加 X 锁。除此之外,还有一种 SX 锁类型,与 S 锁兼容,与其他 SX 和 X 锁互斥,独占写权限但允许读。同时为了保证因 page 满或者稀疏而分裂或合并引起 btree 结构发生变化时的正确性,Innodb 还有一把整个 index 的全局 latch,在 dict_index_t 元信息中。
Btree 是树状组织的数据结构,在访问加 latch 需要满足一定顺序,才能防止死锁。然而保证加锁顺序的同时,还需要尽可能减少 latch 持有的范围,提高访问并发度。Innodb 经过多年的发展,在 btree latch 上的也做了大量的优化。文章 [4] 对于 innodb btree latch 的发展做了全面的概述,本文不再展开叙述,主要介绍在 MySQL 8.0 版本 btree latch 的机制。整体上遵守自顶向下,自左向右的访问策略,因此如果要访问一个 page 的 上层 page 或者 左边(prev)page,都需要从 root 结点开始重新遍历搜索。
对于读操作(BTR_SEARCH_LEAF),不会引起 btree 结构发生变化,对 index latch 加 S 锁,一路顺着 cursor 搜索路径,沿路对 page 加 S 锁,直到达 leaf page。
对于修改操作时,分为两种情况,认为当前修改不影响 btree 结构的乐观修改(BTR_MODIFY_LEAF)、以及认为当前修改会使得 btree 结构发生变化的悲观修改(BTR_MODIFY_TREE),两种搜索加锁策略的粒度是不同的,如图 6 所示。
乐观修改和读操作类似,会对 index latch 加 S 锁,一路顺着 cursor 搜索路径,沿路对 page 加 S 锁,到 leaf page 加 X 锁进行修改即可。
悲观修改加锁更为复杂,首先对 index latch 加 SX 锁,即此时仅允许一个悲观修改访问 btree,但允许并发的读操作和乐观修改。顺着 cursor 搜索路径,初始时不对沿路 page 加锁(此时其他访问不可能修改非叶子 page),当访问到 leaf page 的 parent 时,会对进行两层判断,如果修改会及联修改 parent 的父结点以上,这时到达 leaf page 时会将沿路的 page 重新加上 X 锁,如果 btree 的修改仅限于 parent,这时仅将 parent 的锁加上。当到达 leaf page 时,会将 leaf page 及其前后的 page 都加上 latch (需要修改前后 page 的指向)。
对于悲观修改,会递归修改上层 page(BTR_CONT_MODIFY_TREE),因为第一次悲观修改已经加好锁,再次搜索是无需对 page 加锁。
在 Innodb 中,某些场景需要获取某个 dtuple 的前一个 page (BTR_SEARCH_PREV 和 BTR_MODIFY_PREV),例如向前 range scan 需要跨 page 到前一个 record 时。由于加锁顺序问题,无法在持有当前 page 的 latch 拿去 previous page 的 latch,因此需要从 btree root 重新遍历,在持有 previous page 的 parent 的 latch 的情况下,释放当前 page 的 latch,获取 previous 的 page 的 latch。这里遍历加锁时候,还要特殊处理 previous page 和 当前 page 不在同一个 parent 的情况。
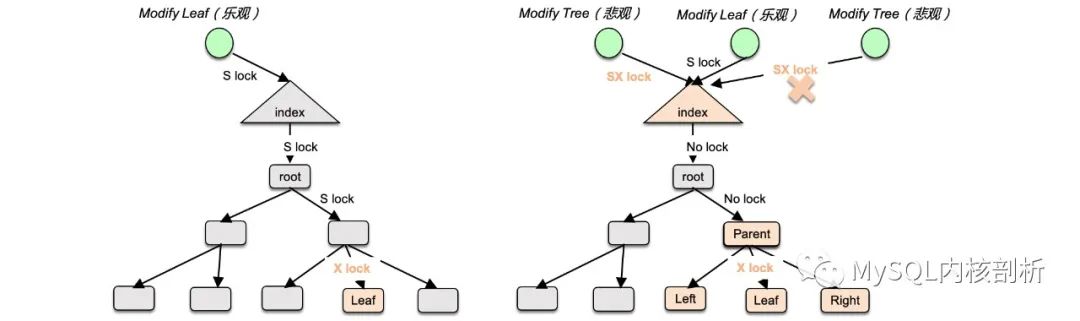
图 6: 乐观修改加锁路径(左)、悲观修改加锁路径(右)
6 Insert 路径解析
介绍完 Innodb 中 Btree 组织形式、搜索和并发控制策略,我们此时来看 Innodb 中 btree 是如何插入一条数据的。Innodb 在插入时需要对主键索引和二级索引分开考虑,先插入主键索引,再插入二级索引。
整个插入流程函数在 row_ins 中,插入前会先判断主键索引是否 unique(即是否定义主键),不是则会先分配 row id 来唯一标识一条 record。
无论主键索引还是二级索引,都需要先构建插入的完整行记录的内存版本(row,dtuple type),再基于 row 和各个索引(dict_index_t)的列信息构建真正需要插入索引中存储的版本(entry,dtuple type),进行 cursor 搜索定位到最后一个小于等于该 dtuple 的 rec_t 后,从 page 内部申请空间插入 entry 的内容。
6.1 主键索引的 insert 路径
主键索引的插入流程在 row_ins_clust_index_entry 函数中,先进行加锁范围更小的乐观插入流程,如果插入失败(page 空间不足),会进行悲观插入流程,加锁范围更大,并触发结点分裂流程,这也和 cursor 的乐观悲观搜索相对应。
控制乐观和悲观插入流程在 row_ins_clust_index_entry_low 中,根据 latch_mode 进行判断,每次都开启一个新的 mtr 流程,我们先看乐观插入:
先进行乐观 cursor 搜索 (BTR_MODIFY_LEAF),定位到 leaf page 的 rec_t 中。
duplicate check: 检查定位的 rec_t 是否和要插入的 entry 相等,存在重复,会将可能相等的 record 都加上事务锁(普通 insert 加 S lock,insert on duplicate key update 则加 X lock,gap mode 取决于事务隔离级别),保证不被其他事务修改。如果 rec_t 不是 delete mark,向上层返回 duplicate key 错误,如果是 delete mark,将插入流程转为 update-in-place 覆盖写入(row_ins_clust_index_entry_by_modify)。
否则进入乐观插入(btr_cur_optimistic_insert),首先会计算插入 entry 空间,先判断 page 中 free list 空间是否足够,free list 空间不够,再判断 page 中未分配的堆的空间,如果还是不够,会判断 reorganize page 后的空间(整理 page 内部的空间碎片),如果存在空闲空间,将 entry 内容 copy 到申请的 rec_t 中,并更新 rec_t 和 page 的元信息,否则会进行悲观插入。
真正插入 entry 前,会检查事务锁和记录 undo (btr_cur_ins_lock_and_undo),检查事务锁 (lock_rec_insert_check_and_lock) 会判断 cursor 定位的下一个 rec_t 上当前有没有锁,有的话加上带有 gap 的插入意向的 X 锁(LOCK_X | LOCK_GAP | LOCK_INSERT_INTENTION )的显示锁,来等待其他 gap 锁释放,确保要插入的区间没有其他事务访问。同时每一条 Insert 的 rec_t 上都默认有一个隐式锁,它是通过 trx_id 和当前活跃事务数组的 id 来检测的,这么做减少了 lock_sys 的操作,提升性能[6]。为了保证事务回滚,插入 entry 前会记录一条 insert 类型的 undo(trx_undo_report_row_operation),将 entry 的 key fields 写入 undo page 中,便于回滚时找到 record 的位置,并根据 undo page 的 id 和 offset 构建出回滚指针存入插入的 rec_t 中[7]。
在写入 entry 之后,会向 mtr 的 log buf 记录 redo log (page_cur_insert_rec_write_log),用于 WAL 故障恢复,通常一条 insert 的 redo log 会记录 page 和 index 信息,以及和 cursor 定位的 rec_t 相比的差异部分(btree的有序特性,相邻的 record 相同部分较多,减少存储的 redo log 大小):
(Page ID, offset) + (len of each field) + (extra info) + (bytes which differs from cursor record)
6.2 结点分裂
如果 cursor 搜索到的 leaf page 剩余空间不足以容纳待插入的 entry,会触发悲观插入流程,腾出插入的空间:
先进行悲观的 cursor 搜索流程,将涉及的 page 的 latch 都加上。
检查事务锁和记录 undo。
进行结点分裂,最后将 entry 插入到分裂后的 page 中,写 redo。
整个结点分裂过程在 btr_page_split_and_insert 中,如图 7 所示,主要是:
选择原 page 的分裂点 (split_rec)。
生成新 page,将原 page 的部分 record list 批量 move 到新 page 中,这里会写 move 相关的 redo(包括原 page 的 delete 和新 page 的 insert)。
修改前后 page 的指针指向、在 parent page 新增一个 index record 指向新 page(触发新的插入流程)。
根据 entry 和 split_rec 的大小关系,将 entry 插入到原 page 或者新 page 中的一个。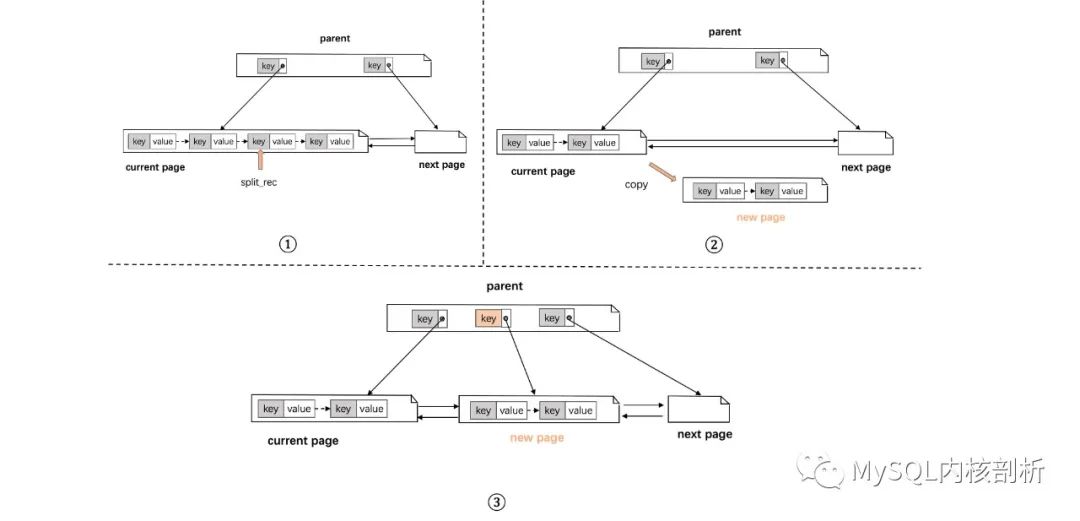
图 7: 结点分裂流程
原 page 的分裂点的选择,为了性能考虑,Innodb 采用了两种策略[8]:
将原始页面中 50% 数据移动到新页面,这是最普通的分裂方法。
为了优化上述中间点分裂在顺序插入场景的问题,InnoDB 实现了在插入点分裂的方法,在每个 page 上记录上次插入位置 (PAGE_LAST_INSERT),以此判断本次插入是否递增或者递减,如果判定为顺序插入,就在当前插入点进行分裂。
6.3 二级索引的 insert 路径
前面介绍二级索引由主键索引的部分 value fields 作为 sk(secondary key),主键索引的 pk (primary key) 作为 value。二级索引的插入流程整体和主键索引相差不大,可以参考主键索引流程,但存在以下几个区别:
duplicate check:二级索引 unique 性质是由 sk 决定的,而和主键索引不同,二级索引覆盖一个 delete mark 的 rec_t,需要满足所有 fields 都相等(sk + pk),因此对于一个 unique 的二级索引,可能存在多个被 delete-mark 的相同 sk 不同 pk 的 rec_t,并且跨多个 page。在搜索时,为了保证 unique 性质,需要把所有被 delete-mark 的 rec_t 以及第一个 sk 不相同的 rec_t 都加上 next-key 锁(gap 锁加在下一个 rec),阻止其他事务插入相同的 sk 的 record 造成 unique 不一致。
由于插入都是以 PAGE_CUR_LE 模式插入,所以插入时候搜索会定位到最后一个相等 sk 的 rec_t 上,然而由于相等 rec_t 可能跨 page,为了符合加锁顺序,在 duplicate check 的时候,会把上一个 mtr 提交,开启一个以 PAGE_CUR_GE 模式的 cursor 搜索过程来加 gap 锁。
由于 gap 锁加了第一个与 sk 不相同的 rec_t,当这中间的 gap 很大时,会造成即使在 RC 隔离级别下,也会很容易发生死锁问题,也是官方遗留很多年的问题,这在文章 [9] 有很好的例子、解释以及方案讨论,感兴趣的可以仔细阅读。
二级索引不需要通过记录 undo 来支持事务回滚和 MVCC 一致性读。
7 总结
本文介绍了以下几个方面:btree 的背景、Innodb 中 btree 的组织形式,包括索引组织表逻辑形式以及 btree 索引页和记录的物理格式。接下来介绍了从 Innodb 中定位 record 的方法和如何保证 btree 的一致性,包括了 cursor 搜索逻辑和并发控制流程。最后介绍了 Innodb 整个 insert 路径,以及如何考虑其他模块如 事务锁、undo、redo、BP 等。btree 索引是数据库的核心,是直接操纵数据的模块,通过 btree 来看 Innodb,对整个数据库都会有更深层次的理解。
审核编辑:刘清
-
北美运营商AT&amp;amp;T认证中的VoLTE测试项2024-12-06 1397
-
onsemi LV/MV MOSFET 产品介绍 &amp;amp; 行业应用2024-10-13 1776
-
FS201资料(pcb &amp; DEMO &amp; 原理图)2024-07-16 555
-
你使用shell脚本中的2&gt;&amp;1了吗?2023-07-30 3382
-
if(a==1 &amp;&amp; a==2 &amp;&amp; a==3),为true,你敢信?2023-05-08 2462
-
如何区分Java中的&amp;和&amp;&amp;2023-02-24 3728
-
详细总结下InnoDB存储引擎中行锁的加锁规则2023-02-21 1362
-
摄像机&amp;amp;雷达对车辆驾驶的辅助2022-11-26 2185
-
HarmonyOS &amp;amp;amp;润和HiSpark 实战开发,“码”上评选活动,邀您来赛!!!2022-04-11 2179
-
OpenMV&&stm32通信2021-12-24 790
-
存储类&作用域&生命周期&链接属性2021-12-09 920
-
单片机STC15双机通信&异步串行通信&Proteus2021-11-18 1106
-
Linux命令 &与&&的作用2019-07-04 1684
-
Altera_FPGA_CPLD设计_基础篇&高级篇2013-05-03 12716
全部0条评论

快来发表一下你的评论吧 !
