

新版编译器的设计思路和优化方法
编程语言及工具
描述
作者 | 马可
小程序编译器是百度开发者工具中的编译构建模块,用来将小程序代码转换成运行时代码。旧版编译器由于业务发展,存在编译慢、内存占用高的问题,我们对编译器做了一次大规模的重构,采用自研架构,做了多线程、代码缓存、sourcemap 等多项优化,在性能和内存占用上都有很大提升。全文介绍了新版编译器的设计思路和优化方法,以及一些能够用在通用打包工具里的技术点。
01
前言
小程序编译器在小程序开发、预览、发布各个阶段都需要使用,因此编译器性能会直接影响到开发者开发效率,也会影响到开发者工具的使用体验。 由于旧版的编译器(基于 webpack4)在构建大型项目时会很慢,内存占用也高,一直被开发者吐槽。我们经过大量的调研和开发,最后采用完全自研架构做新编译,针对小程序项目构建做了大量优化,基本解决了旧编译存在的问题。 下图是部分项目构建时间对比: 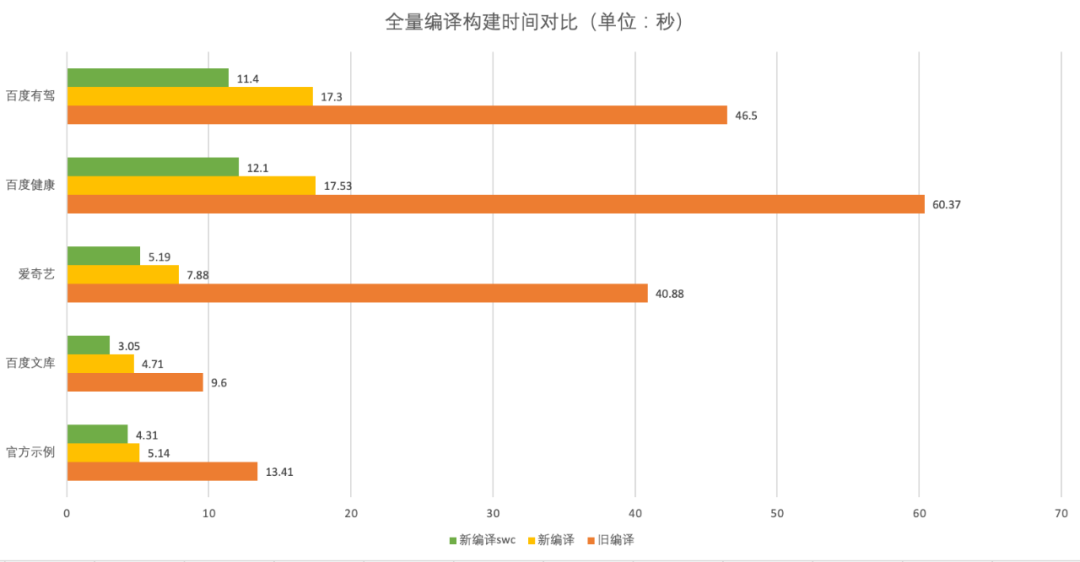
新版编译器相对于旧版实现了 2~7 倍的性能提升,并且支持实时编译、热重载等特性,内存占用更少,构建产物更优。
下面从 框架选型、新编译器工作原理、性能和产物优化方法 等方面介绍新版编译器的成长之路。
GEEK TALK
02
框架选型
在进行新版编译器设计时,需要明确当前的痛点问题:性能,优先解决性能问题。其他新技术和新想法对编译器有帮助的也一起实施。
旧版编译器基于 webpack4 存在如下几个问题:
大型项目构建速度太慢。
dev 启动慢、增量编译慢,仅支持 loader 缓存,bundle 无缓存也比较慢。
基于 webpack4 做扩展开发,需要 patch 部分模块才能工作,维护困难。
部分 webpack bundle 过程无法针对小程序代码结构进行优化,存在无效构建。
新编译的设计目标:
更快的全量编译速度,消除 webpack 存在的无效构建过程。
支持全缓存,加快首次和增量编译速度。
支持实时编译,减少 dev 启动和二次编译时间。
支持多线程编译加速,支持页面热重载。
优化产物结构,减少产物体积。
2.1 主流构建工具
下面介绍的是我们调研过的主流前端构建工具,每个工具都有适用场景和优缺点。
在新版本编译器架构设计时,其他构建工具的设计理念和技术特点都值得参考。
Webpack 构建过程:
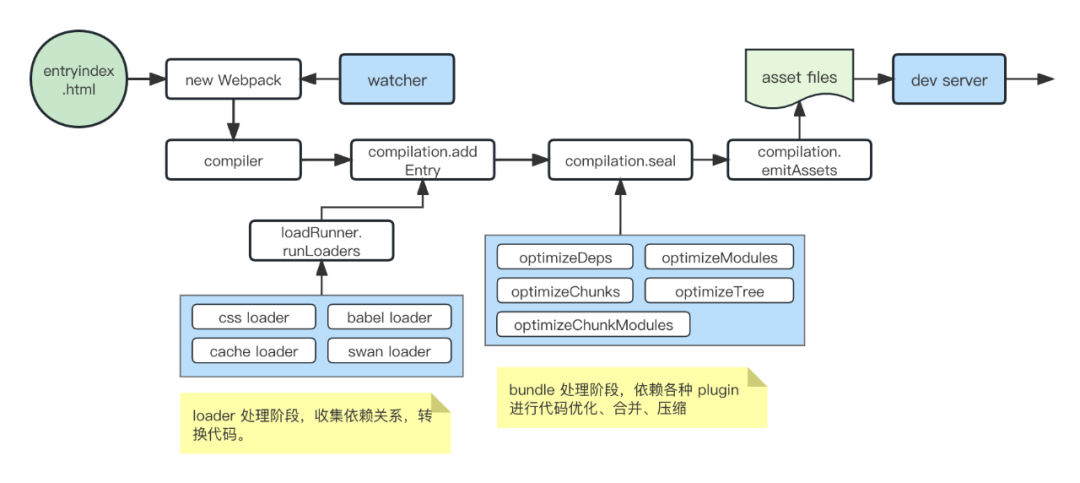
Webpack 优点:功能完善、社区活跃、可配置性强、有很强的扩展性。
Webpack 缺点:配置复杂、构建速度慢,二次开发困难。
Parcel 构建过程: 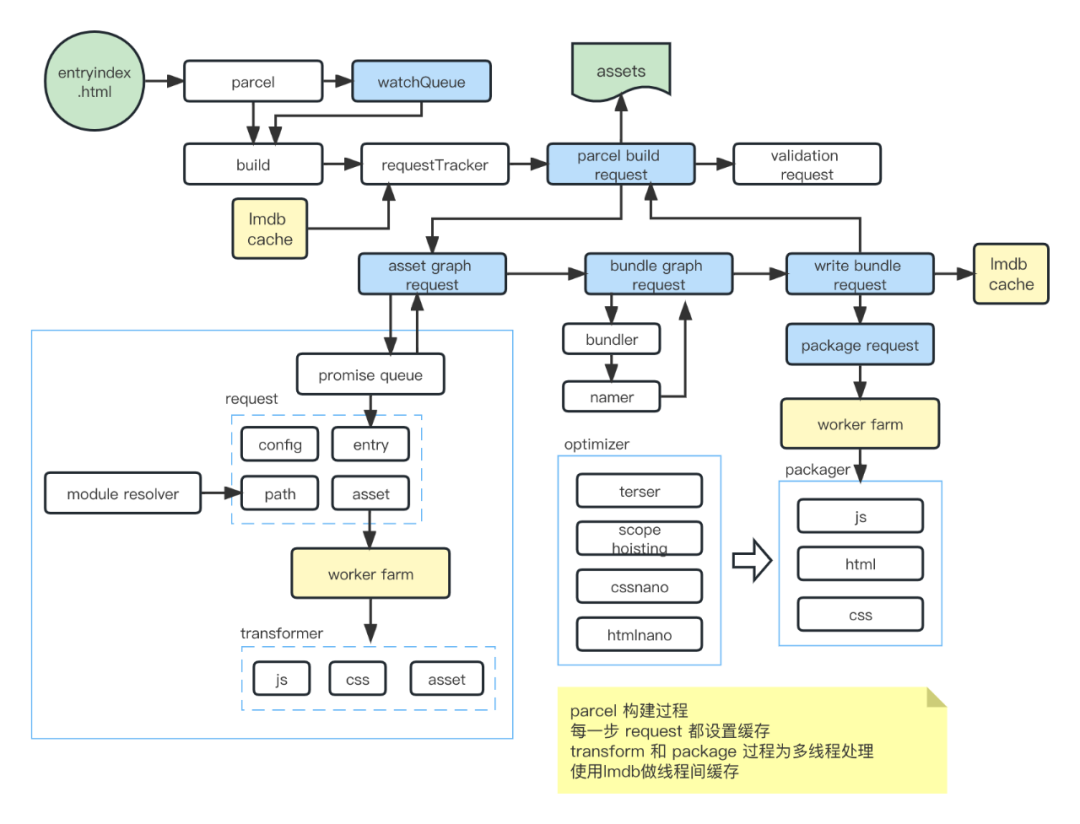
Parcel 优点:无需配置,构建速度快,原生支持多线程和全缓存,多线程之间共享数据通过 lmdb 进行,避免跨线程通信开销。
Parcel 缺点:生态小,自定义性有限,大量采用 Node 插件,兼容性也差一些。
Vite 构建过程:
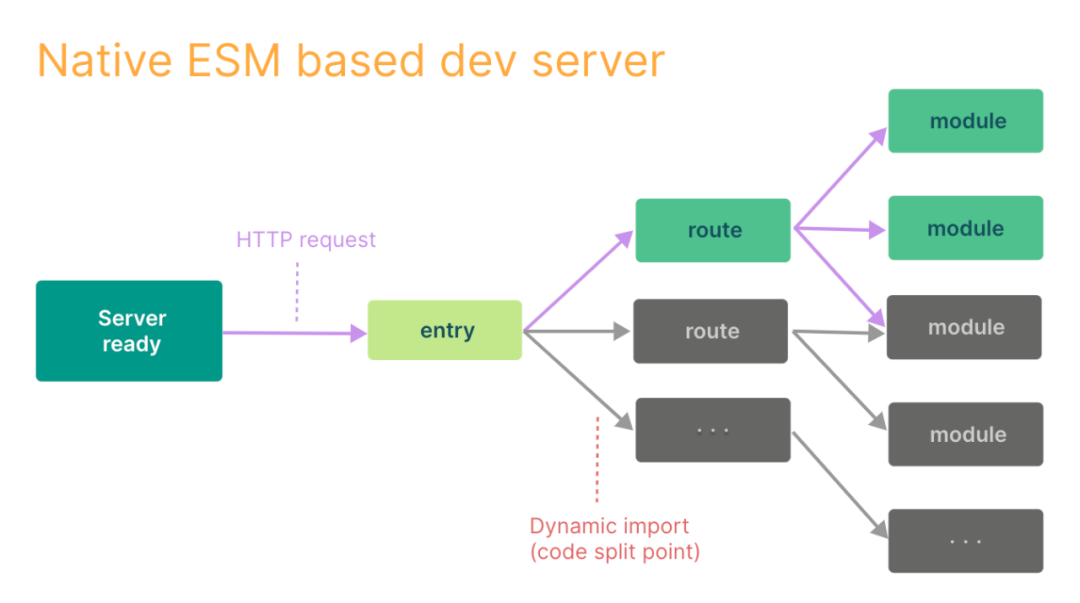
Vite 优点:配置较为简单,按需编译,启动快,dev 时有不错的体验。
Vite 缺点:生态小,dev 和 发布走两套构建流程。
其他小程序平台:
微信基于 gulp 和 C++ 模块做小程序构建,并且对 npm 模块做了预构建,在性能和开发体验上做的比较好。
支付宝基于 webpack 做小程序构建,并且使用了 esbuild 加速代码压缩。
抖音小程序使用自研编译器,构建流程比较简单。
2.2 新版编译器
在设计新编译框架时,借鉴了主流打包工具的工作流程,结合小程序代码特点,决定不做通用打包工具,重点优化小程序打包性能。
最终选择了自研编译器的方案,并做了大量优化工作,新版编译器优化点有如下几个方面:
1.支持多 Compiler 协同工作,将动态库开发等多类型项目构建解耦。
2.编译阶段全流程缓存,节省二次构建时间 90% 以上。
3.dev 开发默认采用按需编译,提升单页编译性能。
4.支持 babel 和 swc 多线程编译,提升全量编译速度 2 ~ 7 倍。
5.采用新版 sourcemap 协议,移除非必要解析合并,将 bundle 阶段耗时大幅缩减。
6.对 js、css、swan 模板编译均做了构建时标记优化,减少 bundle 合并耗时。
7.对于预览、发布阶段的 js 压缩和混淆,采用了 terser 和 esbuild 并行方案,esbuild 用于快速打出预览包,terser 可以保证压缩率用于发布包。
从结果看,新编译器从速度、资源占用和可维护性上相对于旧版都有显著的提升。
GEEK TALK
03
新版编译器工作原理
新编译器的处理流程和 parcel 比较类似,Compiler 控制处理流程,Processor 进行代码转换,基本流程如下:
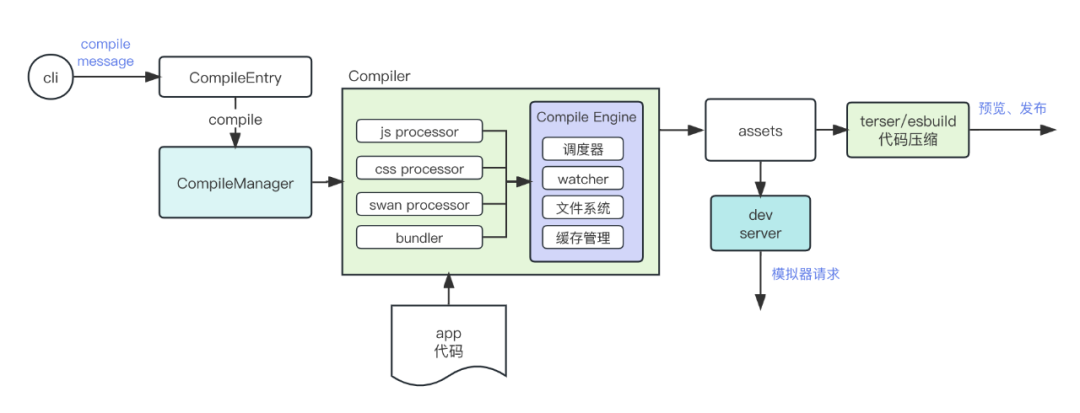
其中几个重要的模块:
CompileEntry 编译器为入口模块,包含 cli 通信、dev server 通信、命令调用等。
CompileManager 为编译管理器,用于依赖资源下载和管理以及多个 Compiler 协同构建。
Compiler 为编译器模块,用于将项目源码编译成运行时代码,项目构建时 Compiler 可能有多个。
Processor 为单元处理器,用于处理 代码转换、代码合并 等单个编译任务。
注:小程序 App 项目有 1 个Compiler,动态库和动态扩展项目 2 个Compiler。
3.1 Compiler 编译器
用于编译单个小程序项目,将开发者原始代码编译为可运行代码。
工作职能:
1.创建运行上下文,提供 config、fs 文件处理、watcher 监控、logger 等模块,给 Processor 使用。
2.全量编译、文件变更时二次编译;这里二次编译也是走一遍全量编译流程,不过大部分用的是缓存结果。
3.管理、调度、运行 Processor 处理单元。
4.维护 Processor 依赖关系和结果缓存。
特点:
1.实现全流程缓存,将每个 Processor 的输入参数、输出结果写入缓存,在有缓存情况下二次编译时长可减少 90% 。
2.支持按需编译,每次按需单页编译、增量编译、全量编译 都走同样的 Processor 处理流程。
3.通过 Proxy 机制自动计算缓存参数依赖,不用手动为每个 Processor 生成缓存 hash,相对于 webpack 或 parcel 减少 bug 产生。
4.仅维护 Processor 依赖关系,不维护 ModuleGraph,简化处理流程。
关于全流程缓存每家打包器都有自己的实现方案,基本原理是根据当前输入参数和依赖情况为处理单元生成一个唯一 hash,hash 一致则结果一致。
webpack 和 parcel 由于维护了 ModuleGraph,缓存的计算和重用会复杂一些。小程序编译器仅根据 Processor 入参和调用依赖进行计算。
3.2 Processor 单元处理器
Processor 有如下特性:
1.在输入参数一致的情况下,保证输出一致,输入和输出都必须可序列化为 json ,实现了 Processor 全缓存。
2.Processor 中的 uri 为构建 ID,在单次构建过程中 ID 一致则处理结果一致,例如处理 app.js 文件,uri 为:js:app.js,好处是可以统一 Processor 资源处理路径。
3.Processor 之间支持互相调用:processWith 调用并继续执行,processWithResult 调用并等待返回结果。
注意:这里的输入参数包含 uri、app config, contextFreeData。
几种常用的 Processor:
1.JS Processor 将 es6 代码转换成 es5 代码,这是最耗时的模块。
2.Swan Processor 将 swan 模板代码转换成 view 层 js 代码。
3.Css Processor 使用 postcss 处理 css 中的单位转换、依赖收集等工作。
4.Bundle Processor 将前面 transformer 处理结果按照 bundle 算法合并文件并输出结果。
Processor 工作流程:
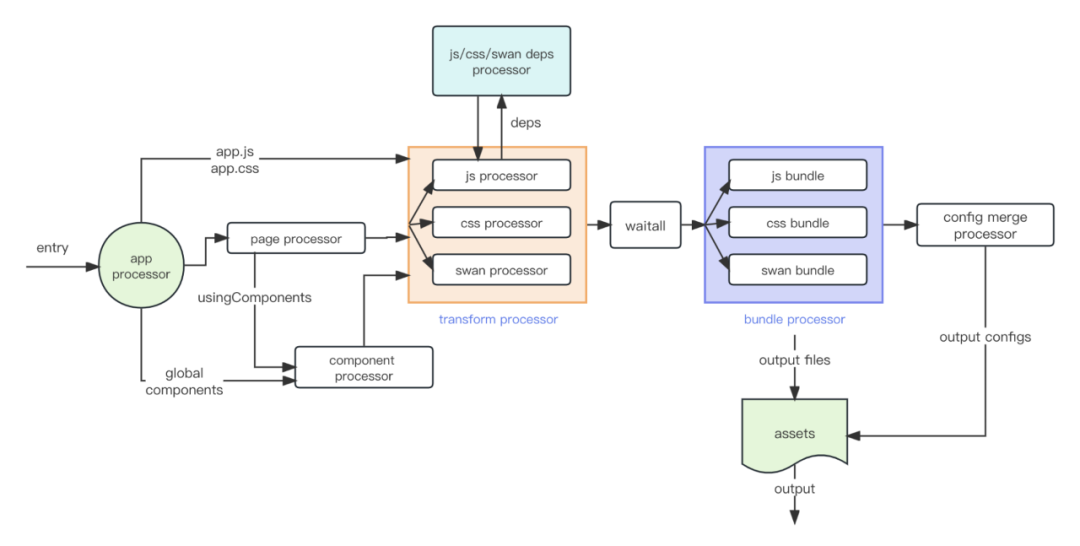
Processor 处理流程需要经过 transform -> bundle 的过程,在小程序里 js, css, swan 模板的 bundle 可以分开并行处理,这里和 webpack 的处理模式不一样,和 parcel 的 pipeline 类似。
3.3 性能和产物优化方法
3.3.1 多核心编译优化
由于 Node 中多线程模块初始化速度和通信效率比多进程好一些,新编译选择使用 多线程 做多核心优化。
多线程编译有 2 种方案选择:
方案1:基于 processor 做多线程调度,由于 processor 间支持相互调用,实际处理会很复杂且有通信成本。
旧的编译器做过基于webpack 的 workerthread-loader,性能提升有限(10%~15%)。
parcel 基于 lmdb 公共缓存消除线程间通信,保证读写效率,是一个比较好的解决方法。
方案2:仅对 js 转译做多线程调度,仅有一来一回 2 次通信成本。
使用 jest-worker 和 babel transform 做 js 多线程转译或者用 swc 多线程做 js 转译。
由于大部分构建时间在 js 转译这里(js 中有大量 node_modules 依赖,均需要转换),css 和 swan 模块转换耗时少。
最终选择方案2 仅做 js 多线程转译,处理流程简单且收益较好,整体提升如下:
使用 jest-worker 多线程 babel 转译,4 线程可提升 1 倍以上速度。
使用 swc 做 js 转译,4 线程提升 4 倍以上速度。
JS Processor 多线程处理:
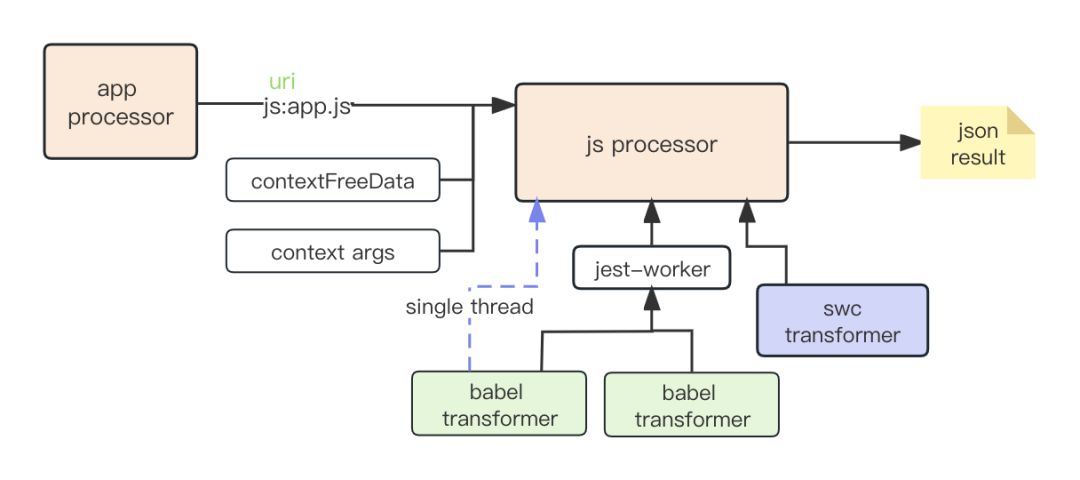
其中:
uri: 为处理器构建 ID
contextFreeData: 单次构建中不可变数据,例如 app.json 中的配置项
context args:全局参数,例如优化实验开关、多线程开关等
在 js 转换处理时规定了 transformer 统一转换接口,基于接口实现了 babel 单线程、babel 多线程、swc 转换 3 种处理器,并且可随时做处理器切换。
对于不同的编译环境可以做到灵活设置:
1.开发者工具中开发者根据机器配置情况可以切换 多线程、swc 编译模式,提升效率。
2.云编译流水线默认开多线程编译提高性能。
3.webIDE 默认开单线程降低资源消耗。
3.3.2 SWC 编译优化
新编译器多线程模式相对于旧编译提升了 1 倍左右,在 dev 开发时一些大型项目页面首次编译还是有些慢,需要10秒以上,主要耗时在 js transform 这里。
swc 目前在 js 转译上基本成熟了,且大部分场景能提升 4 倍以上转译速度,因此增加了 swc 多线程转译支持,将大型项目页面首次编译控制在了 5 秒以内。
需要编写 2 个 swc 插件来适配 swc 转译:
@swanide/swc-require-rename 将 require/import/export 中的模块提取路径信息,以便于后续在 js 中分析模块依赖关系。
@swanide/swc-web-debug 对 js 代码进行插桩处理,用来支持真机调试中的断点调试。
swc 编译带来的性能提升是巨大的,在使用中也发现了一些问题:
1.swc 存在内存泄露,在 dev 阶段如果全量编译次数过多,会导致内存占用很高,需手动重启编译器。
2.swc 插件支持的 api 较少,一部分 babel 容易实现的功能,在 swc 中很难处理。
3.swc 由于使用 rust 编写插件,插件在不同 @swc/core 版本间不能通用,需要为不同平台生成 swc 插件,在部署上会麻烦一些。
在实际使用中,对于一部分 swc 不能很好处理的场景,会降级到 babel 处理。
3.3.3 代码压缩和运行时缓存
在 dev 阶段,编译后的代码是没有经过压缩的,可以在模拟器中运行。在预览发布阶段由于限制了包体积,需要做代码压缩以减少产物体积。
可选的代码压缩工具有如下 3 个:
1.terser 压缩率高,产物体积小,速度最慢。
2.swc 压缩快,mangle 支持不完善,压缩率较差。
3.esbuild 压缩最快(比 terser 快了 10 倍以上),支持 mangle,代码压缩率不如 terser。
最后经过对比考虑,选择了如下压缩方案:
1.预览阶段由于不需要 sourcemap,移除 sourcemap,并使用 esbuild 做代码压缩,提高预览速度(对于自动预览场景有很大提升)。
2.发布阶段使用 terser 做多线程压缩,并保留 sourcemap。
运行时缓存 指的是构建过程的中间结果都在内存中做了缓存,包括 Processor 处理结果 和 代码压缩结果,在二次构建时可以节省大部分重新构建时间。由于缓存中保留的是字符串和 json 对象,相对于基于 webpack 的旧版编译器有 40% ~ 60% 的内存节省,在内存占用上处于可接受范围。
3.3.4 Swan 模板处理优化
旧的 swan 模板处理使用 swan-loader 进行模板转换,由于设计时没有处理好模板 import 作用域,导致 标签以及 filter 过滤器函数只能内联到页面代码中,如果模板中大量使用了 template 和 filter,最终生成的代码体积会非常大。
新编编译器纠正了 import 作用域关系,将编译产物中的 template 、 filter 生成模式由内联改为 require 引用,然后在 bundle 阶段做代码合并,使相同模块能够得到重用,算是填了一个大坑。
新编译器 swan 模板处理流程:
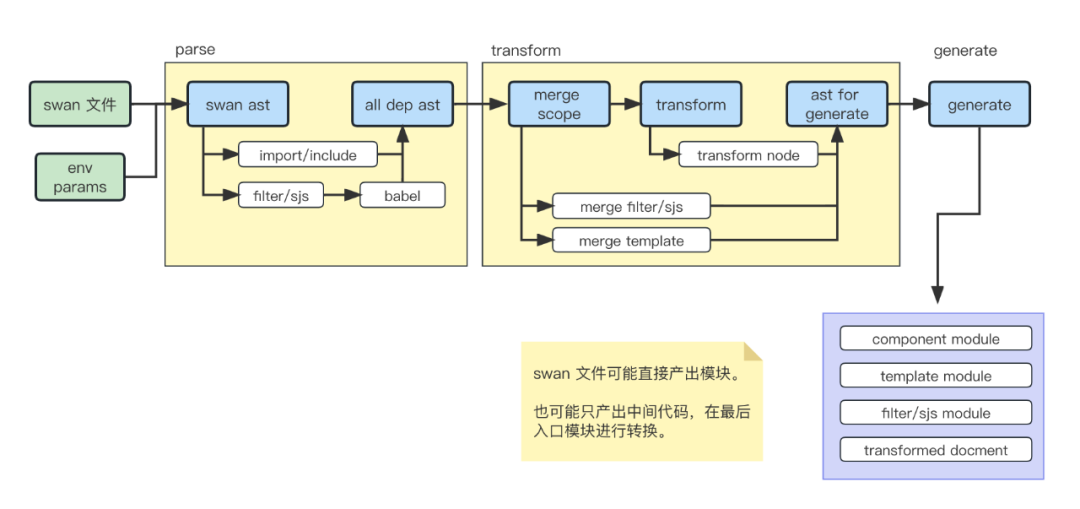
单个 swan 文件经过 Processor 处理后可能的产物有:
component 组件模块,用于生成页面和自定义组件
template 模块
filter 过滤器函数、sjs 过滤器函数
transformed document 中间代码
将 swan 模板转换成不同类型的 js module,并维护依赖关系,便于后续的代码合并时更精细化的控制。
由于历史原因 import/include 中包含 sjs 或者 template 引用时不能直接生成 template 模块,需要在最后入口模板中生成。新编译也提供了 template静态编译选项,将严格限制 import 作用域,可直接生成 template 模块代码,对于 taro 生成的小程序项目可以节约 30% 左右的产物大小。
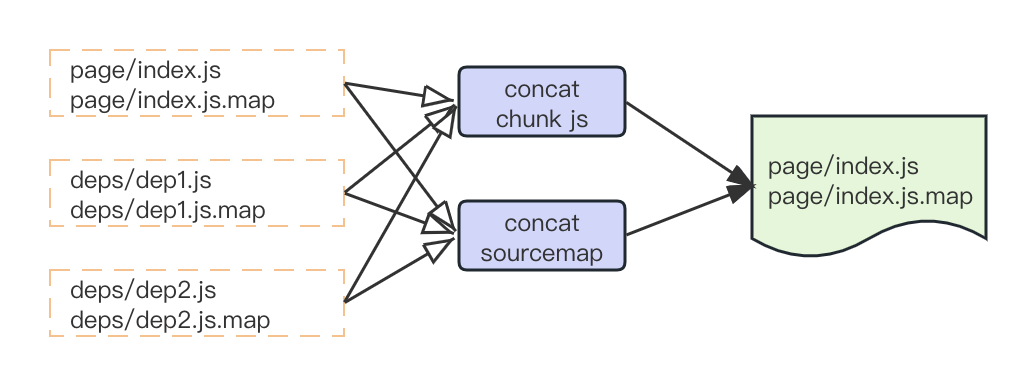
3.3.5 Sourcemap 优化
由于编译器需要支持 js 代码调试以及运行时 error 跟踪,在 dev 和发布阶段都需要生成 sourcemap。
在 webpack 中生成代码时需要对 sourcemap 进行合并计算,较大的项目 sourcemap 合并会占用很长时间,并且每次重新编译都要重新计算 sourcemap。
调研时发现浏览器 devtools 对 sourcemap 协议 的 index map 支持非常好, 新编译器基于 index map 协议做了 sourcemap 合并优化,由之前的多文件 sourcemap 合并计算,变成了计算生成 offset map 并拼接内容,这样 js bundle 耗时就由原来的 几秒到几十秒变为了固定 3 秒以内。
一个有意思的事情是 vscode 的 js-debugger 直到 22 年 6 月份才支持 index map 调试(index map 2011 年发布的),微软的动作稍微慢了一些。
3.3.6 后续工作
在新编译器开发完成之后的推广中,采用了渐进式推广方式:
第一阶段,开发者工具新旧编译器共存,dev、预览使用新编译器,发布使用旧编译器。
第二阶段,内部 pipeline 预览和发布全量使用新编译。
第三阶段,开发者工具全部切换到新编译器。
新版编译实际上线后还存在一些小的兼容性问题,需要尽量提前暴露问题才能做发布全量替换。
针对小程序项目,新编译做了大量的优化工作,部分优化工作还没有完成开发,包括:
hmr 热重载:开发中,由于 运行时框架、开发者工具均需要做接口适配,需要较长时间调试才能达到预期。
tree-shaking 代码消除:对于 es6 模块在 transform 阶段可以做 tree-shaking 消减代码。
scope-hoisting 作用域提升:理论可行,需要验证代码缩减效果。
新版编译器由于需要完全兼容旧版编译器构建结果,在 bundle 打包场景还存在优化空间,我们在后续工作中配合运行时框架可以做更多打包产物优化。
GEEK TALK
04
总结
新版编译器采用自研打包方案,对比基于 webpack 的旧编译器实现了巨大的性能提升,彻底解决了编译慢、资源占用高的问题,相对友商的编译器也有不错的性能优势。
一些新编译引入的优化手段如 swc 转译、esbuild 压缩、sourcemap 优化 也能用在其他前端项目构建中,并起到加速效果。
在新编译器项目中每个同学都非常努力,贡献了很多奇妙的点子,遇到的大部分难题都有效解决了。我们会继续坚持性能和产物优化这两个方向,不断提升开发者体验和运行时效率。
编辑:黄飞
-
Triton编译器的优化技巧2024-12-25 2613
-
Triton编译器功能介绍 Triton编译器使用教程2024-12-24 3684
-
Keil编译器优化方法2024-10-23 3957
-
编译器的优化选项2023-11-24 2421
-
编译器如何对代码进行优化(上)2023-02-01 1704
-
基于C++编译器的节点融合优化方法2021-06-15 1424
-
编译器优化对函数的影响2020-06-22 3693
-
关于volatile关键字对编译器优化的影响2020-02-28 4021
-
GCC编译器最新版本下载地址(windows)2017-10-29 1112
-
C编译器及其优化2017-10-17 1558
-
编译器_keil的优化选项问题2016-02-25 1108
-
MCS-51程序空间扩展原理及编译器优化2010-10-23 940
-
SIMD计算机的优化编译器设计2009-04-03 948
全部0条评论

快来发表一下你的评论吧 !
