

什么是__attribute__?嵌入式C代码属性怎么定义?
电子说
描述
嵌入式开发,离不开 C 语言,C语言中有很多语法会直接或间接影响你代码的质量,下面就来讲讲__attribute__ 关键字的用法。
1. 什么是 __attribute__
GNU C 编译器增加了一个 __attribute__ 关键字用来声明一个函数、变量或类型的特殊属性。申明这些属性主要用途就是指导编译程序进行特定方面的优化或代码检查。
__attrabute__ 的用法非常简单,当我们定义一个一个函数、变量或者类型时,直接在他名字旁边添加如下属性即可:
__attribute__ ((ATTRIBUTE))
需要注意的是,__attribute__ 后面是两对小括号,不能图方便只写一对,否则会编译报错。括号里的 ATTRIUBTE 表示要声明的属性,目前支持十几种属性声明:
section:自定义段
aligned:对齐
packed:对齐
format:检查函数变参格式
weak:弱声明
alias:函数起别名
noinline:无内联
always_inline:内联函数总是展开
......
比如:
char c __attribute__((algined(8))) = 4;
int global_val __attribute__ ((section(".data")));
当然,我们对一个变量也可以同时添加多个属性。在定义变量前,各个属性之间用逗号隔开。以下三种声明方式是没有问题的。
char c __attribute__((packed, algined(4))); char c __attribute__((packed, algined(4))) = 4; __attribute__((packed, algined(4))) char c = 4;
2. 属性声明:section
section 属性的主要作用是:在程序编译时,将一个函数或者变量放到指定的段,即指定的section 中。
一个可执行文件注意由代码段,数据段、BSS 段构成。代码段主要用来存放编译生成的可执行指令代码、数据段和BSS段用来存放全局变量和未初始化的全局变量。
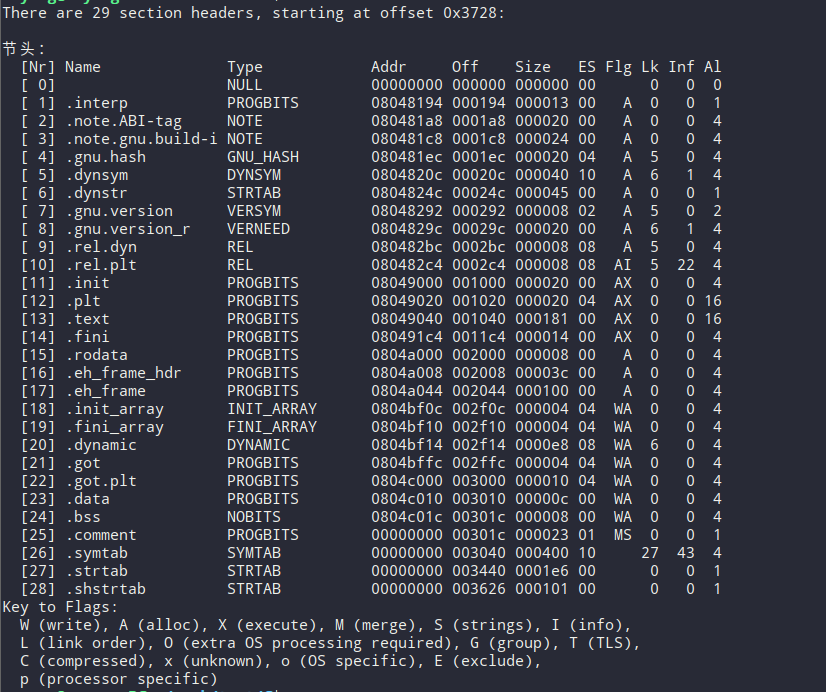
除了这三个段,可执行文件还包含一些其他的段。我们可以用 readelf 去查看一个可执行文件各个section信息。
下表是不同的 section 及说明:
| section | 组成 |
|---|---|
| 代码段(.text) | 函数定义、程序语句 |
| 数据段 (.data) | 初始化的全局变量、初始化的静态局部变量 |
| BSS 段(.bss) | 未初始化的全局变量,未初始化的静态局部变量 |
int global_val = 8;
int unint_val;
int main(void)
{
return 0;
}
我们使用gcc 编译这个程序:
gcc -m32 -o a.out gnu.c
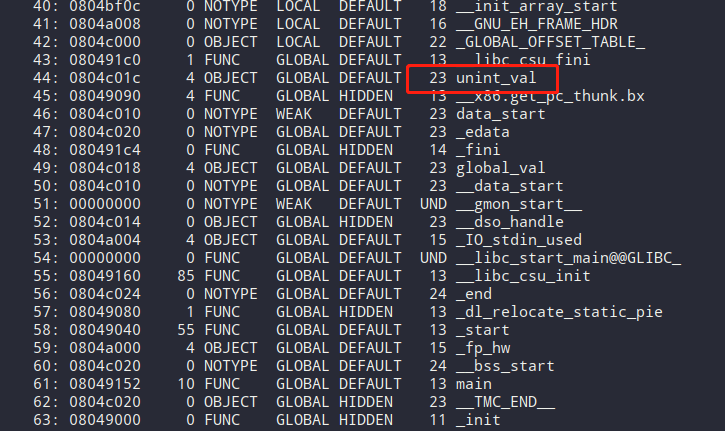
查看符表号信息:
#readelf -s a.out Num: Value Size Type Bind Vis Ndx Name 44: 0804c020 4 OBJECT GLOBAL DEFAULT 24 unint_val 45: 08049090 4 FUNC GLOBAL HIDDEN 13 __x86.get_pc_thunk.bx 46: 0804c010 0 NOTYPE WEAK DEFAULT 23 data_start 47: 0804c01c 0 NOTYPE GLOBAL DEFAULT 23 _edata 48: 080491c4 0 FUNC GLOBAL HIDDEN 14 _fini 49: 0804c018 4 OBJECT GLOBAL DEFAULT 23 global_val 50: 0804c010 0 NOTYPE GLOBAL DEFAULT 23 __data_start 51: 00000000 0 NOTYPE WEAK DEFAULT UND __gmon_start__ 52: 0804c014 0 OBJECT GLOBAL HIDDEN 23 __dso_handle 53: 0804a004 4 OBJECT GLOBAL DEFAULT 15 _IO_stdin_used 54: 00000000 0 FUNC GLOBAL DEFAULT UND __libc_start_main@@GLIBC_ 55: 08049160 85 FUNC GLOBAL DEFAULT 13 __libc_csu_init 56: 0804c024 0 NOTYPE GLOBAL DEFAULT 24 _end 57: 08049080 1 FUNC GLOBAL HIDDEN 13 _dl_relocate_static_pie 58: 08049040 55 FUNC GLOBAL DEFAULT 13 _start 59: 0804a000 4 OBJECT GLOBAL DEFAULT 15 _fp_hw 60: 0804c01c 0 NOTYPE GLOBAL DEFAULT 24 __bss_start 61: 08049152 10 FUNC GLOBAL DEFAULT 13 main
查看 section 信息:
# readelf -S a.out
使用 __attribute__ ((section("xxx"))),修改段的属性。
int global_val = 0;
int unint_val __attribute__((section(".data")));
int main()
{
return 0;
}
可以看到 unint_val 这个变量,已经被编译器放在数据段中。当然也可以自定义段的名称。
3. 属性声明:aligned
GNU C 通过 __attribute__ 来声明 aligned 和 packed 属性,指定一个变量或类型的对齐方式。
通过 aligned 属性,我们可以显示地指定变量 a 在内存中的地址对齐方式。aligned 有一个参数,表示要按几个字节对齐,使用时要注意,地址对齐的字节数必须是 2 的幂次方,否则编译就会报错。
3.1 地址对齐
#includeint a = 1; int b = 2; char c1 = 3; char c2 = 4; int main() { printf("a = %p ", &a); printf("b = %p ", &b); printf("c1 = %p ", &c1); printf("c2 = %p ", &c2); return 0; }
可以看到,char 占一个字节,c2的地址紧挨着 c1
a = 0x404030 b = 0x404034 c1 = 0x404038 c2 = 0x404039
使用 aligned 地址对齐
#includeint a = 1; int b = 2; char c1 = 3; char c2 \__attribute__((aligned(4))) = 4; int main() { printf("a = %p ", &a); printf("b = %p ", &b); printf("c1 = %p ", &c1); printf("c2 = %p ", &c2); return 0; }
可以看到,c2 的地址是按照4字节对齐
a = 0x404030 b = 0x404034 c1 = 0x404038 c2 = 0x40403c
通过 aligned 属性声明,虽然可以显示的指定变量地址的对齐方式,但是也会因为边界对齐造成一定的内存空间浪费。
地址对齐的好处是,为了配合计算机硬件设计,可以简化CPU和内存RAM之间的接口和硬件设计。
例如,一个32位的计算机操作系统,在CPU读取内存时,硬件设计上可能只支持4字节或者4字节倍数对齐地址访问,CPU 每次向 RAM 读写数据时,一个周期可以读写4字节。如果我们把一个int型数据就放在4字节对齐的地址上,那么CPU就可以一次性把数据读取完毕,否则可能需要读取两次。
3.2 结构体对齐
结构体作为一种复杂的数据类型,编译器在给一个结构体变量分配存储空间时,不仅要考虑结构体内各个成员的对齐,还要考虑结构体整体的对齐。
为了结构体各成员对齐,编译器可能会在结构体内填充一些字节。为了结构体的整体对齐,编译器可能会在结构体的末尾一些空间。
#includestruct data { char a; int b; short c; }; int main() { struct data s; printf("size = %d ", sizeof(s)); printf("a = %p ", &s.a); printf("b = %p ", &s.b); printf("c = %p ", &s.c); return 0; }
四字节对齐:占12字节
size = 12 a = 0xffb6c374 b = 0xffb6c378 c = 0xffb6c37c
结构体成员顺序不同,所占大小有可能不同:
#includestruct data { char a; short b; int c; }; int main() { struct data s; printf("size = %d ", sizeof(s)); printf("a = %p ", &s.a); printf("b = %p ", &s.b); printf("c = %p ", &s.c); return 0; }
四字节对齐:占8字节
size = 8 a = 0xffa2d9f8 b = 0xffa2d9fa c = 0xffa2d9fc
显示的指定成员的对齐方式:
#includestruct data { char a; short b __attribute__((aligned(4))); int c; }; int main() { struct data s; printf("size = %d ", sizeof(s)); printf("a = %p ", &s.a); printf("b = %p ", &s.b); printf("c = %p ", &s.c); return 0; }
四字节对齐:占12字节
size = 12 a = 0xffb6c374 b = 0xffb6c378 c = 0xffb6c37c
显示指定结构体对齐方式:
#includestruct data { char a; short b; int c; } __attribute__((aligned(16))); int main() { struct data s; printf("size = %d ", sizeof(s)); printf("a = %p ", &s.a); printf("b = %p ", &s.b); printf("c = %p ", &s.c); return 0; }
16字节对齐,末尾填充8字节:占16字节
size = 16 a = 0xffa2d9f8 b = 0xffa2d9fa c = 0xffa2d9fc
3.3 编译器一定会按照 aligend 指定的方式对齐吗?
我们通过这个属性声明,其实只是建议编译器按照这种大小地址对齐,但不能超过编译器允许的最大值。一个编译器,对每个基本的数据类型都有默认的最大边界对齐字节数,如果超过了,则编译器只能按照它规定的最大对齐字节数来对变量分配地址。
4. 属性声明:packed
aligned 属性一般用来增大变量的地址对齐,元素之间地址对齐会造成一定的内存空洞,而packed属性则正好相反,一般用来减少地址对齐,指定变量或类型使用最可能小的地址对齐方式。
显示的对结构体成员使用packed
#includestruct data { char a; short b __attribute__((packed)); int c __attribute__((packed)); }; int main() { struct data s; printf("size = %d ", sizeof(s)); printf("a = %p ", &s.a); printf("b = %p ", &s.b); printf("c = %p ", &s.c); return 0; }
使用最小一字节对齐:
size = 7 a = 0xfff38fb9 b = 0xfff38fba c = 0xfff38fbc
对整个结构体添加packed属性
struct data {
char a;
short b;
int c;
}__attribute__((packed));
内核中的packed、aligned 声明
在内核源码中,我们经常看到aligned 和 packed 一起使用,即对一个变量或者类型同时使用packed 和 aligned 属性声明。这样做的好处是即避免了结构体各成员间地址对齐产生的内存空洞,又指定了整个结构体的对齐方式。
struct data {
char a;
short b;
int c;
} __attribute__((packed, aligned(8)));
5. 属性声明:format
GNU 通过 __attribute__ 扩展的 format 属性,来指定变参函数的参数格式检查。
它的使用方法如下:
__attribute__((format (archetype, string-index, frist-to-check))) void LOG(const char *fmt, ...) __attribute__((format(printf,1,2)));
属性format(printf,1,2) 有3各参数,第一个参数pritnf 是告诉编译器,按照printf的标准来检查;第二个参数表示LOG()函数所有的参数列表中格式字符串的位置索引,第三个参数是告诉编译器要检查的参数的起始位置。
LOG("hello world ,i am %d ages
", age); /* 前者表示格式字符串,后者表示所有的参数*/
6. 属性声明:weak
GNU C 通过 weak 属性声明,可以将一个强符号,转换为弱符号。使用方法如下:
void __attribute__((weak)) func(void); int num __attribute__((weak));
在一个程序中,无论是变量名,还是函数名,在编译器眼里,就是一个符号而已,符号可以分为强符号和弱符号。
强符号:函数名,初始化的全局变量名
弱符号:未初始化的全局变量名。
在一个工程项目中,对于相同的全局变量名、函数名,我们一般可以归结为以下3种场景:
强符号 + 强符号
强符号 + 弱符号
弱符号 + 弱符号
强符号和弱符号主要用来解决在程序链接过程中,出现多个同名全局变量、同名函数的冲突问题,一般我们遵循以下3个原则:
一山不容二虎
强弱可以共处
体积大者胜出
在一个项目中,不可能同时存在两个强符号。如果在一个多文件的项目中定义两个同名的函数后者全局变量,那么连接器在链接时就会报重定义错误。
但是,在一个工程中允许强符号和弱符号同时存在,比如可以定义一个初始化的全局变量和一个未初始化的全局变量,这种写法在编译时是可以编过的。
编译器对这种同名符号冲突时,在做符号决议时,一般会选择强符号,丢掉弱符号。
还有一种情况是,在一个工程中,当都是弱符号时,那么编译器该选择哪个呢?谁在内存中存储空间大,就选谁。
变量的弱符号与强符号
// func1.c
int a = 1;
int b;
void func(void)
{
printf("func.a = %d
", a);
printf("func.b = %d
", b);
}
// main.c
int a;
int b = 2;
void func();
int main()
{
printf("main.a = %d
", a);
printf("main.b = %d
", b);
func();
return 0;
}
编译后,程序运行结果如下。可以看出打印的都是强符号的值。
main.a = 1 main.b = 2 func.a = 1 func.b = 2
一般不建议在一个工程中定义多个不同类型的同名弱符号,编译时可能会出现各种各样的问题。也不能同时定义两个同名的强符号,否则会报重定义错误。我们可以使用GNU C 的扩展 weak 属性,将一个强符号转换为弱符号。
int a __attribute__((weak)) = 1;
函数的强符号与弱符号
链接器对于同名的函数冲突,同样遵循相同的规则。函数名本身是一个强符号,在一个工程中定义两个同名的函数,编译器肯定会报重定义错误。但是,我们可以通过weak 属性声明,将其中的一个函数名转换为弱符号。
//func1.c
int a __attribute__((weak)) = 1;
void func(void)
{
printf("func.a = %d
", a);
}
//main.c
int a = 4;
void __attribute__((weak)) func(void)
{
printf("main.a = %d
", a);
}
int main(void)
{
func();
return 0;
}
弱符号的用途
在一个源文件中引用一个编号或者函数,当编译器只看到声明,而没看到其定义时,一般编译时不会报错。在链接阶段,链接器会到其他文件中找到这些符号的定义,若未找到,则报未定义错误。
当函数被声明一个弱符号时,会有一个奇特地方:当链接器找不到这个函数的定义时,也不会报错。编译器会将这个函数名,即弱符号,设置为0或者一个特殊值。只有当程序运行时,调用到这个函数,跳转到零地址或者一个特殊的地址才会报错误,产生一个内存错误。
如果我们在使用函数前,判断这个函数地址是否为0,即可避免段错误。你会发现,即使函数未定义也可以正常编过。
弱符号的这个特性在库函数开发设计中应用十分广泛,如果在开发一个库时,基础功能已经实现,有些高级功能还未实现,那么你就可以将这些函数通过weak 属性声明转换为一个弱符号。
7. 属性声明:alias
GNU C 扩展了一个 alias 属性,这个属性很简单,主要用来给函数定义一个别名。
void __f(void)
{
printf("__f
");
}
void f(void) __attribute__((alias("__f")));
int main(void)
{
f();
return 0;
}
在Linux 内核中你会发现alias有时候会和weak属性一起使用。如有些接口随着内核版本升级,函数接口发生了变化,我们可以通过alias属性对旧的接口名字进行封装,重新起一个接口名字。
//f.c
void __f(void)
{
printf("__f
");
}
void f() __attribute__((weak, alias("__f")));
//main.c
void __attribute__((weak)) f(void);
void f(void)
{
printf("f
");
}
int main()
{
f();
return 0;
}
如果我们在main.c 中定义了f()函数,那么main 函数调用f()会调用薪定义的函数,否则调用__f()函数。
8. 属性声明:noinline 和 always_inline
8.1 什么是内联函数
说起内联函数,就不得不说起函数调用开销。一个函数在执行过程中,如果要调用其他函数,则一般会执行以下过程:
保存当前函数现场
跳到调用函数执行
恢复当前函数现场
继续执行当前函数
对于一些短小精悍,并且调用频繁的函数,调用开销大,这个时候我们可以将函数声明为内联函数。编译器遇到内联函数会想宏一样将内联函数之间在调用处展开,这样做就减少了函数调用的开销。
8.2 内联函数与宏
与宏相比,内联函数有以下优势:
参数类型检查:内联函数本质上还是一个函数,在编译过程中编译器会对齐进行参数检查,而宏不具备这个特性。
便于调试:函数支持的调试功能有断点、单步等。
返回值:内联函数有返回值。这个优势是相对于ANSI C 说的。因为现在的宏也有返回值和类型了,如使用语句表达式定义的宏。
接口封装:有些内联函数可以用来封装一个接口,而宏不具备这个特性。
8.3 编译器对内联函数的处理
我们虽然可以通过inline 关键字将一个函数声明为一个内联函数,但是编译器不一定会对这个函数内联展开。编译器也要根据实际情况进行评估,权衡展开和不展开的利弊,并最终决定要不要展开。
内联函数并不是完美的,也有一些缺点。内联函数会增大程序的体积。
一般而言判断一个内联函数是否展开,从程序员的角度主要从以下几点出发:
函数体积小
函数体内无指针赋值、递归、循环语句等
调用频繁
当我们认为一个函数体积小、而且被大量调用,应做内联展开时,就可以使用static inline 关键字修饰它,但是编译器不一定会内联展开。如果想明确告诉编译器一定要展开,或者不展开就可以使用 noinline 和 always_inline 对函数的属性做一个声明。
8.4 内联函数为什么定义在头文件中?
在Linux 内核中,你会看到大量的内联函数被定义在头文件中,而且常常使用static关键字修饰。
为什么定义在头文件中呢?因为它是一个内联函数,可以像宏一样使用,在任何想使用内联函数的源文件中,都不必亲自在定义一遍,直接包含这个头文件即可。
为什么还要用static 修饰呢?因为使用inline关键字定义的内联函数,编译器不一定会内联展开,那么当一个工程中多个头文件包含这个内联函数的定义时,编译时就可能报重复定义的错误。使用satic 关键字修饰,则可以限定这个函数的作用域在各自的源文件内,避免重复定义的发生。
9. 总结
本文主要介绍了 GNU C 的扩展语法 __attributr__ 关键字,并对其中常用的属性声明做了详细的介绍:
section
packed
aligned
format
alias
weak
noinline
always_inline
审核编辑:刘清
-
深入探索GCC的attribute属性2025-02-13 1174
-
求助,请问一个结构体如何全部定义到 __attribute__ 区域?2024-01-16 524
-
rC语言__attribute__的运用2023-05-23 3560
-
嵌入式C语言的弱符号和弱引用2022-12-23 638
-
C语言中__attribute__ 关键字的用法2022-10-19 14895
-
怎么理解RTT中#define UNUSED __attribute__((unused))这个语句呢2022-03-29 2436
-
来了解一下GNU C __attribute__机制2022-03-03 8475
-
【STM32CubeIDE】将变量定义到指定地址2021-12-27 3630
-
attribute用法section部分的资料大合集2021-11-25 769
-
__attribute__((section(x))) 使用详解2021-11-16 1896
-
嵌入式外中断c语言代码2021-07-30 1110
-
__ATTRIBUTE__ 你知多少?2016-09-05 3091
全部0条评论

快来发表一下你的评论吧 !
