

3D芯片堆叠是如何完成
制造/封装
描述
作者:Samuel K. Moore
高端计算的解决方案是堆叠硅片。
一批高性能处理器表明,延续摩尔定律的新方向是向上发展。每一代处理器都要比上一代性能更好,究其根本,这意味着要在硅片上集成更多的逻辑。但其中存在两个问题。首先,我们缩小晶体管及其组成的逻辑和内存块的能力正在放缓。其次,单块芯片已经达到了尺寸极限。光刻工具可以在850平方毫米的面积内绘制图案,这大约是一个现代服务器图形处理单元(GPU)的大小。
有一种解决办法是将两块或多块硅片并排放置在同一个封装中,并使用几毫米长的密集互连将它们缝合在一起,这样它们就可以作为一个单元有效地运行。这种所谓的2.5D方案由先进的封装技术实现,已经落后于几个顶级处理器,这些处理器现在由多个功能性“芯粒”组成,而不是单个集成电路。 但是,要像在同一块芯片上一样传输大量数据,我们需要更短、更密集的连接,而这只能通过将一块芯片堆叠在另一块芯片上来实现。在3D方案中面对面连接两块芯片可能意味着每平方毫米要有数百甚至数千微米长的连接。通过这些短而密集的连接,只需很少的能量就能将数据从一块硅片快速传输到另一块,就好像两块硅片是一块芯片一样。
要做到这一点需要很多创新。工程师们必须想办法防止堆栈中一块芯片的热量破坏另一块芯片,决定哪些功能应该放在哪里、这些功能如何实现,防止偶尔出现的坏芯片造成大量昂贵的无用系统,以及应对一次完成这一切所增加的复杂性。
以下3个示例不仅展示了3D芯片堆叠是如何完成的,还介绍了其优势。
采用3D V-Cache缓存技术的AMD Zen 3
长期以来,个人计算机都可以选择增加内存,以便提高处理超大应用和大数据量工作的速度。由于3D芯片堆叠的出现,CPU芯粒也有了这个选择,但如果你想打造一台更具魅力的计算机,那么订购一款有超大缓存的处理器可能是正确的选择。

在这些架构瑰宝之上,还有一组硅通孔(TSV),即直接穿透大部分硅的垂直互连。硅通孔构建在Zen 3的最后一级缓存中,也就是名为L3的静态随机存取存储器(SRAM)块中。缓存位于计算芯粒的中间,并由其全部8个内核共享。 在处理大量数据工作负载的处理器中,Zen 3晶圆的背面被减薄,使得硅通孔暴露出来。然后,使用混合键合(参见补充介绍“3D技术”)将64MB的SRAM芯粒连接到这些暴露出来的硅通孔上。后一种技术可以每隔9微米在CPU内核和高速缓存之间形成连接。最后,为了结构稳定性和便于热传导,附加上空白硅芯粒以覆盖Zen 3 CPU裸片的其余部分。 以2.5D排列形式在CPU 裸片旁额外添加缓存并不可取,因为数据要花很长时间才能到达处理器内核。AMD高级研究员、设计工程师约翰•吴(John Wuu)在今年2月举行的IEEE国际固态电路会议(ISSCC)上对虚拟参会者说:“虽然L3(缓存)的尺寸增加了两倍,但3D V-cache只增加了4个(时钟)周期的延迟,这只有通过3D堆叠才能实现。”
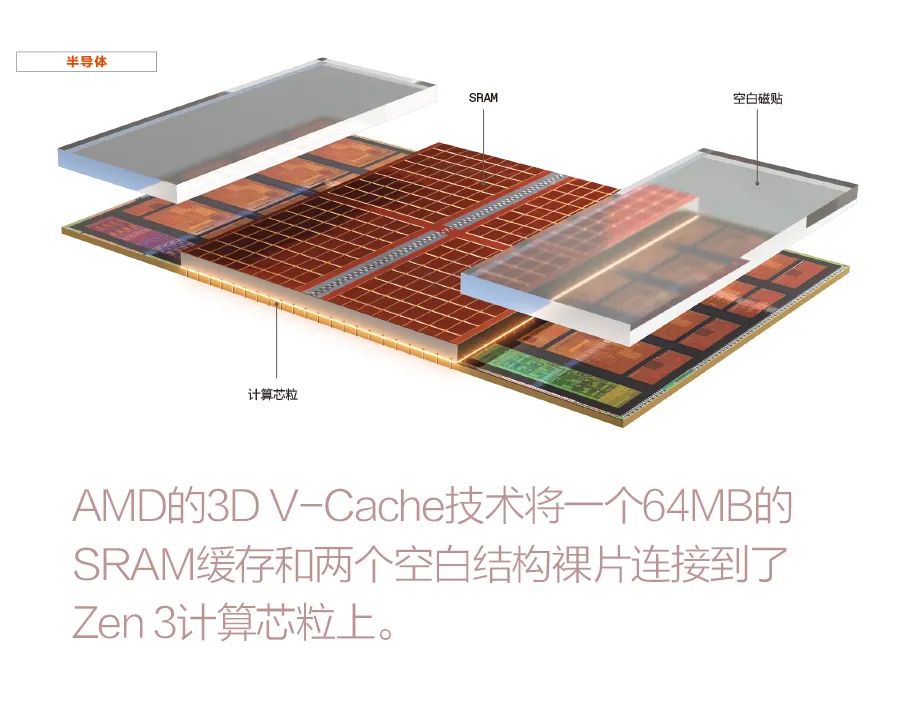
更高的缓存在高端游戏中有了用武之地。这也适用于霄龙服务器中央处理机(CPU)所处理的更重要的工作,可将困难的半导体设计验证工作的运行时间缩短66%。
吴指出,与缩小逻辑的能力相比,业界缩小SRAM的能力正在放缓。因此,未来的SRAM扩展包可能会继续使用更成熟的制造工艺,而计算芯粒将被推到摩尔定律的最前沿。
Graphcore的Bow AI处理器
即使堆栈中的一块芯片上没有晶体管,3D集成也可以加快计算速度。总部位于英国的人工智能(AI)计算机公司Graphcore仅通过在其AI处理器上安装一块功率传输芯片,就大幅提高了其系统的性能。增加功率传输硅片意味着名为Bow的组合芯片可以运行得更快,为1.85而非1.325千兆赫,且电压低于其前一代。与上一代相比,这相当于通过训练神经网络使计算机的速度提高了40%,而能耗降低了16%。重要的是,用户无须更改其软件便能获得这种提升。
功率管理裸片由电容器和硅通孔组合而成。后者只是向处理器芯片供电和提供数据。真正起作用的是电容器。与动态RAM中的位存储组件一样,这些电容器位于硅片中深窄的沟槽中。由于这些电荷储存器离处理器晶体管非常近,因此功率可以顺畅地传输,从而能使处理器内核在较低电压下更快地运行。如果没有功率传输芯片,处理器必须将其工作电压提高到标称水平以上,才能在1.85千兆赫下工作,因此耗电量更高。有了功率芯片,它可以实现更高的时钟频率,并且功耗也更低。 Bow的制造工艺独一无二,但不太可能一直保持这种方式。大多数3D堆叠是在其中一块芯片仍在晶圆上时将一块芯片键合到另一块芯片上完成的,称为“晶圆上芯片”(chip-on-wafer)。相反,Bow采用了台积电的堆叠晶圆(wafer-on-wafer)技术,将一种类型的整片晶圆与另一种类型的整片晶圆键合起来,然后切割成芯片。Graphcore首席技术官兼联合创始人西蒙•诺尔斯(Simon Knowles)表示,Bow是市场上第一款使用这种技术的芯片,它使两块裸片之间的连接密度高于使用晶圆上芯片工艺所能达到的密度。
虽然目前Graphcore的功率传输芯片没有晶体管,但未来可能会有。诺尔斯说,将这种技术用于功率传输“只是我们的第一步,在不久的将来,它会走得更远”。
英特尔的Ponte Vecchio超级计算机芯片
极光超级计算机旨在成为美国首批突破exaflop屏障(每秒百亿亿次高精度浮点运算)的高性能计算机之一。为了让极光达到这种高度,英特尔的Ponte Vecchio在47块硅片上封装了1000多亿个晶体管,构成了一台处理器。英特尔使用2.5D和3D技术将3100平方毫米的硅片塞进了2330平方毫米的空间中,大约相当于4块英伟达A100 GPU。
英特尔院士威尔弗雷德•戈麦斯(Wilfred Gomes)在ISSCC上对各位工程师说,这款处理器将英特尔的2D和3D集成技术推向了极限。 每个Ponte Vecchio实际上是两组使用英特尔2.5D集成技术Co-EMIB连接在一起的镜像芯粒。Co-EMIB是“共嵌式多裸片互连桥接”的缩写,它在两个3D芯粒堆栈之间形成了高密度互连硅桥。Co-EMIB裸片还将高带宽内存和一个I/O芯粒连接到了其余芯粒堆叠的“基底磁贴”上。 基底磁贴采用了英特尔的3D集成技术Foveros,将计算和缓存芯粒堆叠其上。Foveros使用微凸块(每根顶部有一个微米宽焊球的短铜柱)使垂直连接相隔几十微米。信号和电源通过硅通孔进入该堆栈。 8个计算磁贴、4个缓存磁贴和8个给处理器散热的空白“热”磁贴都连接到了基底磁贴上。基底磁贴本身具备高速缓存和允许任何计算磁贴访问任何存储元件的网络。
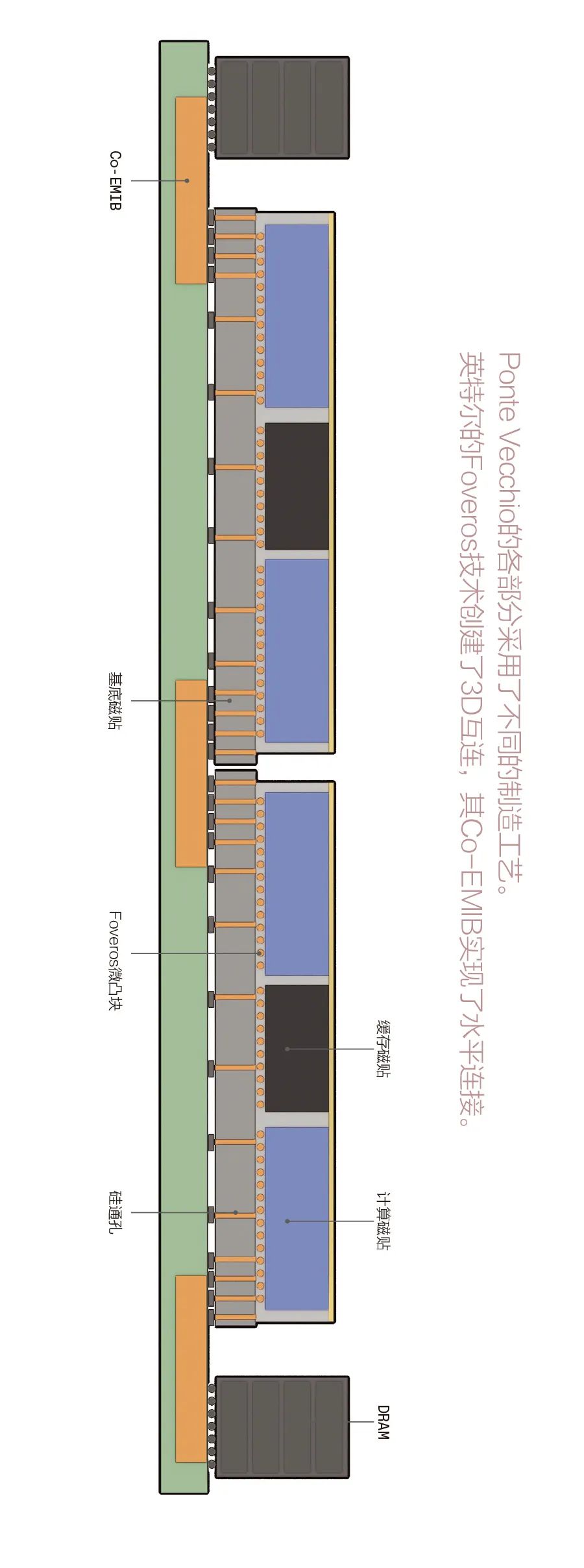
无需多言,这一切都不容易。戈麦斯对与会者说,这项技术在收益管理、时钟电路、热调节和功率传输方面进行了创新。例如,英特尔工程师选择为处理器提供高于正常值(1.8伏)的电压,以便电流足够低,从而简化封装。基底磁贴中的电路将电压降低到了近0.7伏,以便在计算磁贴上使用,并且每个计算磁贴必须在基底磁贴上有自己的功率域。这项能力的关键是一种名为“同轴磁集成电感器”的新型高效组件。因为这些组件都内置在封装基板中,所以在向计算磁贴提供电压之前,电路实际上在基底磁贴和封装之间来回蜿蜒。
戈麦斯表示,从2008年第一台千万亿次浮点运算超级计算机发展到今年的百亿亿次浮点运算超级计算机花了14年。他预测,借助3D堆叠等先进封装技术,下次将计算速度提高千倍所需的时间可能会缩短到6年。
3D技术
混合键合将芯片互连堆栈顶部的铜焊盘与另一块芯片上的铜焊盘直接键合在一起。在混合键合中,焊盘位于被氧化物绝缘体包围的小凹槽中。绝缘体被化学激活,在室温下被反向按压时会立即结合。然后,在退火步骤中,铜焊盘会膨胀并桥接间隙,形成低阻抗链路。 混合键合的连接密度高达每平方毫米1万个键合,远高于微凸块技术每平方毫米400至1600个键合的连接密度(见图表)。

如今可以实现的间距(从一个互连的边缘到下一个互连最边缘的距离)约为9微米,更紧密的几何结构正在研究中。封装技术公司ASE集团的工程和技术营销总监曹丽红(Lihong Cao,音)表示,这项技术的极限间距可能在3微米左右。她说,改进混合键合最关键的步骤是防止晶圆翘曲,并将每一面的表面粗糙度降低到纳米级。

微凸块本质上是一种叫做“倒装芯片”的标准封装技术的缩小版。在倒装芯片中,焊料凸块被添加到了芯片顶部(表面)的互连端点。然后将芯片翻转到具有一组匹配互连的封装基板上,并熔化焊料形成键合。要用这种技术堆叠两块芯片,其中一块芯片的表面必须有短铜柱。然后用一个“微凸块”焊料盖住这些芯片,通过熔化焊料将两块芯片面对面连接起来。
使用微凸块时,从一个连接的起点到下一个连接最边缘的最短距离(也就是间距)可以小于50微米。英特尔在Ponte Vecchio超级计算机芯片中使用了36微米间距版本的Foveros 3D集成技术。三星表示,其名为3D X-Cube的微凸块技术可以实现30微米的间距。该技术达不到(上述)混合键合的密度。然而,它对对齐和平面化的要求并不像混合键合那样严格,因此更容易将采用不同制造技术制造的多块芯片堆叠到单个基极芯片上。

硅通孔(TSV)是垂直向下穿过芯片硅的互连。它们不会贯穿整个晶圆,因此必须将硅片的背面磨平,直至硅通孔暴露出来。这在3D堆叠芯片中通常是必要的,因为要将芯片键合在一起使其互连面对面。在这种情况下,硅通孔可为堆栈供电并提供数据。多年来,它们在垂直堆叠多块内存芯片的高带宽动态RAM中得到了广泛应用。但随着3D芯片堆叠技术的发展,这项技术也应用到了逻辑芯片中。
作者:Samuel K. Moore
编辑:黄飞
-
三星电子完成 900 层超高堆叠 3D NAND 闪存原型开发2026-05-26 1363
-
3D堆叠像素探测器芯片技术详解(72页PPT)2024-11-01 4787
-
3D堆叠发展过程中面临的挑战2024-09-19 2713
-
3D芯片堆叠是如何完成的2022-08-31 7790
-
AMD 3D堆叠缓存提升不俗,其他厂商为何不效仿?2022-04-13 8058
-
3D封装技术定义和解析2020-05-28 7593
-
芯片的3D化历程2020-03-19 2264
-
国际大厂们之间的“3D堆叠大战”2020-01-28 4550
-
Global Foundries 12nm工艺的3D封装安谋芯片面世2019-08-13 3677
-
2.5D异构和3D晶圆级堆叠正在重塑封装产业2019-02-15 8636
-
什么是3D芯片堆叠技术3D芯片堆叠技术的发展历程和详细资料简介2018-12-31 34714
-
英特尔为你解说“Foveros”逻辑芯片3D堆叠技术2018-12-14 9215
-
半导体产业的未来:3D堆叠封装技术2016-06-10 2878
-
TSMC 和 Cadence 合作开发3D-IC参考流程以实现真正的3D堆叠2013-09-26 1858
全部0条评论

快来发表一下你的评论吧 !
