

基于卷积神经网络的双重特征提取方法
人工智能
描述
集成电路(IC)的单个元件非常小,其生产要求达到原子级的精度。集成电路是通过在由半导体材料(通常是硅)制成的晶圆上创建电路结构。为了生产高密度集成电路,晶圆表面必须非常干净,而且在前一个晶圆上制作的电路层应该是对齐的。如果这些条件没有得到满足,高密度结构可能会坍塌。
为了防止这种情况的发生,必须不断地清洗晶圆以避免污染,并清除以前的工艺步骤的残留物。然后,自动缺陷分类(ADC)被用来使用扫描电子显微镜图像来识别和分类晶圆表面缺陷。然而,目前ADC系统的分类性能很差。如果缺陷可以被正确分类,那么制造问题的根源就可以被识别并最终解决。
机器学习技术已被广泛接受,并且很适合此类分类问题。基于卷积神经网络的双重特征提取方法。提出的模型使用Radon拉冬变换进行第一次特征提取,然后将此特征输入卷积层进行第二次特征提取。用真实的数据集进行的实验验证了所提方法取得了较高的缺陷分类性能,缺陷模式识别准确率高达98.5%,我们证实了所提特征提取技术的有效性。
对于集成电路的制造来说,Wafer Map上显示的缺陷图案包含了工程师寻找缺陷原因的关键信息,以提高良率。因此,分析晶圆图缺陷的根本原因对于提高良率和最大限度地提高良好芯片的产量至关重要。然而,分析wafer map的传统方法很耗时,而且准确度低。基于人工的方法的准确率低于45%。
近年来,许多都对晶圆缺陷模式识别问题进行了研究。应用决策树和神经网络对晶圆级芯片级封装图像进行缺陷分类。对无监督学习的神经网络来构建晶圆图的聚类。根据特定的故障模式对集群进行了标注,而wafer map则根据其与集群的接近程度进行分类。这种方法的优点是可以引入新的故障模式来识别表现出未知故障模式的wafer map。
wafer map可以转换为图像,wafer map故障模式识别适合于深度学习,这是一种强大的监督学习技术,不需要人工设计特征。深度学习可以达到很高的分类精度,特别是在主要包括图像分类的任务中。一种基于新型人工神经网络(ANN)架构的快速而准确的解决方案,使用卷积神经网络(CNN)采用最先进的技术进行精确的光刻热点检测。将CNN用于缺陷模式分类和晶圆图检索任务,证明了通过只使用合成数据进行网络训练,真实的wafer map可以以高精确度进行分类使用CNN和极端梯度提升技术对ADI(After Deveroper Inspection)缺陷进行分类。CNN和极端梯度提升的测试数据集的总体分类精度分别为99.2%和98.1%。证明了这种技术在识别半导体晶圆的缺陷模式方面的成功。
方法
建议的方法有三个贡献。首先,该方法只需要有和没有目标故障图案的晶圆图来识别,而不需要手动设计故障图案的特征来识别。第二,能够在双重特征提取的基础上实现高识别精度。在这个模型中,使用Radon拉东变换进行第一次特征提取,然后将此特征输入卷积层进行第二次特征提取。在这个过程中,可以在每一层学到丰富的特征,这些特征可以作为图像检索的良好描述符。最后,我们的方法可以扩展到多类分类,以同时识别各种类型的故障模式。使用半导体制造的真实数据证实了框架的有效性。
A. 研究过程
有六个步骤(如图1所示)。首先,探索了缺陷图像的数据。其次,用以下方法对图像进行预处理:调整图像大小、反转像素强度等。然后,进行特征提取。同时使用两种方法来提取特征,Radon拉东变换和CNN。在模型的训练和测试中,将80%用于训练集,20%用于测试集。最后,用准确率、精确度、召回率和F1-Score来评估所提出的方法的性能。
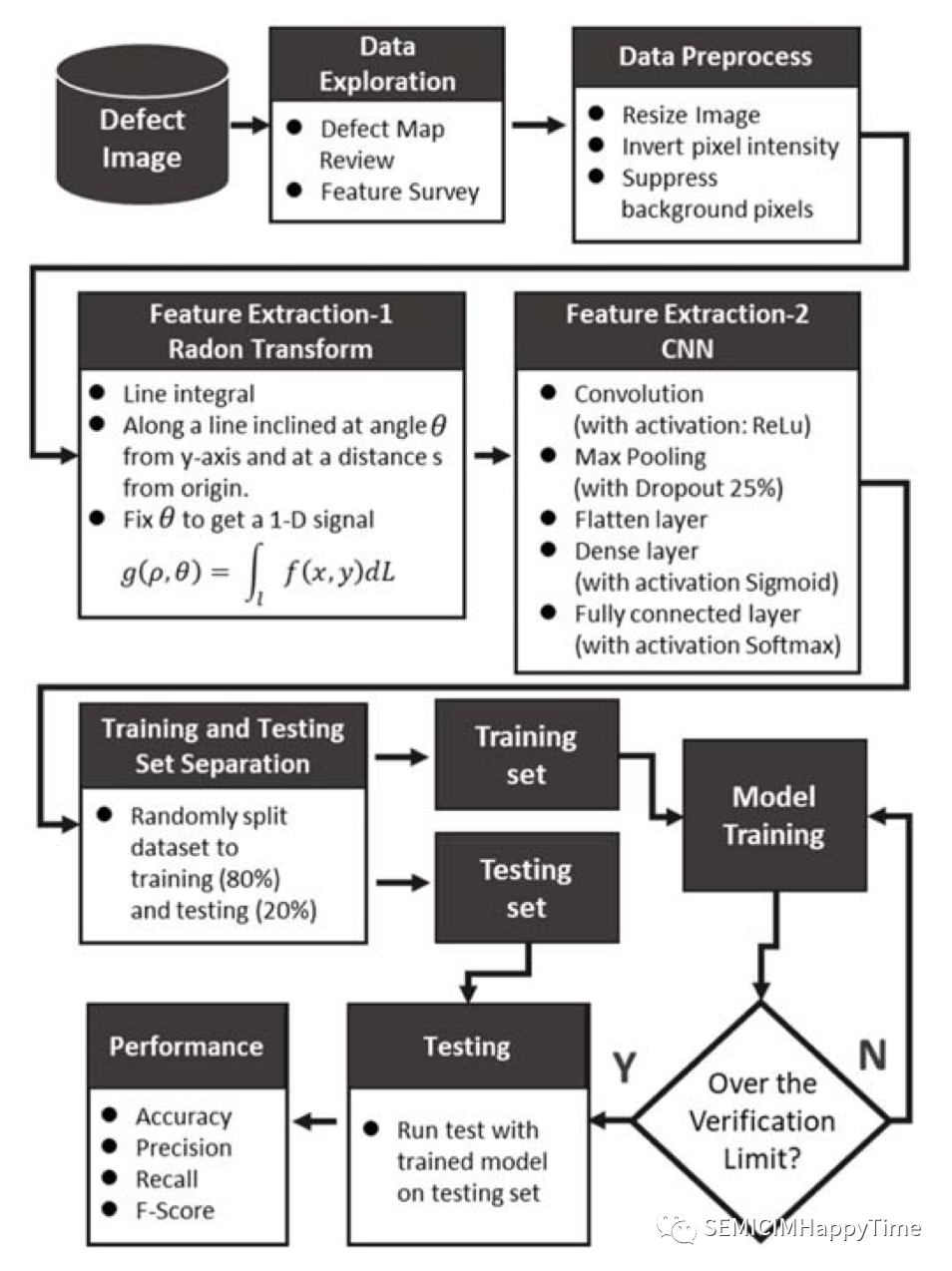
图1. 模型训练和测试的工作流程
B. 数据探索
共有11种缺陷类型,包括残留、划痕、球状、瓶状、法隆、丝状、多点、小颗粒、椭圆形和颜色标记(如表一所示)。每个缺陷都有不同的特点和要素。例如,"Flask "的缺陷类型由铝(Al)和氧(O)组成,"Falon "的缺陷类型由铁(Fe)和镍(Ni)组成,而 "Oval "的缺陷类型则由氟(F)组成。不同机器零件的老化会导致不同的缺陷。例如,"Flask"的缺陷包含铝(Al)和氧(O)元素,主要来自化学气相沉积(CVD)工艺腔室的静电吸盘(ESC)(图2)。

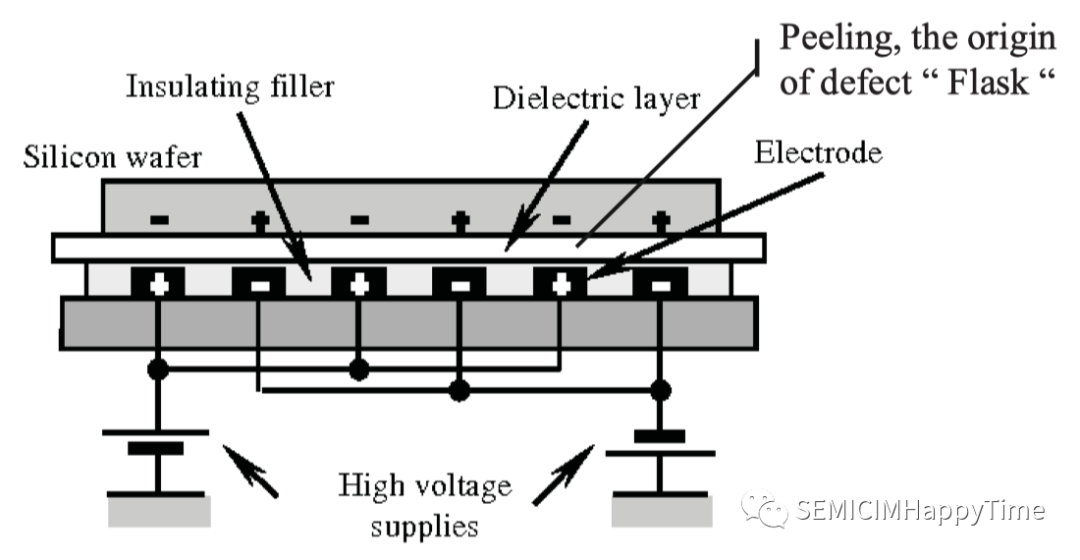
图2. 静电吸盘(ESC)的结构
静电吸盘是一种在施加于电极的电压下在电极和物体之间产生吸引力的装置。在CVD工艺的高温高压环境下,随着静电吸盘的老化,颗粒会落在晶圆表面。当检测到这种缺陷时,这意味着CVD设备的腔体需要维护,并以新的部件替换老化的部件。同样,当检测到其他类型的缺陷时,他们必须有自己的失控行动计划(OCAP),以确保半导体制造的质量。
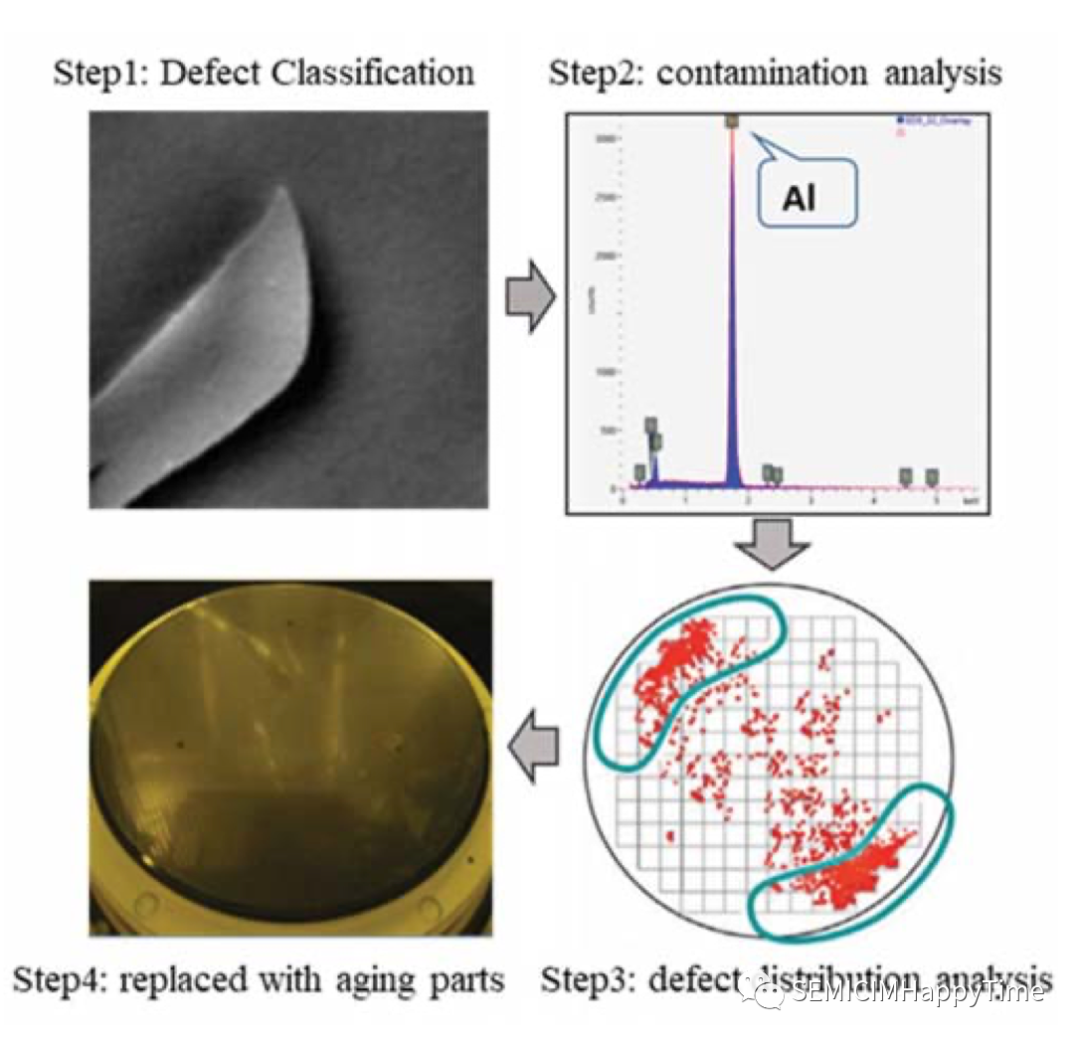
图3. 缺陷 "Flask"的失控行动方案
C. CNN的特征提取
卷积神经网络是受生物启发的动物视觉皮层的变体。有两种类型的细胞:简单细胞和复杂细胞,其中简单细胞提取特征,而复杂细胞从空间邻域结合几个这样的局部特征。CNN试图模仿这种结构,以类似的方式从输入空间提取特征,然后进行分类。网络中的每个卷积层包含许多特征图。一个特征图中的神经元被约束为共享相同的权重。
参数共享的理念允许不同的神经元共享相同的参数。为了完成这一任务,隐藏的神经元被组织成共享参数的特征图。覆盖图像不同块的特征图中的隐藏单元共享相同的参数,并从不同块中提取相同类型的特征。一个图像的每个区块都与多个特征图相关联,不同特征图中的神经元从同一区块中提取不同的特征。图4帮助我们清楚地理解了参数共享的过程:特征图中的每个隐藏单元与图像的不同块相连,并提取相同类型的特征。不同特征图中的隐藏单元从同一块中提取不同的特征。
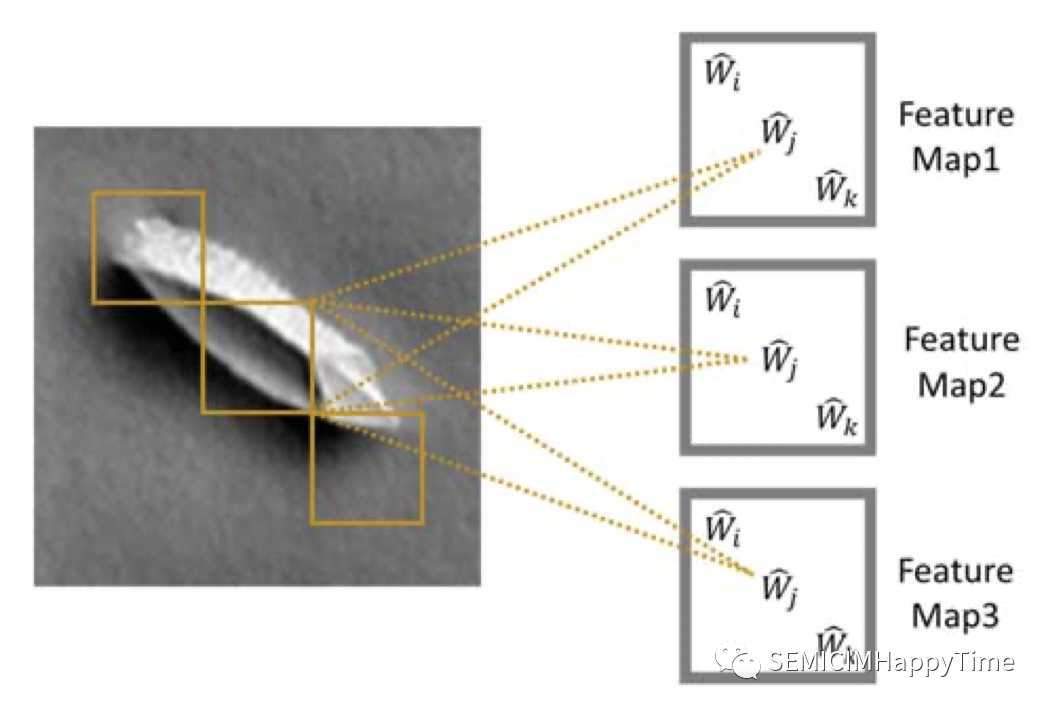
图4. CNN中的参数共享
在一幅图像中,区块可以重叠。为了获得每个隐藏单元的激活值,连接到特征图的输入通道的权重要乘以输入向量。这种操作被称为卷积。基本上,我们专注于离散卷积。离散卷积操作可以定义为:
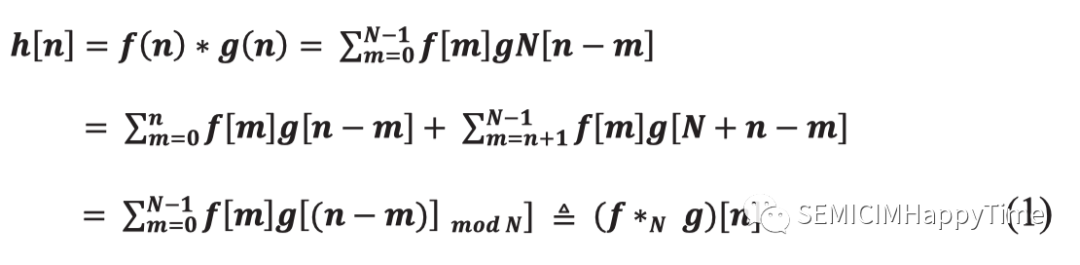
和是两个函数。离散卷积是移位、乘法和加法运算的组合。在这里,卷积操作是通过将权重矩阵与图像的某些块相加,然后将权重矩阵移到其他重叠的块上。
D. Radon拉东变换的特征提取
Radon拉东变换是用于检测图像内特征的技术之一。它基于图像域直线的参数化和沿这些直线的图像积分的评估。由于Radon拉东变换的固有特性,它是捕捉图像方向性特征的一个有用工具。此外,Radon拉东变换是平移和旋转不变的,所以它可以保留像素强度的变化。二维图像函数在平面上的Radon拉东变换定义为:
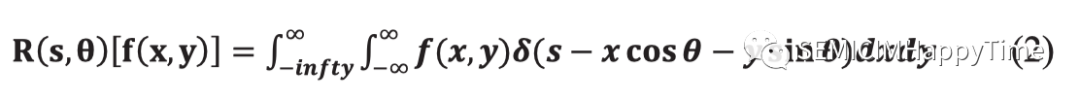
其中是狄拉克函数,是直线与原点的垂直距离,是距离向量形成的角度。
Radon拉东变换已被广泛用于检索边缘检测、纹理分类和计算机断层成像中的图像局部特征。图5展示了一个缺陷图像的Radon拉东变换的例子。在此,提出了一种新的方法,通过使用Radon拉东变换和卷积神经网络的组合来识别缺陷图案。。

图5. 原始图像和Radon拉东变换在各自角度为0-170°时的比较
E. 模型架构
使用卷积神经网络(CNN)作为分类器的主要架构。CNN是一个非线性过滤器的堆栈,它逐渐减少图像的空间范围,同时增加描述每个位置的图像的过滤器输出数量。在堆栈的顶部是一个多叉逻辑回归分类器,它将表征映射到每个输出类别("剩余"、"划痕"、"球"、"驼峰 "等)的概率值。整个网络通过反向传播共同优化,这通常是通过随机梯度下降实现的 。
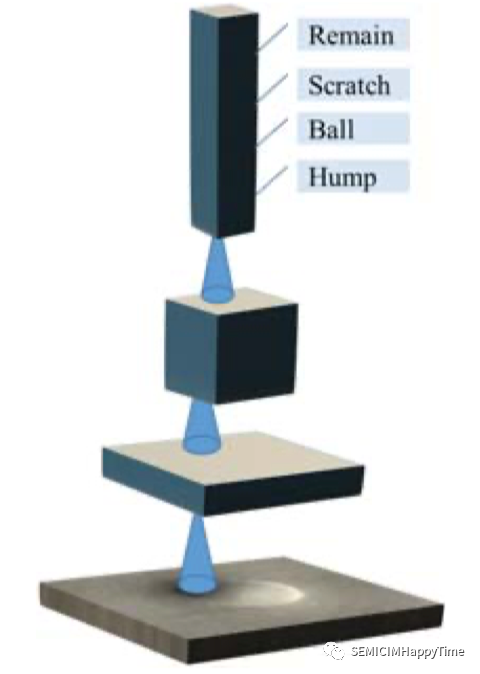
图6. CNN模型结构
尝试将不同的卷积神经网络与Radon拉东变换相结合,作为缺陷模式识别的分类器,包括VGG16、Inception和ResNet。如图7所示,RadonNet有两个主要架构。第一个是原始图像的CNN。它基于卷积层和ReLU修正线性单元激活提取特征,然后通过参数共享将结果输出到扁平化层。第二个是Radon拉东变换后的图像的CNN。它可以在每个卷积层学习丰富的特征。最后,将这两个结果结合起来,输出到具有sigmoid函数激活的全连接层。模型平均后,加入另一个具有通道11(缺陷类的数量)的全连接层。输出是用于计算类别概率的softmax层。
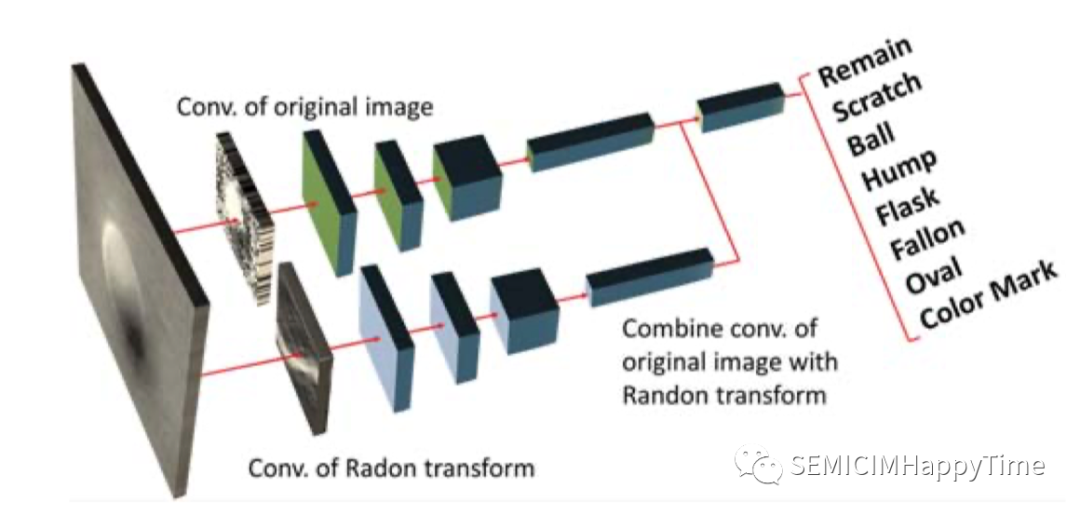
图7. RadonNet的结构
F. 算法设计
RadonNet使用小批量随机梯度下降法进行训练(图8)。在每次迭代中,随机抽取n个图像来计算梯度,然后更新网络参数(W)。它在数据集中经过次后停止。算法中的所有函数和超参数都可以在后面介绍的不同神经网络中实现。

图8. CNN模型结构
学习率
在训练任何深度学习模型时,最难设置的参数之一是学习率。如果数值很大,模型的权重就会开始振荡,它们会有很大的变化,使模型无法适应误差的变化。如果学习率太小,会使模型的学习成本增加,很可能卡在局部最小值。在训练深度网络时,随着时间的推移使学习率退火通常是有帮助的。在这里使用用Cosine decay作为学习率的函数,它实证研究了CIFAR-10和CIFAR-100数据集的性能,这些数据集已经被证明是最先进的新结果。计算步骤如下:

其中可以被看作是一个基线,以确保学习率不会低于某个值。
2. 输出设计
输出层是一个全连接层,其隐藏大小等于所代表的标签数量,以输出预测的置信度分数()。如公式7所示,给定一个图像,用表示类的预测分数。这些分数可以通过softmax算子进行归一化,得到预测的概率。让表示softmax算子的输出,类的概率可以通过以下公式计算:
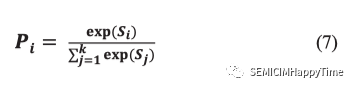
其中,并且 ,是一个有效的概率分布。
3. 损失函数
在训练过程中,使用负交叉熵损失函数的最小化来更新模型参数,使这两个概率分布彼此相似。如公式8所示,假设图像的真实标签是,的真实概率分布()可以构造为,否则可以构造为0。
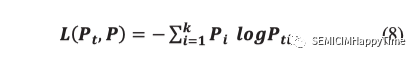
特别是,通过的构造方式,我们知道 。最佳解决方案是 = 无限大,同时保持其他的足够小。它可以促使输出的分数大大地与众不同。
G. 数据扩增
在深度学习中,我们经常需要大量的数据来保证训练过程中不会出现过拟合。事实证明,数据扩增可以解决数据不足的问题,提高系统训练的准确性。它是通过转换训练数据来生成样本的过程,目的是提高分类器的准确性和鲁棒性。我们使用以下方法作为数据增强:随机裁剪(512中的±64),随机翻转(±90°x i ,),随机亮度(255中的±32),随机饱和度(从50%到150%),随机色调(0.5中的±0.2),以及随机对比度(从50%到150%)。做完这些工作后,我们的眼睛也许还能认出它是同一张图片,但对机器来说,它是一张完全不同的新图片。
结果
将这个方法与最先进的深度学习方法在先进的半导体工艺(5纳米芯片)缺陷模式分类上进行评估和比较。
A. 训练程序
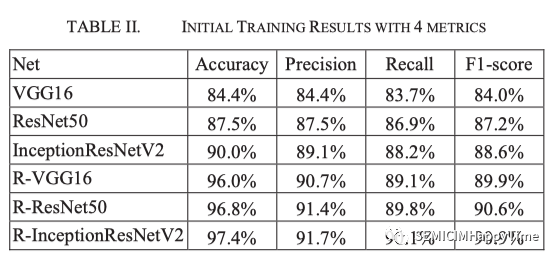
首先,我们使用SGD优化器训练模型,并将所有实验的批次大小设置为32。我们将初始学习率设置为10-4。使用准确性、精确性、召回率和F1-score作为评价指标。初始训练结果见表二。R-VGG16/ResNet50/R-InceptionResNetV2是与Radon拉东变换相结合的改进模型。根据结果,RadonNet比原始模型有明显的改进。
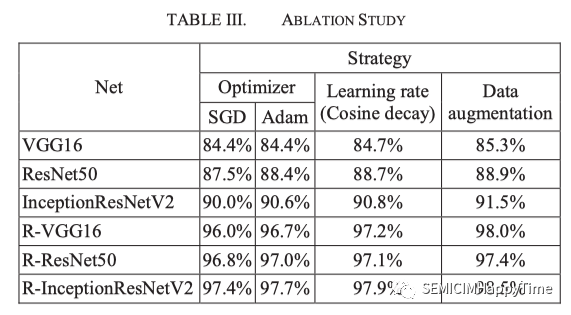
B. 消融学习
为了证明RadonNet的实用性,进行了严格的消融学习,并在表三中显示了定量比较。优化器 "的策略显示了使用SGD(随机梯度下降)和Adam(自适应矩估计)作为优化器的准确性。Adam结合了SGD和RMSprop(Root Mean Square Propagation)的功能,保留了动量来调整过去梯度方向的梯度速度,同时也调整了梯度值平方的学习率。这将使参数更新更加稳定,以获得更好的训练效果。
“学习率"的策略通过Cosine decay来显示训练结果。在使用Cosine decay的情况下,训练结果比使用固定的学习率要好。最后,带有数据增强的R-InceptionResNetV2是最好的模型,准确率为98.5%。
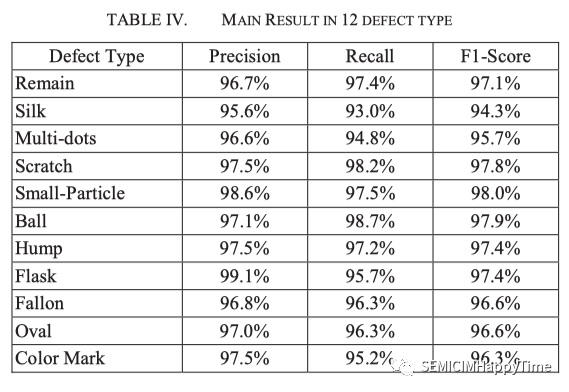
C. 主要结果
用三个评价指标验证了所提模型的有效性:精度、召回率和F1-score。表四显示了11种缺陷类型的验证模型的性能。所有缺陷类型的精确度都在95%以上。除了 "Silk "和 "Multi-dots "的缺陷类型,其他两个指标也都高于95%。这可能是由于其结构不确定,容易与其他缺陷形状相混淆。
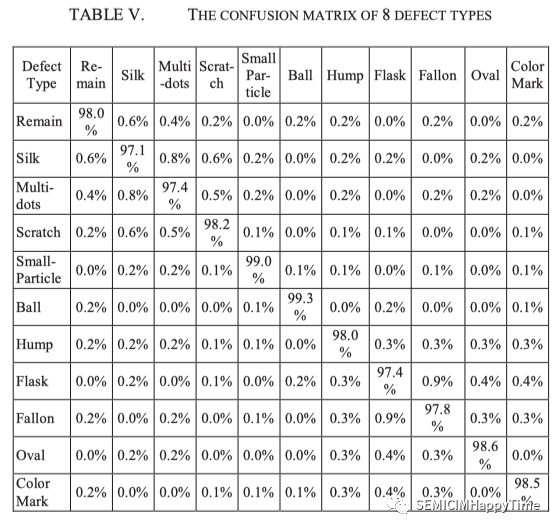
表五是混淆矩阵,它显示了以百分比表示的每类分类的准确性。由于保密的原因,只能提供每类的准确性,而不是晶圆的绝对数量。在这个表格中,标签(基础事实)显示在左列,而建议的方法的预测结果在最上面一行。对角线上的元素代表每种类型的识别率。大多数缺陷类型的准确率都大于97%。总体准确率为98.5%。
成功地将双特征提取技术用于晶圆缺陷分类。提出了一种新的ADC方法,结合了Radon拉东变换和卷积神经网络。Radon拉东变换可以从晶圆表面缺陷图像中提取有效特征。CNN将图像转换为深度维度,用于第二次特征提取。然后,神经网络可以学习这个丰富的特征来识别什么类型的缺陷。使用真实的缺陷图像数据集进行的性能评估实验得出的分类准确率平均为98.5%。证明了新的ADC方法对晶圆图故障模式识别是有效的。
编辑:黄飞
-
卷积神经网络的基本结构和工作原理2024-07-03 3341
-
卷积神经网络的基本结构及其功能2024-07-02 5338
-
卷积神经网络的基本原理 卷积神经网络发展 卷积神经网络三大特点2023-08-21 4163
-
卷积神经网络模型发展及应用2022-08-02 13420
-
为什么卷积神经网络可以做到不变性特征提取?2021-05-20 6342
-
卷积神经网络是怎样实现不变性特征提取的?2021-04-30 3643
-
基于卷积循环神经网络的自动代码特征提取模型2021-03-30 1203
-
基于三通道全连接层的卷积神经网络特征提取2017-11-28 1654
-
模拟电路故障诊断中的特征提取方法2016-12-09 5461
-
如何将脉冲耦合神经网络,体视学等结合实现药材显微图像的特征提取?2015-04-16 2788
-
故障特征提取的方法研究2006-03-11 2020
全部0条评论

快来发表一下你的评论吧 !
