

如何使用Vitis-AI加速YOLOX模型实现视频中的目标检测
描述
本文将介绍如何使用Vitis-AI加速YOLOX模型实现视频中的目标检测,并对相关源码进行解读。由于演示的示例程序源码是Vitis-AI开源项目提供的,本文演示之前会介绍所需要的准备工作。演示之后会对关键源码进行解析。
一、Vitis AI Library简介
上一篇帖子中,我们了解了Vitis统一软件平台和Vitis AI,并体验了Vitis AI Runtime的Resnet50图像分类示例程序。本篇文章我们将会介绍Vitis AI Library,并体验基于Vitis AI Library的YOLOX视频目标检测示例程序。
Vitis AI User Guide中的一张图可以很好的理解Vitis AI Library和Vitis AI Runtime的关系:
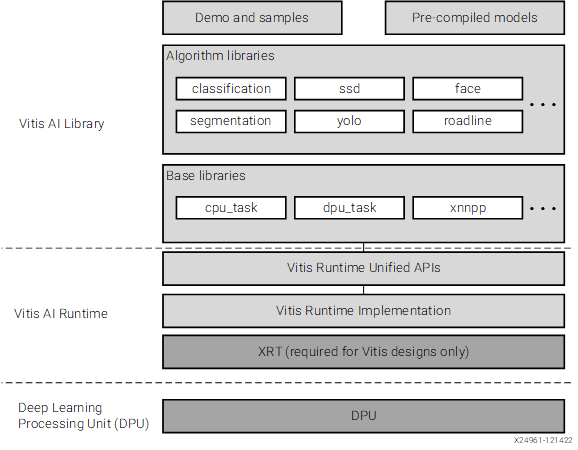
简单来说,Vitis AI Library是在Vitis AI Runtime之上构建出来的。
二、YOLOX视频目标检测示例体验
参考此前的帖子:【KV260视觉入门套件试用体验】部署DPU镜像并运行Vitis AI图像分类示例程序
首先需要部署DPU镜像,DPU镜像系统启动过程中会加载DPU IP到FPGA侧,并且系统本身已经集成了Vitis AI所需的各种库文件。
2.1 准备测试所需视频文件
赛灵思官方文档里面提供了测试视频资源
在开发板上下载、解压的命令为:
# 跳转到HOME目录 cd ~ # 下载 tar.gz 文件 TGZ=[vitis_ai_library_r3.0.0_video.tar.gz](https://china.xilinx.com/bin/public/openDownload?filename=vitis_ai_library_r3.0.0_video.tar.gz) wget -O $TGZ "[https://china.xilinx.com/bin/public/openDownload?filename=](https://china.xilinx.com/bin/public/openDownload?filename=vitis_ai_library_r3.0.0_video.tar.gz)$TGZ" # 解压 tar.gz 文件 DIR=[vitis_ai_library_r3.0.0_video](https://china.xilinx.com/bin/public/openDownload?filename=vitis_ai_library_r3.0.0_video.tar.gz) mkdir $DIR tar -C $DIR -xvf $TGZ
(左右移动查看全部内容)
2.2 准备KV260套件和DPU镜像SD卡
和上一篇帖子一样,使用Vitis-AI之前需要先准备好KV260套件和写入DPU镜像的SD卡,具体可以参考上一篇帖子中的第二章“部署DPU镜像到KV260”:【KV260视觉入门套件试用体验】部署DPU镜像并运行Vitis AI图像分类示例程序
2.3 编译YOLOX视频目标检测示例程序
KV260使用DPU镜像的SD卡启动后,跳转到Vitis-AI/目录下,可以看到如下文件及目录:

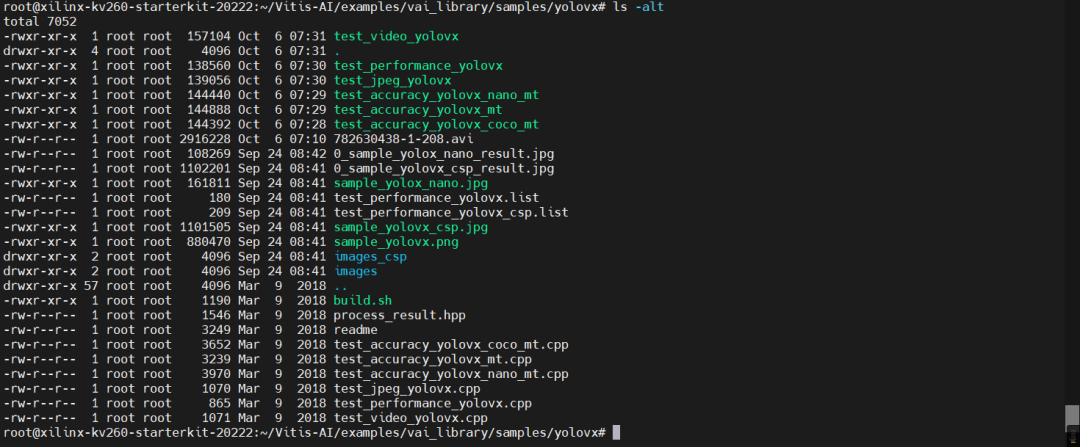
其中,蓝色的为目录,绿色的为可执行文件,白色的为没有执行权限的文件。
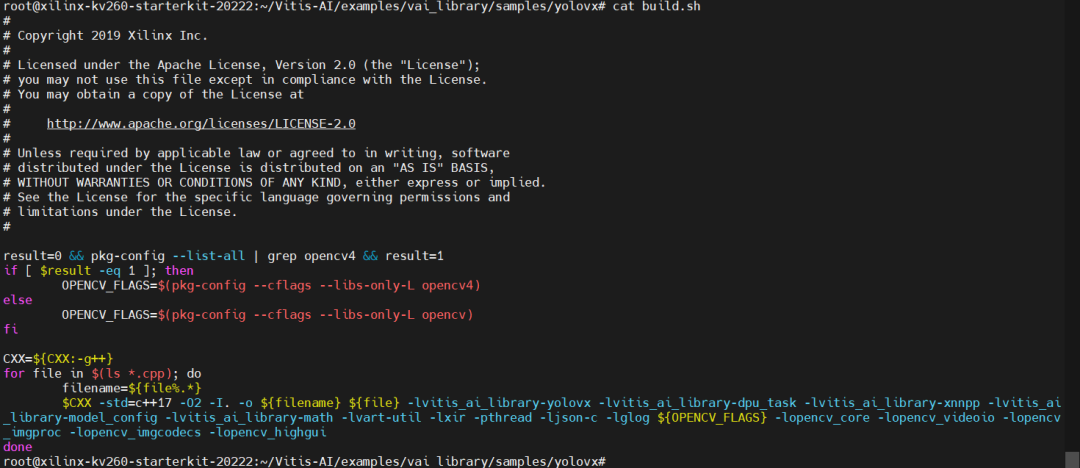
执行build.sh脚本,可以重新编译文件(可以尝试将可执行文件删除掉再重新执行build.sh脚本)。
该脚本文件内的代码为:
重新编译后,可以看到时间戳全部更新了:
2.4 运行YOLOX视频目标检测示例程序
接下来,运行YOLOX视频目标检测程序——test_video_yolox,命令为:
VIDEO_PATH=~/vitis_ai_library_r3.0.0_video/apps/seg_and_pose_detect/seg_960_540.avi MODEL_NAME=yolox_nano_pt ./test_video_yolovx $MODEL_NAME $VIDEO_PATH
(左右移动查看全部内容)
可以看到,画面中的目标被框起来了。
三、YOLOX视频目标检测原理解析
YOLOX视频目标检测示例程序源码非常简短(test_video_yolovx.cpp文件):
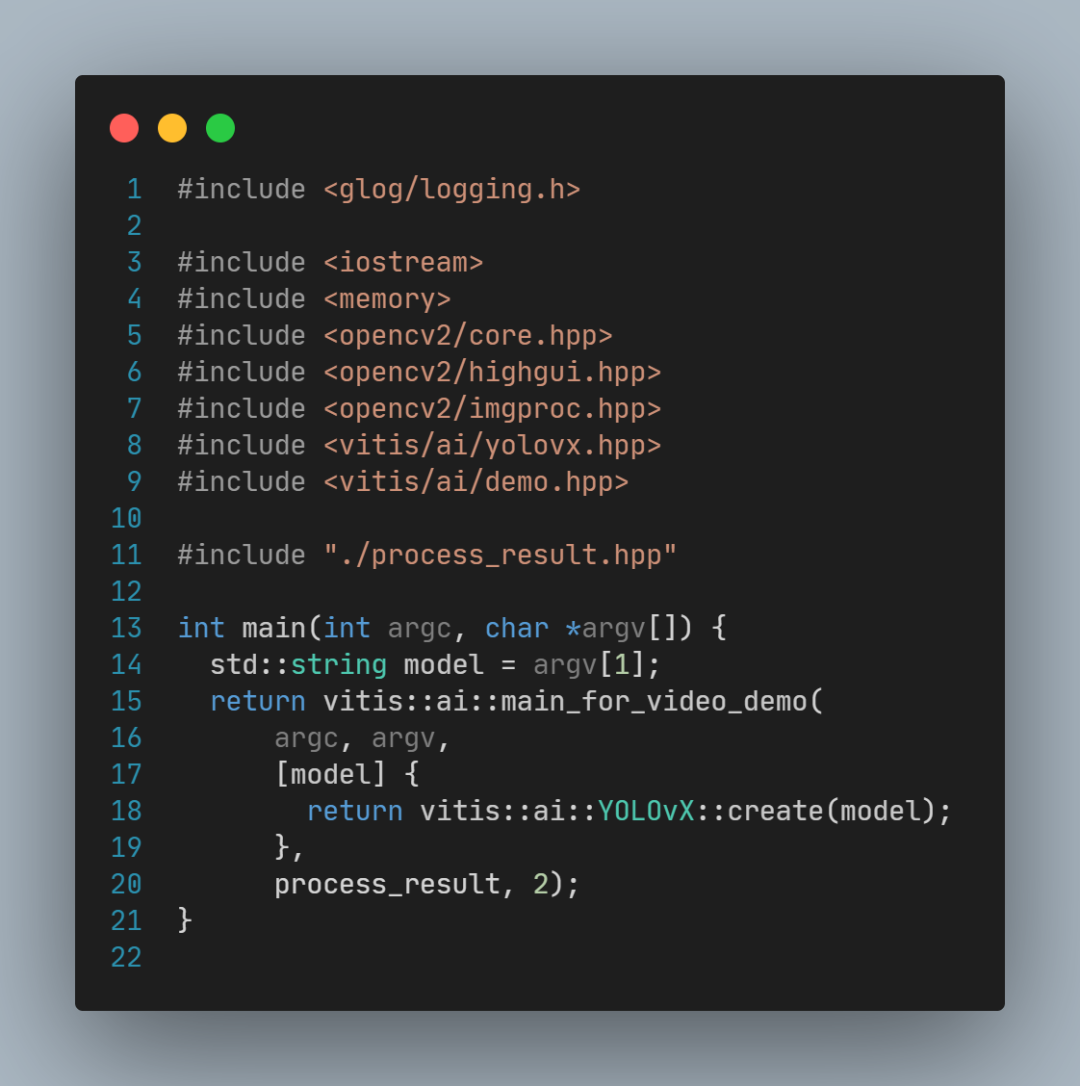
这段代码中:
model是模型名称;
vitis::create(model) 用于创建模型;
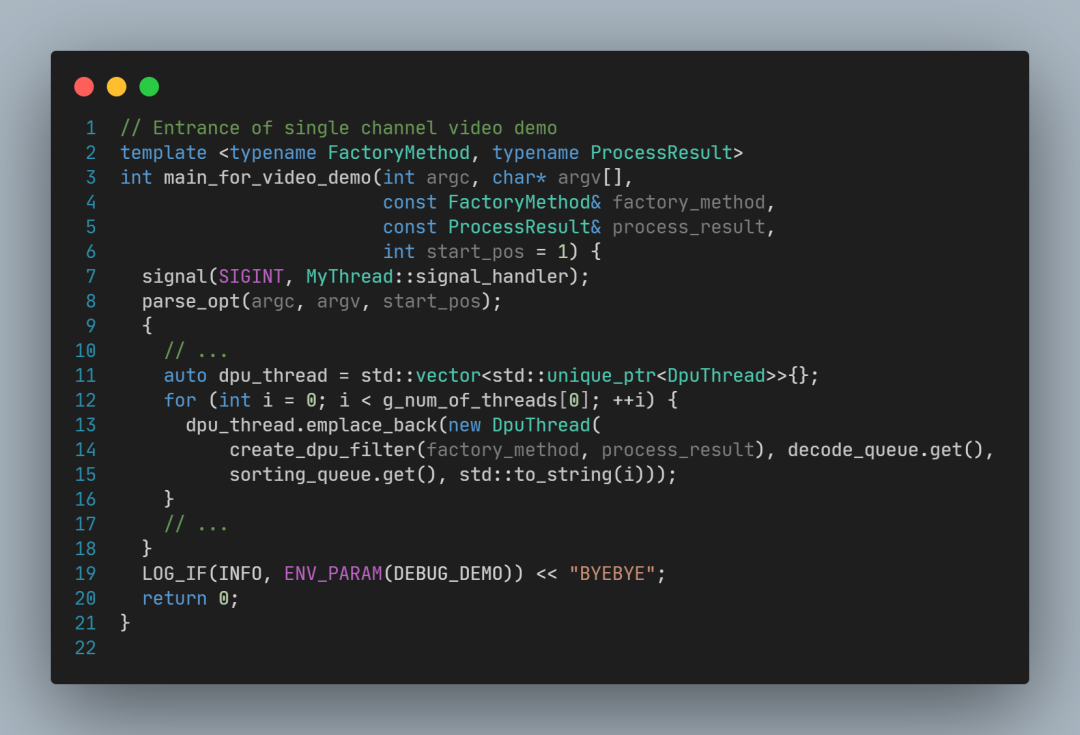
3.1 main_for_video_demo 源码分析
main_for_video_demo 核心代码如下:
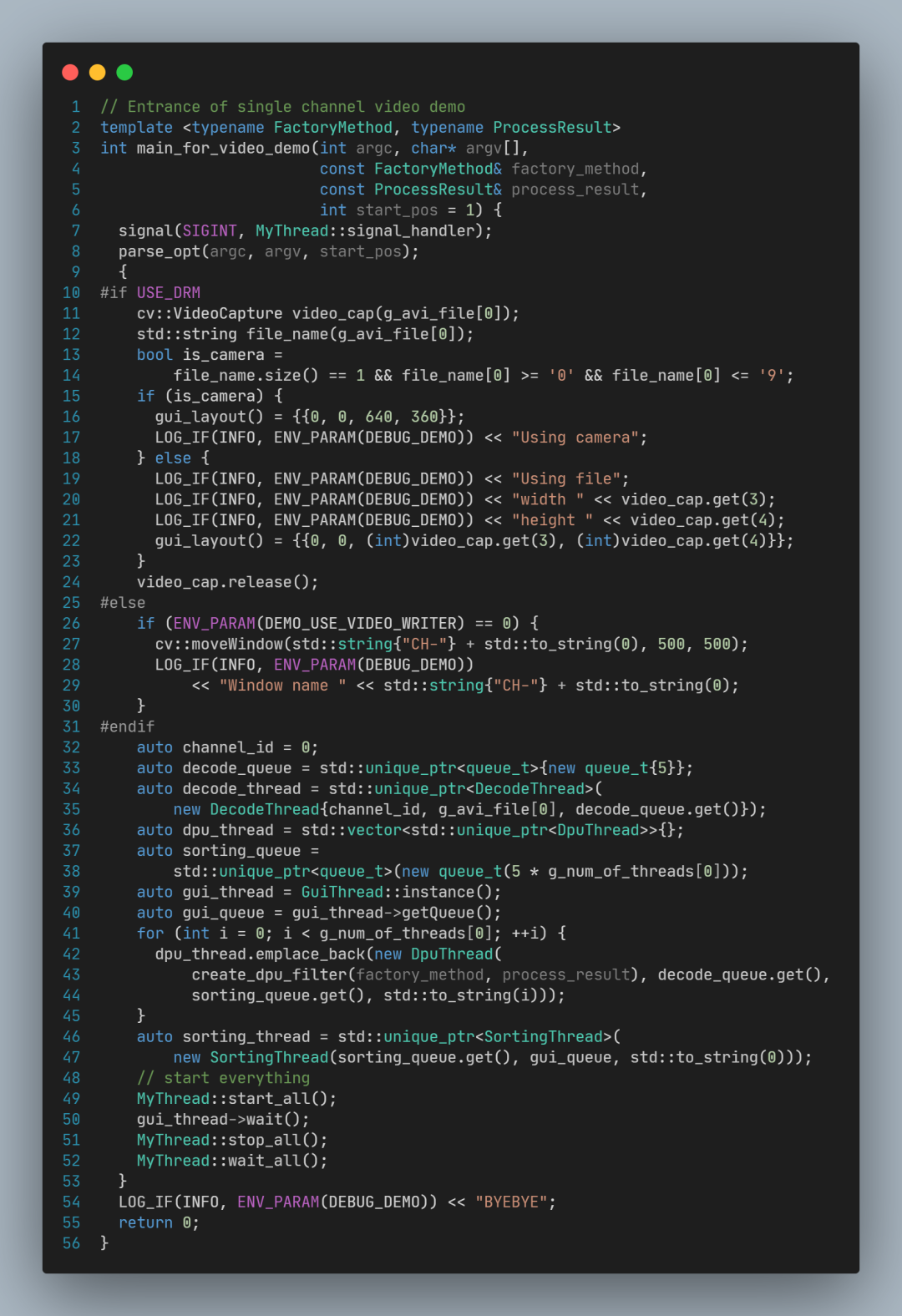
其中,关键代码行如下:
parse_opt 用于解析命令行参数,包括线程数(例如-t 4指定4个线程)和视频文件名
decode_queue 是解码队列,用于传递已经解码的图像;
decode_thread 是解码任务线程,读取视频文件,并解码每一帧画面,放入解码队列;
dpu_thread 是DPU任务线程,从解码队列取出图像,如果-t 参数指定的大于1,会创建多个DPU线程(不指定-t参数,默认为1个DPU线程);
gui_thread 是图形用户界面(GUI)线程,调用cv::imshow显示每一帧结果画面;
gui_queue 是结果图像队列,GUI线程会从这个队列取出图像再显示出来;
sorting_thread 是排序线程,用于确保传递给gui_queue的图像和视频中出现的顺序一致,从而保证视频显示的画面正常。
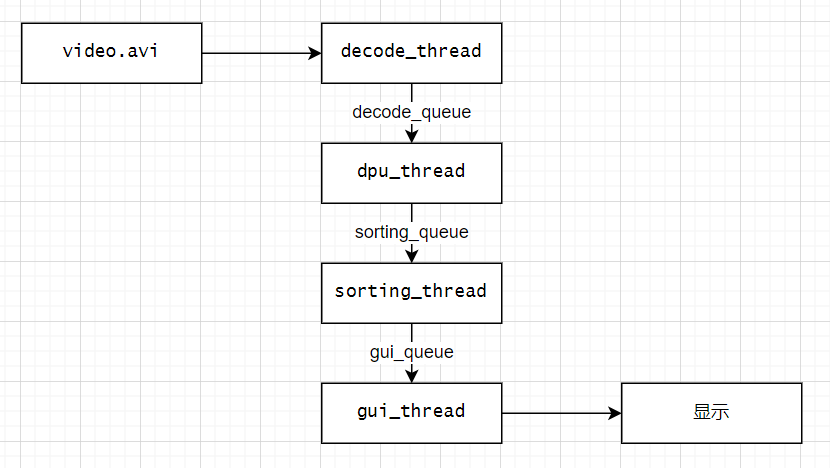
这段代码搭建了一个多线程的视频处理流水线,流水线结构如下图所示:
3.2 DecodeThread 源码分析
DecodeThread的构造函数:
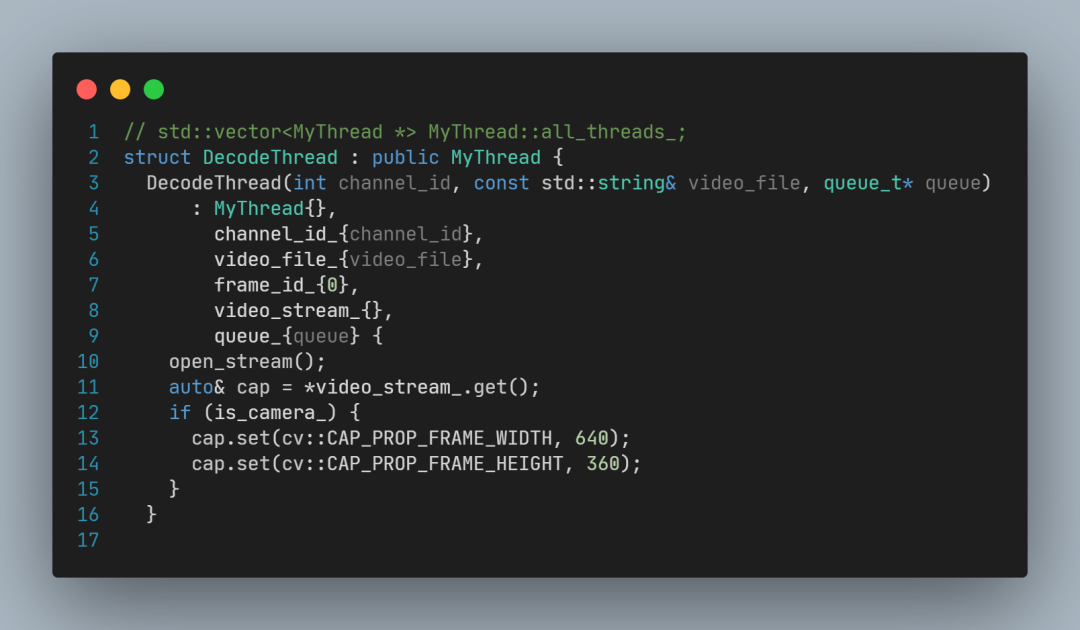
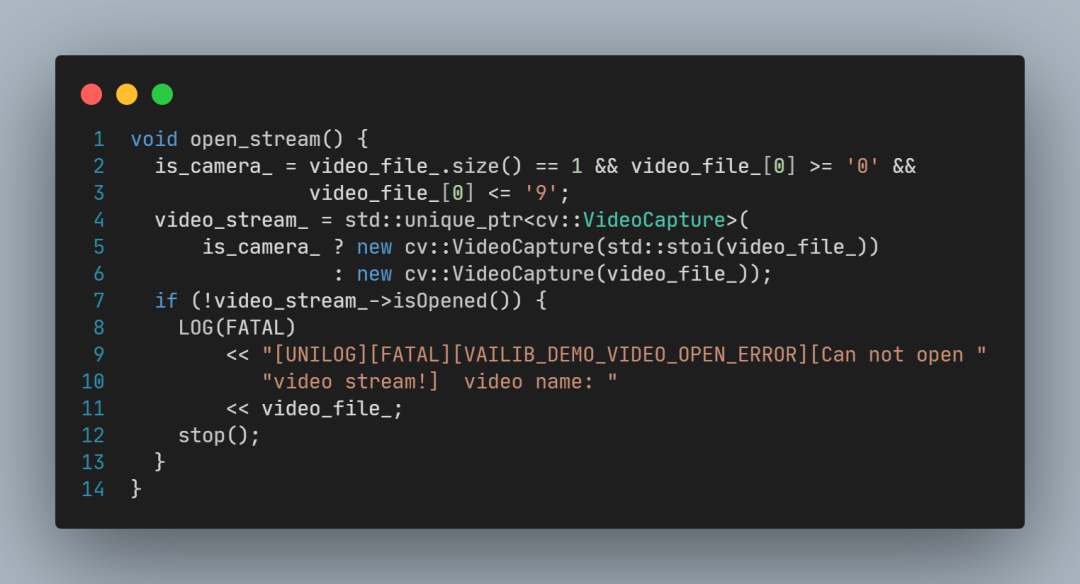
构造函数中调用open_stream,open_stream创建了OpenCV的VideoCapture对象指针,用于后续视频文件读取操作。
DecodeThread::run函数:
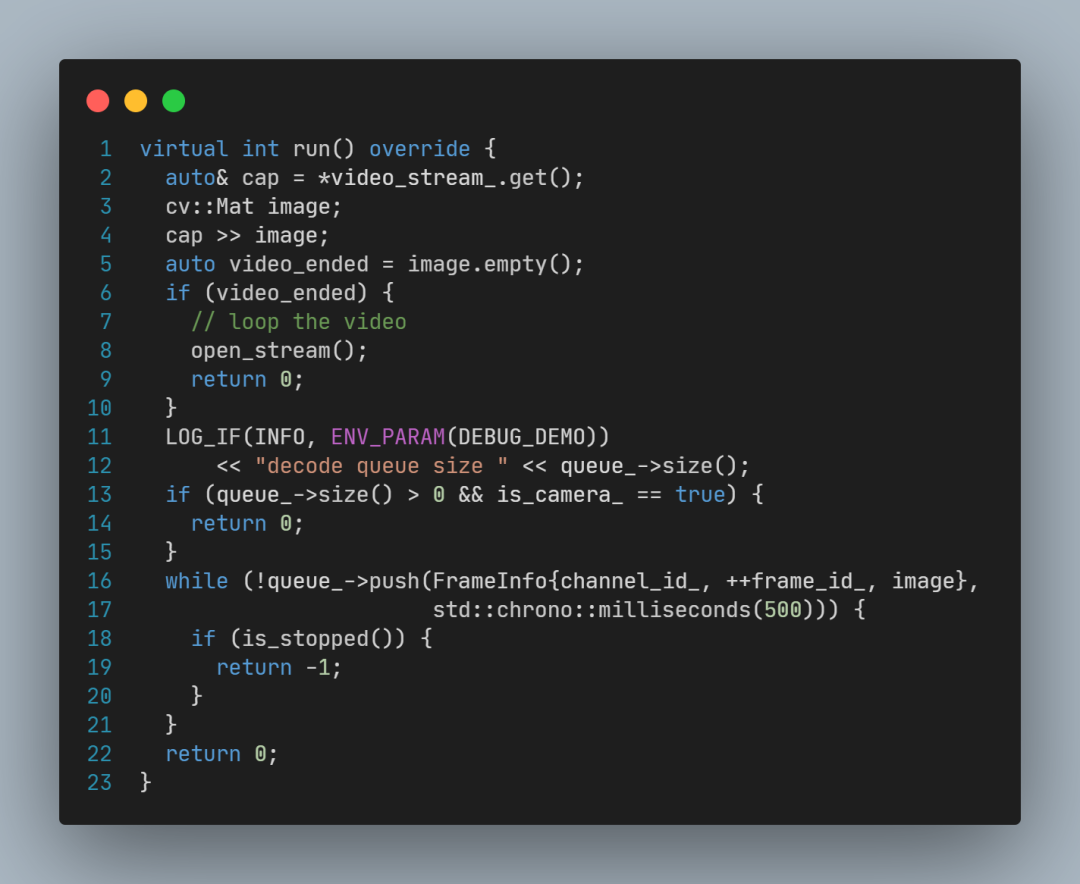
DecodeThread::run函数的关键代码为:
cap >> image 实现了从视频读取画面,
queue_->push(…) 实现了给帧画面编号,并将其放入队列。
3.3 SortingThread 源码分析
SortingThread::run函数关键代码如下:
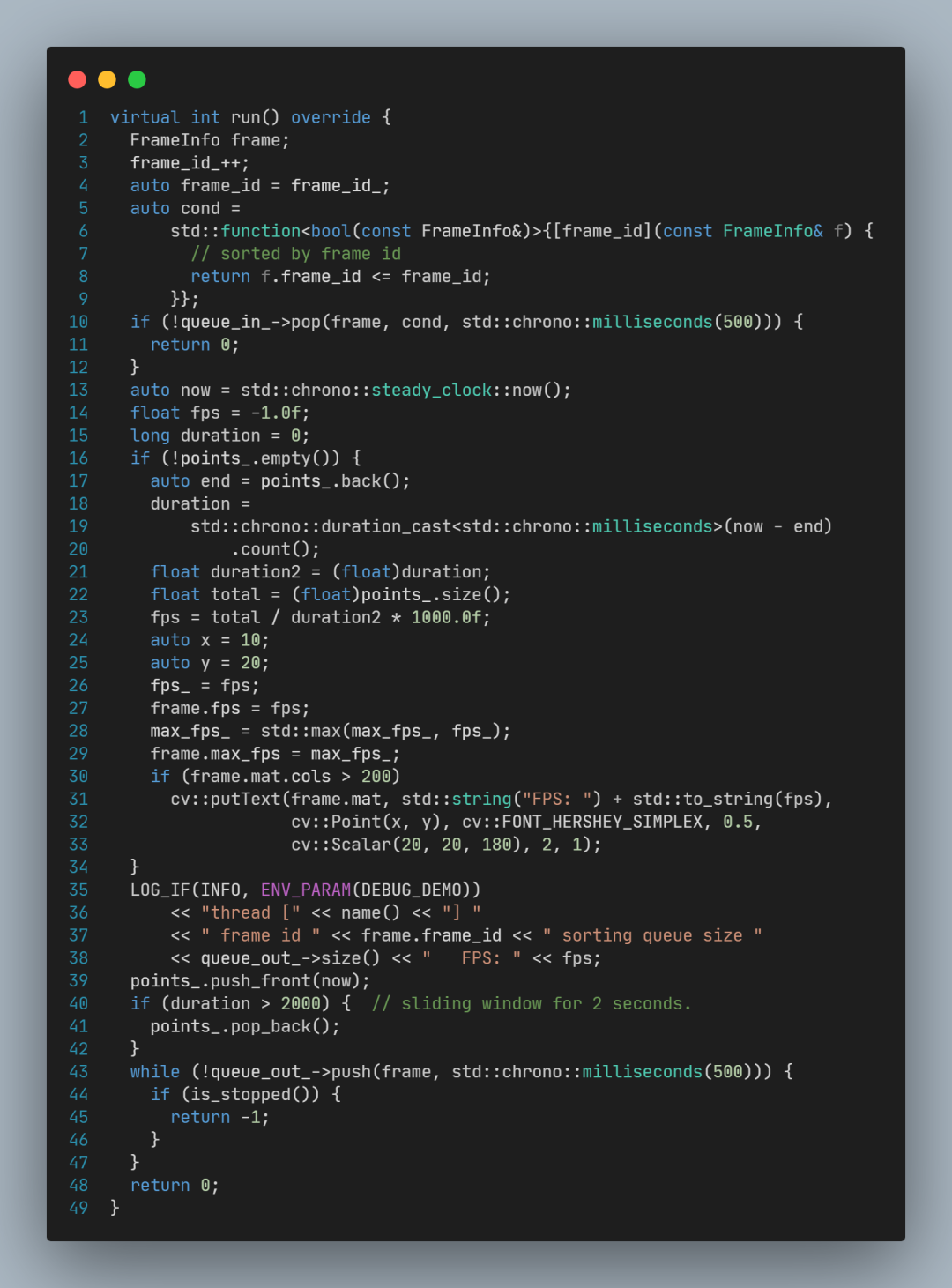
SortingThread::run中的关键代码为:
queue_in_->pop(…) 等待特定frame_id的图像到来;
queue_out_->push(…) 再将其放入输出队列(gui_queue)。
3.4 GuiThread 源码分析
GuiThread::run函数源码:
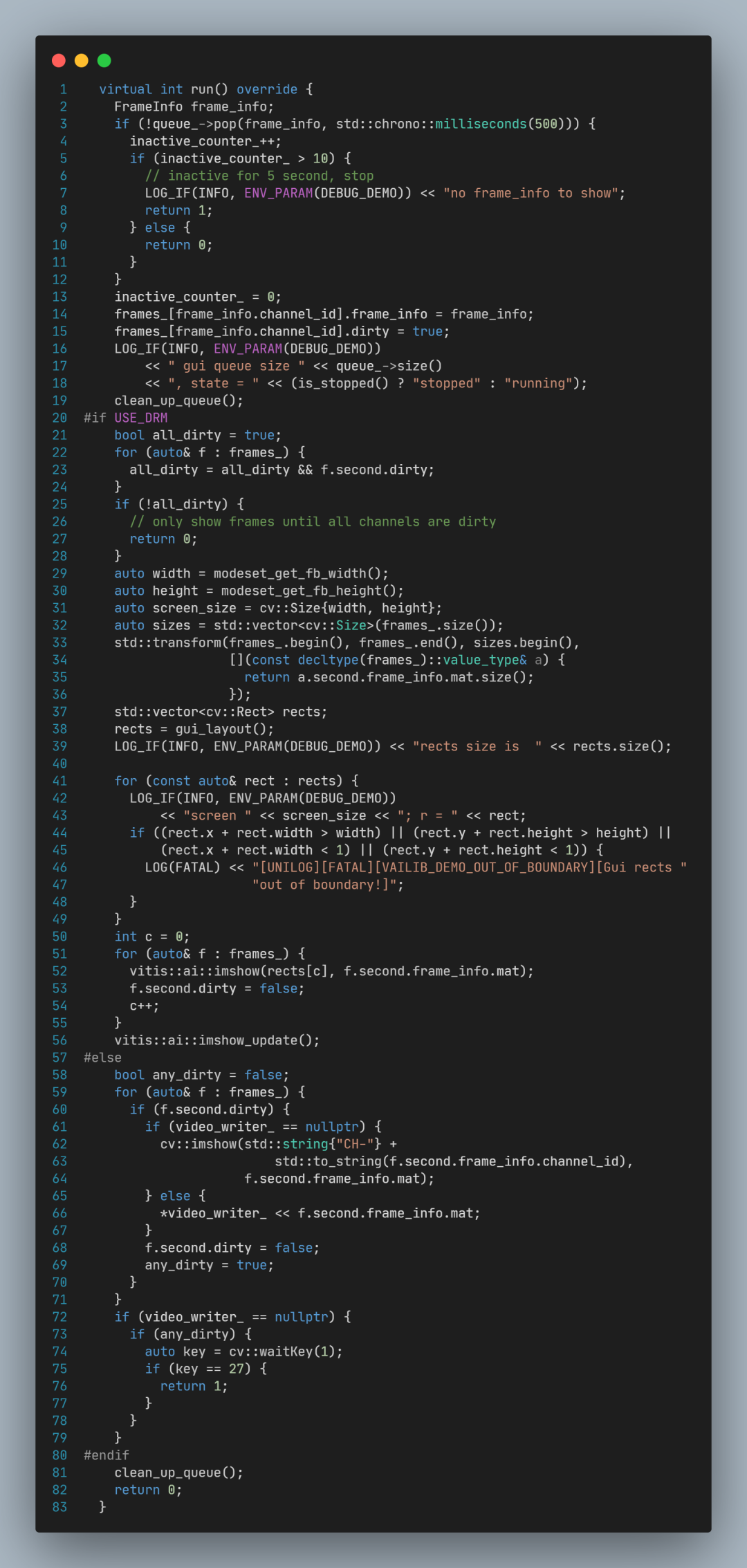
其中关键的代码为:
调用queue_->pop()从队列取出一帧画面;
调用cv::imshow显示图像画面。
3.5 DpuThread 源码解析
DpuThread::run函数源码:
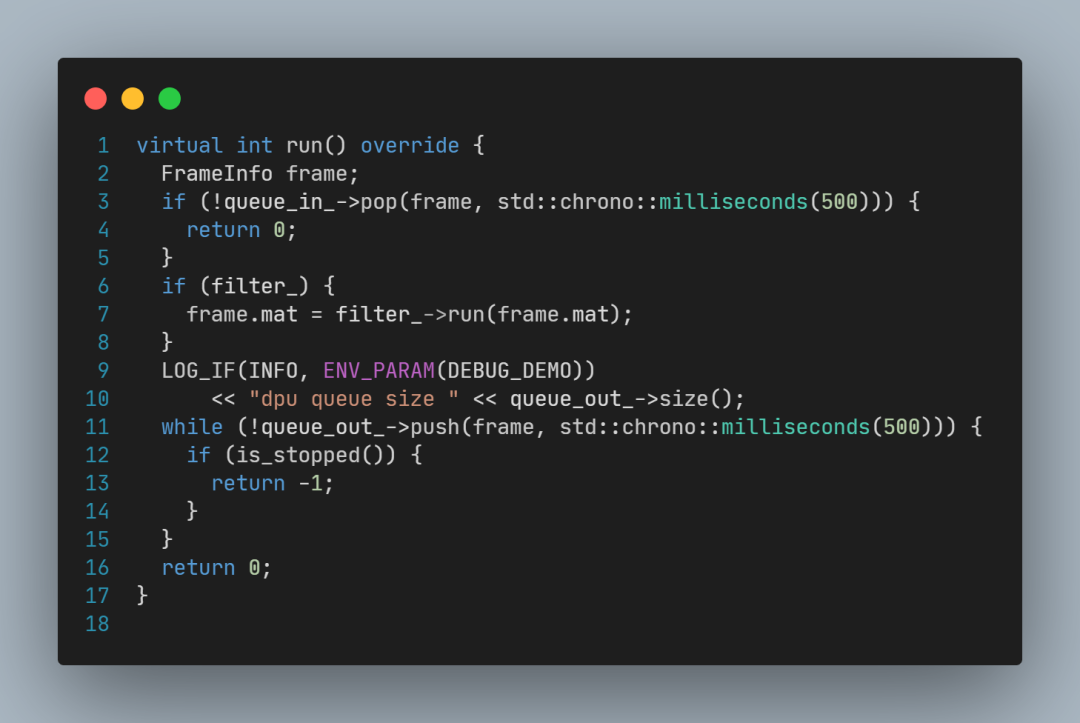
其中关键代码为:
调用queue_in_->pop(frame)取出画面;
调用filter_->run(frame.mat)处理画面;
调用queue_out_->push(frame)传出画面;
要解读filter到底是什么,还需要看DpuThread构造函数的声明:
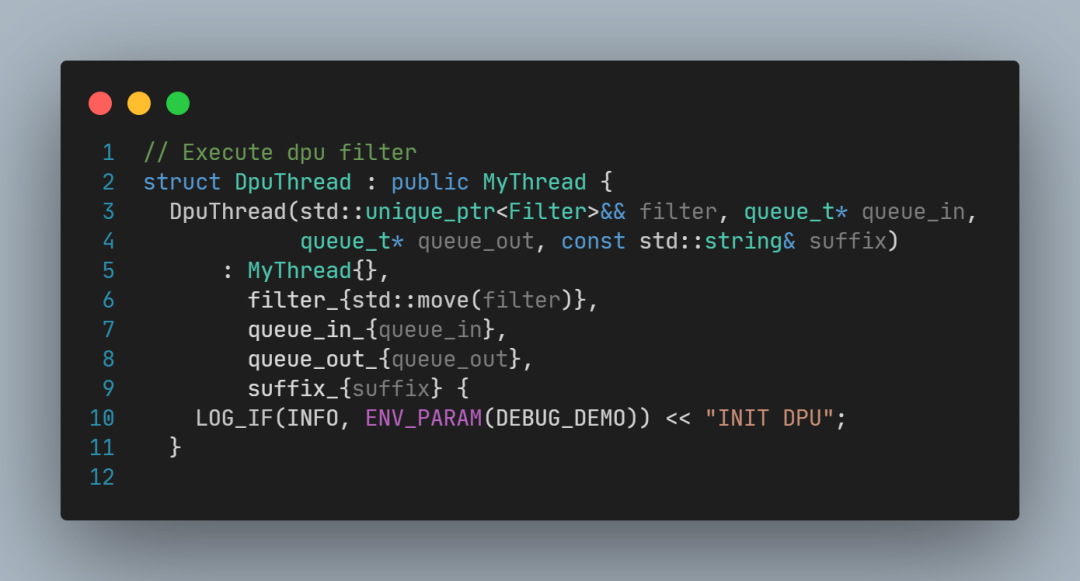
以及DpuThread类型实例化的代码:
以及main函数:
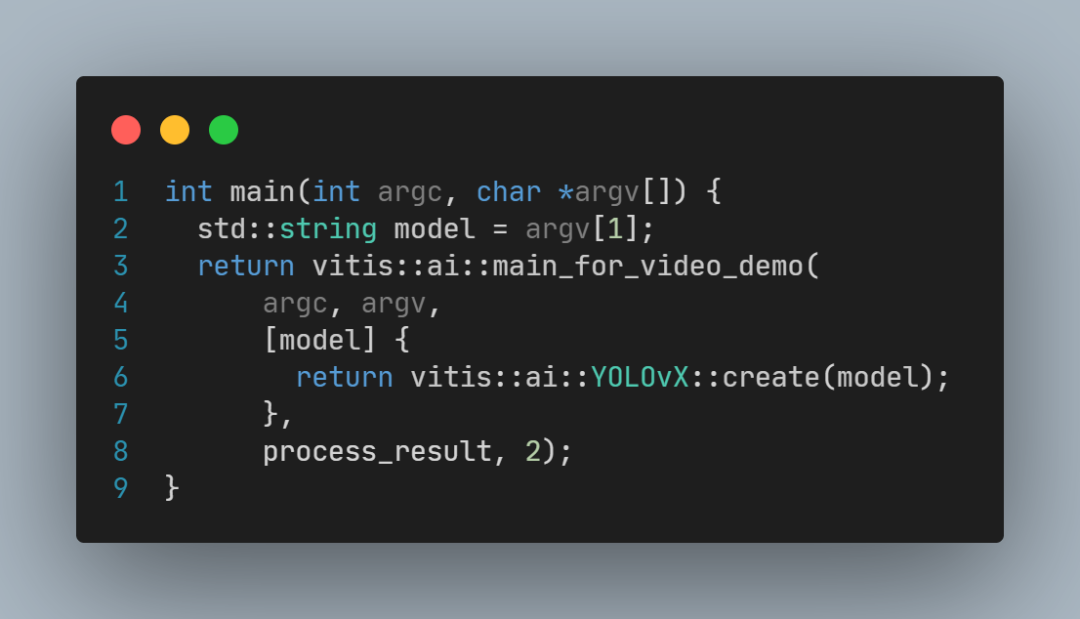
这里可以看到:
factory_method是一个C++11的lamba表达式,
其中调用了vitis::create(model);
vitis::create的具体实现代码较多,感兴趣的可以自行查阅Vitis-AI源码,它主要实现了模型加载,以及调用Vitis-AI-Runtime接口执行推理,这里不再解读。
process_result函数定义:
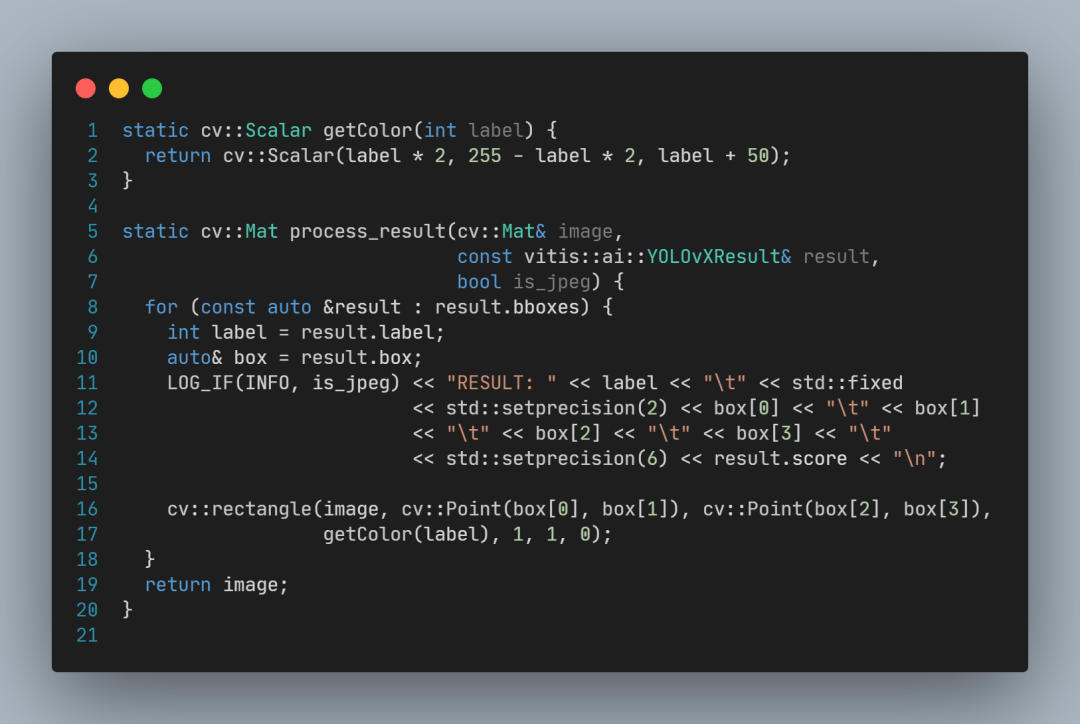
可以看到,process_result的作用主要是画出方框,以及打印日志。
审核编辑:汤梓红
-
基于紫光同创FPGA的多路视频采集与AI轻量化加速的实时目标检测系统2023-11-02 1344
-
【KV260视觉入门套件试用体验】Vitis AI 构建开发环境,并使用inspector检查模型2023-10-14 12115
-
【KV260视觉入门套件试用体验】Vitis-AI加速的YOLOX视频目标检测示例体验和原理解析2023-10-06 12513
-
【KV260视觉入门套件试用体验】基于Vitis AI的ADAS目标识别2023-09-27 11246
-
【KV260视觉入门套件试用体验】五、VITis AI (人脸检测和人体检测)2023-09-26 9727
-
【KV260视觉入门套件试用体验】部署DPU镜像并运行Vitis AI图像分类示例程序2023-09-10 3831
-
【KV260视觉入门套件试用体验】部署vitis-ai环境以及测试demo2023-08-27 947
-
使用Vitis-AI进行车牌识别2023-06-27 910
-
Xilinx KV260 Vitis-AI 1.4人脸检测2023-06-14 1184
-
基于YOLOX目标检测算法的改进2023-03-06 1599
-
在ultrascale+上利用VCU和DPU实现的智能零售系统2023-02-20 1356
-
YOLOX目标检测模型的推理部署2022-04-16 5491
全部0条评论

快来发表一下你的评论吧 !
