

23张图带你弄懂HTTP协议!
通信网络
描述
HTTP初探
1. HTTP版本
自 HTTP 协议发明到现在,经过了几次版本修改,分别是HTTP/0.9,HTTP/1.0,HTTP/1.1以及HTTP/2。现在市面上主要还是 HTTP/1.1,我们本文也主要介绍的是该版本。
2. TCP/IP协议
在学习 HTTP 协议之前我们先来了解下 TCP/IP 协议。它是 HTTP 的基础,地基打稳了房子才能结实!
大家在工作过程中可能经常听到 OSI 七层网络结构以及 TCP/IP 四层网络结构等,但是这些都是什么呢?你平时工作中是否被搞晕过呢?
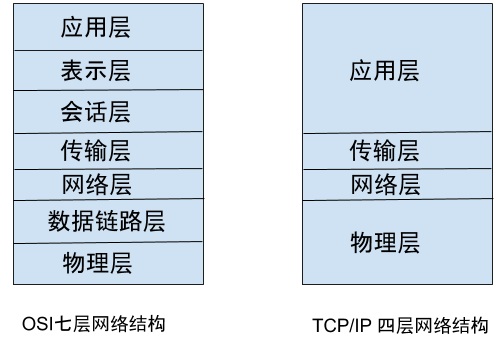
左边的是大名鼎鼎的国际标准化组织 ISO 指定的网络结构模型。但是实际上大家使用的都是右边的 TCP/IP 四层网络结构。
ISO指定网络标准的时候,TCP/IP已经成为了事实上的标准,所以造成了一种奇葩现象。国际协会指定了标准,但是大家都不用~~
下面我们简单的聊一下 TCP/IP 四层结构中每一层的作用。
应用层: 这一层就是上层应用使用的协议。比如HTTP协议,FTP协议,SMTP协议等。
传输层: 从物理层到传输层这三层都是负责建立网络连接,发送数据。他们并不关心应用层使用什么协议。传输层使用的就是TCP和UDP协议。
网络层: 这一层负责选择路由路径。条条大路通罗马嘛,所以从相同的出发地到相同的目的地 也会有很多种路径,网络层就负责选择一条数据通行的路径。
物理层: 这一层负责数据的发送。这是最底层的网卡负责的。网卡把数据转换成高/低电平,然后通过网线发送出去。
下面我们以一个实际的例子来说明这个过程:
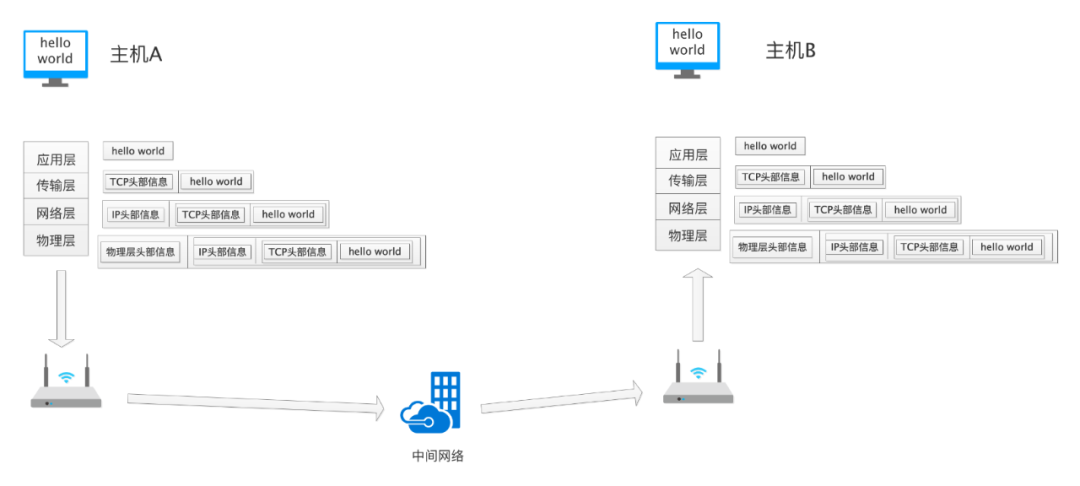
上图是 主机A 向 主机B 发送 hello world 的过程。用户发出一个请求之后,从应用层开始,一直到物理层,每一层都会被加上盖层所属的附加信息;在接收端,每经过一层都会去掉该层的附加信息,然后交给上层处理。
是不是很像洋葱,一层又一层……
应用层把待发送的信息 hello world 使用自己的协议进行封装,然后调用传输层的接口,以此类推,最终数据传递给了物理层。每一层都会加上自己特有的一些标志信息。物理层最后把要发送的数据(包含应用层真正想发送的hello world 以及每个层自己增加的标识信息)转换为高低电平发送出去,接收端收到之后进行一个逆向的解析过程,最后主机B收到了 hello world。
上面是一个简单的描述,但是整体的原理就是这样的~ 大家不要被每一层的概念所迷惑。这些层是人为划分出来的概念。就是为了写代码实现的时候比较方便。只需要定义每个层的接口,上一层调用下一层的接口就行了,不必关心具体实现。这也是软件设计中的一种理念。
3. HTTP协议
上面简单的说了一下网络的结构,这些东西是 HTTP 运行的基础。 下面我们聊一下本文的重点:HTTP 协议相关的内容。
3.1 HTTP协议总览
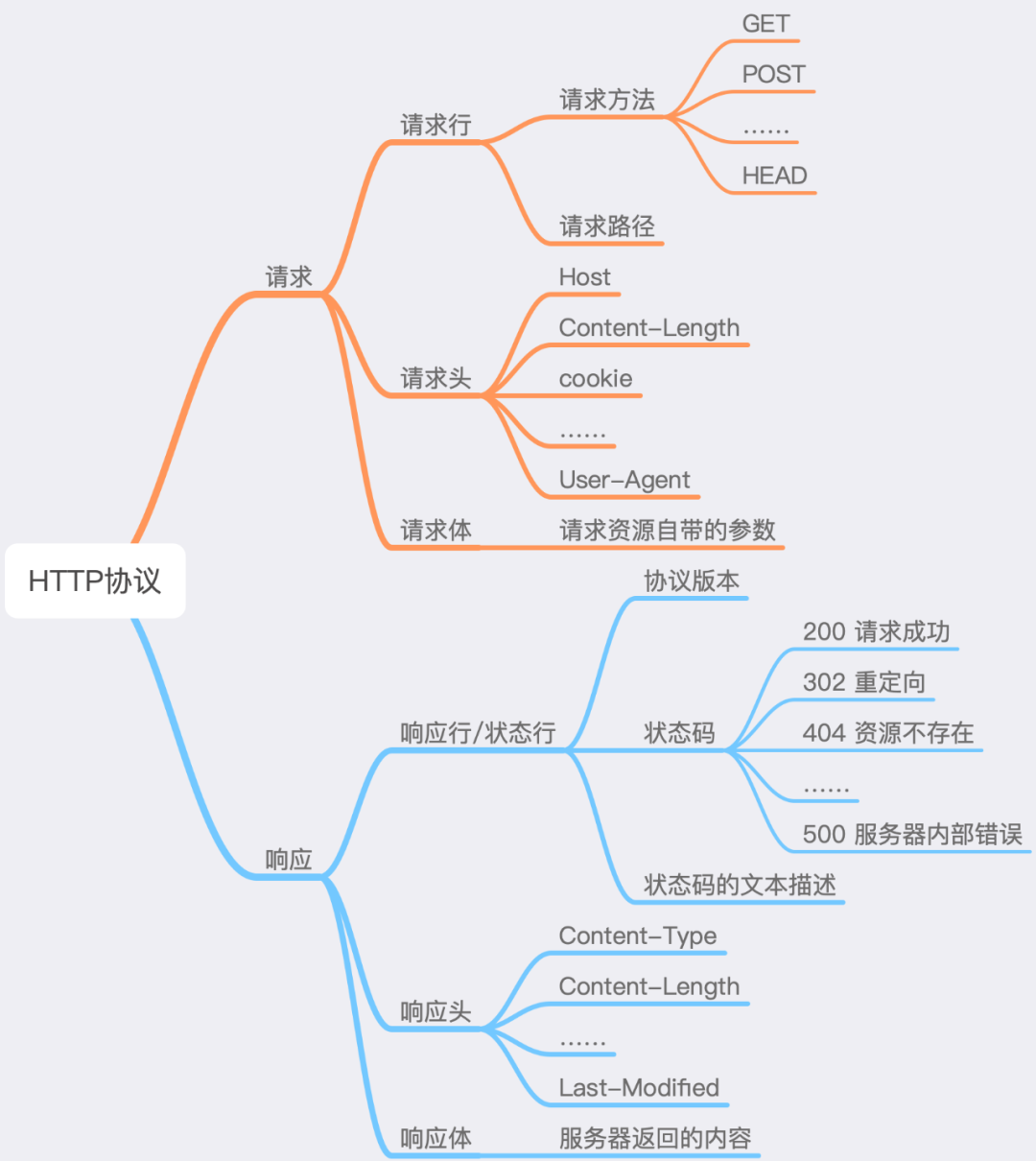
我们先看一下 HTTP 协议的总览图,如下:
3.2 HTTP协议结构

图中可以看到,HTTP协议分为三个部分,其中报文头部和报文主体之间使用空行进行分隔。
HTTP 是一个 Request-Response 的协议。

客户端发出 HTTP 请求( request );
服务器接收请求,处理请求,然后返回响应结果( response );
客户端接收响应结果,进行其它处理。
下面我们针对HTTP的请求和响应分别学习他们的报文结构。
3.3 HTTP 请求报文

我们可以看到,HTTP请求报文分为三部分:
请求行
请求头
请求体
3.3.1 请求行
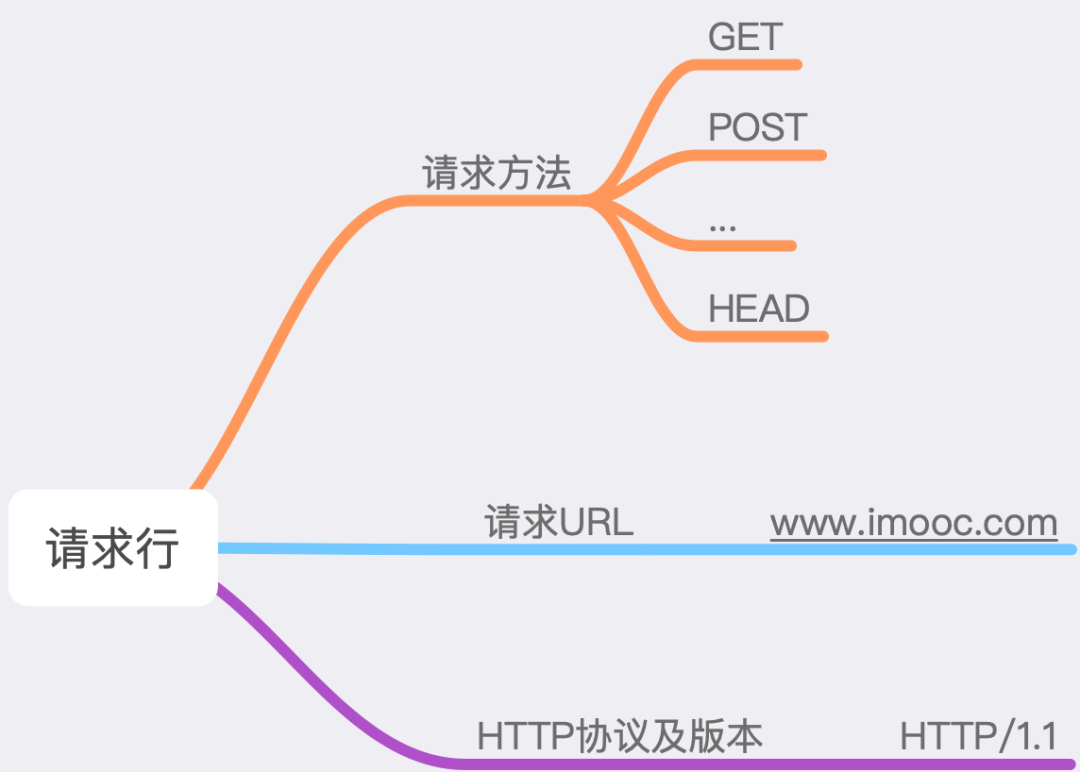
请求行包含了三部分,分别是请求方法,请求的 URL 以及请求体。
3.3.2 请求方法
HTTP/1.1支持多种请求方法 ( method ),如下图:
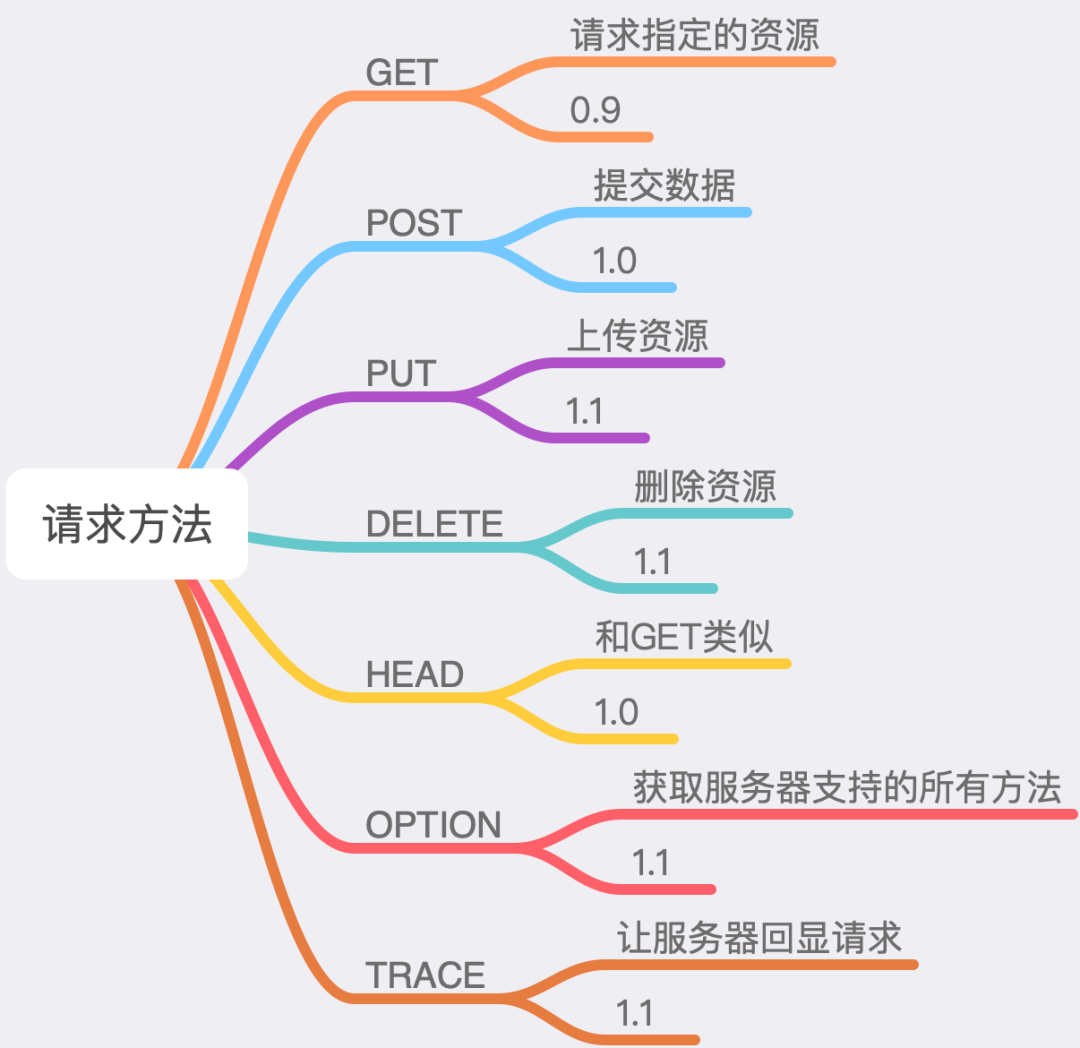
图中的数字表示的是支持该方法的最低 HTTP 协议版本,例如我们从图中可以看到HTTP/0.9只支持GET方法。在工作中我们最常用到的是 GET 和 POST 方法。下面我们简单来聊一下这两种方法的区别。
3.4 GET 方法和 POST 方法
3.4.1 GET : 获取资源
一般来说,GET 请求只用于获取数据。比如我们获取指定页面的信息,并返回响应。
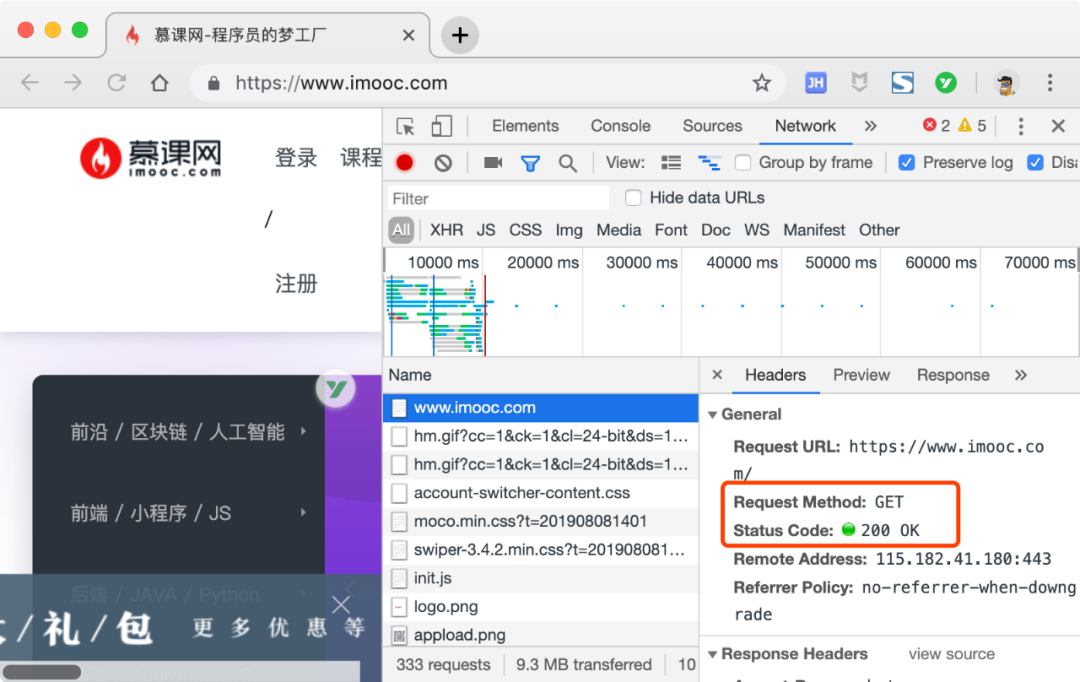
上图是我们访问慕课网的首页,我们可以发现使用的就是GET方法。
3.4.2 POST : 请求资源
POST 请求主要是向指定资源提交数据,服务器接收到这些数据进行处理。比如我们在注册页面中填写了一些个人信息,当我们提交这些信息的时候会向服务器发送一个 POST 请求,将信息放在请求体中,服务器收到之后进行相应的处理。
虽然 HTTP 协议中的请求方法很多,但是在大部分的时候 GET 方法和 POST 方法已经满足我们的需求了,我在工作中最常用的也是这两种方法,别的方法基本没用过……
3.4.3 GET 和 POST 的区别
说了这么多,那么 GET 方法和 POST 方法到底有什么区别呢?这是一个绕不开的话题,而且这个问题在面试的时候也经常会被问到。也许我们被问到这个问题的时候都能扯上一两句,比如:
GET 请求的参数是通过 URL 传递的, POST 请求参数是通过 Request Body 传递的;
GET 允许传递的参数没有 POST 的长度长。
还有很多类似答案,但是事实上是这样的吗?我不得不告诉你一个残酷的事实:GET和POST其实没有任何区别 ~
HTTP 是一个应用层的协议,它底层使用的是 TCP/IP,所以 GET 和 POST 二者的底层是相同的,二者能做的事情是一模一样的。我们一一驳斥上面的几个理由。
如果你愿意, GET 请求也可以有 Request body ,你可以请求参数放到 Request body 中是完全可以的。同样地,你也可以在 POST 请求的 URL 中加入请求参数。本人刚加入微博的时候,发现很多 POST 请求的 URL 中都包含了很多参数,对此深表疑问,后来查了很多资料才发现,原来是自己一直理解错误了,尴尬~
GET 和 POST 参数长度问题。这些长度并不是 HTTP 规定的,而是浏览器和服务器自己的规定,和 HTTP 协议没有一毛钱的关系。
浏览器和服务器为了节省内存,所以都会限制我们参数的大小。在 Nginx 中可以通过large_client_header_buffers来限制请求头的长度~
那说来说去,二者是一样的,那为啥要搞两种方法呢?
来,我们划重点了:有一些客户端,比如 CURL 命令,当 POST 的数据大于 1024 字节的时候,会先分为两个步骤:
向服务器发送一个包含 Expect: 100-continue 请求,询问服务器是否愿意接收数据。
服务器返回 100 continue , curl 把真正的 POST 数据发送给服务器。
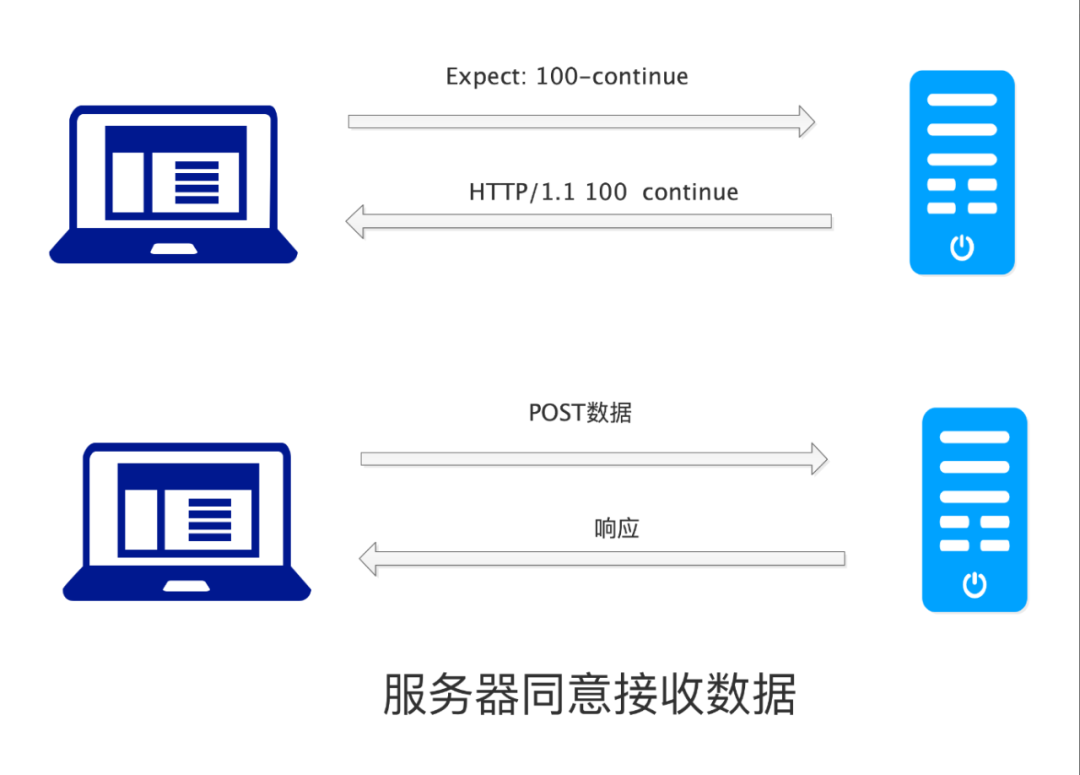
当然了,并不是所有的服务器都会返回 100-continue,有的会返回 417 Expectation Failed,这时候就不能继续 POST 了。

到这里之后,大家是否明白了 GET 和 POST 的区别了呢?
3.5 请求URL
这部分就是我们请求的资源的地址,它配合请求头部的 Host 属性共同工作。
3.6 协议版本
这部分就是当前请求使用的 HTTP 协议的版本信息。上面我们提到过,不同的 HTTP 版本的功能是不相同的,所以我们要明确的说明当前请求使用的是哪个版本。
3.7 请求头
请求头是个什么东西呢?我们不妨以一个例子说明:
放学的时候,王老师对小明说,“小明,明天早上八点,你去学校西门口迎接一位新同学小李,他穿白色T恤,身高180……”
在这里面,接小李就是HTTP的报文,而明天早上八点, 学校西门口,白色T恤,身高180这些附加信息就相当于HTTP 的请求头,这些信息是为了完成工作所添加的额外信息。
HTTP 的请求和响应都包含报文头,报文头分为如下几种:
通用首部字段
请求首部字段
响应首部字段
实体首部字段
每一种类型的头部都有很多不同的选项,我们先介绍前两种报文头,后面在学习响应报文时介绍剩下的两种报文格式。
3.8 通用首部
通用首部既可以用在Request中,也可以用在Response中。常用的有以下几个:
| 首部字段 | 作用 |
|---|---|
| Date | 报文的日期相关 |
| Cache-Control | 控制缓存 |
| Connection | 管理连接 |
我们这里主要看一下 Connection 选项,这个选项是用于管理 HTTP 连接的,格式如下:
Connection: keep-alive
Connection: close
3.9 keep-alive
HTTP 是基于 Resquest-Response 形式的,客户端每次发送完一个请求之后,等待服务器响应,最后和服务器断开连接,本次请求结束。由于 HTTP 是基于 TCP/IP 传输的,当 HTTP 发送请求的时候要和服务器经过三次握手建立连接,断开的时候要经过四次挥手进行断开。如果有大量的 HTTP 请求的话,每次都要进过三次握手和四次挥手,就会非常的耗时。

为了解决这个问题,HTTP引入了 keep-alive 机制。所谓的keep-alive就是客户端和服务器三次握手之后,可以发送多个请求,最后再进行四次挥手。
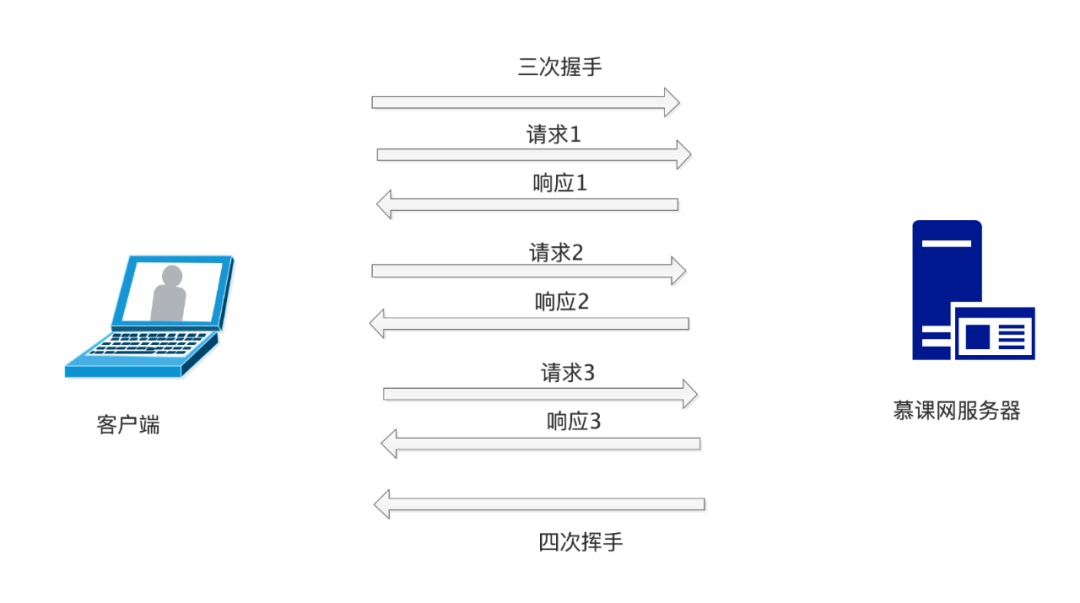
这样我们就可以节省很多次握手和挥手的步骤,提升了服务器的性能。
HTTP 头部中的 connection 就是完成这个功能的,当我们设置 Connection: keep-alive 的时候,就会保持该链接,直到某个请求的 Connection: close 为止。这样可以在很大程度上提高 HTTP 的性能。
3.10 请求首部字段
请求首部字段是发送 HTTP 请求时使用的首部字段,用于补充请求的额外信息,便于服务器理解请求的内容。请求首部字段有很多内容,我们学习几个常用的字段:
| 字段名 | 作用 |
|---|---|
| Host | 请求资源所在的服务器 |
| If-Match | 标志位,用于判断资源是否符合要求 |
| If-Modified-Since | 当资源比该字段内容更新时,发送资源 |
| If-Unmodified-Since | 和If-Modified-Since作用相反 |
| Referer | 当前请求来源方的地址 |
| User-Agent | 客户端的类型,比如Chrome浏览器,IE浏览器, CURL程序等 |
| Cookie | 发送请求时给服务端的一些信息 |
3.10.1 Host字段
这个字段说明了当前请求的服务器的域名。比如我们访问慕课网首页的时候,我们可以看到浏览器发送的请求中,Host字段就被设置为了 www.imooc.com。
Host: www.imooc.com
3.10.2 If系列
我们这里列出来了三种 If 系列首部字段。HTTP 协议还有其它几种 If 字段,大体功能都类似。从名字中我们可以看出来,这些首部都带有判断性质,如果满足了某种条件才会做什么。这三个选项都是为了让 HTTP 更高效,节省网络带宽。
当服务器发送一个响应的时候,可能会带有一个 ETag 标志,客户端在第二次获取该资源的时候,可以带上 If-Match 字段,它的值就是服务器返回的 ETag,当服务器发现对应的资源发生改变的时候,会将新资源返回,并生成新的 ETag 返回给客户端。如果资源未发生改变,那么服务端会返回 304 Not Modified,这样就节省了带宽。
If-Modified-Since和 If-Unmodified-Since 也是类似的作用,只不过它们比较的是返回内容的时间戳。
3.10.3 Referer字段
这个字段是为了说明当前是从哪里来的。比如我们从慕课网首页跳转到免费课程的时候,就可以发现请求的 Referer 如下:
Referer: https://www.imooc.com/
说明我们是从慕课网的首页跳转而来的,这个字段对于图片防盗链非常有效。
3.10.4 Cookie
Cookie 相关的问题会经常在面试中被问到,那么什么是 Cookie 呢?在说明这个东西之前,我们先来了解一个概念:HTTP 协议是一个无状态的协议,啥叫无状态协议呢?来看下图:
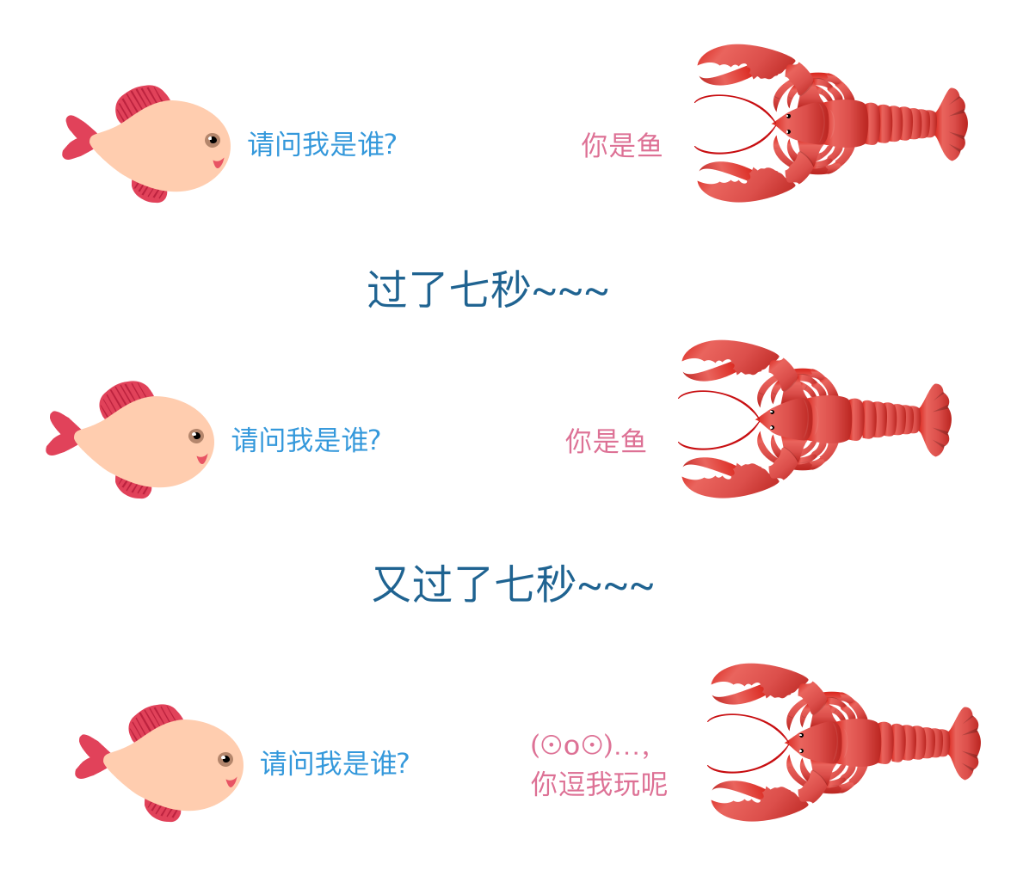
传说,鱼只有七秒的记忆,所以它可以每天非常欢乐的在水里游啊游,游啊游~
如果把鱼比作 HTTP 协议的话,那么它应该是世界上最快乐的协议了,因为 HTTP 连一点记忆都没有~~ 。HTTP 的无状态指的是它不会保存任何状态信息,每个请求都是独立的,和其它请求没有任何关系。
比如,我们在第一个页面登陆了慕课网,当我们打开第二个慕课网页面的时候,HTTP并不会记住我们已经登录了慕课网。
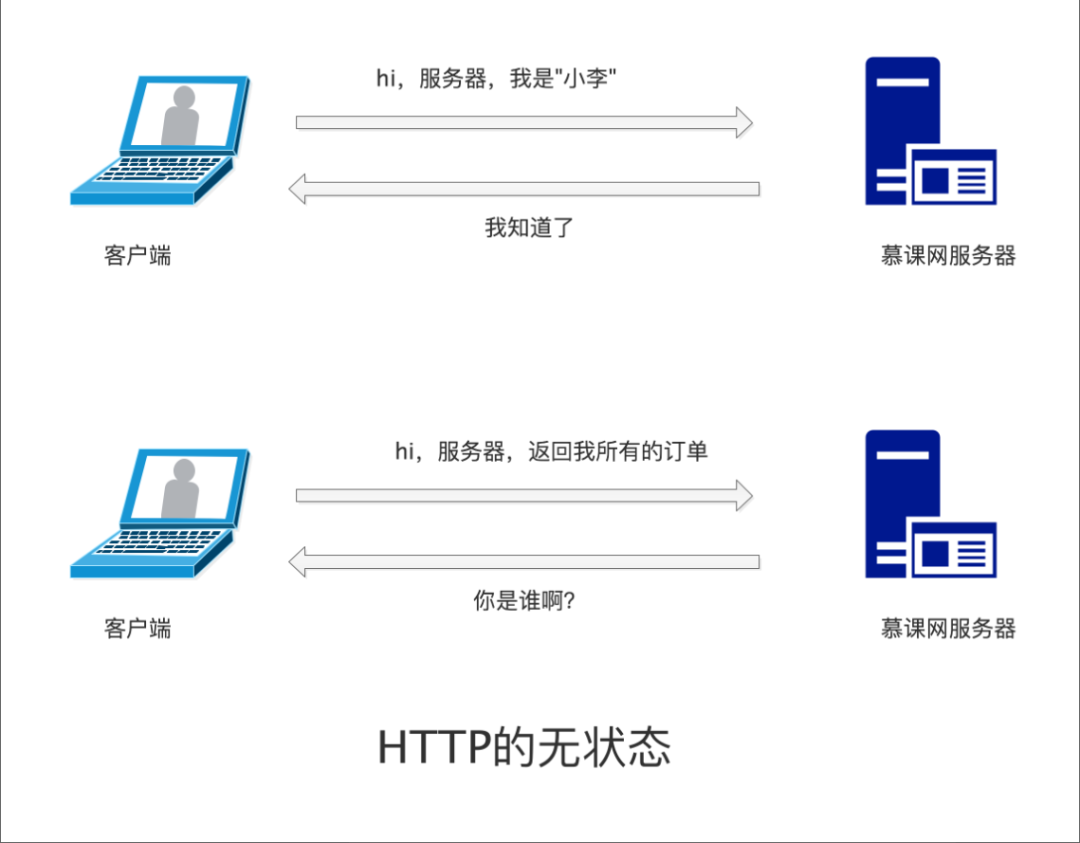
为了解决这个问题,HTTP 引入了 cookie 和 session 机制。每次发出 HTTP 请求的时候,都会把 cookie 带上,那么第二次请求通过状态信息就可以知道当前用户是谁了。
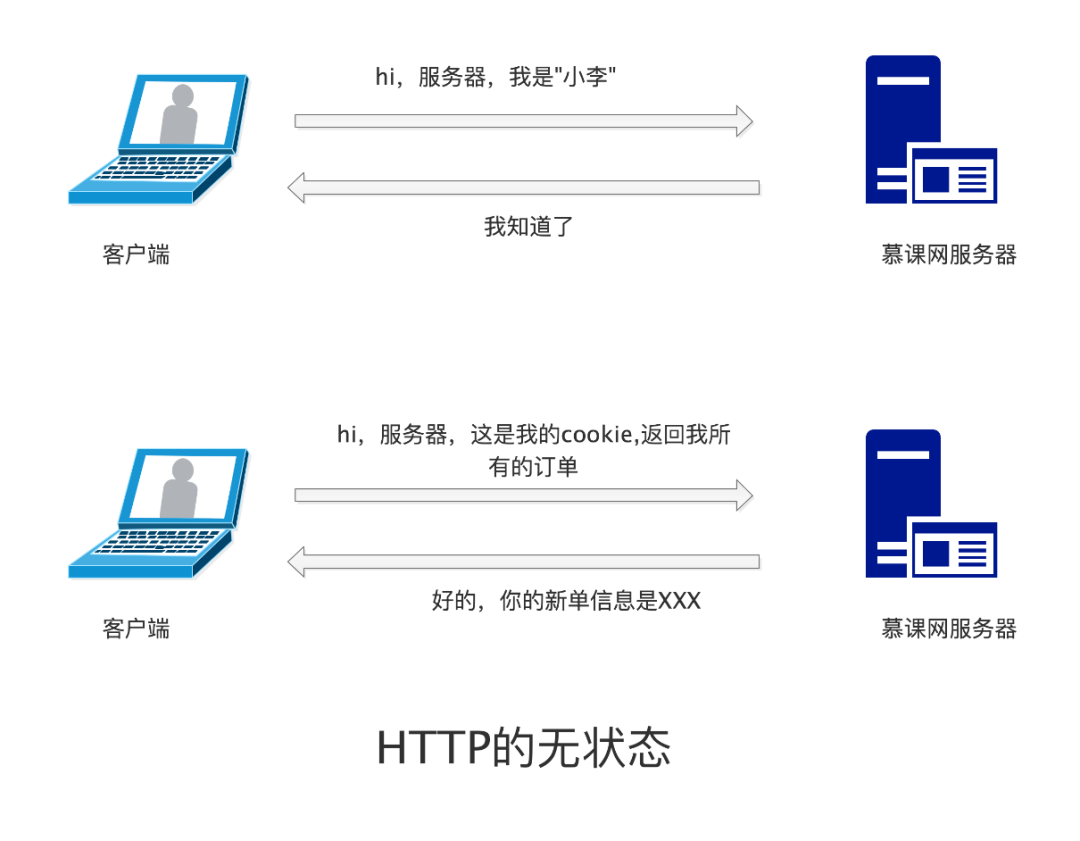
但是由于cookie是保存在客户端的信息,所以很容易被篡改,因此 HTTP 引入了 session 机制。session 是保存在服务端的信息,起到的作用和 cookie 类似,都是用于保存一些状态信息。
到这里之后,我们再把 Cookie 的概念告诉你,是不是很容易理解了呢?
An HTTP cookie (web cookie, browser cookie) is a small piece of data that a server sends to the user’s web browser. The browser may store it and send it back with the next request to the same server. Typically, it’s used to tell if two requests came from the same browser — keeping a user logged-in, for example. It remembers stateful information for the stateless HTTP protocol.
—以上是来自 MDN 对于 Cookie 的解释
在这里我用我那撇脚的英语水平给大家翻译一下:
Cookie 是服务端发送给客户端的一段数据。客户端可以保存该数据,并在后续请求中带上该数据。通常来说,Cookie 用于用户登录等操作。Cookie 使得无状态的 HTTP 变得有状态了。
3.10.5 请求体
这里面就是我们真正要做的事情了,这里面的内容就是每个请求自定义的~~。比如我们在注册的时候,通常在点击注册按钮时,会发送一个POST请求,请求体里面就包含了我们填写的姓名、密码、邮箱等个人信息。
3.11 HTTP 响应报文

可以看到,响应报文同样分为三部分:
状态行
响应头
相应内容
3.11.2 状态行
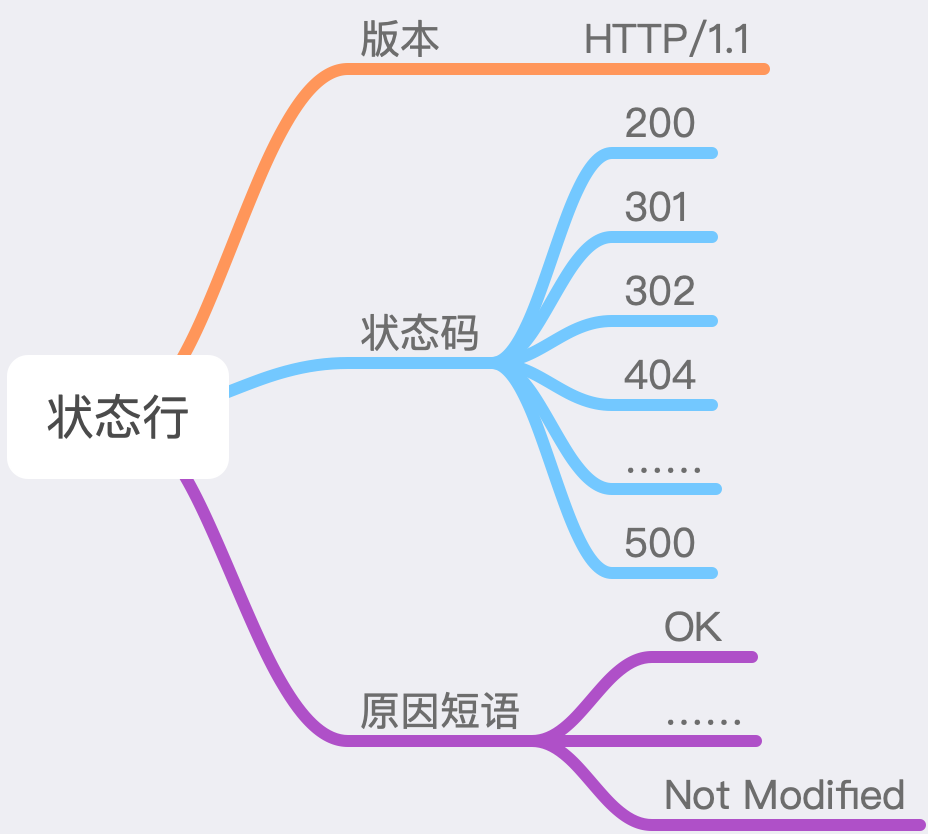
状态行分为三部分,分别是HTTP版本,状态码以及原因短语。
3.11.3 HTTP版本
当前使用的 HTTP 版本号,比如 HTTP/1.1
3.11.4 状态码和原因短语

状态码是一个数字,是为计算机设计的,而原因短语是当前状态码的一种可读文本,是为人设计的。HTTP协议中的状态码分为五大部分,大概60多种,下面我们列举几个会经常用到的:
200 : 这个是我们经常遇到的,表示当前的请求成功了;
301 : 表示当前请求的资源已经被永久的移动了了另外一个位置,响应的 Location 头部应该包含资源的新地址,客户端应该去另一个地址获取这个资源;
302 :表示当前请求的资源被临时的移动到了另外一个位置,响应的 Location 头部应该包含资源的新地址;
304 :如果请求头里面包含类似 If-Modified-Since 这样的选项,若服务器发现当前请求的资源不符合 If-Modified-Since 要求,那么就会返回 304 ,表示当前的资源没有发生改变,不用重新请求;
404 :这个应该是大家最熟悉的了,表示当前的资源不存在;
413 :当 POST 的数据太大的时候, Nginx 就会返回这个状态码,响应的原因短语是 Request Entity Too Large ;
500 :这个错误表示当前的服务器发生了错误,比如我们的代码有 bug 等。
3.11.5 响应头
我们在请求头部分说了通用首部字段和请求首部字段,下面我们看一下剩余的两种首部字段。
3.11.6 响应首部字段
响应首部字段是服务器向客户端返回的报文中使用的字段,该字段也有很多,我们讲几个比较常用的。
| 字段名 | 作用 |
|---|---|
| Accept-Ranges | 服务器用来表示自身支持的范围请求 |
| Location | 配合301和302状态码使用,表示资源位置发生了改变 |
| Etag | 资源标识 |
2.3.11.6.1 Accept-Ranges
该字段表示服务器自身是否支持范围请求,它的值用于表示范围请求的单位。
格式:
1) Accept-Ranges: bytes
2) Accept-Ranges: none
none 不支持任何范围请求单位,由于其等同于没有返回此头部,因此很少使用。不过一些浏览器,比如IE9,会依据该头部去禁用或者移除下载管理器的暂停按钮。 bytes 范围请求的单位是 bytes (字节)。
3.11.6.2 Etag
服务器对返回的内容会计算一个数值,比如返回文件的MD5,这个值标识了当前返回的内容。客户端根据这个值配合If-Match请求头使用,可以有效的降低网络带宽。
3.11.7 实体首部字段
实体首部字段可以用于请求报文,也可以用于响应报文,用于表示实体的一些相关特性。
| 字段名 | 作用 |
|---|---|
| Content-Length | 表示实体的大小,单位是字节 |
| Content-Range | 用于范围请求 |
| Content-Type | 实体的类型 |
| Last-Modified | 最后修改时间 |
3.11.7.1 Content-Type
表示实体的类型,这个类型非常非常的多
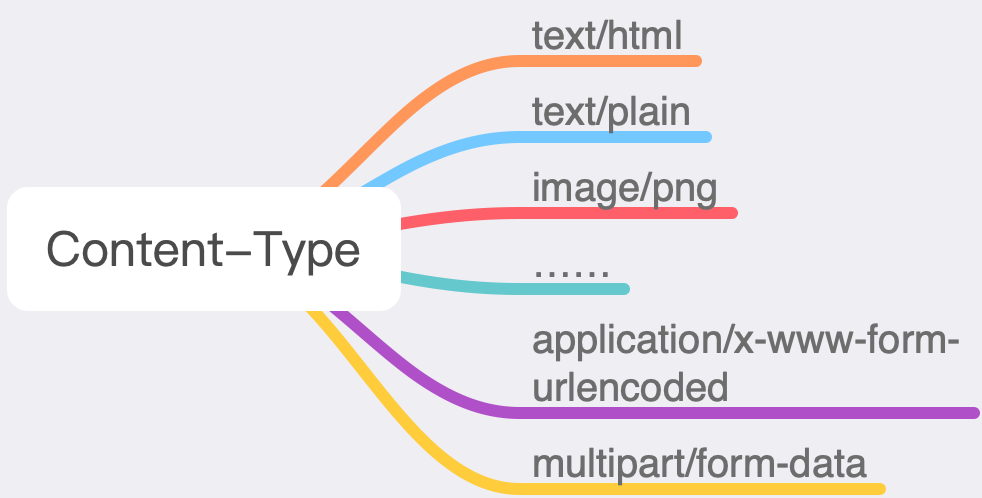
但是我们常用的也就那么几个
application/x-www-form-urlencoded 默认的 GET 和 POST 编码方式,所有的数据都会变成键值对的形式,如 key1=value1&key2=value2 。
multipart/form-data 如果我们上传资源的时候,那么必须使用这种格式。
3.11.7.2 Content-Length
这个字段的值代表的是实体的长度,以字节表示。
3.11.7.3 Content-Range
这个字段是配合 Range 请求使用的,适用于断点续传,下载等功能。比如在下载的时候,可以使用多个进程,分别下载文件的一部分,到最后合并成一个文件,加快下载速度。
这个实体是非常费解的,英文叫做Entity,我的个人理解它就是请求或返回的body数据
3.11.8 响应body
这部分就是响应的主体部分哈~~
编辑:黄飞
-
HTTP 协议的工作原理2024-12-30 2096
-
4张动图带你看懂齐纳二极管工作原理2023-12-05 2592
-
如何理解HTTP协议是无状态的2023-11-11 4351
-
什么是HTTP协议?HTTP协议的基本特点和发展历程2023-08-04 2834
-
33.033 HTTP协议 初识HTTP协议充八万 2023-07-19
-
HAS 2023|一张图带你了解Net5.5G2023-04-14 1393
-
大话HTTP协议前世今生2023-02-07 1508
-
什么是Http协议?2021-12-22 1121
-
HTTP协议的使用方式和设计原理讲解2018-06-28 4628
-
【技能秒get】5张思维导图带你了解碳纤维及其复合材料2018-05-09 9940
-
24张图带你读懂什么是MODBUS技术2017-11-26 26510
-
iOS中HTTP传输协议2017-09-26 1122
-
HTTP,HTTP协议的作用是什么?2010-03-22 25476
全部0条评论

快来发表一下你的评论吧 !
