

Boltons:超过230个的纯Python实用工具库
描述
经过了几十年的发展,Python 的轮子生态越来越丰富,例如针对网络请求有 requests,针对命令行开发有 typer 等等,这些第三方库给我们的日常开发带来了极大的便利。
今天给兄弟们推荐另一个第三方库 -- Boltons,和大多数第三方库不太一样,它并不是针对某一功能的工具库,而是将开发中那些重复性(经常使用)及复杂度较高(不容易编写)较高的代码剥离出来,并按照操作对象分门别类整合在一起的工具库。
Boltons 使用的是 BSD 许可证,到目前为止已经收录 超过230个 的纯 Python实用工具库,这些工具库与 Python 标准库并没有重合,是补充的关系,包括:
- cacheutils 工具集:用于管理缓存,提供 LRU 和 LRI 等缓存方式
- debugutils 工具库:用于调试实用程序
- dictutils 工具库:映射类型(OMD)
- ecoutils 工具库:生态系统分析
- fileutils工具库:文件系统帮助器,提供原子文件保存等功能
- formatutils 工具库:str.format() 工具箱
- funcutils 工具库:functools 修正
- gcutils 工具库:垃圾收集工具
- ioutils 工具库:增强输入/输出功能
- iterutils 工具库:itertools 改进
- jsonutils 工具库:JSON交互
- listutils 工具库:list 衍生物
- mathutils 工具库:提供数学函数的支持
- mboxutils 工具库:Unix邮箱实用程序
- namedutils 工具库:提供两种轻量级容器类型
- pathutils 工具库:提供处理文件路径的函数
- queueutils 工具库:优先级队列,目前提供基于堆及基于排序列表两种队列实现
- setutils 工具库:IndexedSet 类型
- socketutils 工具库:socket 包装纸
- statsutils 工具库:统计基本面
- strutils 工具库:文本操作,涉及到方方面面,有非常多的工具函数
- tableutils 工具库:2D数据结构
- tbutils 工具库:回溯跟踪和调用堆栈,丰富的Tracebackinfo类实现了栈追踪
- timeutils 工具库:增加 datetime 对象处理能力
- typeutils 工具库:类型处理
- urlutils 工具库:结构化URL,方便对 URL 进行处理
# 1. 如何安装
安装只需要一条命令
pip install boltons
# 2. 实用范例
Boltons 的工具库函数非常多,不能一一举例,本文只摘取一些明哥认为经典的工具做为演示
遍历日期
在 timeutils 工具库中有一个 daterange 可以对日期进行遍历,省去自己手动构造日期
>> > from datetime import date
>> > from boltons.timeutils import daterange
>> >
>> > christmas = date(year=2022, month=12, day=25)
>> > new_year = date(year=2023, month=1, day=1)
>> > for day in daterange(christmas, new_year):
... print(repr(day))
...
datetime.date(2022, 12, 25)
datetime.date(2022, 12, 26)
datetime.date(2022, 12, 27)
datetime.date(2022, 12, 28)
datetime.date(2022, 12, 29)
datetime.date(2022, 12, 30)
datetime.date(2022, 12, 31)
当然,你也可以指定遍历的间隔
> > > for day in daterange(date(2017, 5, 1), date(2017, 8, 1),
... step=(0, 1, 0), inclusive=True):
... print(repr(day))
...
datetime.date(2017, 5, 1)
datetime.date(2017, 6, 1)
datetime.date(2017, 7, 1)
datetime.date(2017, 8, 1)
其中参数的意义是:
- step (int):元组 (year, month, day) 。
- inclusive (bool) :是否包含 stop 的日期
范围转具体
在 libvirt 里的 xml 上的 CPU 上通常都是这样表示的
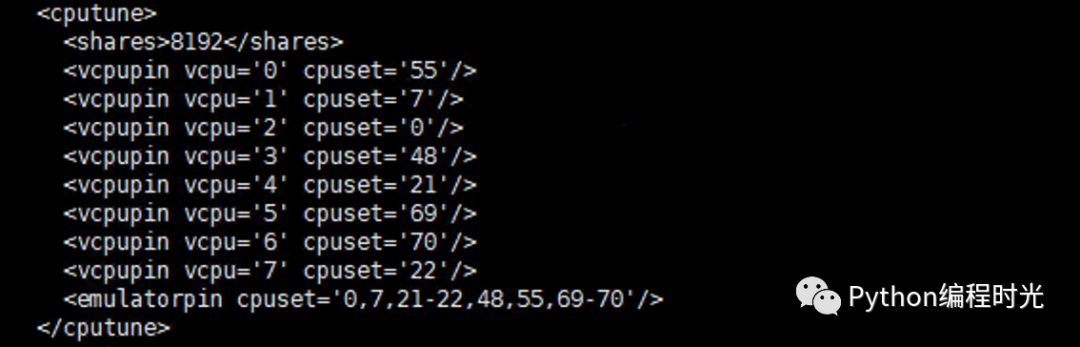
如何将这种格式(emulatorpin 里的 cpuset)的范围,直接转成具体包含了哪些核呢?
使用 boltons 的 strutils 工具包的一个函数立马搞定
> > > from boltons.strutils import parse_int_list
> > >
> > > parse_int_list('0,7,21-22,48,55,69-70')
[0, 7, 21, 22, 48, 55, 69, 70]
递归映射
iterutils 工具包里提供一个 remap 函数,可用于遍历和转换嵌套结构。
如下面这个例子,将删除所有 value = None 的元素
> > > from pprint import pprint
> > >
> > > reviews = {'Star Trek': {'TNG': 10, 'DS9': 8.5, 'ENT': None},
... 'Babylon 5': 6, 'Dr. Who': None}
> > >
> > >
> > > from boltons.iterutils import remap
> > >
> > > pprint(remap(reviews, lambda p, k, v: v is not None))
{'Babylon 5': 6, 'Star Trek': {'DS9': 8.5, 'TNG': 10}}
与 remap 相似的函数还有一个 research,可用于递归匹配查找
假设有如下一个字典
root = {'a': {'b': 1, 'c': (2, 'd', 3)}, 'e': None}
此时我想找出所有 value 为整数的的项,可以这样子实现
> > > from boltons.iterutils import research
> > >
> > > res = research(root, query=lambda p, k, v: isinstance(v, int))
> > > print(sorted(res))
[(('a', 'b'), 1), (('a', 'c', 0), 2), (('a', 'c', 2), 3)]
流式读取多文件
如果你有多个文件需要连接起来处理,可以使用 ioutils 工具包里的 MultiFileReader
> > > from boltons.ioutils import MultiFileReader, BytesIO
> > >
> > > mfr = MultiFileReader(BytesIO(b'ab'), BytesIO(b'cd'), BytesIO(b'e'))
> > > mfr.read(3).decode('ascii')
'abc'
创建多级目录
Linux 上可以使用 mkdir -p 命令来创建多级目录,但若使用 Python 来实现这个功能其实是非常麻烦的,如果不断的判断,一级一级往下去创建
而在 boltons 上的 fileutils 工具包提供的 mkdir_p 函数,可以达到 Linux 上 mkdir -p 丝滑体验
> > > from boltons.fileutils import mkdir_p
> > >
> > > mkdir_p("/home/foo/bar/test")
URL结构处理
一个 URL 由下面结构组成
foo://user:pass@example.com:8042/over/there?name=ferret#nose
_/ _______/ _________/ __/_________/ _________/ __/
| | | | | | |
scheme userinfo host port path query fragment
当我想从 URL 中解析获取部分内容时,就要对该字符串进行正则匹配。
若使用 boltons 中的 urlutils 工具库 中的 URL 类,可以很方便对获取任何 url 构成
> > > from boltons.urlutils import URL
> > >
> > > url = URL('foo://example.com:8042/over/there?name=ferret#nose')
> > > print(url.host)
example.com
> > >
> > > print(url.port)
8042
> > >
> > > print(url.path)
/over/there
> > >
> > > print(url.query_params)
QueryParamDict([('name', 'ferret')])
# 3. 写在最后
Boltons 是纯Python,如果你不想引入 Boltons 巨大的工具箱时,也不用担心,每个模块都是独立的,没有依赖关系,可以直接复制到项目中使用。Boltons 旨在为广泛的基本功能提供最好的支持,是对标准库的一个补充,并且将高级功能留给其他更加专业的第三方库。推荐给大家使用!
-
matlab的实用工具命令2009-09-22 4611
-
申请实用工具软件版主!【申请通过】2011-04-27 2680
-
51单片机实用工具2012-12-20 3231
-
LabVIEW实用工具***宝典课件2015-01-25 45064
-
Labview实用工具详解 代码下载2015-06-30 9250
-
LabVIEW实用工具详解简版.pdf2015-07-28 26262
-
labview实用工具详解 配套程序2016-10-22 17071
-
调整线条宽度的实用工具2009-02-14 1208
-
uartassist串口调试助手_实用工具2016-11-17 2827
-
多种电子工程师实用工具大全2018-06-27 2277
-
电阻色环的识别实用工具应用程序免费下载2019-11-12 1642
-
windows启动修复实用工具免费下载2019-12-10 1259
-
LLC计算的实用工具应用程序免费下载2020-03-31 1997
-
频率电感电容计算的实用工具免费下载2020-05-06 1603
-
如何使用 Python 来创建一些强大的应用和实用工具2022-09-08 1304
全部0条评论

快来发表一下你的评论吧 !
