

读者理解:LEAP泛化到新的物体类别和场景
描述
摄像机姿态对于多视角三维建模是否必要?现有的方法主要假设可以获得准确的摄像机姿态。虽然这个假设对于密集视图可能成立,但对于稀疏视图,准确估计摄像机姿态常常是困难的。作者的分析显示,噪声估计的姿态会导致现有稀疏视图三维建模方法的性能下降。为了解决这个问题,作者提出了LEAP,一种新颖的无姿态方法,挑战了摄像机姿态不可或缺的普遍观念。LEAP舍弃了基于姿态的操作,从数据中学习几何知识。LEAP配备了一个神经体积,该体积在场景之间共享,并且通过参数化编码几何和纹理先验。对于每个输入的场景,作者通过按特征相似性驱动的方式聚合2D图像特征来更新神经体积。更新后的神经体积被解码为辐射场,从而可以从任意视点合成新的视图。通过对物体为中心和场景级别的数据集进行实验,作者展示了LEAP在使用最先进的姿态估计器预测的姿态时显著优于先前的方法。值得注意的是,LEAP的性能与使用真实姿态的先前方法相当,同时比PixelNeRF运行速度快400倍。作者还展示了LEAP泛化到新的物体类别和场景,并且学习的知识与极线几何密切相关。
读者理解:
LEAP方法:一种新的三维建模方法,可以从稀疏的视图中重建高质量的三维模型,而不需要知道相机的姿态(位置和方向)。这种方法利用了深度神经网络和几何约束,可以处理任意数量和分布的视图,甚至是单张图片。
与现有的三维建模方法相比,LEAP有以下优势:
不需要相机姿态信息,可以处理任意视角的图片。
可以从极少量的视图中重建出高质量的三维模型,甚至是单张图片。
可以处理不同尺度、不同光照、不同背景的图片,具有很强的泛化能力。
可以实现实时的三维建模,只需要几秒钟就可以生成三维模型。
LEAP实验:作者在多个数据集上进行了实验,包括ShapeNet、PASCAL3D+、Pix3D和自采集数据集。实验结果表明,LEAP在三维重建质量、运行速度和泛化能力方面都优于现有的方法。作者还展示了一些LEAP生成的三维模型的可视化效果。
1 引言
本文介绍了一种基于神经辐射场的3D建模方法LEAP,其与传统方法不同的是摒弃了使用摄像机姿态的操作,并通过学习数据中与姿态相关的几何知识和表示来进行建模。LEAP使用神经音量来初始化辐射场,并通过聚合方式更新神经音量。而在聚合2D图像特征时,LEAP采用注意力机制而非摄像机姿态来确定待聚合的像素。此外,LEAP还通过多视角编码器来提高非规范视角图像特征的一致性。训练中,LEAP使用真实的摄像机姿态生成2D渲染图像,并通过2D重建损失进行优化。实验结果表明LEAP在多种数据集上表现出了优越的性能、快速的推理速度、强大的泛化能力以及易解释的先验知识。这里也推荐「3D视觉工坊」新课程彻底搞透视觉三维重建:原理剖析、代码讲解、及优化改进》。

2 相关工作
本文主要介绍了两个与NeRF(Neural Radiance Fields)相关的工作,分别是针对稀疏视角输入的NeRF变体和稀疏视角相机姿态估计。针对NeRF的稀疏视角输入,有两种不同的方法:一种是针对特定场景的NeRF,通过从头开始优化辐射场来实现;另一种是通用的NeRF变体,通过预测2D图像特征条件下的辐射场来实现。然而,这些方法在推理3D点之间关联性和假设获取地面真实相机姿态方面存在一些局限性。而LEAP方法具有3D推理能力,在没有姿态的情况下可以处理图像。稀疏视角相机姿态估计是一个具有挑战性的问题,相比于密集视角,由于图像之间的最小或缺失重叠,对于准确的相机姿态估计来说,跨视角对应线索的形成十分困难。除了传统的基于密集视角的相机姿态估计技术的局限性外,还有一些方法通过引入能量模型、多视图信息和预训练模型等方法来提高姿态估计的准确性。然而,LEAP方法不需要专门的相机姿态估计模块,不受相机姿态估计的影响,可以更接近使用地面真实姿态的结果。对于没有准确或没有相机姿态的NeRF建模,有一些方法通过将相机姿态作为可调参数,并与辐射场一起进行优化来解决该问题。而LEAP方法通过3D感知的设计和基于特征相似性的2D-3D信息映射来消除对相机姿态的依赖,从而得到与使用地面真实姿态更接近的结果。
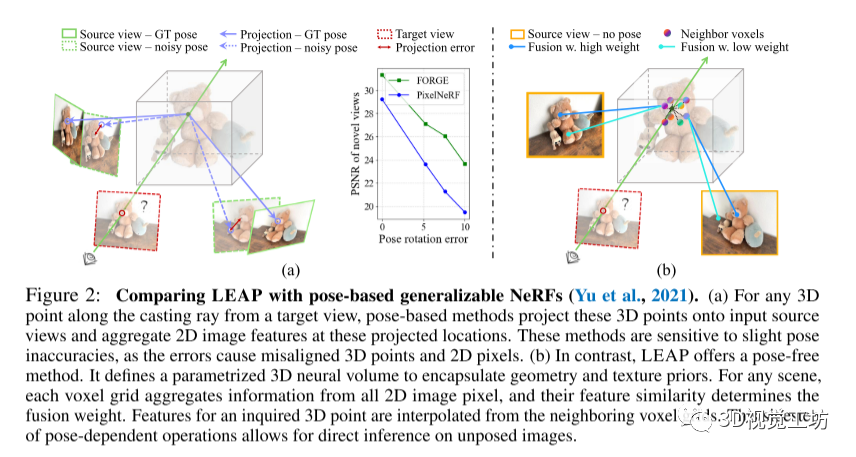
3 方法
本文介绍了LEAP方法的任务形式化和概述。给定一组k个场景的2D图像观测值,表示为{ |i = 1,..., k},LEAP预测了一个神经辐射场,可以从任意目标视点合成一张2D图像。需要注意的是,在我们的稀疏源视图设置中,由于宽基线相机拍摄的视图数量通常小于5,并且这些视图在推理过程中没有任何相关的相机姿态信息。
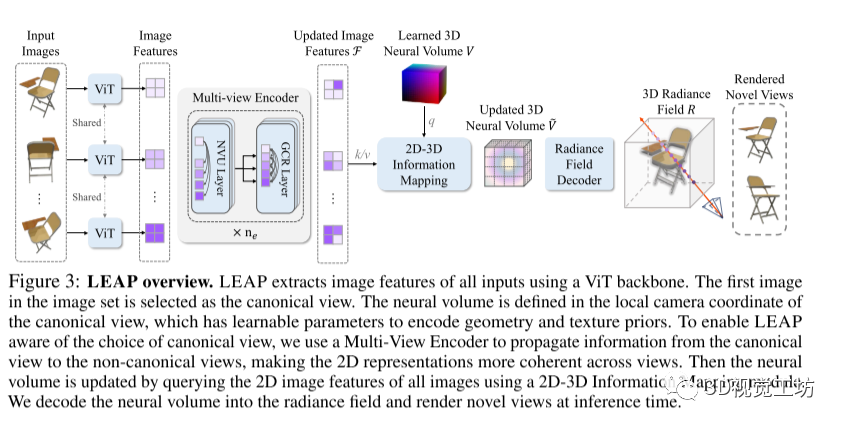
3.1 模型架构
LEAP首先从所有视角提取2D图像特征,使用一个DINOv2初始化的ViT作为特征提取器,以建模跨视角相关性。然后,LEAP引入了一个可学习的神经体积,对几何和纹理先验进行编码,并在所有场景中充当初始的3D表示。对于每个场景,LEAP通过查询多视图特征,将2D信息映射到3D领域,更新了神经体积,并预测了辐射场。具体来说,LEAP通过多视图图像编码器实现了对规范视图选择的感知,并通过捕捉交叉视角相关性来改善特征的一致性。接下来,LEAP引入了一个2D-3D信息映射模块,使用Transformer层对特征进行更新和整合,并进行了多次的2D-3D信息映射,以粗到细的方式重建对象的潜在体积。最后,LEAP使用更新后的神经体积预测了基于体素的神经辐射场,然后利用体积渲染技术生成渲染图像和对象掩码。总体来说,LEAP的模型架构可以在没有姿态信息的情况下,通过特征一致性和2D-3D信息映射来实现对场景的建模和图像合成。
3.2 LEAP的训练与推理
LEAP通过光度损失函数在没有任何3D监督的情况下对渲染结果和输入之间进行训练。首先定义了应用于RGB图像的损失函数LI,其中 = (ˆ, ) + (ˆ, )。其中L_{mse}I_{i}(ˆ分别表示原始图像和渲染后的图像,λp是用于平衡损失函数的超参数,Lp是感知损失函数(Johnson等,2016)。然后定义了应用于密度掩模的损失函数LM,即 = (ˆ, ),其中ˆ和分别表示原始和渲染后的密度掩模。最终损失函数定义为L = + ˆ,其中是用于平衡权重的超参数。如果掩模不可用,则只使用 。推断和评估。在推断过程中,LEAP在不依赖于任何姿态的情况下预测辐射场。为了评估新视角合成的质量,作者使用测试相机姿态在特定视点下渲染辐射场。
4 实验
本文介绍了LEAP方法在不同类型的数据集上进行的评估实验,并给出了实现细节和数据集说明。在实验中,LEAP表现出相对于其他基线模型的更好性能,包括更高的PSNR和更低的LPIPS值。此外,LEAP还展示了强大的泛化能力,能够适应不同几何和纹理特性的对象。LEAP还在场景级别数据集上取得了较好的结果,在性能上超过了PixelNeRF和与SPARF相媲美。该研究还进行了消融实验,探索了LEAP模型中各个组成部分的影响,并对LEAP的解释进行了可视化展示。结果表明,LEAP方法有效地利用多视角信息进行3D建模。这里也推荐「3D视觉工坊」新课程彻底搞透视觉三维重建:原理剖析、代码讲解、及优化改进》

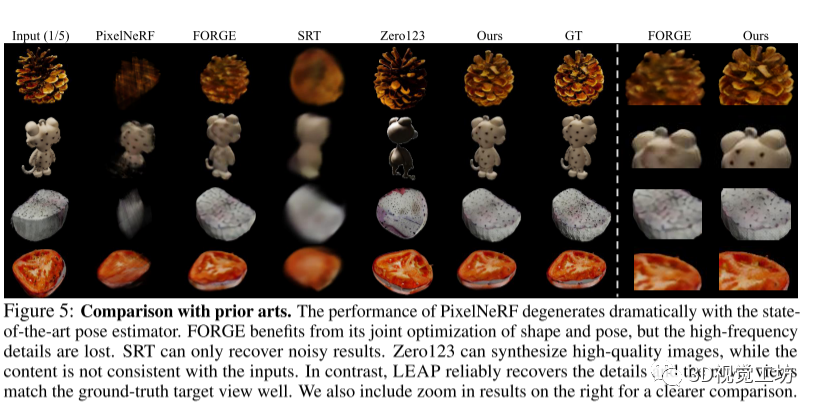

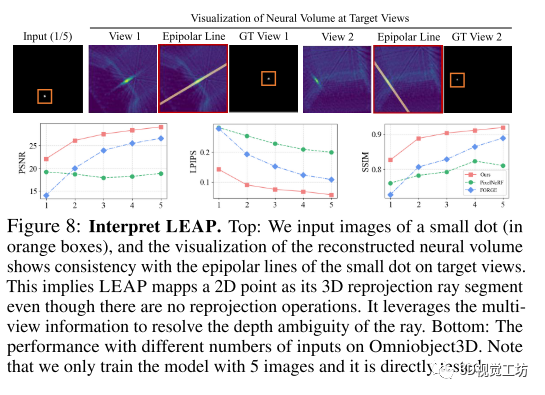
5 总结
本文提出了一种名为LEAP的无姿势方法,用于从一组非定姿稀疏视图图像进行三维建模。通过适当设置三维坐标并聚合二维图像特征,LEAP展示了令人满意的新视角合成质量。在我们的实验中,LEAP在从物体居中到场景级别,从合成图像到真实图像,以及从小规模到大规模数据的范围内,与使用估计姿势或噪声姿势的先前基于姿势的方法相比,始终表现出更好的性能。LEAP还与使用基准真实姿势的先前方法的版本取得了可比较的结果。此外,LEAP展示了强大的泛化能力,快速推理速度和可解释的学习知识。
-
cogo商城对轻量化LEAP的研究2012-03-22 2450
-
号外号外 Magic Leap造假了!2016-12-13 2864
-
不同类别的电池是如何回收的?2009-11-04 1034
-
LEAP,LEAP是什么意思2010-03-10 4237
-
泰克荣获《ECN杂志》读者选择技术奖2012-01-10 1322
-
基于多类别语义词簇的新闻读者情绪分类2017-12-13 961
-
Leap Motion开发教程之Leap Motion官方中文开发文档资料免费下载2018-10-18 1688
-
如何理解泛化是深度学习领域尚未解决的基础问题2021-04-08 3493
-
智能零售场景中的图像分类技术综述2021-06-07 1103
-
iNeRF对RGB图像进行类别级别的物体姿态估计2022-08-10 2310
-
三维场景点云理解与重建技术2023-08-08 2758
-
自动驾驶场景理解模块2023-10-04 1802
-
自动驾驶汽车是如何进行“场景理解”的?2025-12-11 789
全部0条评论

快来发表一下你的评论吧 !
