

看看ARM处理器存储访问一致性问题
处理器/DSP
描述
1 存储访问一致性问题介绍
当存储系统中引入了cache和写缓冲区(Write Buffer)时,同一地址单元的数据可能在系统中有多个副本,分别保存在cache、Write Buffer及主存中,如果系统采用了独立的数据cache和指令cache,同一地址单元的数据还可能在数据cache和指令cache中 有不同的版本 。
位于不同物理位置的同一地址单元的数据可能会不同 ,使得数据读操作可能得到的不是系统中“最新的数值”,这样就带来了存储系统中数据的一致性问题。
- (1)cache(介于CPU和DDR) 解决CPU速度和内存速度的速度差异问题(CPU存取数据的速度非常快,而内存比较慢),内存中被CPU访问最频繁的数据和指令被复制到CPU中的缓存,CPU访问数据直接去缓存中访问就行了。
- (2)cache一致性 CPU的访问数据与DDR的数据没有同步。
- (3)CPU、Cache以及DDR之间访问关系 Cache是一个介于CPU以及DDR(DRAM)之间的一个高速缓存(一般好像是SRAM),在处理器内部,读写速度较DDR高,但是低于CPU的速度。假如没有Cache,直接访问DDR,CPU的速度远远高于DDR,那么CPU就需要等待DDR的数据到来,才能做其他事情,就会造成CPU使用效率较低。使用Cache之后,提前将DDR的数据缓存到Cache中,如果恰好CPU访问DDR的数据在Cache中有,那么CPU拿到数据的时间将更短,处理效率将大大增加。但是同时也会造成一致性问题,即CPU的访问的数据(Cache)与DDR的数据没有同步,造成执行错误。假设一种真实情况,CPU要访问DDR中的一块数据,那么这块数据会放在Cache中,之后DMA控制器直接将外设的数据放在DDR中,更新了刚刚的那一块CPU要访问的数据,此时CPU要获取数据进行处理,还是拿着Cache中未更新的数据(没有立马反映到DDR中),就会造成一致性问题。
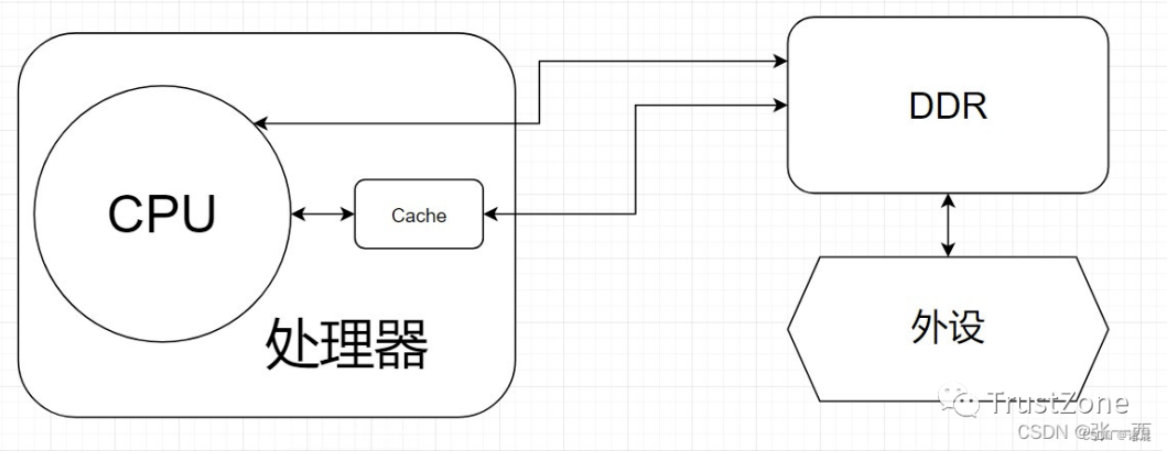
- (4)解决Cache一致性问题 将Cache中的数据清空,或者将DDR与Cache的数据同步。(使用CacheFlush和Cache Invalidate操作,CacheFlush把Cache里的数据清空,将Cache内容推到DDR中;而Cache Invalidate表示当场宣布Cache内容无效,需要从DDR中重新加载数据,即把数据从DDR中拉到Cache中。)

其实涉及到了缓存,不只是逻辑上的存储,在互联网,分布式架构,在现在的大数据环境下,也会面临数据一致性的问题。
怎么保持这个数据的一致性,不要让彼此读到了脏数据,是一个很重要的事情。
在ARM存储系统中,数据不一致的问题则 需要通过程序设计时遵守一定的规则来保证 ,这些规则说明如下。
1.1 地址映射关系变化造成的数据不一致性
当系统中使用了MMU时,就建立了虚拟地址到物理地址的映射关系, 如果查询cache时进行的相连比较使用的是虚拟地址 ,则当系统中虚拟地址到物理地址的映射关系发生变化时,可能造成cache中的数据和主存中数据不一致的情况。
(所以这个cache好使归好使,但是插入了中间人,这个就会带来一些风险与问题。)
读
在虚拟地址到物理地址的映射关系发生变化前,如果虚拟地址A1所在的数据块已经预取到cache中,当虚拟地址到物理地址的映射关系发生变化后,如果虚拟地址A1对应的物理地址发生了改变,则当CPU访问A1时再使用cache中的数据块将得到错误的结果。
这就很吓人呢,你本来想看一个正常的日本动作电影,结果访问到了错误的地址,运气好点你能访问你有权限的内存,运气不好这个动作电影还带了爱情,瑟瑟发抖。
写
同样当系统中采用了Write Buffer时,如果CPU写入Write Buffer的地址是虚拟地址,也会发生数据不一致的情况。
在虚拟地址到物理地址的映射关系发生变化前,如果CPU向虚拟地址为A1的单元执行写操作,该写操作已经将A1以及对应的数据写入到Write Buffer中,当虚拟地址到物理地址的映射关系发生变化后,如果虚拟地址A1对应的物理地址发生了改变,当Write Buffer将上面被延迟的写操作写到主存中时,使用的是变化后的物理地址,从而使写操作失败。
这个归根结底,关键点就在于cache里面的数据地址是不是最新的,怎么保证是最新的,未被修改的。(阅读这个部分的时候脑子里一定要有SMP架构,不然要是都是一个人的,那有啥不一致的呢)
为了避免发生这种数据不一致的情况, 在系统中虚拟地址到物理地址的映射关系发生变化前 ,根据系统的具体情况,执行下面操作序列中的一种或几种:
- 1)如果数据cache为write back类型,清空该数据的cache;
- 2)使数据cache中相应的块无效;
- 3)使指令cache中相应的块无效;
- 4)将Write Buffer中被延迟的写操作全部执行;
- 5)有些情况可能还要求相关的存储区域被设置成非缓冲的。
一、CPU向cache写入数据时的操作,两者的区别
1、Write-through:CPU向cache写入数据时,同时向memory(后端存储)也写一份,使cache和memory的数据保持一致。
2、Write-back:cpu更新cache时,只是把更新的cache区标记一下,并不同步更新memory(后端存储)。只是在cache区要被新进入的数据取代时,才更新memory(后端存储)。
二、两者相比较优势
1、Write-through:优点是简单
2、Write-back:优点是CPU执行的效率提高
三、两者相比较劣势
1、Write-through:缺点是每次都要访问memory,速度比较慢。
2、Write-back:缺点是实现起来技术比较复杂。两者区别形象比喻:Write-through与Write-back和买卖东西相似,Write-Through就相当于你亲自去买东西,你买到什么就可以亲手拿到;而Write-Back就和中介差不多,你给了中介钱,然后它告诉你说你的东西买到了,然后就相信拿到这个东西了,但是要是出现特殊情况中介跑了,你再去检查,东西原来没有真正到手。
1.2 指令cache的数据不一致性问题

看一下ICACHE和DCACHE同步问题。
由于程序的运行而言,指令流的都流过icache,而指令中涉及到的数据流经过dcache。
所以对于自修改的代码(Self-Modifying Code)而言,比如我们修改了内存p这个位置的代码(典型多见于JIT compiler),这个时候我们是通过store的方式去写的p,所以新的指令会进入dcache。
但是我们接下来去执行p位置的指令的时候,icache里面可能命中的是修改之前的指令。

相当于这个就是P位置得这个要执行得指令,本质上也是数据,我把这个指令当数据得时候,我去修改以及整理得时候走的是dcache,但是我操作得时候去读得是icache。
当系统中采用独立的数据cache和指令cache时,下面的操作序列可能造成指令不一致的情况:
- 1)读取地址为A1的指令,从而包含该指令的数据块被预取到指令cache中。
- 2)与A1在同一个数据块中的地址为A2的存储单元的数据被修改,这个数据写操作可能影响数据cache、Write Buffer和主存中地址为A2的存储单元的内容,但是不影响指令cache中地址为A2的存储单元的内容。
- 3)如果地址A2存放的是指令,当该指令执行时,就可能发生指令不一致的问题。如果地址A2所在的块还在指令cache中,系统将执行修改前的指令。如果地址A2所在的块不在指令cache中,系统将执行修改后的指令。
为了避免这种指令不一致情况的发生,在上面第1)步和第2)步之间插入下面的操作序列:
- 1)对于使用统一的数据cache和指令cache的系统,不需要任何操作;
- 2)对于使用独立的数据cache和指令cache的系统,使指令cache的内容无效;
- 3)对于使用独立的数据cache和指令cache的系统,如果数据cache是write back类型的,清空数据cache。
当数据操作修改了指令时,最好执行上述操作序列,保证指令的一致性。下面是上述操作序列的一个典型应用场合。当可执行文件加载到主存中后,在程序跳转到入口点处开始执行之前,先执行上述的操作序列,以保证下面指令的是新加载的可执行代码,而不是指令中原来的旧代码。
所以这个时候软件需要把dcache的东西clean出去,然后让icache invalidate,这个开销显然还是比较大的。但是,比如ARM64的N1处理器,它支持硬件的icache同步,详见文档:The Arm Neoverse N1 Platform: Building Blocks for the Next-Gen Cloud-to-Edge Infrastructure SoC

特别注意画红色的几行。软件维护的成本实际很高,还涉及到icache的invalidation向所有核广播的动作。接下来的一个问题就是多个核之间的cache同步。下面是一个简化版的处理器,CPU_A和B共享了一个L3,CPU_C和CPU_D共享了一个L3。实际的硬件架构由于涉及到NUMA,会比这个更加复杂,但是这个图反映层级关系是足够了。

比如CPU_A读了一个地址p的变量?CPU_B、C、D又读,难道B,C,D又必须从RAM里面经过L3,L2,L1再读一遍吗?这个显然是没有必要的,在硬件上,cache的snooping控制单元,可以协助直接把CPU_A的p地址cache拷贝到CPU_B、C和D的cache。
snooping控制单元,看到这个单词想到了什么?是的,咱们的狗狗。嗅探检测到改变。

这样A-B-C-D都得到了相同的p地址的棕色小球。假设CPU B这个时候,把棕色小球写成红色,而其他CPU里面还是棕色,这样就会不一致了:

这个时候怎么办?这里面显然需要一个协议,典型的多核cache同步协议有MESI和MOESI。
MOESI相对MESI有些细微的差异,不影响对全局的理解。下面我们重点看MESI协议。MESI协议定义了4种状态:
- M(Modified): 当前cache的内容有效,数据已被修改而且与内存中的数据不一致, 数据只在当前cache里存在 ;类似RAM里面是棕色球,B里面是红色球 (CACHE与RAM不一致 ),A、C、D都没有球。

- E(Exclusive):当前cache的内容有效,数据与内存中的数据一致, 数据只在当前cache里存在 ;类似RAM里面是棕色球,B里面是棕色球(RAM和CACHE一致),A、C、D都没有球。

- S(Shared):当前cache的内容有效,数据与内存中的数据一致,数据在多个cache里存在。类似如下图,在CPU A-B-C里面cache的棕色球都与RAM一致。

- I(Invalid):当前cache无效。前面三幅图里面cache没有球的那些都是属于这个情况。然后它有个状态机

这个状态机比较难记,死记硬背是记不住的,也没必要记,它讲的cache原先的状态,经过一个硬件在本cache或者其他cache的读写操作后,各个cache的状态会如何变迁。
所以,硬件上不仅仅是监控本CPU的cache读写行为,还会监控其他CPU的。
只需要记住一点:这个状态机是为了保证多核之间cache的一致性,比如一个干净的数据,可以在多个CPU的cache share,这个没有一致性问题;但是,假设其中一个CPU写过了,比如A-B-C本来是这样:

然后B被写过了:

这样A、C的cache实际是过时的数据,这是不允许的。 这个时候,硬件会自动把A、C的cache invalidate掉 ,不需要软件的干预,A、C其实变地相当于不命中这个球了:
- Cache Invalidate 该操作主要为解除内存与Cache的绑定关系。例如操作DMA进行数据搬移时,如果目标内存配置为可Cache,那么后续通过CPU读取该内存数据时候,若Cache命中,则可能读取到的数据不是DMA搬移后的数据,那么在进行DMA搬移之前,先进行Cache Invalidate操作,保证后续CPU读取到的数据是DMA真正搬移的数据。
实际案例:软件处理的数据异常,与期望结果不一致,通过抓取DMA搬移的源数据,与后续CPU数据进行比较,发现部分数据相同,部分数据不一致,后续确认为内存地址配置成了可Cache,导致CPU读取进行处理的软件数据异常。
- Cache Flush 该操作为将Cache中的数据写回内存。

这个时候,你可能会继续问,如果C要读这个球呢?它目前的状态在B里面是modified的,而且与RAM不一致,这个时候,硬件会把红球clean,然后B、C、RAM变地一致,B、C的状态都变化为S(Shared):

这一系列的动作虽然由硬件完成,但是对软件而言不是免费的,因为它耗费了时间。如果编程的时候不注意,引起了硬件的大量cache同步行为,则程序的效率可能会急剧下降。
所以了解知道硬件的行为,写出来的代码才会更加的效率提升!!!
都到这里,不得不说前辈整的这个图真的是非常非常NICE,感激这些前辈的分享。都到这里了,不一起来学习一个例子的话,就很不合适了。
下面我们写一个程序,这个程序有2个线程,一个写变量,一个读变量:

这个程序里,x和y都是cacheline对齐的,这个程序的thread1的写,会不停地与thread2的读,进行cache同步。它的执行时间为:
$ time ./a.out
real 0m3.614s
user 0m7.021s
sys 0m0.004s
它在2个CPU上的userspace共运行了7.021秒,累计这个程序从开始到结束的对应真实世界的时间是3.614秒(就是从命令开始到命令结束的时间)。如果我们把程序改一句话,把thread2里面的c = x改为c = y,这样2个线程在2个CPU运行的时候,读写的是不同的cacheline,就没有这个硬件的cache同步开销了:

它的运行时间:
$ time ./b.out
real 0m1.820s
user 0m3.606s
sys 0m0.008s
现在只需要1.8秒,几乎减小了一半。感觉前面那个a.out,双核的帮助甚至都不大。如果我们改为单核跑呢?
$ time taskset -c 0 ./a.out
real 0m3.299s
user 0m3.297s
sys 0m0.000s
它单核跑,居然只需要3.299秒跑完,而双核跑,需要3.614s跑完。单核跑完这个程序,甚至比双核还快,有没有惊掉下巴?!!!因为单核里面没有cache同步的开销。下一个cache同步的重大问题,就是设备与CPU之间。
如果设备感知不到CPU的cache的话(下图中的红色数据流向不经过cache),这样,做DMA前后,CPU就需要进行相关的cacheclean和invalidate的动作,软件的开销会比较大。

这些软件的动作,若我们在Linux编程的时候,使用的是streaming DMA APIs的话,都会被类似这样的API自动搞定:
dma_map_single()
dma_unmap_single()
dma_sync_single_for_cpu()
dma_sync_single_for_device()
dma_sync_sg_for_cpu()
dma_sync_sg_for_device()
如果是使用的dma_alloc_coherent() API呢,则设备和CPU之间的buffer是cache一致的,不需要每次DMA进行同步。
对于不支持硬件cache一致性的设备而言,很可能dma_alloc_coherent()会把CPU对那段DMA buffer的访问设置为uncachable的。
这些API把底层的硬件差异封装掉了,如果硬件不支持CPU和设备的cache同步的话,延时还是比较大的。
那么,对于底层硬件而言,更好的实现方式,应该仍然是硬件帮我们来搞定。比如我们需要修改总线协议,延伸红线的触角:

当设备访问RAM的时候,可以去snoop CPU的cache:
- 如果做内存到外设的DMA,则直接从CPU的cache取modified的数据;
- 如果做外设到内存的DMA,则直接把CPU的cache invalidate掉。
这样,就实现硬件意义上的cache同步。当然,硬件的cache同步,还有一些其他方法,原理上是类似的。
注意,这种同步仍然不是免费的,它仍然会消耗bus cycles的。实际上,cache的同步开销还与距离相关,可以说距离越远,同步开销越大,比如下图中A、B的同步开销比A、C小。

对于一个NUMA服务器而言,跨NUMA的cache同步开销显然是要比NUMA内的同步开销大。意识到CACHE的编程通过上一节的代码,读者应该意识到了cache的问题不处理好,程序的运行性能会急剧下降。
所以意识到cache的编程,对程序员是至关重要的。
从CPU流水线的角度讲,任何的内存访问延迟都可以简化为如下公式:
Average Access Latency = Hit Time + Miss Rate × Miss
Penaltycache miss会导致CPU的stall状态,从而影响性能。现代CPU的微架构分了frontend和backend。
- frontend负责fetch指令给backend执行,
- backend执行依赖运算能力和Memory子系统(包括cache)延迟。

backend执行中访问数据导致的cache miss会导致backend stall,从而降低IPC(instructions per cycle)。
减小cache的miss,实际上是一个软硬件协同设计的任务。
比如硬件方面,它支持预取prefetch,通过分析cache miss的pattern,硬件可以提前预取数据,在流水线需要某个数据前,提前先取到cache,从而CPU流水线跑到需要它的时候,不再miss。
当然,硬件不一定有那么聪明,也许它可以学会一些简单的pattern。但是,对于复杂的无规律的数据,则可能需要软件通过预取指令,来暗示CPU进行预取。
cache这个学问真的就很大了,比如MESI协议这些等等。后续好好整一个系列,学习一下。
1.3 DMA造成的数据不一致问题
DMA操作直接访问主存,而不会更新cache和Write Buffer中相应的内容,这样就可能造成数据的不一致。
如果DMA从主存中读取的数据已经包含在cache中,而且cache中对应的数据已经被更新,这样DMA读到的将不是系统中最新的数据。同样DMA写操作直接更新主存中的数据,如果该数据已经包含在cache中,则cache中的数据将会比主存中对应的数据“老”,也将造成数据的不一致。
为了避免这种数据不一致情况的发生,根据系统的具体情况,执行下面操作序列中的一种或几种:
- 1)将DMA访问的存储区域设置成非缓冲的,即uncachable及unbufferable;
- 2)将DMA访问的存储区域所涉及数据cache中的块设置成无效,或者清空数据cache;
- 3)清空Write Buffer(执行Write Buffer中延迟的所有写操作);
- 4)在DMA操作期间限制处理器访问DMA所访问的存储区域。
1.4 指令预取和自修改代码
在ARM中允许指令预取,在CPU执行当前指令的同时,可以从存储器中预取其后若干条指令,具体预取多少条指令,不同的ARM实现中有不同的数值。
当用户读取PC寄存器的值时,返回的是当前指令下面第2条指令的地址。比如当前执行的是第N条指令,当用户读取PC寄存器的值时,返回的是指令N+2的地址。对于ARM指令来说,读取PC寄存器的值时,返回当前指令地址值加8个字节;对于Thumb指令来说,读取PC寄存器的值时,返回当前指令地址值加4个字节。
2 Linux中解决存储访问一致性问题的方法
在Linux中,是用barrier()宏来解决以上存储访问一致性问题的,barrier()的定义如下所示:
#define barrier() __asm__ __volatile__("": : :"memory")
另外在barrier()的基础上还衍生出了很多类似的定义,如:
#define mb() __asm__ __volatile__ ("" : : : "memory")
#define rmb() mb()
#define wmb() mb()
#define smp_mb() barrier()
#define smp_rmb() barrier()
#define smp_wmb() barrier()
barrier是内存屏障的意思,CPU越过内存屏障后,将刷新自己对存储器的缓冲状态 。barrier()宏定义这条语句实际上不生成任何代码, 但可使gcc在barrier()之后刷新寄存器对变量的分配。 具体分析如下。

概括起来说barrier()起到两个作用:
- 1)告诉编译器不要优化这部分代码,保持原有的指令执行顺序;
- 2)告诉CPU执行完barrier()之后要进行同步操作,更新registers、cache、写缓存和内存中的内容,全部重新从内存中取数据。
-
聚焦充电桩新国标,能否有效解决协议一致性问题?2017-04-14 1251
-
介绍ARM存储一致性模型的相关知识2023-02-14 3038
-
如何解决stm32 H7 DMA串口发送数据一致性问题?2021-12-06 1134
-
ARM系列 - - 存储模型(一)2022-04-11 5166
-
顺序一致性和TSO一致性分别是什么?SC和TSO到底哪个好?2022-07-19 2733
-
一致性规划研究2009-04-06 725
-
异构多处理器系统Cache一致性解决方案2009-09-26 911
-
CMP中Cache一致性协议的验证2010-07-20 1057
-
片上嵌入式多处理器的一致性机制设计2011-07-06 1026
-
DBA迅速解决分布式事务XA一致性问题2017-09-07 1042
-
加速器一致性接口2017-11-17 4612
-
DSA系统的全局一致性需求分析2017-12-06 1145
-
Cache一致性协议优化研究2017-12-30 1248
-
管理基于Cortex®-M7的MCU的高速缓存一致性2021-04-01 1035
-
缓存与数据库一致性问题如何解决2023-03-24 1449
全部0条评论

快来发表一下你的评论吧 !
