

Google的TPU芯片的发展历史和硬件架构
处理器/DSP
描述
Google在高性能处理器与AI芯片主要有两个系列:1)针对服务器端AI模型训练和推理的TPU系列,主要用于Goggle云计算和数据中心;2)针对手机端AI模型推理的Tensor系列,主要用于Pixel智能手机。
结合最近几年Google在HotChips、ISCA、ISSCC发布的论文和报告,总结了Google的TPU芯片的发展历史和硬件架构,可作为学习、研发高性能处理器与AI芯片的参考资料。
1. TPUv1
Google第一代TPU芯片,服务器端推理芯片。
硬件架构 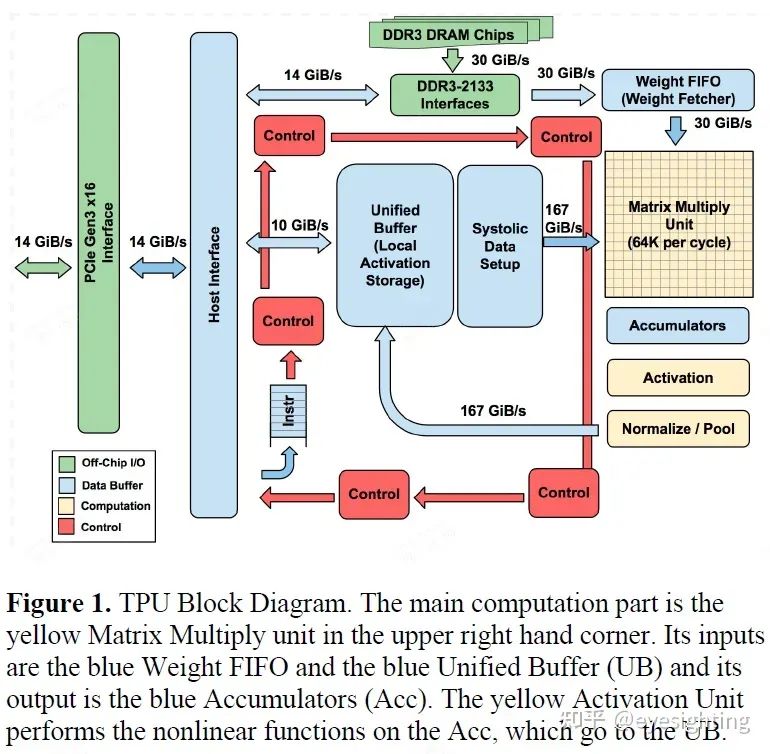
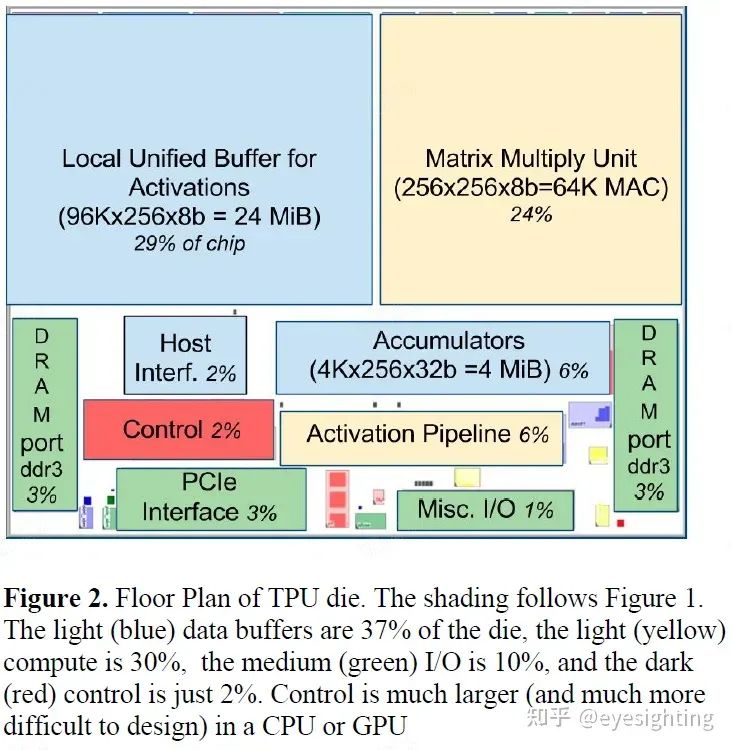
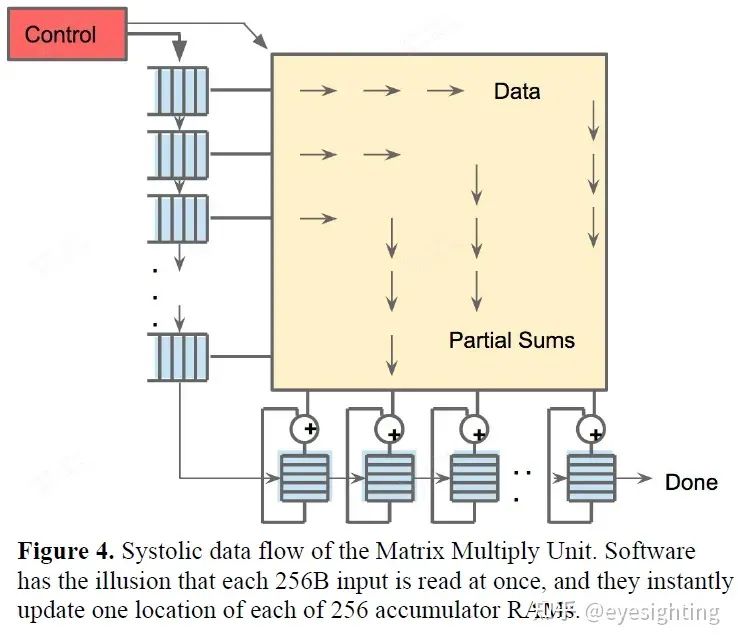
 功能特性
功能特性
1).TPU指令通过PCIe Gen3 x16总线从主机发送到指令缓冲区。矩阵乘法单元是TPU的核心,包含256x256个MAC,可以对有符号或无符号整数执行8位乘法和加法。16位乘积被收集在矩阵单元下方的32位累加器的4 MiB中。4MiB表示4096256个元素的32位累加器。矩阵单元在每个时钟周期产生一个256元素的部分和。
2).当混合使用 8 位权重和 16 位激活时(反之亦然),矩阵单元以半速计算,而当两者都是 16 位时,它以四分之一速度计算。
3).省略了稀疏架构支持。稀疏性将在未来的设计中占据高度优先地位。
4).TPU 指令遵循 CISC 传统,包括重复字段。这些 CISC 指令的平均每条指令时钟周期 (CPI) 通常为 10 到 20。总共约有 12 条指令,但以下 5 条是关键指令:Read_Host_Memory、Read_Weights、MatrixMultiply/Convolve、Activate、Write_Host_Memory。其他指令是备用主机内存读/写、设置配置、两个版本的同步、中断主机、调试标记、nop 和暂停。
2. TPUv2
Google的第二代TPU,定位是服务端AI推理和训练芯片。
硬件架构 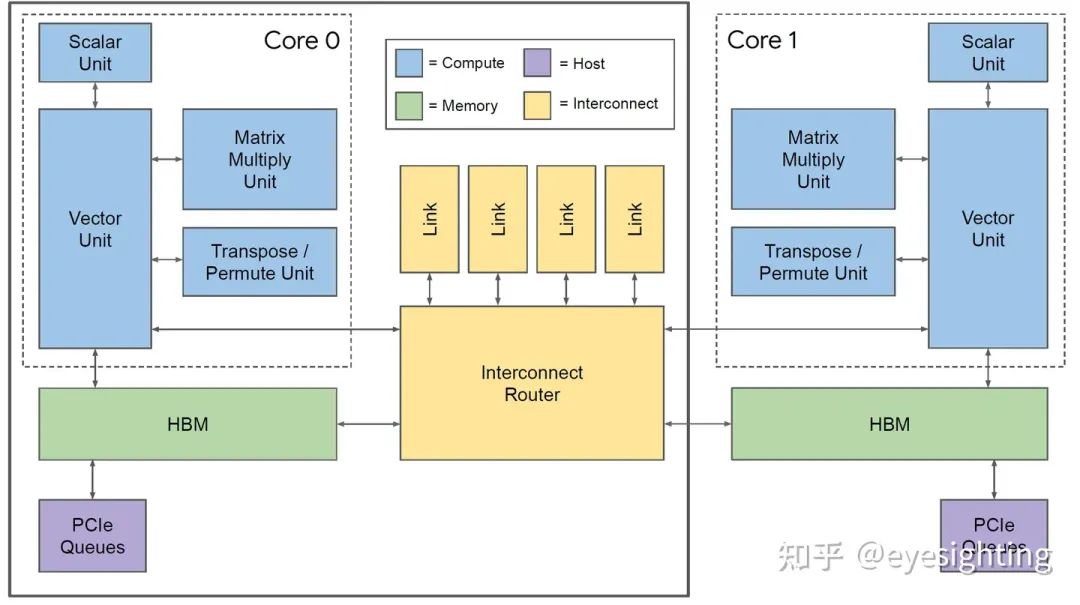

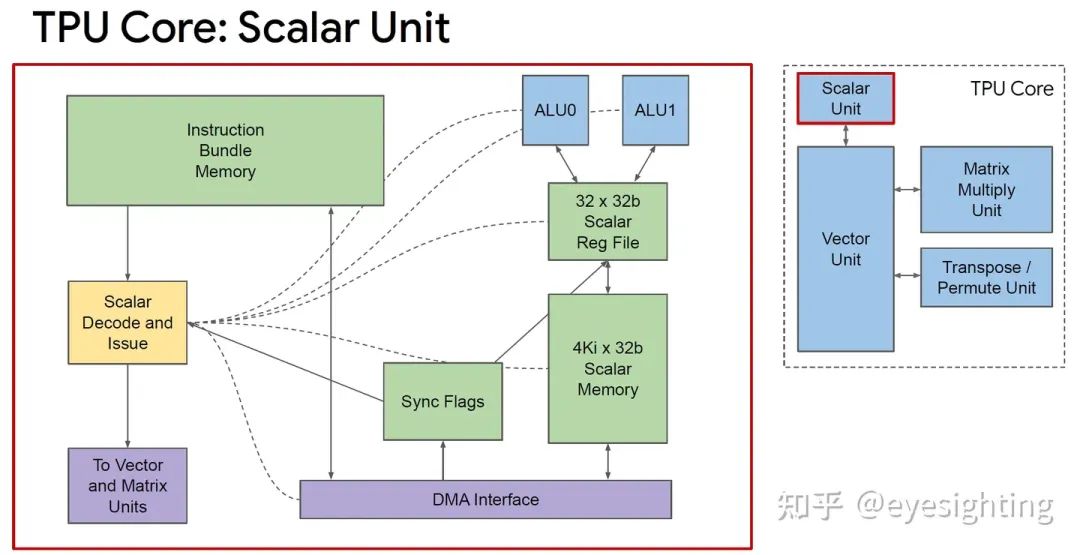
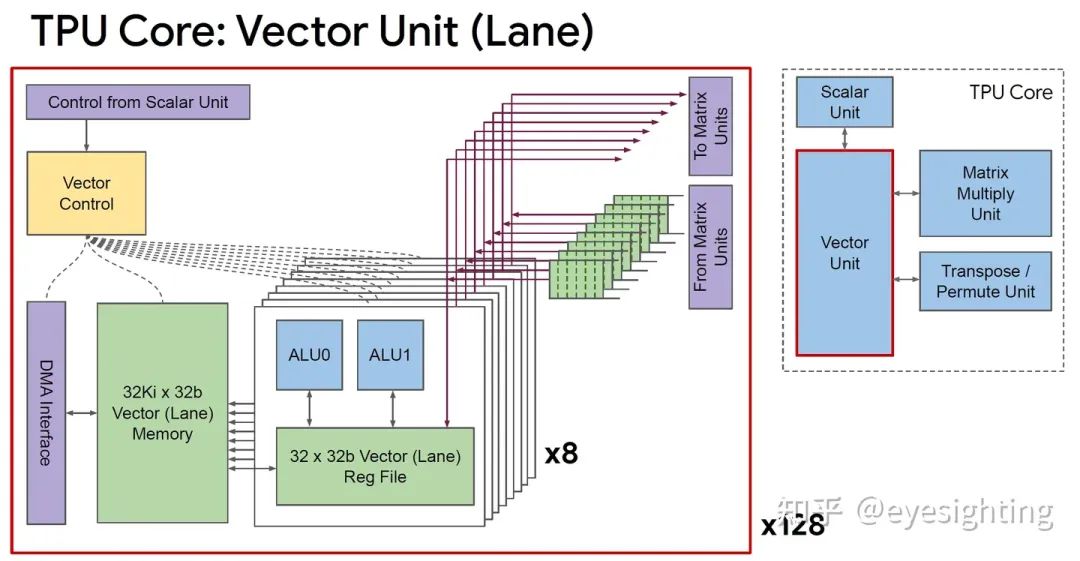


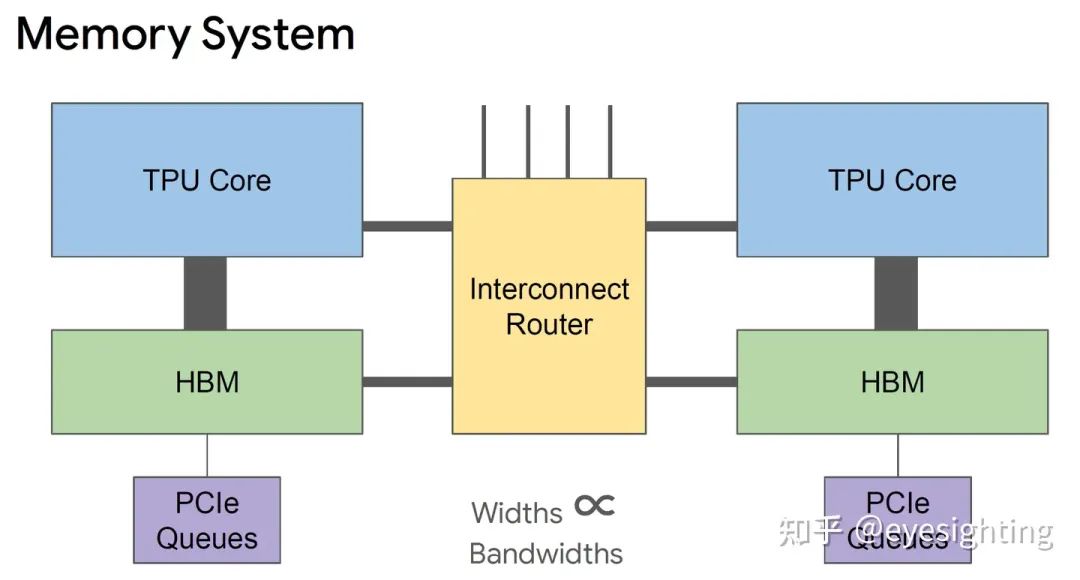
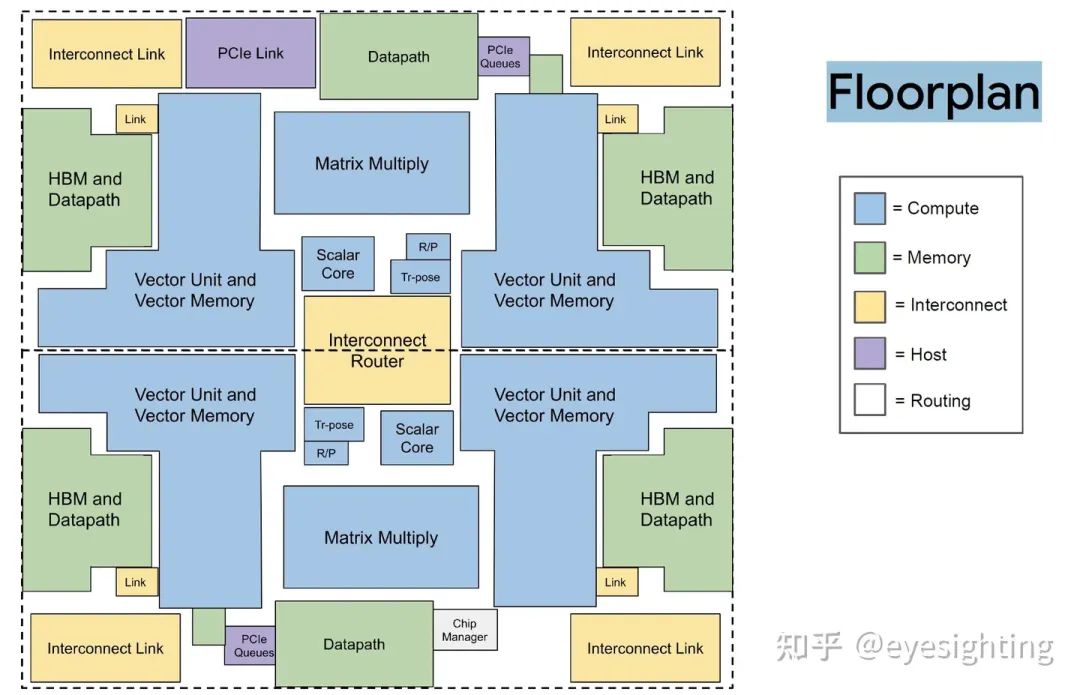
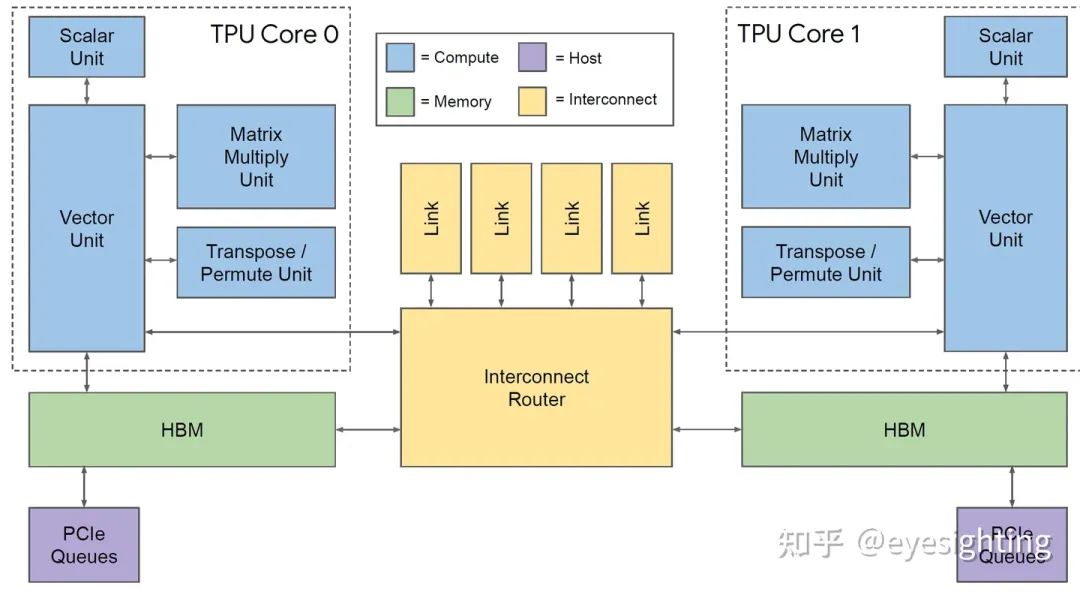 TPUv2改变
TPUv2改变
单个向量存储器,而不是固定功能单元之间的缓冲区。
通用向量单元,而不是固定功能激活管道。
连接矩阵单元作为向量单元的卸载。
将 DRAM 连接到内存系统而不是直接连接到矩阵单元。
转向 HBM 以获得带宽。
添加互连以实现高带宽扩展。
TPUv2 Core
超长指令字架构:利用已知的编译器技术。
线性代数ISA:标量、向量和矩阵,为通用性而构建。
TPU 核心:标量单元 322b VLIW 捆绑包:
2 个标量槽
4 个向量槽(2 个用于加载/存储)
2 个矩阵插槽(推入、弹出)、
1 个杂项插槽
6 个立即数
存储系统
针对 SRAM 暂存器进行加载和存储
在核心内提供可预测的调度
可能会因同步标志而停止
可通过异步 DMA 访问
在同步标志中指示完成
互连器
具有 4 个链路的片上路由器
每个链路 500 Gbps
组装成2D环面
软件视图:使用 DMA,就像 HBM 一样;限制推送 DMA;只需定位另一个芯片 ID
3. TPUv3
TPU3是是对TPU2的温和重新设计,采用相同的技术,MXU和HBM容量增加了两倍,时钟速率、内存带宽和ICI带宽增加了1.3倍。TPU3超级计算机还可以扩展到1024个芯片。
硬件架构 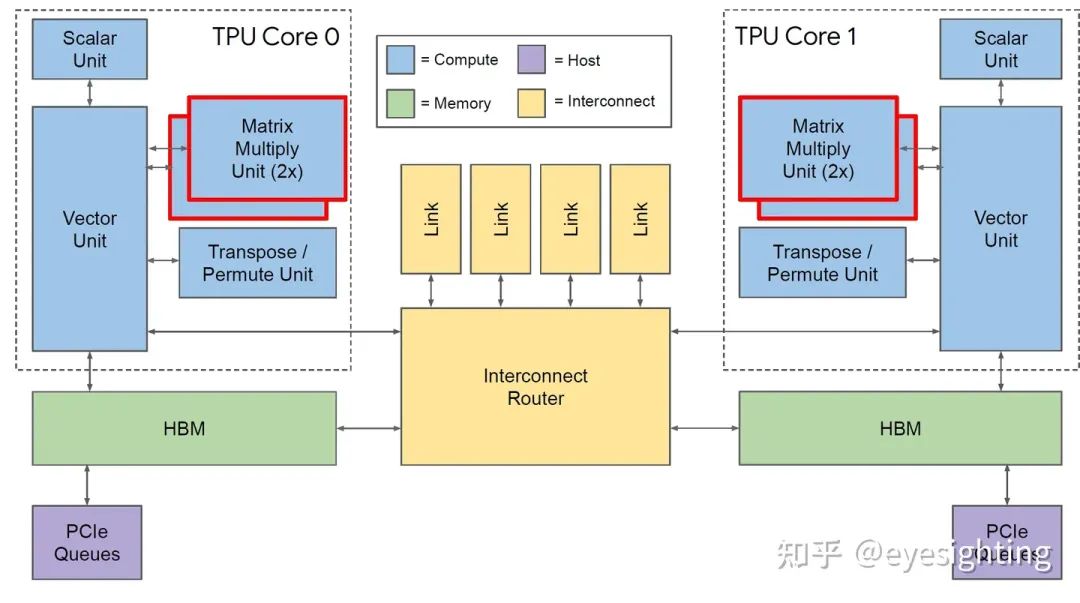
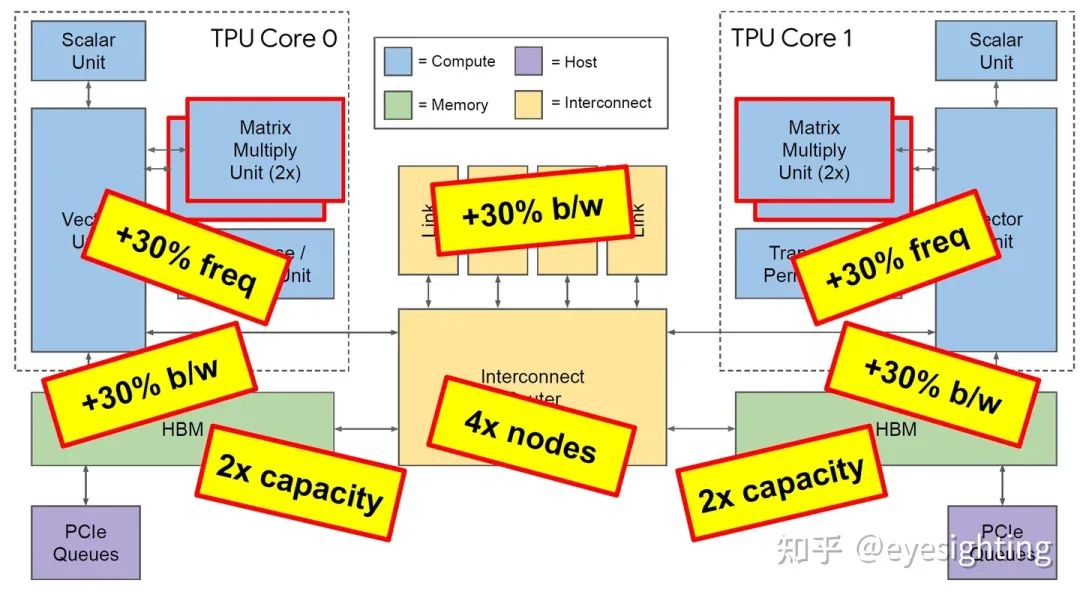 功能特性
功能特性
协同设计:具有软件可预测性的简化硬件(例如,VLIW、暂存器)。
使用 bfloat16 脉动阵列计算密度:HBM 为计算提供支持,XLA编译器。
具有原则性线性代数框架的灵活大数据核心。
4. Edge TPU
Google发布的嵌入式TPU芯片,用于在边缘设备上运行推理。
5. TPUv4i
TPUv4i:Google于2020年发布,定位是服务器端推理芯片.
硬件架构 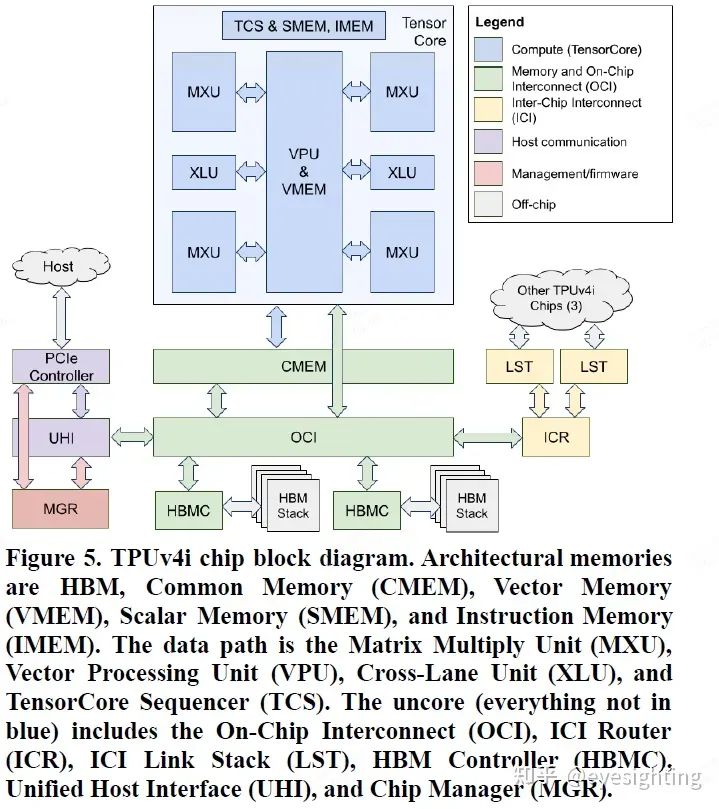
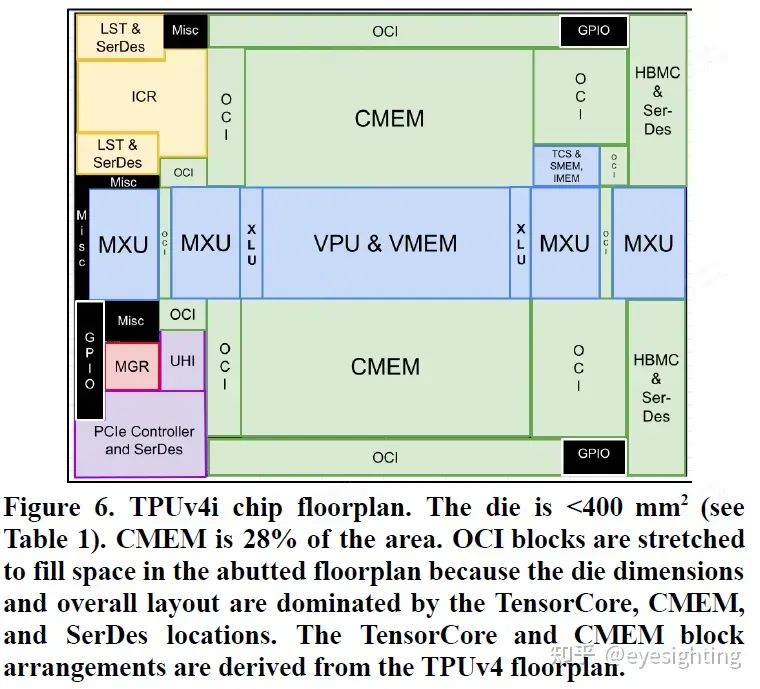
 功能特性 1).单核TPUv4i 用于推理,双核 TPUv4(可扩展至 4096 个芯片)用于训练。 2).选择编译器兼容性,而不是二进制兼容性。 3).通过通用内存 (CMEM)增加了片上 SRAM 存储。 4).四维张量 DMA 引擎充当协处理器,可完全解码和执行 TensorCore DMA 指令。 5).添加了一个共享片上互连 (OCI),用于连接芯片上的所有组件。 6).引入了四输入加法器运算单元。 7).时钟频率达到 1.05 GHz。 8).2个ICI链路链接板端4 个芯片。 9).具有广泛的跟踪和性能计数器等硬件功能。
功能特性 1).单核TPUv4i 用于推理,双核 TPUv4(可扩展至 4096 个芯片)用于训练。 2).选择编译器兼容性,而不是二进制兼容性。 3).通过通用内存 (CMEM)增加了片上 SRAM 存储。 4).四维张量 DMA 引擎充当协处理器,可完全解码和执行 TensorCore DMA 指令。 5).添加了一个共享片上互连 (OCI),用于连接芯片上的所有组件。 6).引入了四输入加法器运算单元。 7).时钟频率达到 1.05 GHz。 8).2个ICI链路链接板端4 个芯片。 9).具有广泛的跟踪和性能计数器等硬件功能。
6. TPUv4
谷歌2020年发布,服务器推理和训练芯片,芯片数量是TPUv3的四倍。
硬件架构 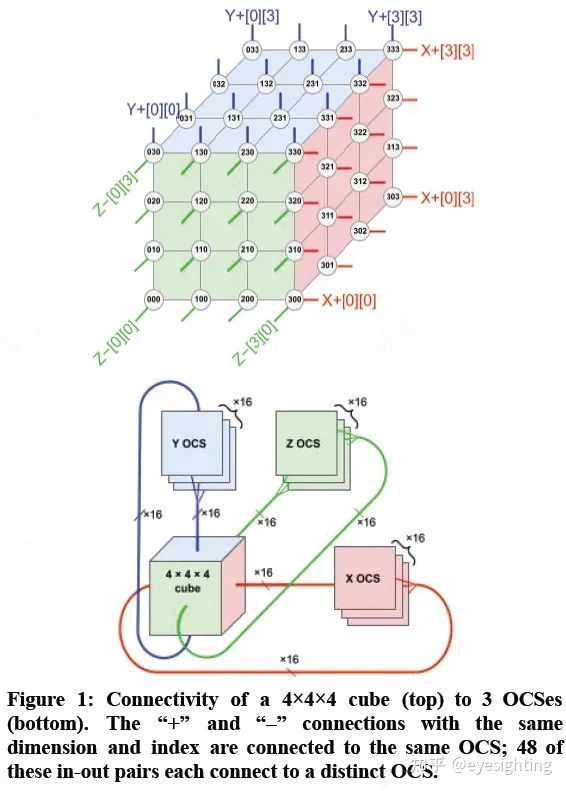

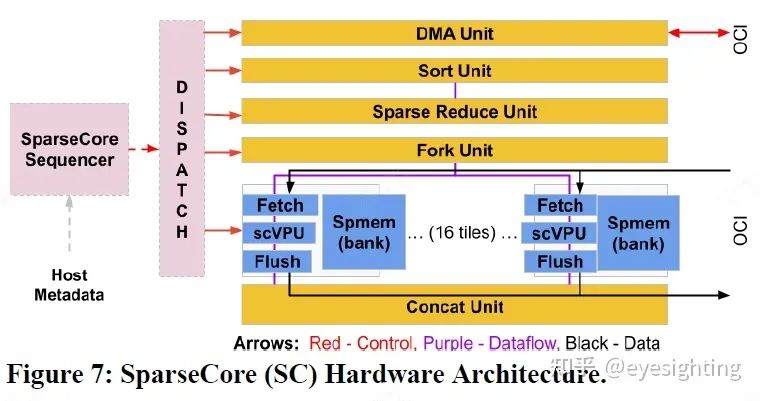
 功能特性 1).通过引入具有光学数据链路的光路交换机(OCS)来解决规模和可靠性障碍,允许 4K 节点超级计算机通过重新配置来容忍 1K CPU 主机在 0.1%–1.0% 的时间内不可用。 2).公开了 DLRM(SparseCore 或 SC)中嵌入的硬件支持,DLRM 是自 TPU v2 以来 TPU 的一部分。 3).结合了前两种功能,为超级计算机规模互连的需求添加了全对全通信模式。 编辑:黄飞
功能特性 1).通过引入具有光学数据链路的光路交换机(OCS)来解决规模和可靠性障碍,允许 4K 节点超级计算机通过重新配置来容忍 1K CPU 主机在 0.1%–1.0% 的时间内不可用。 2).公开了 DLRM(SparseCore 或 SC)中嵌入的硬件支持,DLRM 是自 TPU v2 以来 TPU 的一部分。 3).结合了前两种功能,为超级计算机规模互连的需求添加了全对全通信模式。 编辑:黄飞
-
谷歌第七代TPU Ironwood深度解读:AI推理时代的硬件革命2025-04-12 4436
-
博通与Google打造第四代TPU,传采用7纳米制程2020-08-17 4542
-
risc-v的发展历史2024-07-29 1711
-
从CPU、GPU再到TPU,Google的AI芯片是如何一步步进化过来的?2017-03-15 3671
-
CORAL-EDGE-TPU:珊瑚开发板TPU2019-05-29 3817
-
TPU透明副牌.TPU副牌料.TPU抽粒厂.TPU塑胶副牌.TPU再生料.TPU低温料2021-11-21 872
-
在Google发布TPU一年后,这款机器学习定制芯片的神秘面纱终于被揭开了。2017-04-06 905
-
Google公布Tensor人工智能服务器芯片TPU技术细节2017-04-08 1289
-
谷歌出手AI芯片和公有云市场 TPU首次对外全面开放2018-02-13 1411
-
Google发布人工智能芯片TPU 32018-05-14 3617
-
Google准备开始销售新款机器学习芯片?2018-08-08 4047
-
Google LLC的Coral产品线是一系列微型芯片模块2020-03-24 4139
-
TPU和NPU的区别2023-08-27 13314
-
如何适配新架构?TPU-MLIR代码生成CodeGen全解析!2023-11-02 3305
-
Google推出第七代TPU芯片Ironwood2025-04-16 2166
全部0条评论

快来发表一下你的评论吧 !
