

深度解析CLIP在视觉语言理解与定位任务上的无监督迁移研究
人工智能
描述
CLIP-VG: Self-paced Curriculum Adapting of CLIP for Visual Grounding
论文题目:CLIP-VG: Self-paced Curriculum Adapting of CLIP for Visual Grounding
发表期刊:IEEE Transactions on Multimedia 一区顶刊
工作内容:基于自步课程学习实现多模态大模型CLIP在多模态视觉语言理解与定位任务上的无监督迁移研究

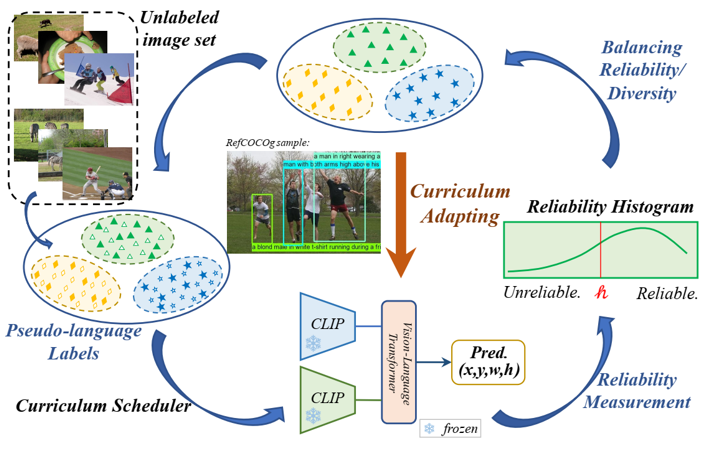
图1。我们提出的CLIP-VG的主要思想,它在自步课程自适应的范式中使用伪语言标签来自适应CLIP,从而实现在视觉定位的任务上得迁移学习。
论文摘要:
视觉定位(VG)是视觉和语言领域的一个重要课题,它涉及到在图像中定位由表达句子所描述的特定区域。为了减少对人工标记数据的依赖,无监督的方法使用伪标签进行学习区域定位。然而,现有的无监督方法的性能高度依赖于伪标签的质量,并且这些方法总是遇到多样性有限的问题。为了利用视觉和语言预训练模型来解决定位问题,并合理利用伪标签,我们提出了一种新颖的方法CLIP-VG,它可以使用伪语言标签对CLIP进行自步式地课程自适应。我们提出了一个简单而高效的端到端网络架构来实现CLIP到视觉定位的迁移。在以CLIP为基础的架构的基础上,我们进一步提出了单源和多源课程自适应算法,这些算法可以逐步找到更可靠的伪语言标签来学习最优模型,从而实现伪语言标签的可靠性和多样性之间的平衡。我们的方法在单源和多源场景下的RefCOCO/+/g数据集上都明显优于当前最先进的无监督方法,提升幅度分别为从6.78%至10.67%和11.39%至14.87%。此外,我们的方法甚至优于现有的弱监督方法。代码和模型可在https://github.com/linhuixiao/CLIP-VG上获得。
论文引言:
视觉定位(Visual Grounding,VG),又称指代表达理解(Referring Expression Comprehension,REC),或短语定位(Phrase Grounding, PG),是指在特定图像中定位文本表达句子所描述的边界框(bounding box,即bbox)区域,这一技术已成为视觉问答[6]、视觉语言导航[7]等视觉语言(Vision-Language, V-L)领域的关键技术之一。
由于其跨模态的特性,定位需要同时理解语言表达和图像的语义,这一直是一项具有挑战性的任务。考虑到其任务复杂性,现有的方法大多侧重于全监督设置(即,使用手工三元组数据作为监督信号)。然而,有监督的定位要求需要高质量的手工标注信息。具体来说,表达句子需要与bbox配对,同时在指代上是唯一的,并且需要具有丰富的语义信息。为了减少对手工劳动密集的标记数据的依赖,弱监督(即,仅给定图像和查询对,没有配对的bbox)和无监督定位(即,不使用任何与任务相关的标注信息去学习定位图像区域)最近受到越来越多的关注。现有的无监督定位方法主要是利用预训练的检测器和额外的大规模语料库实现对未配对数据的指代定位。最先进的(SOTA)无监督方法提出使用人工设计的模板和空间关系先验知识来匹配目标和属性检测器获得的结果,以及相应的目标bbox。这将生成表达式和bbox伪对,它们被用作为伪标签,进而以监督的方式学习定位模型。然而,这些现有方法中的伪标注信息的有效性严重依赖于总是在特定数据集上预训练的目标或属性检测器。这可能会限制语言分类和匹配模式的多样性,以及上下文语义的丰富度,最终损害模型泛化能力。
在过去的几年里,视觉语言预训练(Vision-Language Pre-trained, VLP)基础模型(如CLIP)通过使用少量任务相关数据来进行迁移或提示的范式,在许多下游任务上取得了令人振奋的结果。这些基础模型的主要优点是,它们可以通过自监督约束从现成的web数据和各种下游任务数据(例如,BeiT3)中学习一般通用的知识。这启发我们考虑转移VLP模型(即,本工作中使用CLIP),以无监督的方式解决下游定位任务。然而由于缺乏与任务相关的标记数据,因此,这是一项具有挑战性的任务。一个直接的解决方案是利用以前的无监督定位方法中生成的伪标签来微调预训练的模型。然而,这将影响预训练模型的泛化能力,因为特定的伪标签和真实特定任务的标签之间存在差距。
在本文中,我们提出了CLIP-VG,如图1所示,这是一种新颖的方法,可以通过利用伪语言标签来解决视觉定位问题,对CLIP进行自步地课程自适应。首先,我们提出了一个简单而高效的端到端纯Transformer的仅编码器的网络架构。我们为了实现CLIP向视觉定位的任务迁移,只需要调整少量的参数,花费最少的训练资源。其次,为了通过寻找可靠的伪标签来实现对基于CLIP的网络架构的更稳定的自适应迁移,我们提出了一种评估实例级标签质量的方案和一种基于自步课程学习(SPL)的渐进自适应算法,即可靠性评估(III-C部分)和单源自步自适应(SSA)算法(III-D部分)。实例级可靠性被定义为通过特定标签源学习的评估器模型正确预测的可能性。具体而言,我们学习了一个初步的定位模型作为可靠性评估器,以CLIP为伪标签的主干,然后对样本的可靠性进行评分,构建可靠性直方图(RH)。接下来,根据构建的RH,以自步的方式执行SSA算法,逐步采样更可靠的伪标签,以提高定位的性能。为了有效地选择伪配对的数据子集,我们设计了一种基于改进的二叉搜索的贪心样本选择策略,以实现可靠性和多样性之间的最优平衡。
我们所提出的CLIP-VG的一个主要优点是其渐进式自适应框架不依赖于伪标签的特定形式或质量。因此,CLIP-VG可以灵活扩展,访问多个伪标签源。在多源场景中,我们首先独立学习每个伪标签源的特定源的定位模型。然后,我们提出了源级复杂度的评估标准。具体而言,在SPL的不同步骤中,我们根据每个表达式中实体的平均数量,从简单到复杂逐步选择伪标签源。在SSA的基础上,我们进一步提出了特定源可靠性(SR)和跨源可靠性(CR),以及多源自适应(MSA)算法(第3 - e节)。特定源的可靠性定义为使用当前标签源学习的定位模型正确预测当前伪标签的可能性近似。相应的,交叉源可靠性的定义是通过与其他标签源学习的定位模型正确预测当前源伪标签的可能性近似。因此,整个方法可以渐进式地利用伪标签来学习易难课程范式中的定位模型,最大限度地利用不同源的伪标签,保证基础模型的泛化能力。
在RefCOCO/+/g、RefitGame和Flickr30K Entities这五个主流测试基准中,我们的模型在单源和多源场景下的性能都明显优于SOTA无监督定位方法Pseudo-Q,分别达到6.78% ~ 10.67% 和11.39% ~ 14.87%。所提出的SSA算法和MSA算法的性能增益为3%以上。此外,我们的方法甚至优于现有的弱监督方法。与全监督SOTA模型QRNet相比,我们仅使用其更新参数的7.7% 就获得了相当的结果,同时在训练和推理方面都获得了显著的加速,分别高达26.84倍和7.41倍。与最新报道的结果相比,我们的模型在速度和能效方面也达到了SOTA。综上所述,本文的贡献有四个方面:
-
据我们所知,我们是第一个使CLIP实现无监督视觉定位的。我们的方法可以将CLIP的跨模态学习能力转移到视觉定位上,而且训练成本很小。
-
我们是第一个在无监督视觉定位中引入自步课程学习的方法。我们提出的可靠性评估和单源自步自适应的方法可以通过在由易到难的学习范式中使用伪标签逐步增强基于CLIP的视觉定位模型。
-
我们首先提出了多源自步自适应算法来扩展了我们的方法,同时可以获取多个伪标签源的信息,可以灵活地提高语言分类的多样性。
-
我们进行了大量的实验来评估我们方法的有效性。结果表明,我们的方法在无监督环境下取得了显著的改进,同样,我们的模型在全监督环境下也具有一定的竞争力。
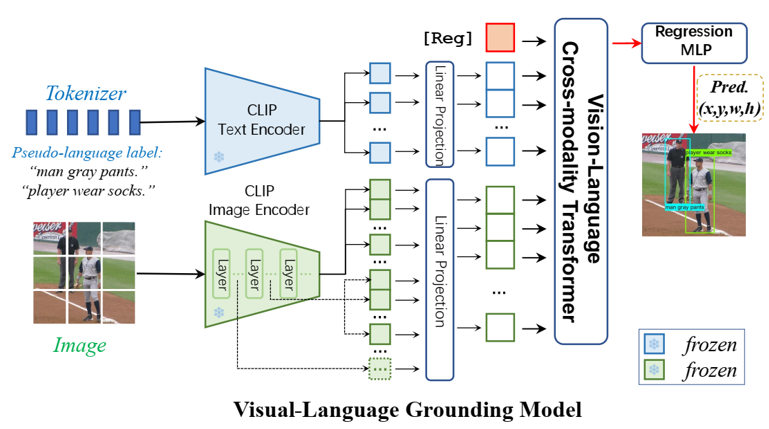
图2. 我们的CLIP-VG模型架构(III-B部分)作为视觉语言定位模型来实现CLIP的自步度课程自适应。
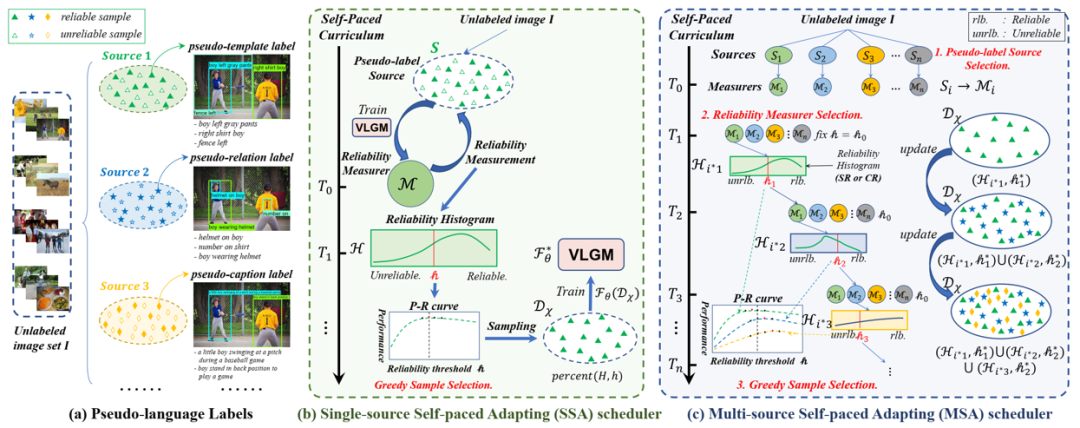
图3。利用伪语言标签和自步课程学习实现无监督视觉定位。(a)伪语言标签的例子(不同伪语言标签的来源在第IV-A节中进行了描述)。(b)单源自步自适应(Single-source self-paced Adapting, SSA)利用视觉语言定位模型(VLGM)对伪模板标签进行可靠性评估和贪婪样本选择,通过寻找可靠的伪标签实现对CLIP更稳定的自适应迁移。(c)多源自适应(Multi-source Self-paced Adapting, MSA)在SSA的基础上进一步提出了特定源可靠性(SR)和跨源可靠性(CR)。它依次进行伪标签源选择、可靠性评估器选择和贪婪样本选择,从而达到可靠性和多样性的最佳平衡。
表1. 在RefCOCO/+/g三个数据集上基于top-1精度的SOTA方法对比结果
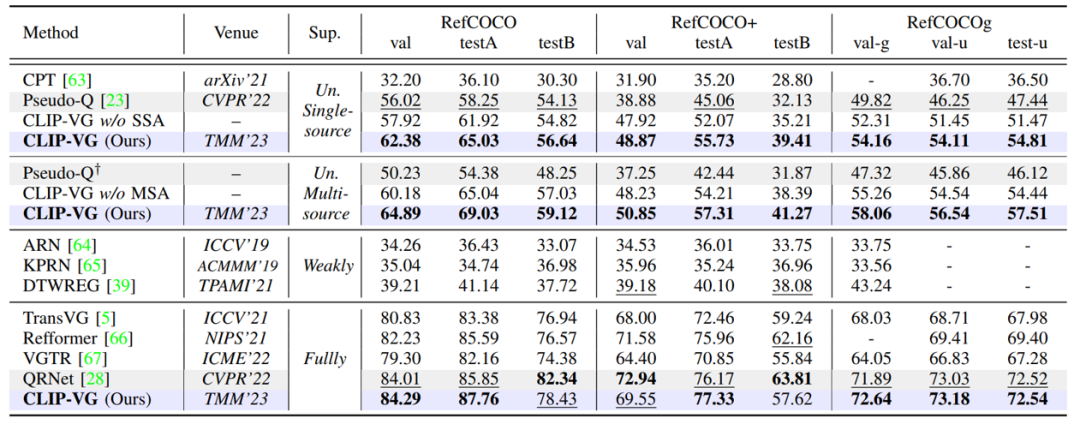
表1. 在Rferit Game和Flickr两个数据集上基于top-1精度的SOTA方法对比结果
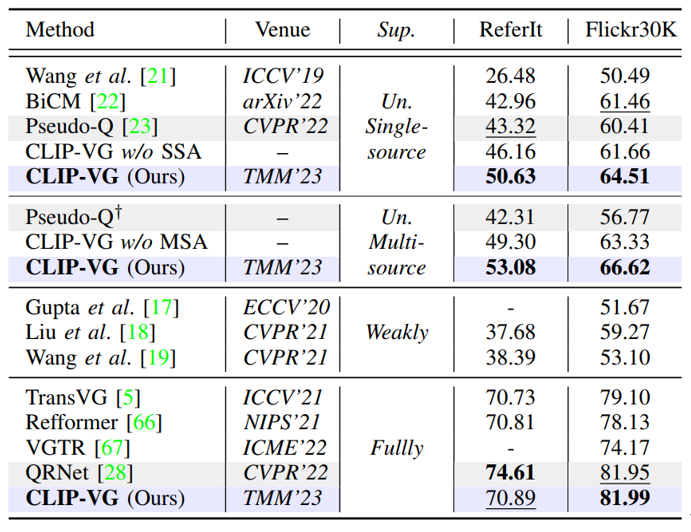
表3. 模型的能效、推理训练速度优势对比

编辑:黄飞
-
基于将 CLIP 用于下游few-shot图像分类的方案2022-09-27 7092
-
【《大语言模型应用指南》阅读体验】+ 基础知识学习2024-08-02 3420
-
深度学习中的机器视觉(网络压缩、视觉问答、可视化等)2019-07-21 4913
-
语义理解和研究资源是自然语言处理的两大难题2019-09-19 2610
-
定位技术原理解析2020-05-04 2448
-
C语言深度解析2023-09-28 894
-
无监督训练加微小调整,只用一个模型即可解决多种NLP2018-06-13 6750
-
3D 点云的无监督胶囊网络 多任务上实现SOTA2021-01-02 3159
-
半监督学习,无监督学习,迁移学习,表征学习以及小样本学习2021-01-18 9751
-
视觉问答与对话任务研究综述2021-04-08 1315
-
利用深度学习在工业图像无监督异常定位方面的最新成果2022-07-31 4443
-
谷歌重磅新作PaLI-3:视觉语言新模型!更小、更快、更强2023-10-20 3980
-
如何利用CLIP 的2D 图像-文本预习知识进行3D场景理解2023-10-29 3294
-
深度学习中的无监督学习方法综述2024-07-09 3390
-
VLM(视觉语言模型)详细解析2025-03-17 10427
全部0条评论

快来发表一下你的评论吧 !
