

可直接访问的分离式内存DirectCXL应用案例
存储技术
描述
本文来自ATC 22,由于出色的硬件异构管理和资源分解能力,CXL 等新型高速缓存一致性互连协议近来备受关注。本文作者提出了可直接访问的分离式内存,DirectCXL,并自行设计了CXL内存控制器、支持CXL的处理器及相关软件运行时以实现DirectCXL。它通过 CXL 的内存协议 (CXL.mem) 直接连接主机处理器复合体和远程内存资源。 由于 DirectCXL 不需要在主机内存和远程内存之间进行任何数据复制,因此它可以向用户展示远程端分离式内存资源的真实性能,相较于RDMA实现的分离式内存访问速度提升8.2x,在真实工作负载上提升最大达3.7x。
01 背景
分离式内存由于可以提升内存利用率而备受关注,现有的分离式内存可以根据它们如何管理数据分为1)page-based和2)object-based。Page-based方法基于虚拟内存技术,当发生缺页中断时从远端交换内存页,无需修改程序代码。而object-based方法则需要使用数据库(如KV数据库)来管理内存对象,需要大量的源码级修改。 尽管还有许多变种,但所有现有的方法都需要类似RDMA的方式使用网络从远端内存移动数据到主机端内存,数据移动和伴随而来的操作(如页面缓存管理)引入了冗余和软件开销,这使得分离式内存的延迟比本地DRAM高多个数量级。
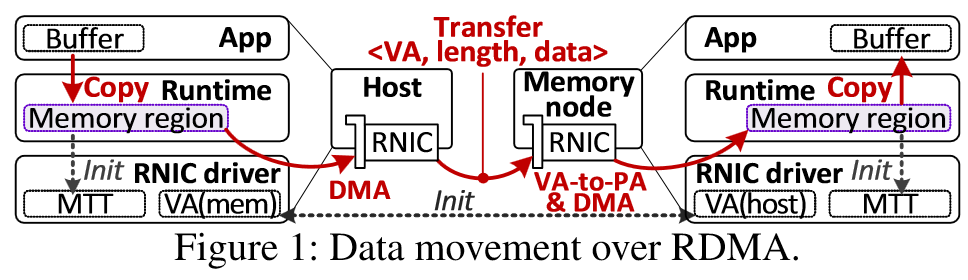
CXL(Compute Express Link)是一个行业支持的缓存一致性互联协议,其下有三个子协议: CXL.io使CXL可运行在标准PCIe物理层之上,PCIe5.0的带宽已经达到63GB/s,这足以为远端内存访问服务。 CXL.cache允许CXL设备缓存主机端的内存。 CXL.mem允许主机使用Load/Store语义像访问本地内存一样访问设备端的内存。 因此CXL在实现分离内存方面表现出巨大的潜力。 02 背景 当前工作中基于网络的数据拷贝严重影响了性能,因此DirectCXL直接将远端内存资源与CPU Compute Complex相连,允许用户以Load/Store指令访问远端内存。
1. 通过CXL连接主机和内存
现有的分离式内存技术仍然需要在远端内存侧设置计算资源,这是因为所有DRAM模块及其接口都设计为无源外设,需要计算资源控制。相比之下,CXL.mem允许主机计算资源通过 PCIe 总线 (FlexBus) 直接访问底层内存;它的工作方式类似于本地DRAM,连接到其系统总线。 在当前架构中,设备的 CXL 控制器解析传入的基于 PCIe 的 CXL 数据包,称为 CXL flit,将其信息(地址和长度)转换为 DRAM 请求,并使用 DRAM 控制器从底层 DRAM 为它们提供服务。
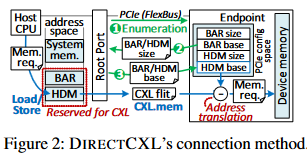
具体来说,主机CPU系统总线包括了多个CXL Root Port(RPs),可以将一个或多个CXL设备作为Endpoint(EP)设备连接。作者实现的主机端驱动在启动时通过查询其base address register(BAR)寄存器和host-managed memory(HDM)大小来枚举CXL设备。根据检索到的大小,内核驱动将BAR和HDM映射到主机的保留内存地址空间中,并通知底层的CXL设备它们被映射到了主机内存。当主机发送Load/Store指令时,请求被送到相应的RP,RP将请求转换为CXL Flit。最后CXL内存控制器将目标内存地址减去基地址就得到了CXL设备中实际的内存地址,下发到DRAM控制器获取数据,结果通过CXL Switch和FlexBus返回到主机。由于该过程中没有数据拷贝和软件干预,因此DirectCXL可以提供低延迟的远端内存访问。 DirectCXL也可以通过交换机实现更广泛范围的互连,在CXL标准中CXL Switch作用类似于网络交换机。
2. DirectCXL的软件运行时
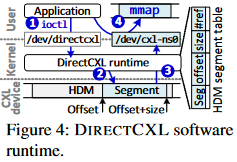
与 RDMA 相反,在主机和 CXL 设备之间创建虚拟层次结构后,主机上运行的应用进程可以通过引用 HDM 的内存空间直接访问 CXL 设备。但是,它需要软件运行时/驱动进程来管理底层 CXL 设备,并在应用进程的内存空间中公开其 HDM。因此,作者提供了DIRECTCXL 运行时,它只是将 HDM 的地址空间拆分为多个段,称为CXL命名空间。然后,DitectCXL 运行时允许应用进程以内存映射文档 (mmap) 的形式访问每个 CXL 命名空间。
03 原型实现
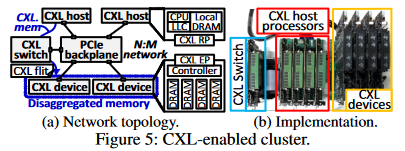
由于还没有已经上市的支持CXL的处理器、设备和OS,因此作者自行实现了DirectCXL。每个CXL设备基于定制的add-in-card(AIC)CXL 内存刀片构建,该刀片采用 16 纳米 FPGA 和 8 个不同的 DDR4 DRAM 模块(64GB)。作者使用FPGA实现了一个CXL控制器和八个DRAM控制器用以管理CXL EP和内部DRAM通道。作者实现使用RISC-V ISAs的内部主机处理器以支持CXL,它采用四个无序内核,其最后一级缓存 (LLC) 实现 CXL RP。每个支持 CXL 的主机处理器都在高性能数据中心加速器卡中实现,充当主机的角色,可以单独运行 Linux 5.13 和 DIRECTCXL 软件运行时。通过 PCIe 背板向四个主机公开四个 CXL 设备(32 个 DRAM 模块)。 04 实验 下图6展示了RDMA和DirectCXL读64B数据的延迟划分。 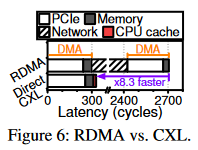 可以看到RDMA需要两次DMA操作,InfiniBand网络开销占到了总延迟的78.7%。相比之下DirectCXL由于不需要网络和拷贝,快8.3倍。
可以看到RDMA需要两次DMA操作,InfiniBand网络开销占到了总延迟的78.7%。相比之下DirectCXL由于不需要网络和拷贝,快8.3倍。
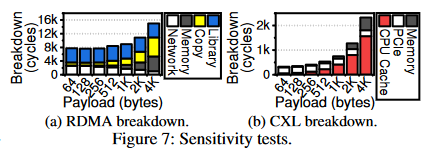
图7a将RDMA访问延迟划分为软件库、拷贝、内存访问和网络,当负载较小时,RDMA库开销占比较大,随着负载增大,拷贝到MR的数据也越来越多,Copy占比逐渐增大。注意网络开销并未降低,当负载增大时网络传输和内存访问可同时进行,重叠部分被划分到内存访问;7b将DirectCXL访问延迟划分为CPU Cache、PCIe和内存访问。随着负载增大,CPU Cache拖慢了访问延迟,这是由于作者定制的CPU中miss status holding registers(MSHR,用于实现非阻塞式缓存)只能处理16个并发内存miss,因此随着组成大负载的内存请求(64B)越来越多,会导致CPU停顿。
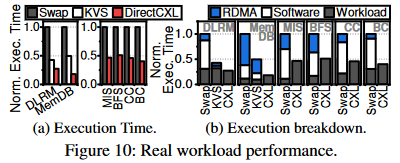
在真实工作负载上,DirectCXL的性能提升达到了3倍和2.2倍。 05 总结 在本文中,作者提出了通过CXL的内存协议(CXL.mem)连接主机处理器复杂和远程内存资源的DirectCXL。其实际系统评估结果表明,当工作负载可以享受主机处理器的缓存时,DirectCXL 的分离式内存资源可以表现出类似 DRAM 的性能。对于实际应用进程,它的性能平均比基于 RDMA 的方法高 3×。
编辑:黄飞
-
基于CXL的直接访问高性能内存分解框架2022-09-23 2005
-
1831B直接访问垂直操作说明2018-10-26 944
-
如何通过pcie链接访问外部处理器的内存?2020-04-22 2109
-
DirectCXL内存分解原型设计实现2022-11-15 1321
-
咖啡机缺水提醒方案-分离式液位传感器2023-06-13 4139
-
分离式液位传感器代替浮球传感器的优势2023-06-20 1326
-
分离式热管换热器的综合利用2009-12-10 1005
-
UCOS扩展例程-UCOSIII直接访问共享资源区2016-12-14 1706
-
行动式内存第三季或将持平,分离式行动内存价格或将小涨2018-06-25 1162
-
智能开关柜的SCR分离式操作机构2018-10-12 2739
-
分离式独立按键电路原理图免费下载2019-08-08 1426
-
如何实现SIMATIC HMI对驱动参数的直接访问呢2022-08-10 3242
-
InfiniBand和远程直接访问是什么,如何进行配置2022-11-25 2825
-
实现HMI直接访问驱动参数的方法2023-07-11 2015
-
STM32L4直接访问内存模块(DMA)介绍2023-08-01 841
全部0条评论

快来发表一下你的评论吧 !
