

如何本地部署大模型
描述
近期,openEuler A-Tune SIG在openEuler 23.09版本引入llama.cpp&chatglm-cpp两款应用,以支持用户在本地部署和使用免费的开源大语言模型,无需联网也能使用!
大语言模型(Large Language Model, LLM)是一种人工智能模型,旨在理解和生成人类语言。它们在大量的文本数据上进行训练,可以执行广泛的任务,包括文本总结、翻译、情感分析等等。openEuler通过集成llama.cpp&chatglm-cpp两款应用,降低了用户使用大模型的门槛,为Build openEuler with AI, for AI, by AI打下坚实基础。
openEuler技术委员会主席胡欣慰在OSSUMMIT 2023中的演讲
应用简介
1. llama.cpp是基于C/C++实现的英文大模型接口,支持LLaMa/LLaMa2/Vicuna等开源模型的部署;
2. chatglm-cpp是基于C/C++实现的中文大模型接口,支持ChatGlm-6B/ChatGlm2-6B/Baichuan-13B等开源模型的部署。
应用特性
这两款应用具有以下特性:
1. 基于ggml的C/C++实现;
2. 通过int4/int8等多种量化方式,以及优化KV缓存和并行计算等手段实现高效的CPU推理;
3. 无需 GPU,可只用 CPU 运行。
使用指南
用户可参照下方的使用指南,在openEuler 23.09版本上进行大模型尝鲜体验。
llama.cpp使用指南如下图所示:
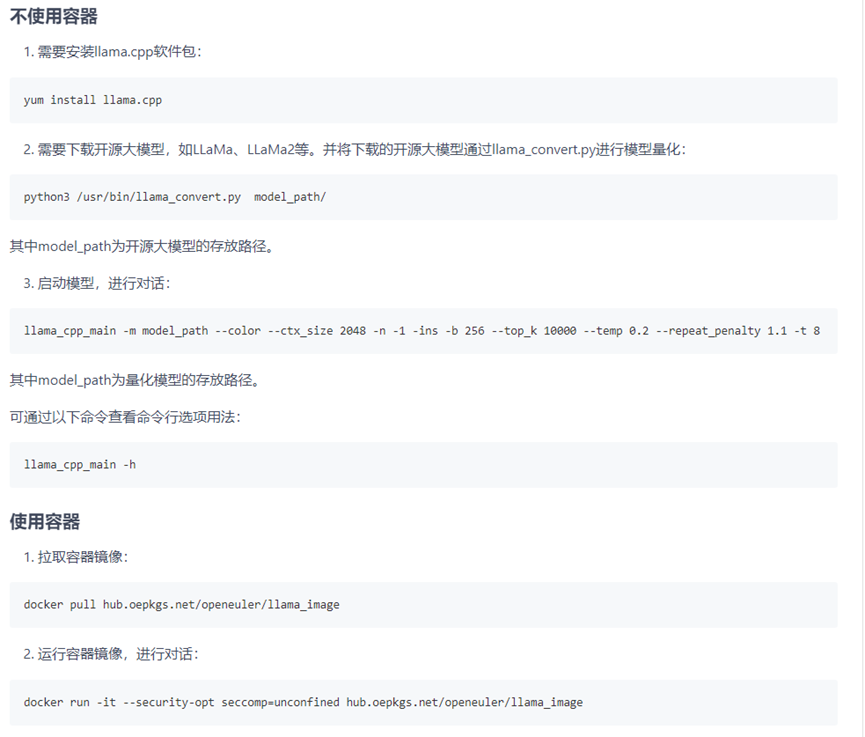
llama.cpp使用指南
正常启动界面如下图所示:
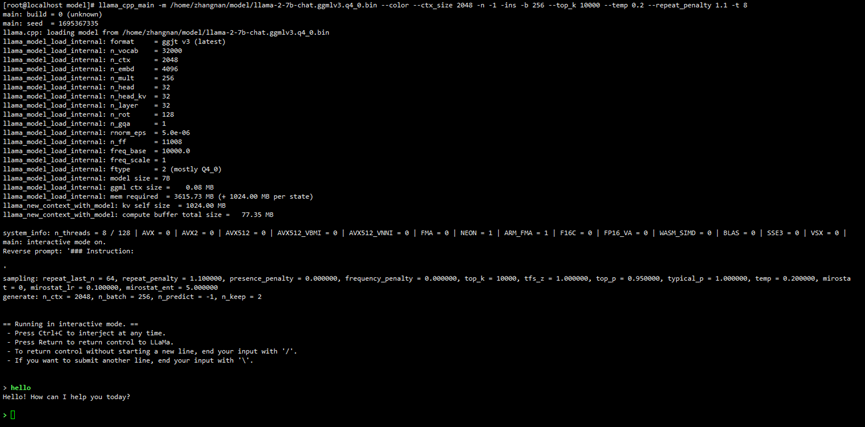
LLaMa启动界面
2. chatlm-cpp使用指南如下图所示:

chatlm-cpp使用指南
正常启动界面如下图所示:
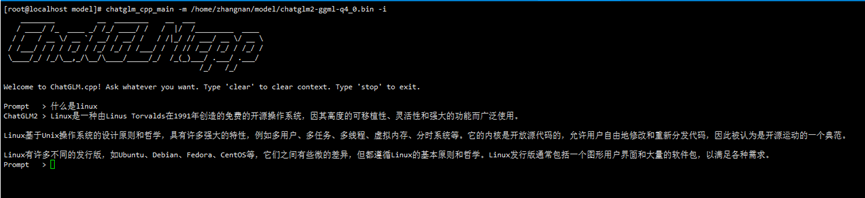
ChatGLM启动界面
规格说明
这两款应用都可以支持在CPU级别的机器上进行大模型的部署和推理,但是模型推理速度对硬件仍有一定的要求,硬件配置过低可能会导致推理速度过慢,降低使用效率。
以下是模型推理速度的测试数据表格,可作为不同机器配置下推理速度的参考。
表格中Q4_0,Q4_1,Q5_0,Q5_1代表模型的量化精度;ms/token代表模型的推理速度,含义为每个token推理耗费的毫秒数,该值越小推理速度越快;
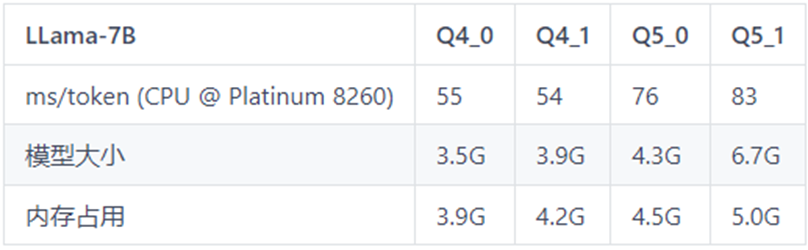
表1 LLaMa-7B测试表格
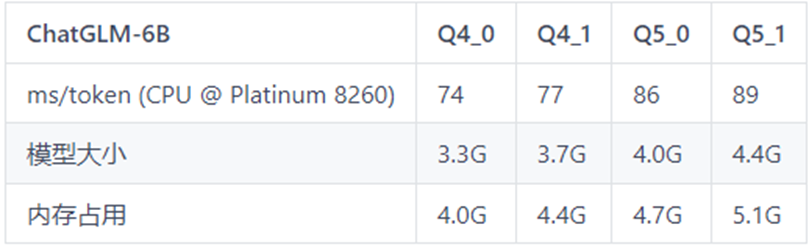
表2 ChatGLM-6B测试表格
欢迎用户下载体验,玩转开源大模型,近距离感受AI带来的技术革新!
感谢LLaMa、ChatGLM等提供开源大模型等相关技术,感谢开源项目llama.cpp&chatglm-cpp提供模型轻量化部署等相关技术。
审核编辑:汤梓红
-
如何在ZYNQ本地部署DeepSeek模型2025-12-19 8106
-
ElfBoard技术实战|ELF 2开发板本地部署DeepSeek大模型的完整指南2025-05-16 2915
-
部署基于嵌入的机器学习模型2022-11-02 3636
-
本地化ChatGPT?Firefly推出基于BM1684X的大语言模型本地部署方案2023-09-09 2860
-
源2.0适配FastChat框架,企业快速本地化部署大模型对话平台2024-02-29 2015
-
llm模型本地部署有用吗2024-07-09 2048
-
用Ollama轻松搞定Llama 3.2 Vision模型本地部署2024-11-23 5025
-
DeepSeek R1模型本地部署与产品接入实操2025-04-19 951
-
曙光顺利完成DeepSeek大模型本地化多点私有部署2025-02-22 1578
-
行芯完成DeepSeek-R1大模型本地化部署2025-02-24 1523
-
博实结完成DeepSeek大模型本地化部署2025-03-19 1556
-
如何本地部署NVIDIA Cosmos Reason-1-7B模型2025-07-09 1155
-
技嘉与趋境科技联合部署AMaaS平台 推动本地大模型应用加速落地2026-03-12 274
-
本地部署OpenClaw,只要500元的开发板?2026-03-20 2569
全部0条评论

快来发表一下你的评论吧 !
