

探讨人工智能发展和国产FPAI芯片研究方向
人工智能
描述
要说2023年最牛技术,ChatGPT说第二估计也没人敢说第一,它的横空出世将整个人工智能技术推向了一个新的高度,NVidia也因此赚的那是一个盆满锅满,今天小编就给各位老铁简单捋捋人工智能的发展和国产最新FPAI芯片研究方向。
1ChatGPT和后摩尔时代
2023年,人工智能领域发生了一件里程碑式的事件:OpenAI发布了基于大型语言模型的聊天机器人ChatGPT,这是一个可以响应人类指令的聊天机器人,可以完成从写文章、做数学题到调试代码的各种任务。ChatGPT的发布刷新了人们对AI的认知,标志着生成式人工智能的商业化启动,它不仅改变了AI研究和技术开发的方式,还对社会产生了深远影响。然而,人工智能并不是一项新兴的技术,而是起源于20世纪60年代,经过半个多世纪的发展,经历了符号主义、连接主义和行为主体三次浪潮的相互交织,现阶段大家普遍认为,人工智能 = 深度学习 + 大规模计算 + 大数据。深度学习是一种特殊的机器学习,它需要以大量的数据为基础,通过“训练”得到各种参数(模型),然后使用训练得到的模型进行推理,得到最终的结果。因此,模型的参数越多,训练和推理所需要的算力就越大。随着深度学习的发展,AI领域对算力的需求以每年超过10倍的速度增长,以ChatGPT为例,其初版基于的大模型GPT-3是一个有着1750亿个参数的巨型模型,而最新版基于的GPT-4,其参数量竟然达到了丧心病狂的1.76万亿(网传)。
人工智能的实现需要算力,而算力的的实现则需要芯片的支撑,这是人工智能进行发展并实现产业化的关键。仍以GPT-3为例,1750亿参数,1000亿词汇语料库,需要1000块英伟达A100 GPU训练一个月。2023年,在芯片领域同样发生了一件大事,3月24日,摩尔定律的提出者,戈登·摩尔先生与世长辞,享年94岁。摩尔曾在1965年对集成电路的发展做出了著名的预测:集成电路上可以容纳的晶体管数目大约每经18到24个月便会增加一倍,即处理器的性能大约每两年翻一倍,同时价格降为原来的一半,这便是大名鼎鼎的摩尔定律。
虽然摩尔定律并不是正式定义的科学定律,而是摩尔对他所观察到的趋势的归纳总结,但是在提出后的半个世纪中,成功预测了集成电路的发展趋势。以英特尔为例,从1971年到2008年,在过去的几十年里,英特尔微处理器芯片上最大晶体管的数量每两年翻一番,而且特征尺寸以每年15%的速度缩减,每5年缩减一半。受益于特征尺寸的缩减,即使保持硬件架构不变,时钟频率也能获得大幅度的提升。仍以英特尔为例,从1990年到2002年,其微处理器的时钟频率不到两年就翻一番,当然这其中也包含架构升级带来的提升。
如果照这个趋势发展下去,那么2008年时,处理器的时钟频率就会提升到30GHz,然而实际上,2002年后,英特尔处理器时钟频率的增长就逐步放缓,并且在2005年达到顶峰。2004年11月,英特尔宣布取消时钟频率4GHz奔腾处理器的计划,转而研究多核架构。是的,虽然半个多世纪以来,摩尔定律为集成电路的发展描绘了美好的蓝图,但是由于物理效应、功耗等多方面的限制,摩尔定律不可能一直延续下去。物理效应方面,随着工艺节点不断缩小,晶体管的尺寸已经接近原子尺度,一些量子效应和噪声效应会影响晶体管的正常工作。例如,当闸极长度足够短时,就会发生量子隧穿效应,导致漏电流增加,同时也会增加功耗和温度。
另外,由于晶体管中原子的数量越来越少,杂质涨落、界面粗糙度、晶格不匹配等因素也会造成晶体管之间的性能差异。功耗方面,随着集成度的提高,芯片上的晶体管数量和时钟频率也相应增加,这会导致芯片的功耗和散热问题变得更加严重。功耗主要包括静态功耗和动态功耗两部分。
静态功耗是指晶体管在关闭状态下仍然存在的漏电流所消耗的功率,它与量子隧穿效应有关。动态功耗是指晶体管在开关状态下由于电容充放电所消耗的功率,它与时钟频率和电压有关。除此之外,经济效益也是需要考虑的一个方面,随着工艺节点的进步,制造芯片所需的设备、材料和人力成本也不断增加,这会影响芯片的价格和市场竞争力。
早在摩尔先生去世之前十几年,业界就认识到摩尔定律的发展逐渐放缓甚至将要被打破,于是提出后摩尔时代这个概念,力求以后的集成电路发展寻找新的技术路线。目前,业界提出了延续摩尔(More Moore)、扩展摩尔(More than Moore)、超越摩尔(Beyond Moore)和丰富摩尔(Much Moore)等四种主要的发展方向。由于芯片的时钟频率不能继续提升,因此处理器的设计从单核超频逐渐向多核并行转变,通过提供多个相同的核心,将计算任务分解到不同的核心上同时计算,从而提高处理性能。然而,随着处理器面临的场景和处理的任务越来越复杂,不同的任务可能具有不同的性能和能效限制。
没有任何处理器架构适合所有的场景,因此,多核处理器的设计从多核同构逐渐向多核异构转变,即处理器中的核心具有不同的架构,比如一些是高性能的、一些是低功耗的,或者一些是通用的、一些是专用的。
2后摩尔时代下的AI芯片
如前所述,以ChatGPT为代表的AI应用需要极大的算力作为支撑,而算力作为人工智能的三大要素之一,需要AI芯片的支撑。虽然,从广义上来说,所有面向AI应用的芯片都可以称为AI芯片,但是人们普遍认为,AI芯片是针对AI算法做了特殊加速设计的芯片。由于深度学习需要很高的并行计算能力,而CPU的架构往往无法充分满足人工智能高性能并行计算需求,因此需要发展适合AI算法的专属芯片。
目前常见的AI加速芯片按照技术路线可以分为GPU、FPGA和ASIC三类:1)GPU:由数以千计的更小、更高效的核心组成大规模并行计算架构,适合用于大量并行计算。2)FPGA:一种半定制芯片,灵活性强集成度高,但运算量小且量产成本高,适用于算法更新频繁的专用领域3)ASIC:领域专用芯片,专用性非常强,开发周期较长且难度极高,适合市场需求量大的专用领域。下表更详细的对比了三者的优缺点:
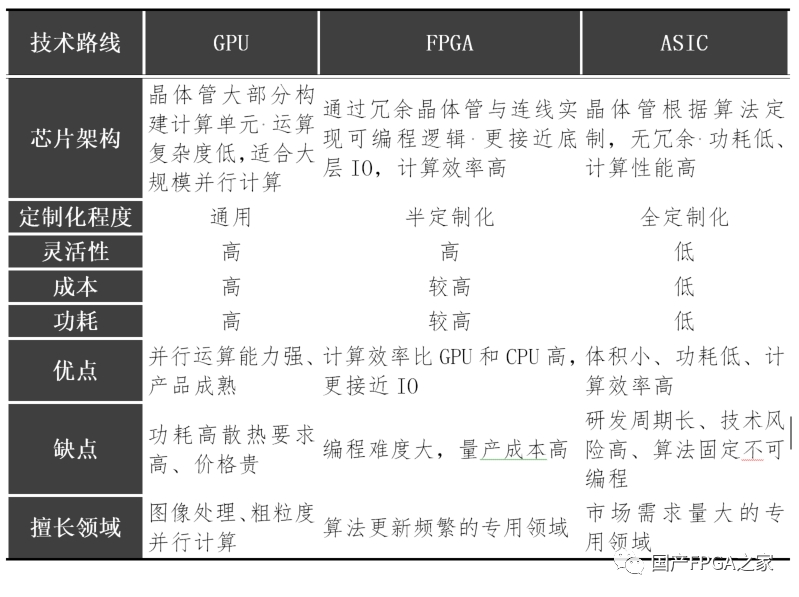
虽然说CPU不能满足AI算法的性能要求,因此不能作为AI专用芯片,但是实际上真正的AI应用场景都需要CPU的参与才能完成。这是因为CPU具有其他AI专用芯片所不具备的通用处理能力,而在AI应用中,数据的前处理、计算过程的流程控制以及计算结果的后处理等等,都需要CPU的通用处理能力才能完成。如前所述,在后摩尔时代,处理器的设计多以多核异构为主,各个处理单元充分发挥自己所长,大家相互配合从而高效地完成计算。而AI处理器作为后摩尔时代芯片设计中的代表,自然也需要采用这种异构多核的设计方式。当然,不同的AI处理器面向的场景不同,具体的异构设计也不相同。
以边缘端的AI处理器为例,其面向的场景需要低功耗、高性能以及数据处理的实时性,因此可以采用传统的SoC设计外加专用的AI处理器(ASIC),其中SoC中的CPU和外设分别提供了通用处理和IO交互等能力,而专用AI处理器则为AI算法进行加速,二者结合兼顾了在AI计算场景中的高性能和低功耗。然而,美中不足的是,AI专用处理器虽然性能高,但是灵活性不足,其所支持的算法在设计完成时便已确定,后期无法灵活的添加;而AI算法的发展日新月异,新算子层出不穷,只靠AI处理器恐怕难以招架。
如果能够在这套系统中再添加一片FPGA,那么灵活性则会极大的提高。如果遇到不支持的算法或者不能满足的(IO)性能需求,只需要通过FPGA的可编程逻辑进行现场定制开发,就能轻易的支持。3FPAI = FPGA + SOC + AI如上所述,对于边缘端的AI处理器,采用FPFA、SoC和专用AI处理器相结合的设计,便能兼顾通用性、灵活性和能效,我们不妨将以上架构命名为FPAI,即 FPAI = FPGA + SoC + AI。以上架构虽然好,但是由于涉及到FPGA的集成,因此实际设计和生产的难度都比较大。万幸的是,某国内厂商敢为人先,已经率先推出了采用FPAI架构的AI处理器。该芯片的架构如下图所示:
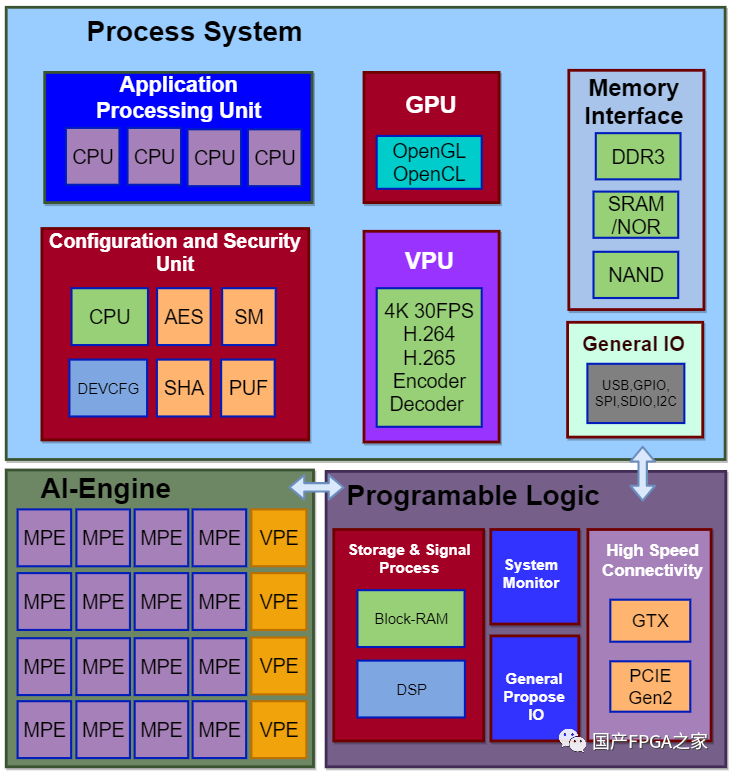
该芯片主要包含了以下三部分:
1)处理器系统:对应FPAI架构中的SoC,主要包含多核CPU/GPU/VPU等处理器、总线、存储单元、一些通用接口和其他功能
2)AI引擎:对应FPAI架构中的AI专用处理器,包含矩阵处理引擎(MPE)、向量处理引擎(VPE)、片上存储和一些其他计算引擎。其中MPE主要用于乘累加的计算,其主要计算单元是一个32×32的MAC阵列;VPE主要用于向量的线性计算以及激活和池化等操作;片上存储用于缓存中间数据,缓解带宽压力。3)可编程逻辑:对应FPAI架构中的FPGA,包含可编程逻辑资源(BRAM, LUT, DSP),高速接口(GTH, ETH, PCIE)和DDR等。
该AI处理器支持INT8和INT16两种计算精度,分别提供27.5TOPS和6.9TOPS的算力。运行Yolov5s网络,耗时6.28ms,浮点精度为0.568,量化后的INT8精度为0.547,INT16精度为0.561。
处理器的多核异构设计会给编程带来很大的复杂度,因此一款好的AI处理器不仅要有好的性能和能效,还要提供好用的编译器来将上层AI应用便捷地部署到AI处理器上加速运行。上述FPAI架构的处理器就提供了功能强大且灵活的AI编译器“Icraft”,其整体架构如下:
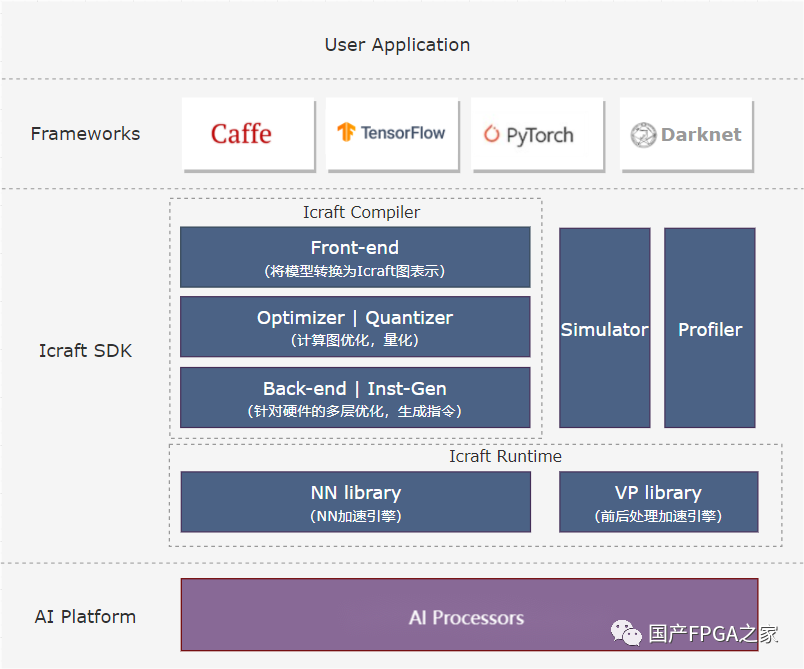
Icraft主要有以下组件:
1)前端解析:将AI框架中的模型解析到Icraft的中间层,支持的前端框架:Pytorch、Tensorflow、ONNX、Caffe、Darknet
2)量化&优化:对框架中解析出来的中间层网络进行量化和一系列优化,一步步适配到AI处理器3)指令生成:将算子转换成AI引擎的指令序列4)仿真&运行:对中间层网络进行仿真,或者将编译好的网络部署到AI处理器上运行5)分析评估:对网络的运行速度、效率等情况进行分析评估,为性能优化提供参考。Icraft对于FPAI架构中的FPGA部分提供了强有力的支持,用户可以在FPGA编程定制自己所需要的加速逻辑,并通过Icraft的自定义算子接口加入到编译流程中,这样用户可以选择将任何算子通过FPGA编程进行加速,从而灵活的满足不同场景的需求。由于篇幅限制,具体的自定义算子流程后面将专门撰文讲述。
战术总结
今天主要给大家讲述了在后摩尔时代,处理器异构多核设计的重要性。同时,针对边缘端AI处理器的设计介绍了FPAI (FPGA + SOC + AI) 架构的优势,并且具体介绍了一款已经上市的FPAI架构的加速器的硬件和软件设计。各位老铁,如果对这款FPAI芯片感兴趣的话,欢迎私信一起交流,小编我会第一时间邀请技术大拿答疑解惑!
编辑:黄飞
-
嵌入式人工智能的就业方向有哪些?2024-02-26 12463
-
人工智能是什么?2015-09-16 6459
-
人工智能发展的好与坏2017-06-24 7604
-
人工智能的就业方向详解2018-04-24 14496
-
【2019人工智能大会】大咖齐聚,共同探讨加速人工智能技术落地2019-01-21 168661
-
人工智能后续以什么形式发展?2019-08-12 2662
-
人工智能语音芯片行业的发展趋势如何?2019-09-11 5301
-
贸泽电子公司将在2021年度Empowering Innovation Together系列节目的下一集中探讨边缘人工智能背后的力量2021-07-09 1693
-
人工智能芯片是人工智能发展的2021-07-27 6727
-
人工智能对汽车芯片设计的影响是什么2021-12-17 2242
-
《移动终端人工智能技术与应用开发》人工智能的发展与AI技术的进步2023-02-17 2394
-
探讨人工智能研究趋势及应用2018-10-30 5746
-
800余专家“云端”聚焦人工智能科技发展2020-03-31 2153
-
相聚银川,共同探讨人工智能发展2020-11-04 2293
-
DSO.ai与新思科技共同探讨人工智能驱动芯片设计的发展趋势2021-08-18 6368
全部0条评论

快来发表一下你的评论吧 !
