

基于机器视觉技术的人车路特征提取中的应用案例
人工智能
描述
随着经济的快速发展,中国机动车保有量突破4.26亿辆,成为全球机动车保有量最大的国家,汽车数量的急剧增加导致各类交通事故频发,造成大量的财产损失和人员伤亡,给社会带来了巨大的安全隐患。在以往的交通事故中,由于高疲劳、接打电话分心等驾驶员状态造成的交通事故占比庞大,已经成为威胁生命安全的最大杀手。因此,如何精准预测驾驶员状态进而提高车辆驾驶安全性已成为人们关注的焦点。
有研究表明,人-车-路多模态特征融合在驾驶员状态识别中的准确率优于其他单模态的特征,其中驾驶员的生理特征和车辆运行状态的特征较易获取,但基于图像资料对驾驶员的行为及道路状况等特征的提取仍然面临着一些挑站,随着计算机视觉的发展,图像检测技术的应用已经为解决这一难题提供了有力的帮助。
01 基于驾驶员-车辆-道路信息的驾驶员状态识别
首先,驾驶场景的核心三要素为驾驶员、汽车和和道路信息。在外部信息的干扰下,以驾驶员为核心感知道路状况和车辆状态,作出正确决策并执行是保证车辆安全运行的关键。有研究表明,90% 以上的交通事故与驾驶员的状态相关,如果我们能够实时的监测到驾驶员的状态并及时给予合适的预警将会大大降低交通事故的发生概率,减少人员伤亡和财产损失。
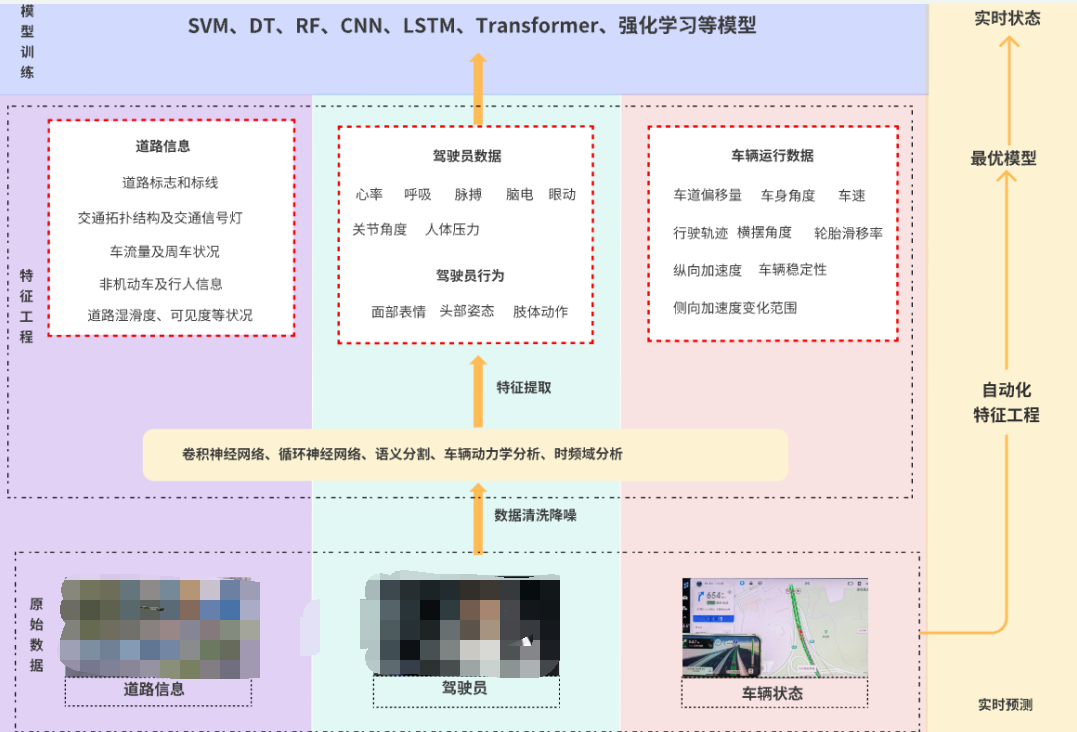
利用人-车-路多模态特征进行驾驶员状态识别的技术路线如下图所示:
1首先,将通过多模态生理、眼动、生物力学等传感器采集到的驾驶员的生理数据,踏板、GPS、IMU及CAN协议采集到的车辆运行数据,音视频采集到的驾驶员的行为及道路环境数据进行数据降噪。 2其次,利用卷积神经网络和循环神网络等深度学习算法,傅里叶变换和拉普拉斯空间滤波等生理信号分析算法,进行多模态人-车-路特征提取,并根据问卷量表等方式进行标签设置。 2接着,采用特征级融合、决策级融合或者混合融合等不同的方式对特征进行融合,采用主成分分析,方差分析等方式进行特征筛选,构建数据集。 3然后,将最终构建的数据集输入算法模型中训练,并根据模型评估结果进行参数调整,找到最优模型。 4最后,利用滑动窗口的方式对实时采集的多模态原始数据进行自动化特征提取,输入到最优模型中进行预测,输出驾驶员的实时状态。
02 机器视觉技术在人车路特征提取中的应用
针对基于图像资料对驾驶员的行为及道路状况等特征的提取问题,目前比较流行的两个思路为图像分类模型和目标检测模型,图像分类模型特别适合用于静态场景的行为判别,比如驾驶员是否系安全带。目标检测模型能够定位目标的位置,适合需要精确定位和目标检测的场景,如检测道路上的速限标志、停车标志、路线指示、交通流量等信息,下文将围绕这两个维度对相关的模型展开介绍。
01 MSA-CNN模型与驾驶员行为特征提取
驾驶员在行驶过程中的喝水、打电话和抽烟等注意力分散行为会严重的影响道路安全,对这些行为的精准识别在智能驾驶领域有着重要的意义。基于多尺度注意力机制的卷积网络模型(MSA-CNN)具备轻量化处理和视觉注意力机制等特点,轻量化技术在保证高精度的同时减少了模型的参数量,降低了计算复杂度。视觉注意力机制有利于抑制全局背景信息的干扰,更有效的抽取细粒度行为特征,上述两个特点有效的提高了该模型对驾驶员行为的辨识能力。
MSA-CNN模型结构 基于多尺度注意力机制的卷积网络模型(MSA-CNN)包括三个模块,分别是多尺度卷积模块、特征强化模块和分类模型,其中多尺度卷积模块和特征强化模块是其核心。
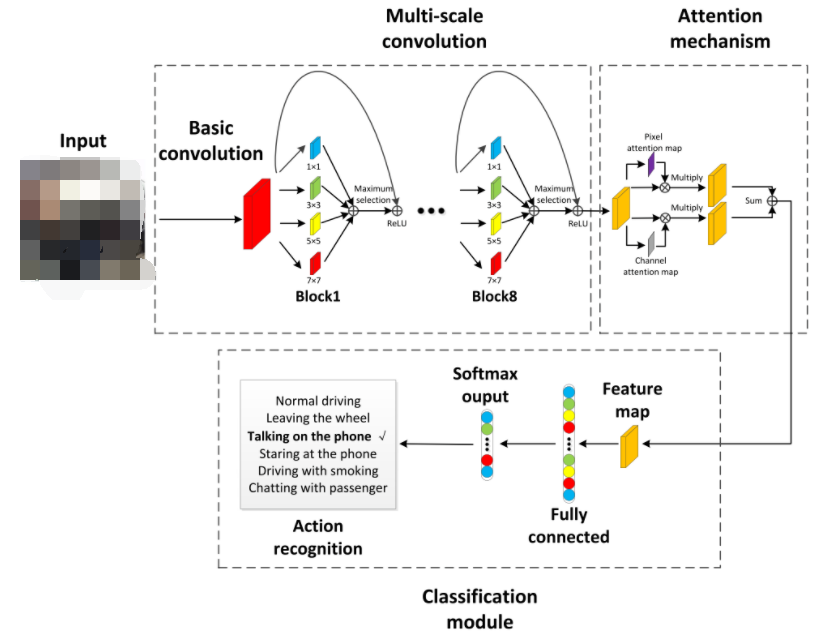
01多尺度卷积模块构成
多尺度卷积网络模块采用了轻量化的多尺度卷积单元LMCU(light-weight Multi-scale Convolution Unit,LMCU)用于从静态图像中提取细粒度的驾驶员行为特征。
1LMCU模块首先使用了先通道升维后通道降维的Bottleneck结构,在减少模型参数的同时提高模型的性能。 2压缩层为1×1的卷积网络,能够减少特征图的通道数。 3Bottleneck Layer是模型的中间层包括3×3,5×5,7×7三种深度可分离卷积核,可以同时捕获不同尺度的特征,提高模型对多尺度信息的敏感性。 4随后使用Maxout激活函数对特征进行融合,以促进多尺度信息的交互。 5最后,输出层采用了Residual Unit的跳跃机制进行连接,减轻梯度消失问题,提高网络的训练收敛性
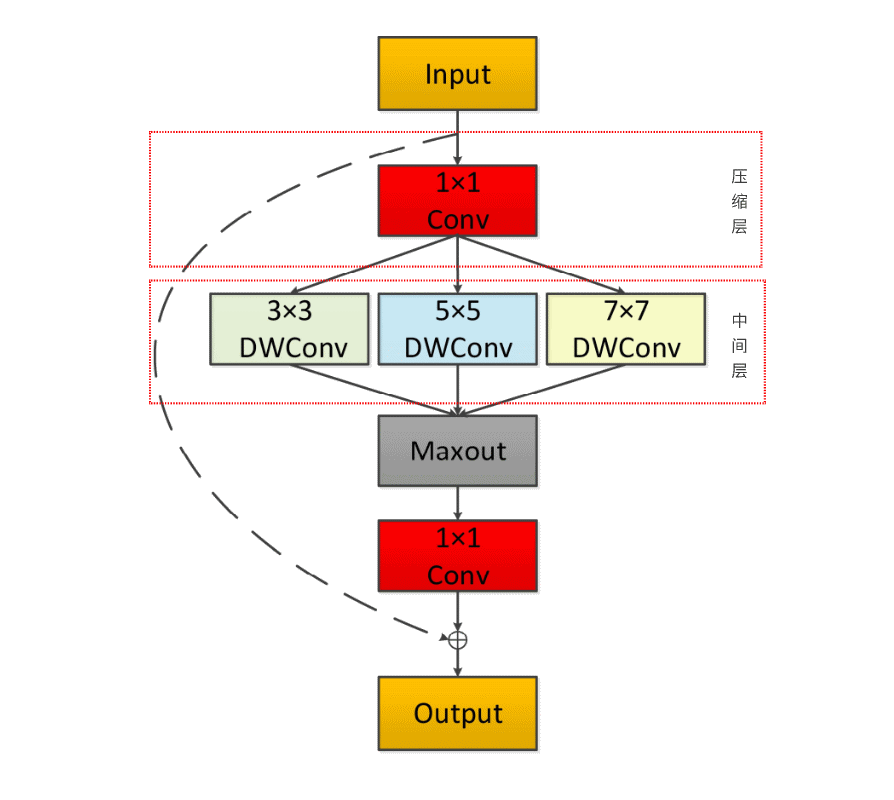
02多尺度卷积模块的优势
普通卷积的每个通道都要经过一个不一样的卷积核卷积,然后对得到的所有数据进行相加得到一个新的通道,也就是说经过普通卷积得到的新一层的特征,其每个通道都整合了上一层网络中所有通道的信息,每个输出通道都需要一组与原通道数量相同的卷积核来进行卷积。
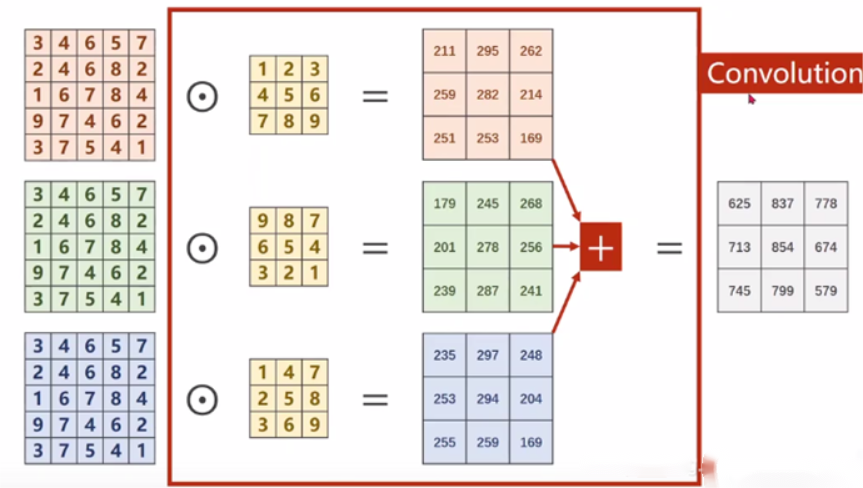
深度可分离卷积包括深度卷积和1×1卷积,深度卷积的每个通道在经过卷积核后并没有进行相加的操作,根据卷积核个数的不同,一个输入通道既可以对应一个输出通道,也可以对应多个输出通道,即可以对一个通道进行多次信息提取。
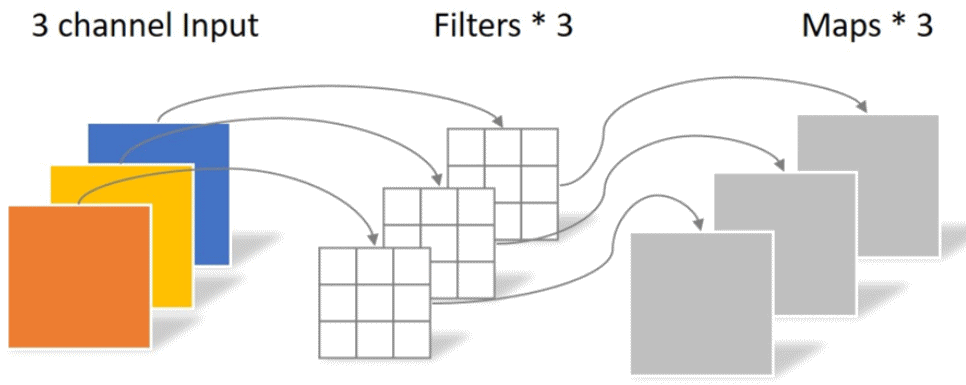
在经过上述处理后,存在两个问题,首先是通道的数量无法变化,其次输出通道只包含了对应输入通道的信息,没有包含所有输入通道的信息,没有起到信息整合的作用。所以进行了逐点卷积,采用1×1×M的卷积核,M为上一层的通道数,这种卷积运算会将上一层的特征图在深度方向上进行加权组合,生成新的特征图,有几个卷积核就会输出几个特征图。
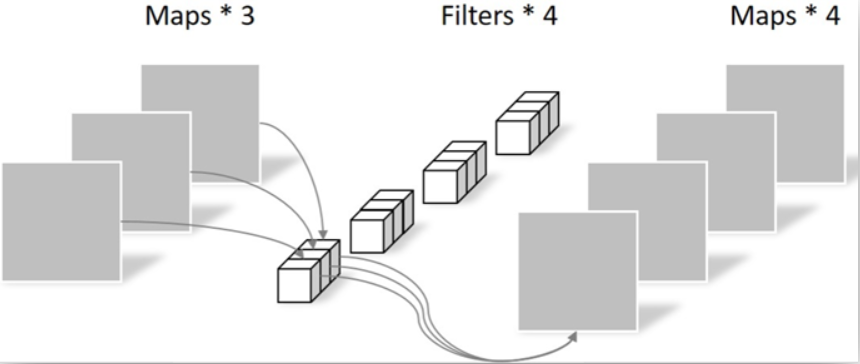
特征图经过3×3、5×5、7×7的可分离卷积运算之后即可获得一组多尺度的特征集合,LMCU采用了Maxout激活函数融合多尺度信息,接着,对融合之后的特征图进行Batch normalization和RELU处理,输出处理后的特征图,并使用1*1的卷积对融合之后的特征图进行降维处理,再使用跳跃连接机制,对结果与原始值进行连接输出。
03特征强化网络模块
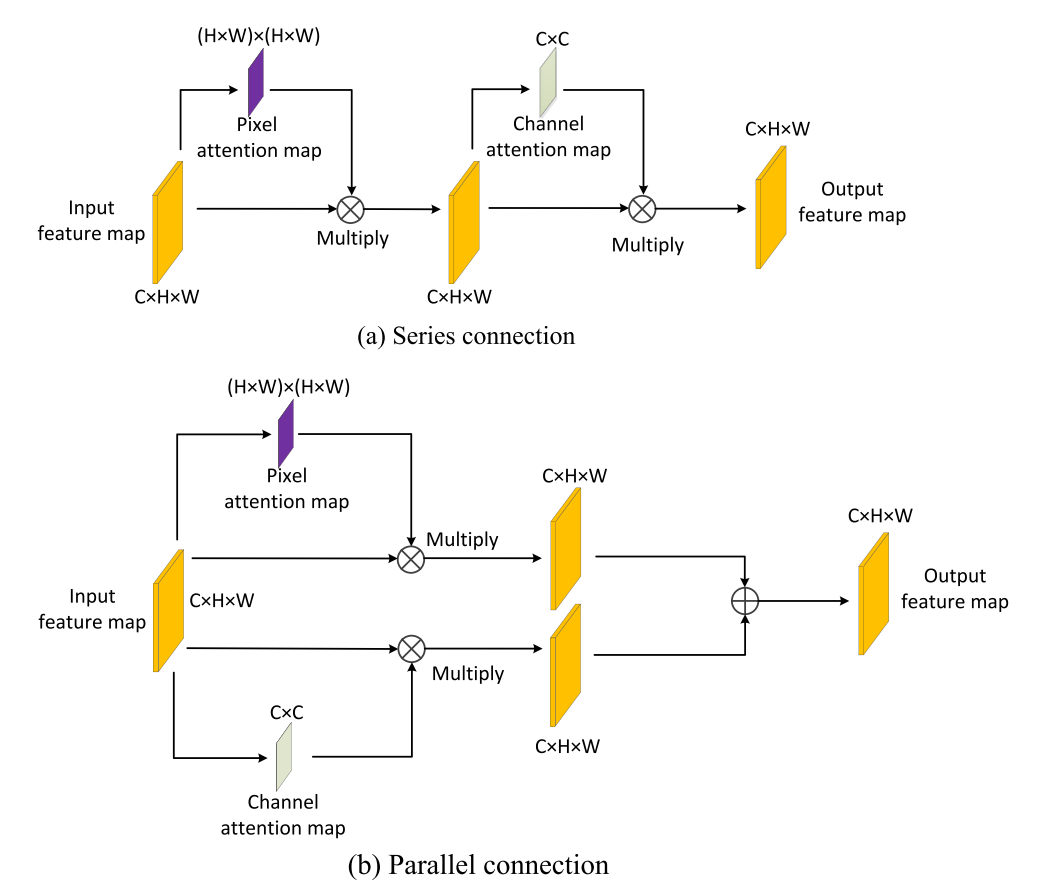
特征强化网络模块采用了空间注意力机制和通道注意力机制,其中空间注意力机制用于衡量图像中不同像素区域的显著性,通道注意力机制更多的关注不同特征图之间的相互依赖关系。空间注意力机制和通道注意力机制通常包括系列融合和并联融合两种方式,研究表明并联融合的方式更好。
04分类网络模块
分类网络模块包含全连接层和softmax分类器,全连接层用于特征学习及数据的扁平化处理,softmax分类器用于特征分类并估计不同类别的概率分布,最终输出驾驶员行为识别结果。
05模型性能评估
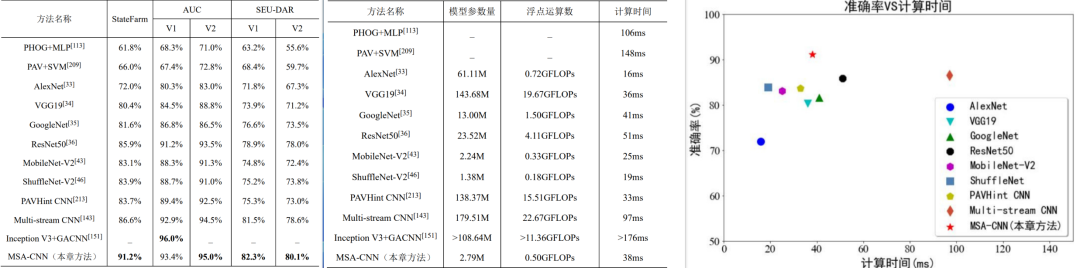
本研究从识别精度和计算效率两个方面评估了MSA-CNN模型的性能,并与现有的驾驶员行为识别方法和模型做了对比,表明MSA-CNN模型在大部分数据集上的精确度高于其他对比方法,计算效率较高,处理速度达到了25fps,且达到了准确率和计算时间的良好平衡。
02RefineDet模型与道路特征提取
交通标识的准确识别在日常出行中具有重要意义,它能够为驾驶员提供及时的交通规则信息,避免道路拥堵,促进驾驶规范,提高道路安全。交通标识检测和识别的核心技术是目标检测,然而在对交通标识进行检测时,通常面临三个严峻的挑战,首先,交通标识的尺寸通常比较小,在原始图像中所占的比例也有限,进行检测时输出的特征包含的信息也相对较少,从而导致漏检或者误检。其次,相似性交通标识比较多,每一大类交通标识有相同的颜色或者形状,这种情况下就比较容易出现误检现象。同时,驾驶中速度一般较高,对时效性的要求也较高。
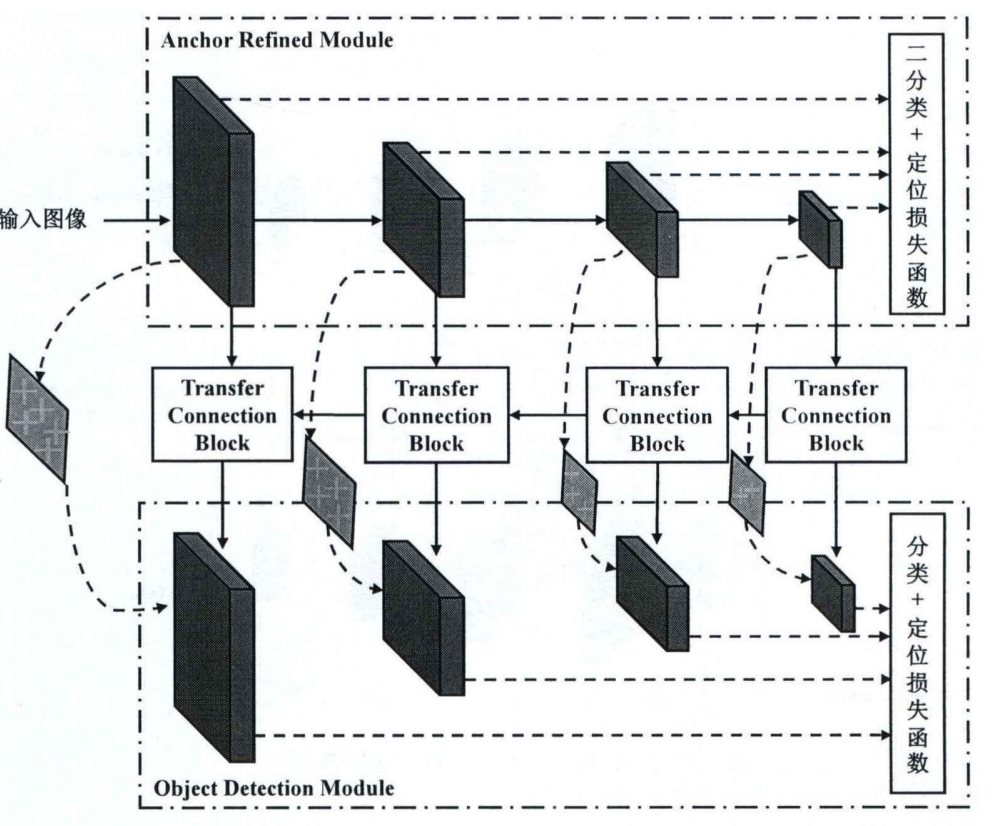
Dense-RefineDet模型结构
RefineDet通过锚点细化模块(Anchor Refinement Module,ARM)、检测模块(Object Detection Module,ODM)和特征传递模块(Transfer Connection Block,TCB)三个模块的协同工作,在一阶目标检测中获得更高的监测精度。锚点细化模块可以优化描点的位置和尺寸,以更好地匹配目标的实际形状和大小。检测模块利用锚点细化模块传递过来的特征对待检测目标进行分类和定位处理。特征传递模块的作用是将锚点细化模块提取的特征传递给检测模块,同时在过程中进行了特征融合。
Dense-RefineDet模型以RefineDet为基础框架,构建了基于锚框设计和稠密连接的交通标识识别模型,其骨干网络是VGG16,输入图像尺寸为 640x640。遵循多尺度输出策略,用于检测的输出特征一共有 4 层,分别是 Conv4-3 层、Conv5-3层、Conv7 层和 Conv8-2,对应的特征尺寸大小分别为 80x80、40x40、20x20以及10x10。
01小目标锚框设计的优势
我们围绕锚框形状设计和锚框坐标设计提出了一个针对小目标的方法,该方法能够更好的进行形状匹配,提高小目标的检测精度:
1应用K-means确定锚框形状。以训练集的所有矩形边界框为数据集,对其进行K均值聚类,k=4,。 2确定锚框坐标。Dense-RefineDet输出了四层不同尺寸的特征,为尺寸最大的浅层特征配置两组尺寸较小的锚框,所有锚框的中心坐标设置为(0,25,0,25),(0,25,0,75),(0,75,0,25)和(0,75,0,75)该层的锚框数量为8。 3对于其余三层而言,配置全部的四组锚框,锚框的中心坐标保持不变,每个特征单元的锚框数量为4,下图为锚框效果图。
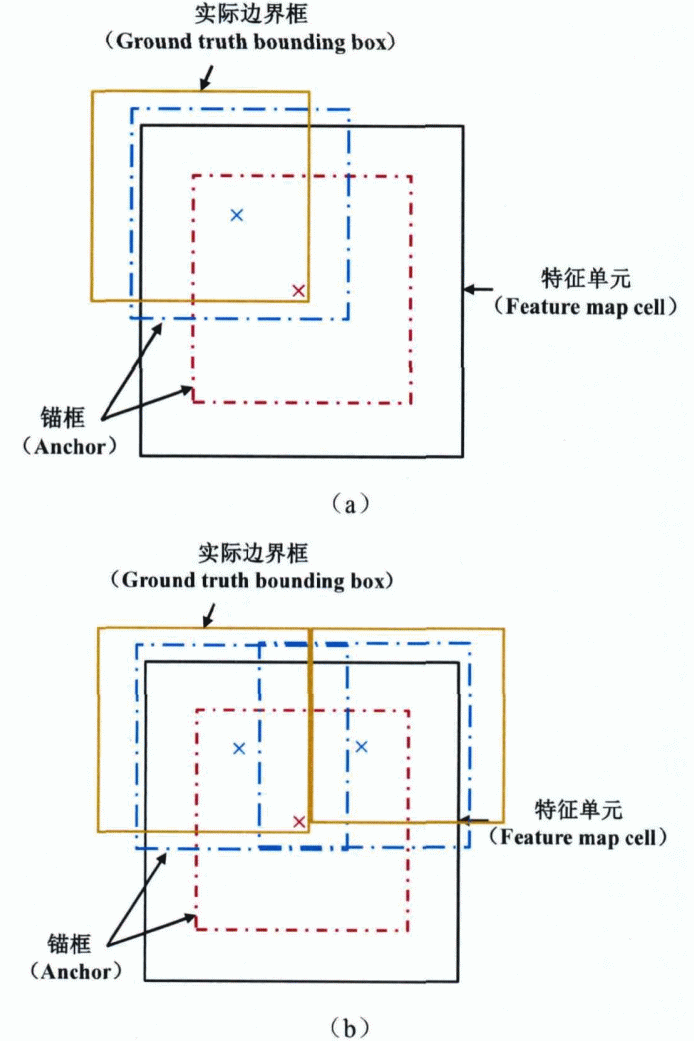
4对于每一个样本计算其矩形边界框跟所有锚框的交并比(IOU)。将其中拥有最大交并比的锚框确定为该检测目标的匹配锚框,同时也将交并比大于某一阈值(一般为0,5)的所有锚框作为该目标检测的匹配项。 5如图(a)中的红色框表示的是形状确定的锚框,其中心坐标是(0,5,0,5)。蓝色框表示的是和红色框形状相同的锚框,他的中心坐标为(0,25,0,75)。待检测目标和红色锚框之间的IOU要小于和蓝色锚框之间的IOU,这表示蓝色框更适合定位该目标。 6在(b)中,红色锚框无法同时匹配两个待检测目标,此时,中心位于特征单元边角位置的两个蓝色锚框则可以同时匹配上述待检测目标。黑色矩形代表的是特征图中的特征单元,红色框和蓝色框表示的是形状确定的锚框,黄色框表示的是待检测目标。
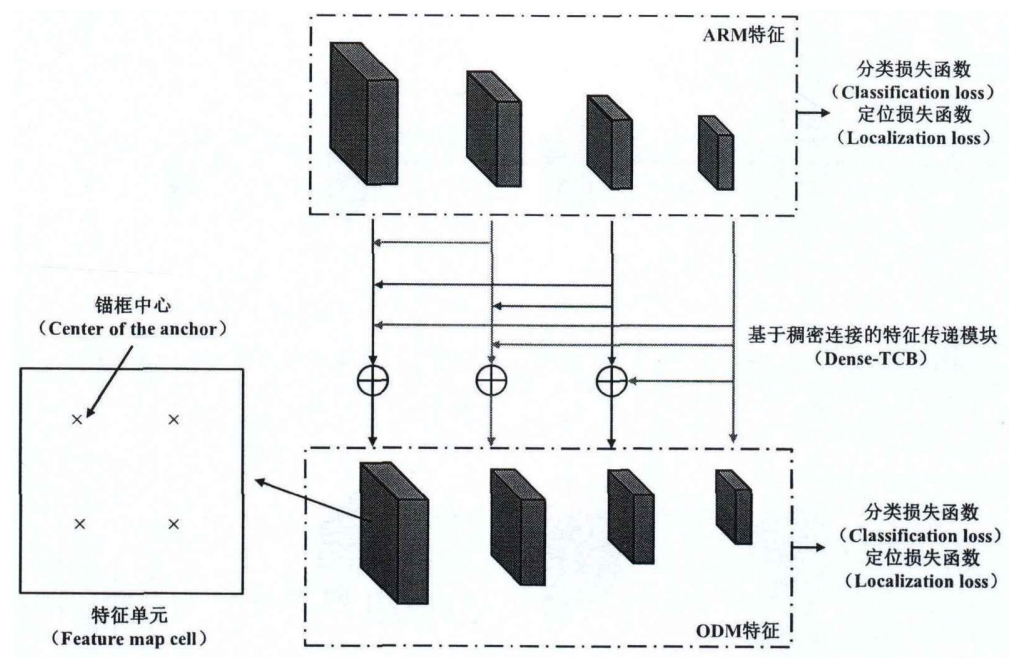
02特征传递模块
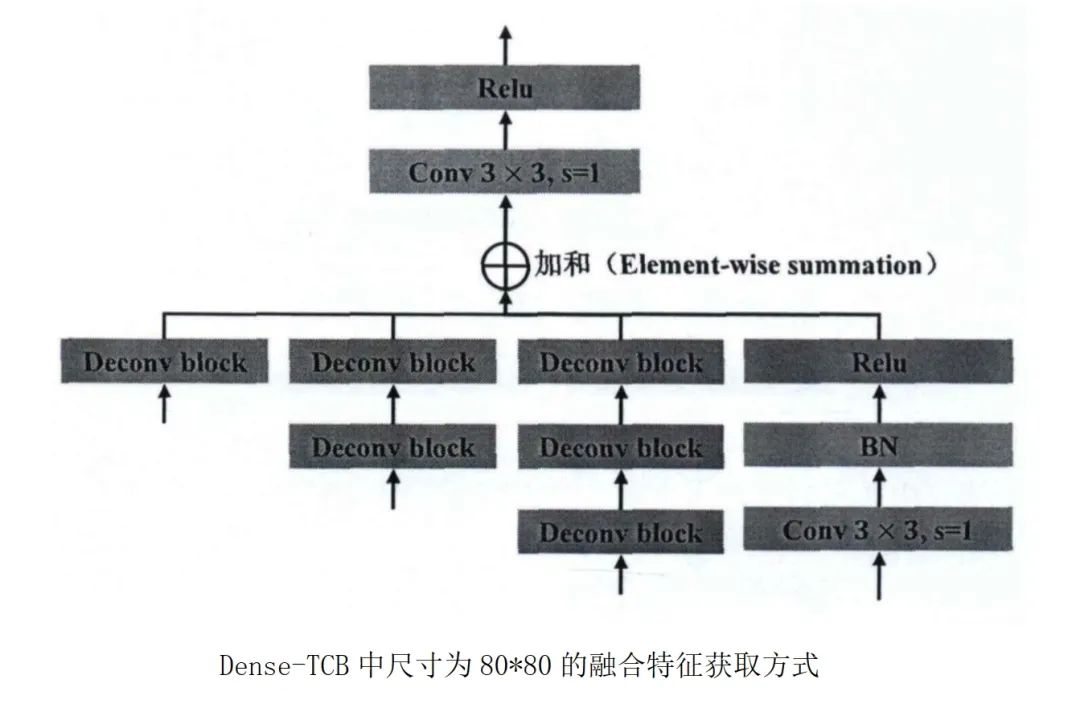
采用稠密连接的方式进行特征传递,稠密链接将高一层级的特征层(Conv8-2层)进行反卷积得到和自身特征层尺寸相同的特征图,通过对应元素加和的方式进行融合,得到最终的特征融合层。最后将融合特征传递到ODM。对于剩余的特征层,直接将其传递到 ODM。这样做的优势在于CNN结构中浅层特征图包含丰富的空间信息,而深层特征图则包含丰富的语义信息,两者结合则可以获取额外的上下文信息,从而提高检测精度。
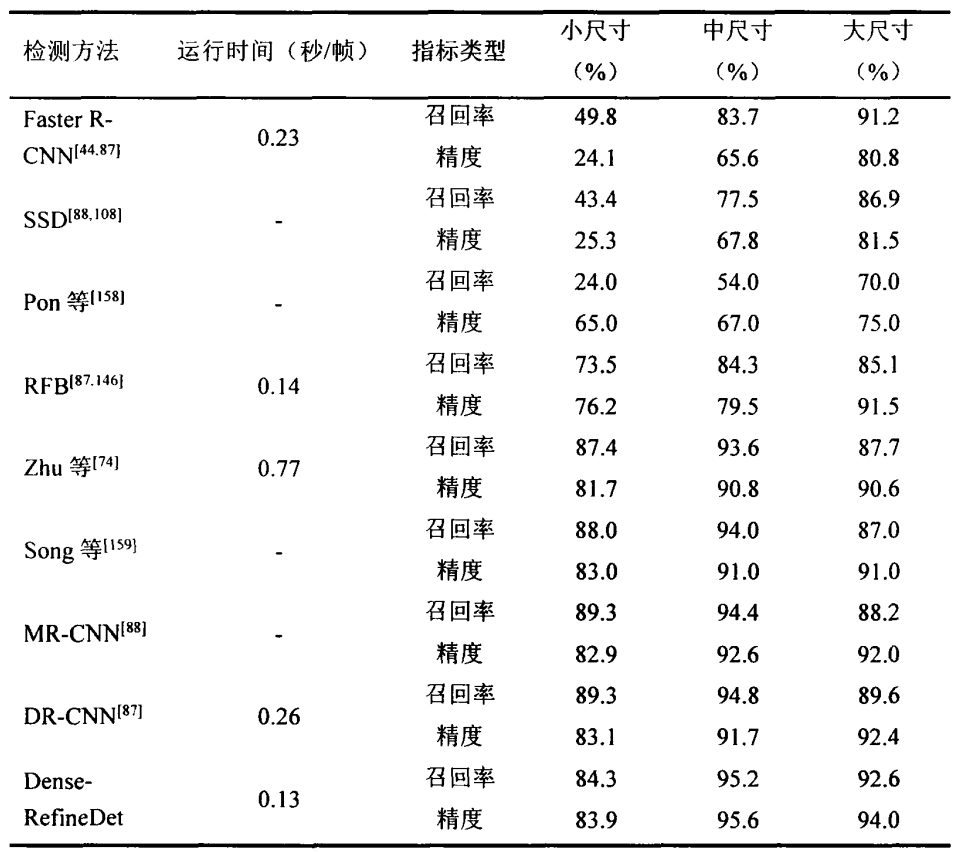
03模型性能评估
在Tsinghua-Tencent 100K数据集上对比了Dense-RefineDet模型与其他深度学习方法的性能,Dense-RefineDet在中等尺寸和大尺寸交通标识识别上的召回率和精度均由于其他模型,在小尺度模型上的召回率虽略逊于DRMR-CNN,但精度和速度高于前者。同时,Dense-RefineDet模型的速度达到0.13秒/帧,这在业界属于速度非常快的模型,能够满足道路标识检测中实时性的需求。
参考文献
【1】李林糠.基于计算机视觉的安全辅助驾驶系统[D].西安电子科技大学2018.
【2】范延军基于机器视觉的先进辅助驾驶系统关键技术研究[D1. 东南大学2016.
【3】RAGESH N,RAJESH R. Pedestrian detection in automotive safety:understanding state-of-the-art[J].IEEE Access,20197: 47864-47890.
【4】SWATHI M,SURESH K. Automatic traffic sign detection and recognition:A review[C]//2017 International Conference on Algorithms, Methodology,Models and Applications in Emerging Technologies (ICAMMAET), 2017:1-6
【5】HILLEL A B, LERNER R, DAN L, et al. Recent progress in road and lanedetection: a survey[J]. Machine Vision & Applications,2014,25(3): 727-745.
【6】Y. Yanbin, Z. Lijuan, L. Mengjun, S. Ling, Early warning of traffic accident inshanghai based on large data set mining, in: 2016 InternationalConferenceon Intelligent Transportation, Big Data Smart City (ICITBS), 2016, pp. 18-21http://dx.doi.org/10.1109/ICITBS.2016.149.
【7】M. Peden, Global collaboration on road traffic injury prevention, Int. J. Inj[2]Control Saf. Promot.12 (2) (2005) 85-91.
【8】F. Jimnez, J.E. Naranjo, J.J. Anaya, F. Garca, A. Ponz, J.M. Armingol, Advanceddriver assistance system for road environments to improve safety and efficiencyTransp. Res. Procedia 14 (2016) 2245-2254, Transport Research Arena TRA2016
【9】P. Viswanath, K. Chitnis, P. Swami, M. Mody, S. Shivalingappa, S. NagoriM. Mathew, K. Desappan, S. Jagannathan, D. Poddar, A. Jain, H. Garud, VAppia, M. Mangla, S. Dabral, A diverse low cost high performance platform foradvanced driver assistance system (adas) applications, in: 2016 IEEE Conferenceon Computer Vision and Pattern Recognition Workshops (CVPRW), 2016, pp819-827,http://dx.doi.org/10.1109/CVPRW.2016.107.
【10】Y. Ouerhani, A. Alfalou, M. Desthieux, C. Brosseau, Advanced driver assistancesystem: Road sign identification using viapix system and a correlation techniqueOpt. Lasers Eng.89 (2017) 184-194, 3DIM-DS 2015: Optical Image Processingin the context of 3D Imaging, Metrology, and Data Security.
编辑:黄飞
-
基于卷积神经网络的双重特征提取方法2023-10-16 1944
-
基于局域判别基的音频信号特征提取方法2011-03-04 1910
-
基于matlab的人脸检测K-L的人脸识别(肤色分割和特征提取)2012-02-22 168301
-
模拟电路故障诊断中的特征提取方法2016-12-09 5428
-
基于已知特征项和环境相关量的特征提取算法2009-04-18 938
-
基于DCT和KDA的人脸特征提取新方法2009-05-25 1141
-
人脸识别系统中的特征提取Feature Extraction2009-06-04 1106
-
模式识别中的特征提取研究2009-12-12 839
-
故障特征提取的方法研究2006-03-11 1963
-
基于EMD法的语音信号特征提取2011-10-10 1138
-
基于Gabor的特征提取算法在人脸识别中的应用2013-01-22 1369
-
基于加权多尺度张量子空间的人脸图像特征提取方法_王仕民2017-01-08 807
-
颜色特征提取方法2017-11-16 4653
-
机器学习之特征提取 VS 特征选择2020-09-14 4989
-
计算机视觉中不同的特征提取方法对比2022-07-11 5207
全部0条评论

快来发表一下你的评论吧 !
