

港中文等发布MagicDrive:日夜、雨晴、多视角全覆盖,人、物位置随意变更
描述
【导读】MagicDrive可以细粒度生成高保真、多相机街景,可以随意变换天气、光照条件以及人物位置,海量自动驾驶数据触手可及!
在深度学习算法的应用中,高质量的数据是技术创新的关键驱动力,尤其在自动驾驶领域,获取和标注3D感知数据的成本不菲,对于许多研究者和开发者来说都是一个重大挑战。
为此,来自香港中文大学、香港科技大学和华为诺亚方舟实验室的研究人员联合提出了基于 Diffusion的3D自动驾驶数据生成方法MagicDrive。
通过多种3D几何条件的细粒度控制,MagicDrive在生成高保真多相机街景图像的同时,还能够支持多种下游感知任务的训练。

论文地址:https://arxiv.org/abs/2310.02601
项目主页:https://gaoruiyuan.com/magicdrive/
Github: https://github.com/cure-lab/MagicDrive
MagicDrive多样化生成数据
MagicDrive是一个突破性的解决方案利用可控生成技术合成自动驾环视相机视图,生成更多样化的自动驾驶数据,为自动驾驶场景仿真提供了新思路。

先来看一些MagicDrive的生成效果。
多视角下,前景和背景都能保持一致性:

可以一键转雨天:

不止生成车,人、障碍物都能准确控制位置:

还可以一键转夜晚:

物体位置可以实现细粒度控制:

关键问题:多种3D条件的编码与注入
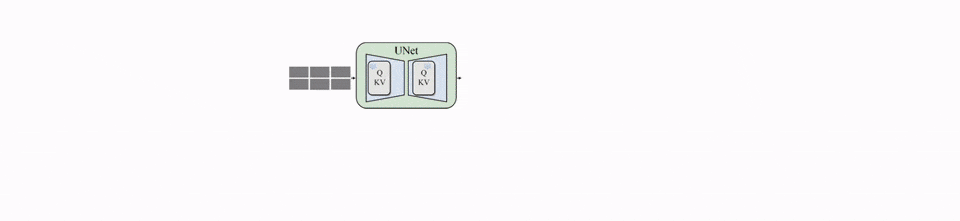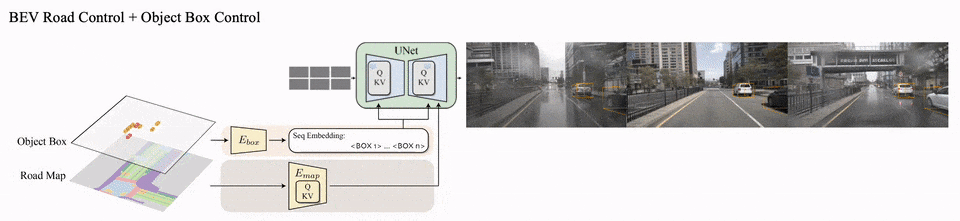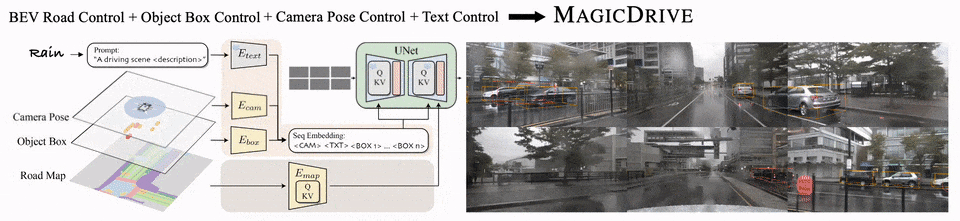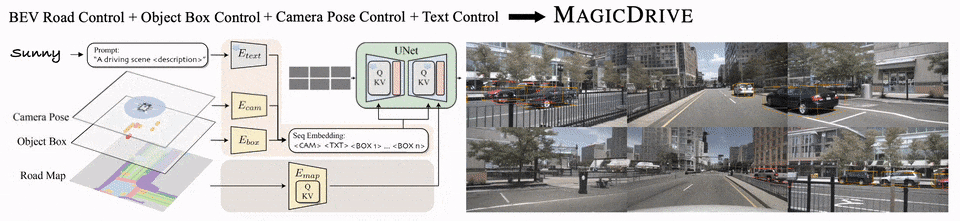
描述自动驾驶场景的条件是多维度的,包括:相机参数、物体框、路面地图以及对场景属性的语言描述(比如天气和时间)。如何将如此复杂的场景信息同时作为条件指导生成,是3D自动驾驶街景数据合成的重点问题。
BEVGen[1]将3D几何信息(路面和物体位置)都投影在BEV空间中,这会丢失全部高度信息,既无法控制物体高度/遮挡,也无法体现路面起伏;BEVControl[2]将3D几何信息分别投影在相机视图中,对于没有高度信息的路面地图而言,投影本身就是一个欠定义的问题,而且这种做法丢失了深度信息,同样无法准确控制遮挡。
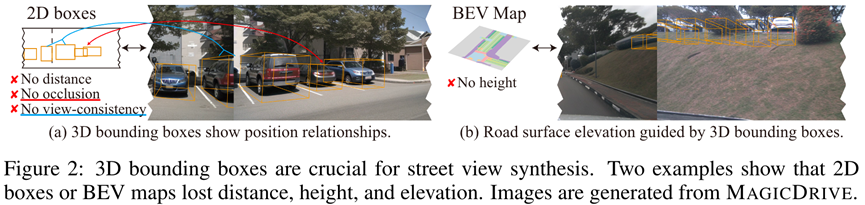
3D几何信息与不同2D投影(相机投影/BEV)控制的比较
MagicDrive在完整考虑这些控制条件的基础上,首次实现3D几何的直接控制。MagicDrive结合Diffusion Model进行条件生成的优势,根据每个控制条件的形式,采用不同的方法对生成进行控制。
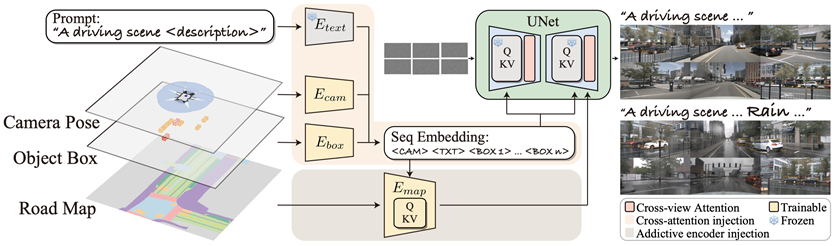
MagicDrive的方法框架
具体来说,对于场景级别的信息(语言描述和相机参数)和物体框信息,由于他们具有可变长的性质,MagicDrive先使用不同的编码器讲输入数据编码成嵌入序列,然后使用交叉注意力模块控制图像生成过程;
对于路面地图信息,BEV能够很好地将路面表示成图像的形式,因此,使用类似ControlNet[3]的额外编码器分支,就能够让生成遵循路面地图的条件。
删繁就简:不同视角的一致性生成
多视角一致性是3D场景相机视图生成的另一个重要要求。此前,已经有一些工作探索了室内场景中的多视角一致性约束方法,例如:MVDiffusion[5]和[6],但室内场景通常视角之间重叠较大,因此他们借助了不同的几何先验来限制视角之间的关系。
对于自动驾驶场景,不同相机之间重叠程度是有限的,因此并不需要过强的几何约束。相反,在几何条件足够的情况下(即不同视角已经有独立的几何条件信息),只需要让不同视角的生成过程有信息交互,就能够保证前景和背景的一致生成。
因此MagicDrive提出cross-view attention模块,用于在各个视角的生成过程中与左右相邻视角交换信息,确保了从多个视角看到的前景和背景是一致的,这大大提高了数据的真实性与可靠性。
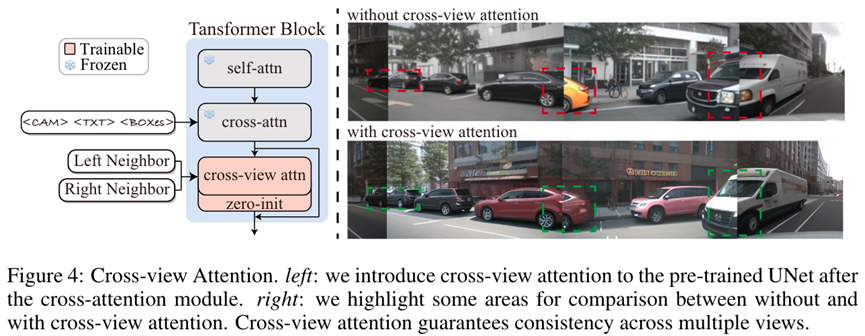
Corss-view attention 模块控制多视角的一致性
生成效果:在多个下游任务上提升明显
用以真实图像训练的感知模型评价生成模型产生的图片,MagicDrive不仅可以在BEV分割任务上超过baseline,并且能够直接支持3D物体检测任务,体现出优越的生成效果。
MagicDrive生成的图片还可以直接用于数据增强,支持BEV分割和3D物体检测任务,提升BEVFusion[6]和CVT[7]的性能。
除此之外,MagicDrive的多条件控制还可以实现场景、背景和前景的多层次街景图像编辑,用来生成更多的新街景图像。
更多评价结果与讨论请参考原论文。
总结
总的来说,MagicDrive带给我们一个全新的、高效的数据生成途径。不仅成功解决了之街景生成中的3D几何控制问题,而且提供了一种全新的方法,利用细粒度可控生成技术为3D自动驾驶产生训练数据,生成数据的质量和真实性向自动驾驶的感知技术注入了新的活力。
-
工厂车间无线WiFi覆盖解决方案2018-08-11 9556
-
定制段码液晶屏如何确认视角反向?2020-07-08 2777
-
中文C语言编程玩转物联网华为鸿蒙Hi3861开发-基础案例合集2023-05-08 3421
-
熵加权多视角核K-means算法2017-12-17 935
-
基于视角相容性的多视角数据缺失补全2017-12-18 861
-
如何实现大区域物联网的低成本全覆盖2019-07-21 5360
-
行业首款RISC-V物联网安全芯片“港华芯”正式发布2022-12-15 2139
-
激光雷达助力泳池水下机器人建图+定位全覆盖2026-02-25 586
全部0条评论

快来发表一下你的评论吧 !
