

一文读懂智算中心网络
描述
作者简介:陈起,江苏有线技术研究院高级工程师,硕士,主要从事IPv6、新型城域网方面的研究,曾参与过TVOS、HINOC等重大项目。
01人工智能主流应用场景及算力需求
人工智能领域包括8大重要应用场景,包括:识别检测、语音交互、AI芯片、自动驾驶、机器人、视频解析、人机协同、机器翻译、精准推荐等。每类场景对算力的要求不同。以人工智能最常应用的三大类场景为例,在应用于安防、医疗诊断和自动驾驶等领域的图像检测和视频检索场景中,以卷积网络为主要算力需求;在博弈决策类应用场景中,以强化学习为主要算力需求;在新基建大型计算机场景中,以自然语音处理为主要算力需求。人工智能领域涉及较多的矩阵、向量的乘法和加法,专用性高,对算力消耗大,不适合用通用CPU进行计算。智算中心需要支持不同种类的计算核心,如CPU、GPU、ARM、FPGA等,通过专用处理器高效完成特定计算。此外,以大数据分析为代表的数据密集型应用需要高效且大量的数据存储空间来存储数据集。
人工智能正朝着更大型的模型发展,模型规模与其对应的参数不断增加。2019年GPT-2参数规模达15亿,2020年GPT-3参数规模达1700亿参数,目前已经达到了1万亿的参数规模。
02智能算力概况
智能计算中心指基于GPU、FPGA等芯片构建智能计算服务器集群,提供智能算力的基础设施。主要应用于多模态数据挖掘,智能化业务高性能计算、海量数据分布式存储调度、人工智能模型开发、模型训练和推理服务等场景。
自2020年4月,人工智能正式被纳入新基建的范畴,我国已经在20多个城市陆续启动了人工智能计算中心建设。2022年2月,“东数西算”工程正式全面启动,8个国家算力枢纽节点全面开工。根据中国信息通信研究院2023年发布的《中国综合算力评价白皮书》,截至2022年底,我国算力总规模达到180EFLOPS,智能算力规模占比约22.8%,相比2021年增加41.4%,智能算力增长迅速。根据ICPA智算联盟统计,截至2022年3月,我国人工智能计算中心已投运的近20个,在建设的超过20个。预计到2025年,我国的AI算力总量将超过1800EFLOPS,占总算力的比重将超过85%。
表:长三角人工智能计算中心情况
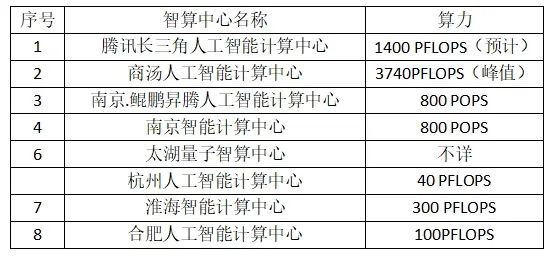
数据来源:2023人工智能发展白皮书
03AI数据中心网络流量特征及技术要求
根据权威定义,智能计算中心是基于最新人工智能理论,采用领先的人工智能计算架构,提供人工智能应用所需算力服务、数据服务和算法服务的公共算力新型基础设施,通过算力的生产、聚合、调度和释放,高效支撑数据开放共享、智能生态建设、产业创新聚集,有力促进AI产业化、产业AI化及政府治理智能化。
AI模型从生产到应用,一般要经历离线训练和推理部署两个阶段。离线训练是产生模型的过程,通过训练模型的数据集及算法,经过多轮迭代,最终生成训练后的模型。这一过程核心是数据计算。通常为了提升计算效率,通过GPU等异构芯片实现加速。人工智能模型训练和推理过程需要强大的算力。人工智能的深度学习计算包含大量的矩阵乘加运算。AI加速芯片如GPU、FPGA、ASIC等能够提供相较于CPU10~100倍的加速。AI服务器通常以CPU+AI加速芯片为主体,构成智算中心的基本单元。其中:
# CPU
通用处理器,用于人机交互和复杂条件分支处理,以及任务之间的同步协调。
# GPU
应用于深度学习等对并行计算、浮点计算要求高的领域。开发周期短,技术体系成熟。
# FPGA
在推演阶段算法性能高、功耗和延迟低。适用于压缩/解压缩、图片加速、网络加速、金融加速等场景。
ASIC,专用芯片,满足特定修的定制化芯片,体积小、功耗低、计算性能高、计算效率高、芯片出货量越大成本越低,包括TPU、NPU、VPU、BPU等各类芯片。
# ASIC
专用芯片,满足特定修的定制化芯片,体积小、功耗低、计算性能高、计算效率高、芯片出货量越大成本越低,包括TPU、NPU、VPU、BPU等各类芯片。
由于AI模型计算对算力的消耗大,单个AI计算单元难以满足算力需求。同时,为了缩短训练时间,通常采用分布式技术对模型和数据进行切分,将训练任务分解为多个子任务,在多个计算节点上同时进行。每个计算节点完成计算任务后,需要进行结果的聚合,完成每一轮次的学习。在这一过程中,多个AI芯片之间需要高速互联,AI服务器之间需要高速通信。因而,需要智算中心网络提供低时延、大带宽、稳定运行的保障,并能够支持大规模计算节点,能够提供方便运维的手段。
低时延
人工智能模型参数规模巨大。预计2025年将达到百万亿级。借助NVMe等接口协议,存储介质访问速率大幅提升,网络时延占比上升到65%,需要采用先进网络设计,降低网络时延。数据中心网络的时延主要包括:静态时延、网络跳数、动态时延以及入网次数。其中,静态时延由查表与转发时延组成,约600ns-1us。网络跳数指网络包经过的设备节点数,不同节点处理时延。该时延与网络架构有关系。动态时延由消息队列产生,该时延与网络拥塞情况相关。当网络拥塞时,数据包在网络设备中排队,或者被丢弃,从而产生时延。入网次数指数据进入网络的次数。分布式训练系统的时延包括单卡的计算时间和卡间通信时间。智算中心网络需要降低卡间通信时间,以提升加速比。降低卡间通信时间通常采用RDMA技术,通过绕过操作系统内核的方式,提升数据访问效率。
大带宽
单节点计算任务的分配以及计算结果的搜集需要大带宽支撑,以快速进行模型参数的迭代计算。以智算中心典型的服务节点为例,单个服务节点可以配置8张GPU卡,8张PCIe网卡。两个GPU跨机互通的突发带宽可能达到50Gbps。一般每个GPU关联一个100Gbps网络端口,单机对外带宽达到800Gbps。
稳定运行
大模型的计算量大、训练时间长,训练期间涉及节点间的频繁交互,对网络稳定性要求高。如果训练期间网络出现不稳定,轻则将回退到上一个分布式训练的断点,重则可能要从0开始,会影响整个训练任务进度。智算中心支撑自动驾驶、智能工厂、远程医疗等行业应用,这些行业应用对网络可靠性要求极高,业务中断会给客户带来重大损失。
智算中心网络要求弹性和可扩展性,支持大规模计算集群,在提供高速连接能力的同时,提供软件定义的加速能力,实现网络的控制和转发分离,减少多维分布式任务带来的性能损耗,提高网络的利用率,支持弹性裸金属服务器、自定义业务功能等特性。
大规模
分布式训练中涉及万级别以GPU为代表的计算节点,智算中心网络需要具备支持大规模节点的能力,且能够方便扩展,为持续增长的算力要求提供接入能力。在智算中心中,多种处理架构并存,NPU(Neural-Network Processing Unit)嵌入式神经网络处理器、VPU(Vector Processing Unit)矢量处理器、GPU等智算中心节点数量将达到百万级。智算中心需要支持算力调度,通过对应用分析和监管,优化算力设备布局规划,提升业务部署效能,提高算力设备的利用率,降低设备闲置率,提升智算中心的生产效率。算力调度涉及配额策略、共享超分、负载均衡等策略。
可运维、可运营
智算中心节点众多,需要具备可运维性、可管理性,能够实时查看智算中心网络运行状态,快速发现和定位网络问题。智算中心中,传统的人机接口变为机器与机器之间的接口,网络、存储、计算边界模糊,故障定位困难,需要引入智能引擎,对应用流量与网络状态进行关联分析,为业务网络提供自愈能力,打造自动驾驶网络。智算中心以云服务模式提供算力服务,不同租户算力需求不同。智算中心需要实现租户间的数据和算力的隔离。
高效智算中心间互联
随着东数西算战略推进及分布式算力协同场景,AI算力突破了单一的智算中心,新型应用依赖多个智算中心之间的协同。智算中心之间的连接要求更高,需要具备更高的带宽(百G甚至上T),更低的丢包率。算力之间的联网和统一调度成为趋势。
此外,在AI训练以及使用过程中,还需要处理好存储问题:解决好处理器内部、处理器和内存、内存和外存以及服务器之间等不同层级数据存取的效率问题。
04AI数据中心网络实现方式
《智能计算中心规划建设指南》中介绍了智能计算中心提供4类算力:
# 生产算力
由AI服务器组成,形成高性能、高吞吐的计算系统,为AI顺联和推理提供基础计算力。
# 聚合算力
由智能网络和智能存储组成,构建高带宽、低延迟的通信系统和数据平台。智能网络、智能存储采用软件定义方式,实现文件、对象、块、大数据存储服务一体化设计。
# 调度算力
将聚合的CPU、GPU、FPGA、ASIC等算力资源进行标准化和粒度切分,满足智能应用的算力需求。
# 释放算力
是指高质量AI模型或AI服务的输出,促进算力高效释放转化为生产力。
这四类算力是智算中心建设的出发点和落脚点。在智算中心网络在具体实现上,从资源管理角度,主要包括三个路线:
# 以CPU为中心
所有存算资源的管理都运行在CPU上,通过远端资源的方式使用其他资源。
# 以内存为中心
内存管理分离出来,实现内存的独立拓展和共享访问,从而实现高效的数据处理和计算。减少了内存管理开销,但其他资源依然由CPU管理和调度。
# 以网络IO为中心
《未来网络白皮书(2023)以网络IO为中心的无服务器数据中心》提出了以网络IO为中心的无服务器数据中心架构,资源去中心化。计算、存储和网络等资源都被视为独立的服务,不同资源的拓展和使用相互独立。资源之间通过消息传递的方式进行通信和协作。网络通信与安全紫金山实验室围绕该理念设计了以网络IO为中心的无服务器数据中心。通过I/O process Unit解耦存算单元使用和协作的枢纽,其对内负责各存算资源的全接入、驱动等,对外负责资源彼此之间的信息交互;通过分布式内核,实现存算资源按需拓展和弹性使用的软件架构。
在网络拓扑架构方面,通常有3种主流设计模式,Fat-Tree架构实现无阻塞转发,Dragonfly架构网络直径小,Torus 具有高扩展性和性价比。
Fat-Tree架构采用1:1无收敛设计。Fat-Tree架构中交换机上联端口与下联端口带宽、数量保持一致,同时交换机要采用无阻塞转发的数据中心级交换机。Fat-Tree架构可以通过扩展网络层次提升接入的GPU节点数量。两层Fat-Tree架构能够接入PP/2张GPU卡,P为交换机的端口数量。三层Fat-Tree架构能够接入 P(P/2)*(P/2)张GPU卡。以40端口的InfiniBand交换机为例,能够接入的GPU数量最多可达16000个。以百度智能云为例,按照服务节点的网卡数量组成AI-Pool,将不同节点相同编号的网口连接到同一台交换机,通过NCCL通信库的Rail Local技术以及主机内GPU间的NVSwitch的带宽,将多机间的跨卡互通转化为跨机间的同GPU卡号的互通,从而实现同2层Fat-Tree架构下,AI-Pool一跳可达,不同AI-Pool 三跳可达。三层Fat-Tree架构下智算节点间同GPU卡号转发3跳可达,不同GPU卡号转发5跳可达。
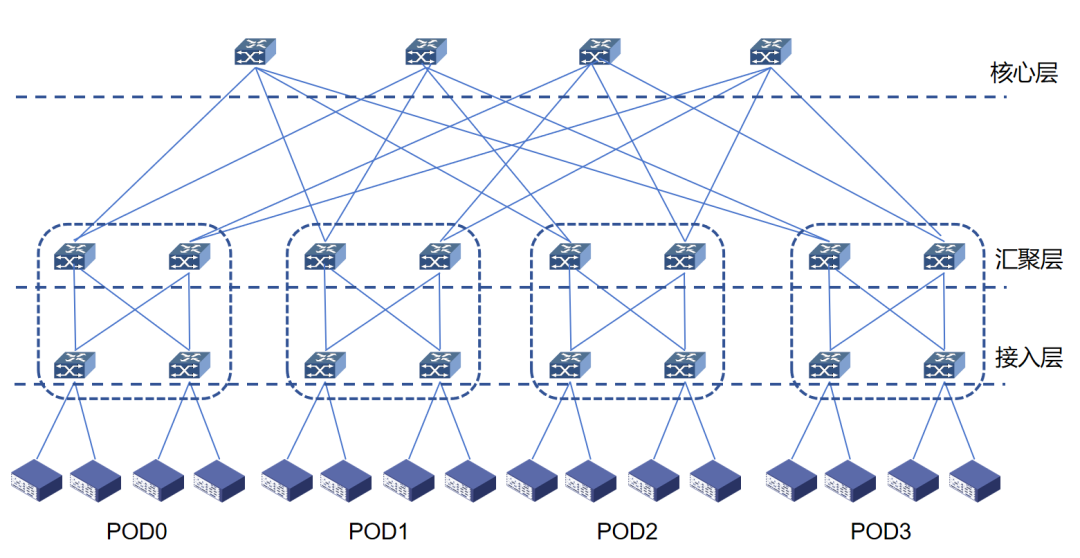
图1:Fat-Tree拓扑图
Dragonfly架构分为三层:Switch层,包含1个交换机及与其相连的计算节点;Group层:包含a个Switch层,a个交换机之间全互联(每个交换机都有a-1条链路连接至其他a-1台交换机);System层:包含g个Group层,g个Group层全连接。对于单个Switch交换机,有P个端口连接计算节点,a-1个端口连接Group内的其他交换机,h个端口连接到其他Group交换机。每个交换机的端口数为k=p+(a-1)+h。可以接入的计算节点总数为N=ap(ah+1),通常按照a=2p=2h配置。采用直连模式,缩短网络路径,减少中间节点数量。64端口交换机支持组网规模27万节点,端到端交换机转发跳数减至3跳。
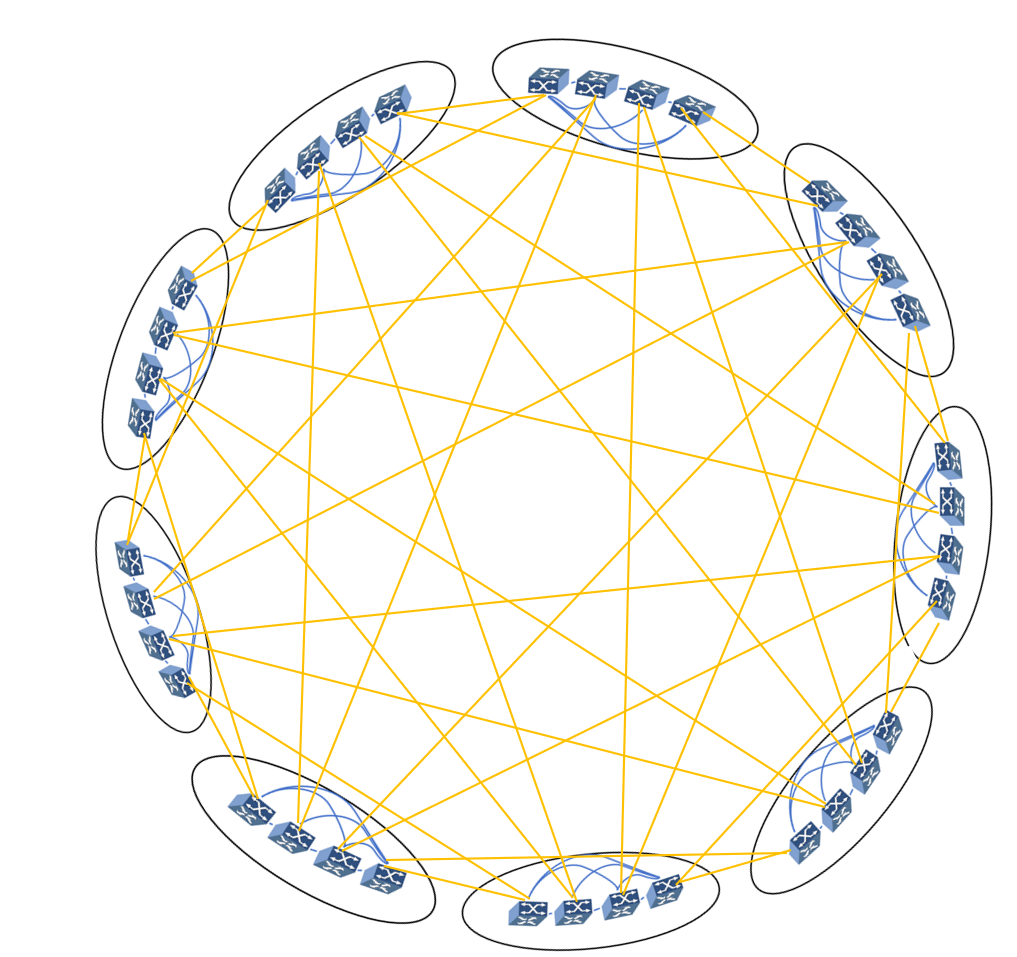
图2:Dragonfly拓扑图
Torus架构,将计算节点按照网格的方式排列,连接同行和同列的相邻节点,同时同行和同列最远端的两个节点之间构建直连线路。有两种构建方法,一种是直接网络,计算节点在环面“晶格”中,计算节点适配器负责转发网络包。对于2D Torus架构,计算节点适配器需要具备4个端口,对于3D Torus架构,需要6个端口,6个线缆连接到计算节点,将影响计算机节点的散热。另一种是将交换机放在环面“晶格”中,计算节点只需要具备常规端口数量的网络适配器,网络包转发主要由交换机完成。Torus架构提供的并非是无阻塞的网络,同时节点之间的距离并非一致,通常通过提升维度来降低时延以及抖动的影响。但是构造成本较低。
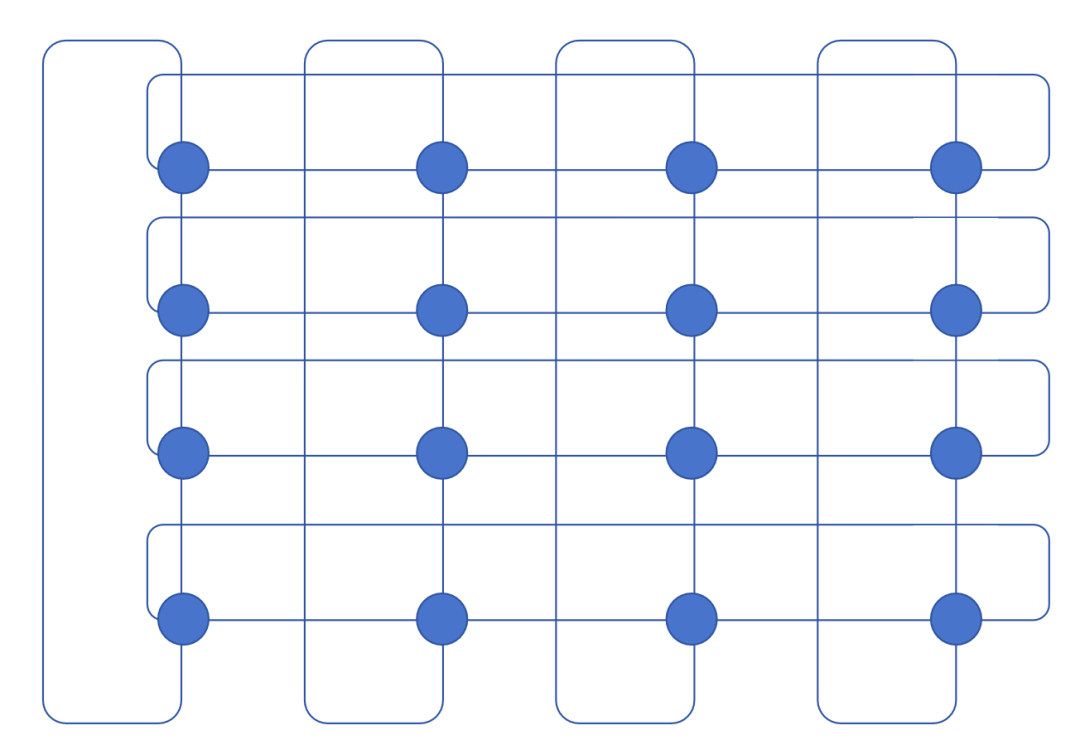
图3:Torus拓扑图
在互联协议选择方面,具体的实现方式包括iWARP、RoCEv1、RoCEv2、InfiniBand四种,后两种是目前的主流方案,应用层端到端的时间能从50us(TCP/IP),降低到5us(RoCE)或2us(InfiniBand)。此外,可通过可编程网络设备,在网计算,减少传输的数据量,进一步提升传输效率。
RoCEv2 采用分布式网络架构,包括支持RoCEv2的网卡和交换机,借助传统以太网的光纤和光模块实现端到端的RDMA通信。交换机转发芯片以博通Tomahawk系列芯片为主,单端口从100Gbps->200Gbps->400Gbps不断演进。RoCEv2 中的Go Back N重传机制采用PFC(优先级流控)实现逐跳流控策略,保证在以太网中实现无丢包。标准RoCEv2协议中每个RC(可靠连接)都映射到唯一的五元组,整网负载均衡性差,容易产生拥塞。RoCEv2通常卸载到网卡中,受限于网卡芯片内的表项空间,芯片内的连接数有限,当网络节点超过一定规模,会发生网卡芯片与主机内存的连接表交换,影响网络传输性能。
InfiniBand网络中关键组成包括Subnet Manager、InfiniBand网卡、InfiniBand交换机和连接线缆。Subnet Manager即为InfiniBand网络的控制器,进行InfiniBand子网划分及QoS管理,向每个交换芯片下发转发表,通过带内方式控制子网内所有交换机和网卡。InfiniBand网卡通过SMA(Subnet Manager Agent)接受Subnet Manager的统一管理。InfiniBand交换机不运行路由协议,网络转发表通过Subnet Manager统一下发。基于Credit信令机制避免缓冲区溢出丢包,网络中每条链路都有预置缓冲区,发送端一次性发送数据不会超过接收端可用的缓冲区大小。
05小 结
智算中心与普通的数据中心相比 存在大量的异构计算核心,东西向之间的通信流量更大,对时延、抖动、可用性的要求更高,对算力的需求更大,需要从安全性、可靠性、能源使用效率综合考虑网络架构设计,最大程度发挥智算中心资源价值。
审核编辑:汤梓红
-
智算中心网络架构选型原则2023-08-07 4165
-
一文读懂接口模块的组合应用有哪些?2021-05-17 2452
-
一文读懂如何去优化AC耦合电容?2021-06-08 3694
-
一文读懂什么是NEC协议2021-10-15 2681
-
一文读懂中断方式和轮询操作有什么区别吗2021-12-10 2751
-
一文读懂NB-IoT 的现状、挑战和前景2020-02-28 7693
-
一文读懂MCU的特点、功能及如何编写2021-12-05 1367
-
一文读懂,什么是BLE?2023-11-27 4896
-
一文读懂车规级AEC-Q认证2023-12-04 2207
-
一文读懂微力扭转试验机的优势2023-11-30 1446
-
一文读懂:什么是“算力”?2023-12-22 14301
-
一文读懂新能源汽车的功能安全2024-09-04 729
-
一文读懂MSA(测量系统分析)2024-11-01 2456
-
一文读懂算力中心四大类型,深度解读应用与趋势2024-10-17 5213
-
一文读懂单灯控制器工作原理2024-11-11 2777
全部0条评论

快来发表一下你的评论吧 !
