

Cpca 模块:自动识别文字中的省市区并绘图
描述
在做NLP(自然语言处理)相关任务时,经常会遇到需要识别并提取省、城市、行政区的需求。虽然我们自己通过关键词表一个个查找也能实现提取目的,但是需要先搜集省市区关键词表,相对而言比较繁琐。
今天给大家介绍一个模块,你只需要把字符串传递给这个模块,他就能给你返回这个字符串内的省、市、区关键词,并能给你在图片上标注起来,它就是 Cpca 模块。
1.准备
开始之前,你要确保Python和pip已经成功安装在电脑上,如果没有,可以访问这篇文章:超详细Python安装指南 进行安装。
**(可选1) **如果你用Python的目的是数据分析,可以直接安装Anaconda:Python数据分析与挖掘好帮手—Anaconda,它内置了Python和pip.
**(可选2) **此外,推荐大家用VSCode编辑器,它有许多的优点:Python 编程的最好搭档—VSCode 详细指南。
请选择以下任一种方式输入命令安装依赖 :
- Windows 环境 打开 Cmd (开始-运行-CMD)。
- MacOS 环境 打开 Terminal (command+空格输入Terminal)。
- 如果你用的是 VSCode编辑器 或 Pycharm,可以直接使用界面下方的Terminal.
pip install cpca
注意,目前 cpca 模块仅支持Python3及以上版本。
在 windows 上可能会出现类似如下问题:
Building wheel for pyahocorasick (setup.py) ... error
先阅读原文去下载 Microsoft Visual C++ Build Tools 安装VC++构建工具,再重新 pip install cpca,即可解决问题。
2.基本使用
通过两行代码就能实现最基本的省市区提取:
# 公众号: Python 实用宝典
# 2022/06/23
import cpca
location_str = [
"广东省深圳市福田区巴丁街深南中路1025号新城大厦1层",
"特斯拉上海超级工厂是特斯拉汽车首座美国本土以外的超级工厂,位于中华人民共和国上海市。",
"三星堆遗址位于中国四川省广汉市城西三星堆镇的鸭子河畔,属青铜时代文化遗址"
]
df = cpca.transform(location_str)
print(df)
效果如下:
省 市 区 地址 adcode
0 广东省 深圳市 福田区 巴丁街深南中路1025号新城大厦1层 440304
1 上海市 None None 。310000
2 四川省 德阳市 广汉市 城西三星堆镇的鸭子河畔,属青铜时代文化遗址 510681
注意第三条的广汉市,cpca 不仅识别到了语句中的县级市广汉市,还能自动匹配到其代管市的德阳市,不得不说非常强大。
如果你想获知程序是从字符串的那个位置提取出省市区名的,可以添加一个 pos_sensitive=True 参数:
# 公众号: Python 实用宝典
# 2022/06/23
import cpca
location_str = [
"广东省深圳市福田区巴丁街深南中路1025号新城大厦1层",
"特斯拉上海超级工厂是特斯拉汽车首座美国本土以外的超级工厂,位于中华人民共和国上海市。",
"三星堆遗址位于中国四川省广汉市城西三星堆镇的鸭子河畔,属青铜时代文化遗址"
]
df = cpca.transform(location_str, pos_sensitive=True)
print(df)
效果如下:
(base) G:push20220623 >python 1.py
省 市 区 地址 adcode 省_pos 市_pos 区_pos
0 广东省 深圳市 福田区 巴丁街深南中路1025号新城大厦1层 440304 0 3 6
1 上海市 None None 。310000 38 -1 -1
2 四川省 德阳市 广汉市 城西三星堆镇的鸭子河畔,属青铜时代文化遗址 510681 9 -1 12
它标记出了识别到省、市、区的关键位置(index),当然如果是德阳市这种特殊的识别会被标记为-1.
3.高级使用
它还可以从大段文本中批量识别多个地区:
# 公众号: Python 实用宝典
# 2022/06/23
import cpca
long_text = "对一个城市的评价总会包含个人的感情。如果你喜欢一个城市,很有可能是喜欢彼时彼地的自己。"
"在广州、香港读过书,工作过,在深圳买过房、短暂生活过,去北京出了几次差。"
"想重点比较一下广州、深圳和香港,顺带说一下北京。总的来说,觉得广州舒适、"
"香港精致、深圳年轻气氛好、北京大气又粗糙。答主目前选择了广州。"
df = cpca.transform_text_with_addrs(long_text, pos_sensitive=True)
print(df)
效果如下:
(base) G:push20220623 >python 1.py
省 市 区 地址 adcode 省_pos 市_pos 区_pos
0 广东省 广州市 None 440100 -1 44 -1
1 香港特别行政区 None None 810000 47 -1 -1
2 广东省 深圳市 None 440300 -1 58 -1
3 北京市 None None 110000 71 -1 -1
4 广东省 广州市 None 440100 -1 86 -1
5 广东省 深圳市 None 440300 -1 89 -1
6 香港特别行政区 None None 810000 92 -1 -1
7 北京市 None None 110000 100 -1 -1
8 广东省 广州市 None 440100 -1 110 -1
9 香港特别行政区 None None 810000 115 -1 -1
10 广东省 深圳市 None 440300 -1 120 -1
11 北京市 None None 110000 128 -1 -1
12 广东省 广州市 None 440100 -1 143 -1
不仅如此,模块中还自带一些简单绘图工具,可以在地图上将上面输出的数据以热力图的形式画出来:
# 公众号: Python 实用宝典
# 2022/06/23
import cpca
from cpca import drawer
long_text = "对一个城市的评价总会包含个人的感情。如果你喜欢一个城市,很有可能是喜欢彼时彼地的自己。"
"在广州、香港读过书,工作过,在深圳买过房、短暂生活过,去北京出了几次差。"
"想重点比较一下广州、深圳和香港,顺带说一下北京。总的来说,觉得广州舒适、"
"香港精致、深圳年轻气氛好、北京大气又粗糙。答主目前选择了广州。"
df = cpca.transform_text_with_addrs(long_text, pos_sensitive=True)
drawer.draw_locations(df[cpca._ADCODE], "df.html")
运行的时候可能会报这个错:
(base) G:push20220623 >python 1.py
Traceback (most recent call last):
File "1.py", line 12, in < module >
drawer.draw_locations(df[cpca._ADCODE], "df.html")
File "G:Anaconda3libsite-packagescpcadrawer.py", line 41, in draw_locations
import folium
ModuleNotFoundError: No module named 'folium'
使用pip安装即可:
pip install folium
然后重新运行代码,会在当前目录下生成 df.html, 双击打开,效果如下:
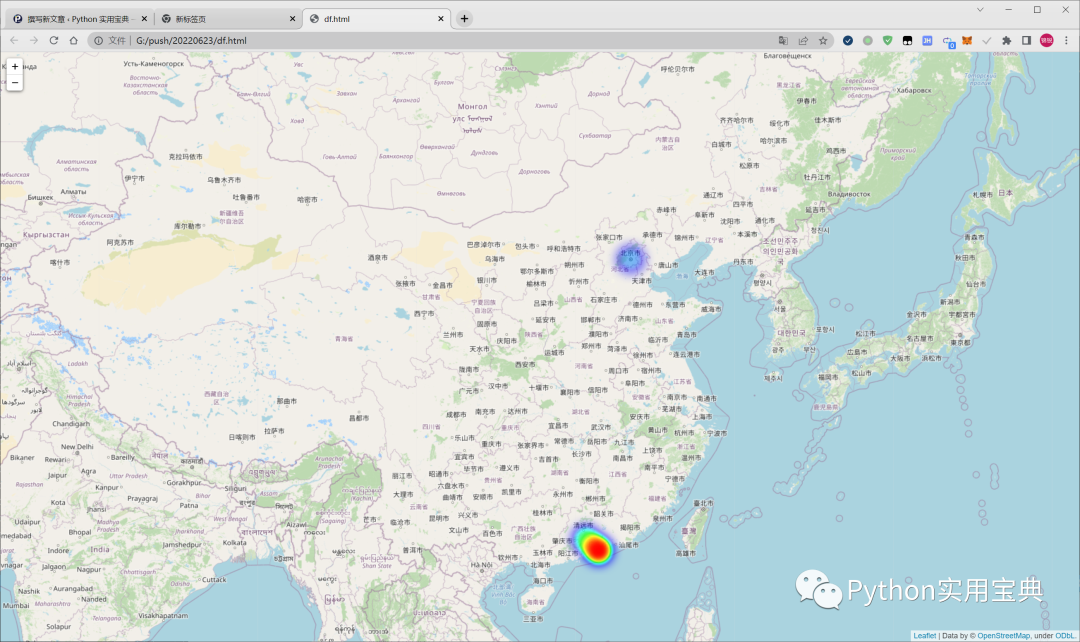
怎么用,是不是感觉非常方便?以后地点的识别用这个模块就完全够了。
-
光学识别字符是自动识别技术吗2024-09-10 1469
-
水位自动识别摄像机2024-07-31 1308
-
数电票试点扩围至36个省市区 百望云解决方案助力企业数电升级2023-11-29 1038
-
OCR如何自动识别图片文字2023-10-31 1912
-
STLink是怎么自动识别STM32芯片型号的?2023-10-27 729
-
Python pacp模块:自动识别文字中的省市区并将其绘图2022-06-27 3605
-
智能交通系统中的车牌自动识别技术有哪些应用呢2022-03-02 1467
-
如何实现系统自动识别并切断电池供电的呢?2022-01-26 1043
-
车辆自动识别称重系统是怎样组成的?2021-05-13 1192
-
车辆自动识别称重系统的工作原理2021-03-01 2877
-
请问USB自动识别芯片RH7901是怎样自动识别充电设备的?2018-05-22 2890
-
求助帖 labview自动识别2013-04-19 2617
-
如何实现串口的自动识别2012-03-23 5135
-
基于射频技术的车牌自动识别装置设计2011-11-15 1183
全部0条评论

快来发表一下你的评论吧 !
