

全球首颗清华忆阻器存算一体芯片究竟是个啥?
电子说
描述
随着ChatGPT强势来袭,AI人工智能应用层出不穷。智能化时代,数据量指数型增长,摩尔定律已经不能满足当前的数据处理需求,元器件的物理尺寸已经接近极限。人工智能的硬件平台面临两大艰巨挑战:算力不足和能效过低。那么,有什么方法提高芯片的算力呢?
其实关键还是在于系统设计和芯片加工。系统设计,重在高性能微架构和先进算术运算,芯片加工则有赖于先进工艺制程和先进封装制备。今年9月份的时候,EETOP曾从运算机制的角度,探讨了计算芯片算力的提升。本期,我们试着从芯片架构方面,继续探讨芯片算力提升的话题。
计算芯片架构趋势:存算一体
现在,无论是CPU还是GPU,采用的都是70年前的冯.诺伊曼体系架构。冯诺依曼体系结构是现代计算机的基础。在冯诺依曼架构中,计算和存储功能分别由中央处理器和存储器完成。计算机的 CPU 和存储器是相互独立发展的,也就是CPU和内存是在不同芯片上的,它们之间的通信要通过总线来进行。数据量少的时候没问题,但一旦数据变多,总线本身就会拥挤成为瓶颈。而现在的GPU,并行处理能力越来越强。当数据传输速度不够时,就会限制算力的天花板, 严重影响目标应用程序的功率和性能。
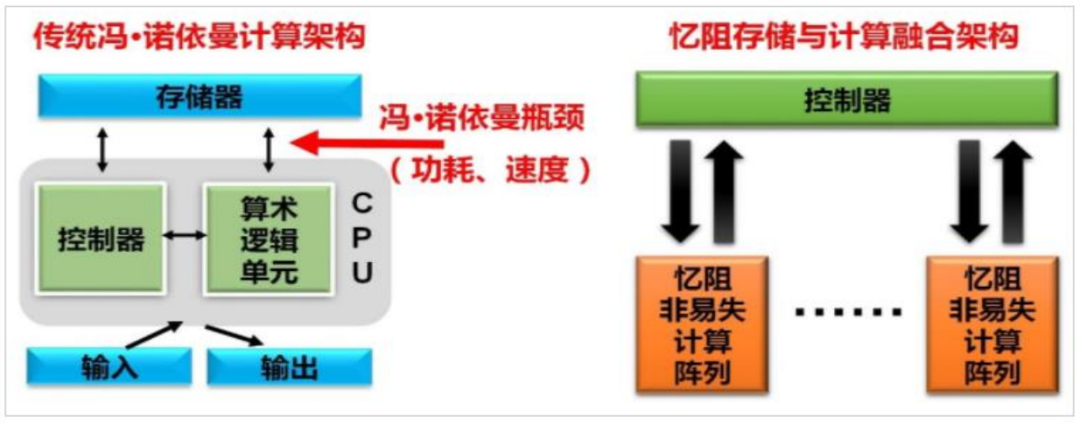
业界很多也都在研究相关的解决方案,以实现更为有效的数据运算和更大的数据吞吐量,其中“存算一体”被认为是未来计算芯片的架构趋势。它是把之前集中存储在外面的数据改为存在GPU的每个计算单元内,每个计算单元既负责存储数据,又负责数据计算。
这几天,清华大学研制出全球首颗全系统集成的、支持高效片上学习(机器学习能在硬件端直接完成)的忆阻器存算一体芯片,可谓刷爆行业媒体圈。这项最新的研究证明了在全集成忆阻器存算一体系统上实现矩阵向量乘法的可行性。据了解,清华大学的研究团队对芯片算法、系统、架构、电路与器件进行了全层次协同优化设计:
器件层面,实现300万个具有高模拟可编程性的忆阻器与CMOS电路的单片集成;
电路层面,提出电压模神经元电路,支持可变精度计算、激活操作、低功耗模数转换;
架构层面,提出双向TNSA(transposable neurosynaptic array)架构,以最小的面积、能耗开销实现灵活的数据流重构;
系统层面,48个CIM核心支持多种权重映射方案,提高推理任务并行度;算法层面,利用多种硬件-算法协同优化方案,降低硬件非理想特性对准确率的影响。
传统计算系统,其计算器件用的是场效应晶体管,计算范式是布尔逻辑数字计算,架构采用的是存算分离;而存算一体计算系统的计算器件是忆阻器,计算范式用的是物理定律模拟计算,架构是存算一体。存算一体架构彻底消除了数据在逻辑处理器与存储芯片之间的搬迁问题,减少能量消耗及延迟。据公开资料显示,相同任务下,该芯片实现片上学习的能耗仅为先进工艺下专用集成电路(ASIC)系统的1/35,同时有望实现75倍的能效提升。
摩尔定律很好的归纳了信息技术进步的速度,但随着半导体芯片技术的快速发展,摩尔定律已经不太适用于现在的半导体芯片发展规律了。冯诺依曼架构遇到了瓶颈,这时便需要忆阻器的魔力,来实现存算一体,打破传统的冯诺依曼架构,开拓新的存储器道路。谈到这里,我们就必须来认识认识忆阻器这个非线性电路元件了。
忆阻器的发展
忆阻器英文名为memristor, 也被称为阻变存储器(RRAM),用符号M表示,与电阻R,电容C,电感L构成四种基本无源电路器件。它是连接磁通量与电荷之间关系的纽带,同时具备电阻和存储的性能,是一种新一代高速存储单元。其功耗,读写速度都要比传统的随机存储器优越,是硬件实现人工神经网络突触的最好方式,主要应用于非易失存储、逻辑运算以及类脑神经形态计算。
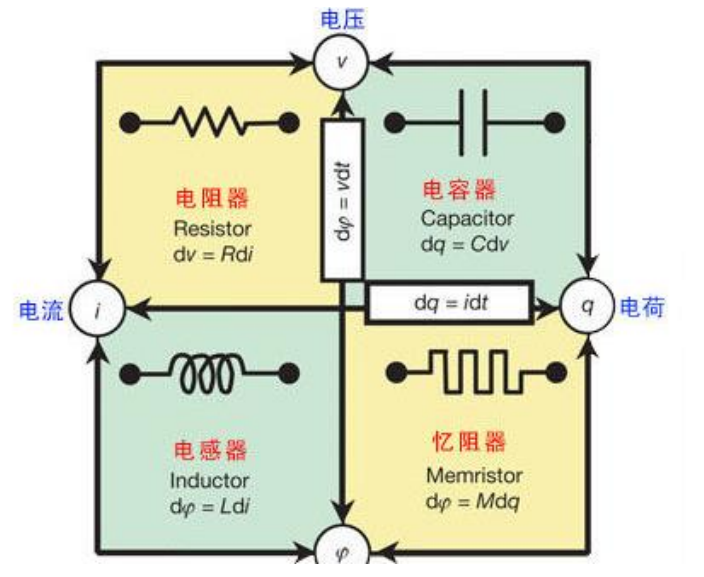
忆阻器全称记忆电阻,是一种具有电荷记忆功能的非线性电阻,于1971年,由加州大学伯克利分校的华裔科学家蔡少棠教授提出。蔡教授从电路完整性角度出发,从数学上推导出忆阻器的概念。不过,由于缺乏实验的支撑,而且传统存储器在工艺上和摩尔定律契合的很好,一直在刷新着自己的存储极限,所以在那之后的很长一段时间,人们认为没有必要花费时间和金钱去研究忆阻器。
忆阻器发展的拐点,发生在2000年之后。2000-2008年,A Beck等人在Cr掺杂的SrZrO3中观察到忆阻器滞回曲线,并指出器件具有存储功能,2006年HP实验室证明了Crossbar RRAM,并于2008年在《Nature》发表了“下落不明的忆阻器找到了”的相关文章,同年,HP公司制备出忆阻器。科学家们开始意识到忆阻器的优势和作用,全世界相关科学家都纷纷参与到忆阻器的研究中来,忆阻器研究高潮就此到来。
类脑计算及神经形态计算是当今科研热点之一,忆阻器是神经元网络的核心器件,它为发展信息存储与处理融合的新型计算体系架构,突破传统冯·诺伊曼架构瓶颈,提供了可行的路线,其性能直接影响神经元网络的计算能力。
下面为大家分享一段教学视频,是清华大学高滨教授主讲的“忆阻器存算一体芯片与类脑计算”。高滨老师表示,现有计算系统普遍采用存储和运算分离的架构,存在存储墙与功耗墙瓶颈,严重制约了系统算力和能效的提升。存算合一的电子突触就是忆阻器。不过,忆阻器也面临着严峻的挑战。核心挑战之一是器件非理想特性,即忆阻器件性能存在离散性和不稳定性,严重影响计算精度;另一个关键挑战就是模拟计算的误差累积。
高滨教授介绍,解决的办法就是存算一体芯片的协同设计。存算一体芯片急需跨层次的协同优化方案,单一层面的优化已经难以达到高性能。其实忆阻器研究的每一次推进和成功,都离不开测试设备提供的数据支持。高滨表示:“测试设备的进步,为忆阻器的研发做出了重要的贡献!”
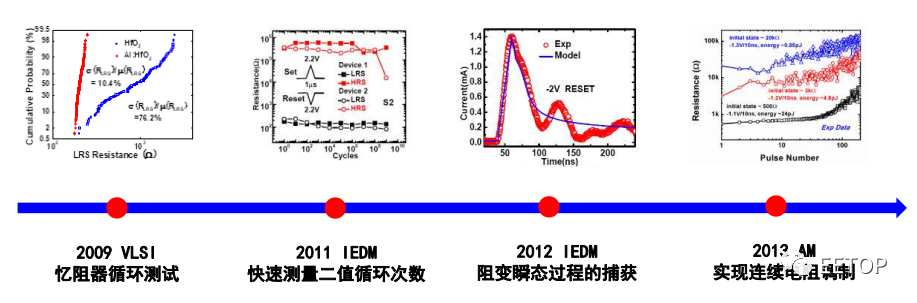
高滨教授关于忆阻器研究的几个关键时间点
忆阻器电学测试现状与展望
存算一体技术对忆阻器特性要求非常高,测试难度也很大。通常,忆阻器的测试可分为三大类,即:
忆阻器基础研究测试,包括忆阻器参数表征、分类及测试流程,以及分析器件在相应的交流、直流、脉冲电信号作用下的忆阻特性;
忆阻器性能研究特性,旨在提高忆阻器存储性能和模拟神经元的性能,如功耗、擦写速度、集成度和可靠性等各方面;
最后是忆阻器集成及应用研究测试,忆阻器单元集成结构是实现阵列忆阻器的关键,如1T1R、1TNR等cell及阵列结构的测试。
如果忆阻器被用于神经元方面的研究,其性能测试除了擦写次数和数据保留时间外,还需要进行神经突触阻变动力学测试。
结束语
在 AI 算力需求暴涨下,存算一体被认为是突破算力瓶颈最有前景的新赛道。目前,国内外很多科技企业及初创公司都在积极开展相关的研发。据相关预测数据显示,到 2030 年,基于存算一体技术的芯片市场规模有望超过千亿人民币。忆阻器在数据存储、存算一体、类脑计算等领域将发挥越来越重要的作用。目前,忆阻器已经具备在先进CMOS工艺平台集成的能力。不过,忆阻器依然面临着严峻的挑战,核心挑战之一是器件非理想特性,即忆阻器件性能存在离散性和不稳定性,严重影响计算精度;另一个关键挑战就是模拟计算的误差累积。
基于忆阻器的存算一体变革性技术正成为学术界和产业界关注的前沿热点。未来仍期待在多通道快切换、高时间分辨等方面取得更大进步。期待***走的更远、更高、更好!
-
领跑芯片圈、高效类脑计算|忆阻器是如何发展至今的?#芯片 #电脑 #显卡 #忆阻器 #AI #存算一体安泰小课堂 2023-11-16
-
一体成型贴片电感在使用中发热究竟是否会影响运行2023-11-13 466
-
忆阻器,你了解吗?全球首颗清华忆阻器存算一体芯片究竟是个啥?2023-10-27 2410
-
忆阻器(RRAM)存算一体路线再次被肯定2023-10-26 3407
-
忆阻器存算一体芯片新突破!有望促进人工智能、自动驾驶等领域发展2023-10-20 7622
-
我国芯片突破!清华大学全球首枚!2023-10-14 1286
-
清华团队研制成功,全球首颗支持片上学习忆阻器存算一体芯片2023-10-13 1814
-
清华大学重磅消息:全球首颗!我国芯片领域取得重大突破2023-10-11 1595
-
基于忆阻器存算一体芯片研究进展、总结与展望2022-12-23 3541
-
基于忆阻器存算一体芯片的研究进展2022-12-12 2983
-
一文读懂eMMC究竟是啥?2021-06-18 4041
-
图解:IGBT究竟是什么?2020-08-10 2756
-
中国制造的全球首款多阵列忆阻器存算一体系统问市2020-04-27 1862
-
清华大学的存算一体化架构和并行加速方法专利2020-03-14 5272
全部0条评论

快来发表一下你的评论吧 !
