

LLaMA2上下文长度暴涨至100万tokens,只需调整1个超参数
描述
只需微调一下,大模型支持上下文大小就能从1.6万tokens延长至100万?!
还是在只有70亿参数的LLaMA 2上。
要知道,即使是当前最火的Claude 2和GPT-4,支持上下文长度也不过10万和3.2万,超出这个范围大模型就会开始胡言乱语、记不住东西。
现在,一项来自复旦大学和上海人工智能实验室的新研究,不仅找到了让一系列大模型提升上下文窗口长度的方法,还发掘出了其中的规律。

按照这个规律,只需调整1个超参数,就能确保输出效果的同时,稳定提升大模型外推性能。
外推性,指大模型输入长度超过预训练文本长度时,输出表现变化情况。如果外推能力不好,输入长度一旦超过预训练文本长度,大模型就会“胡言乱语”。
所以,它究竟能提升哪些大模型的外推能力,又是如何做到的?
大模型外推能力提升“机关”
这种提升大模型外推能力的方法,和Transformer架构中名叫位置编码的模块有关。
事实上,单纯的注意力机制(Attention)模块无法区分不同位置的token,例如“我吃苹果”和“苹果吃我”在它眼里没有差异。
因此需要加入位置编码,来让它理解词序信息,从而真正读懂一句话的含义。
目前的Transformer位置编码方法,有绝对位置编码(将位置信息融入到输入)、相对位置编码(将位置信息写入attention分数计算)和旋转位置编码几种。其中,最火热的要属旋转位置编码,也就是RoPE了。
RoPE通过绝对位置编码的形式,实现了相对位置编码的效果,但与相对位置编码相比,又能更好地提升大模型的外推潜力。
如何进一步激发采用RoPE位置编码的大模型的外推能力,也成为了最近不少研究的新方向。
这些研究,又主要分为限制注意力和调整旋转角两大流派。
限制注意力的代表研究包括ALiBi、xPos、BCA等。最近MIT提出的StreamingLLM,可以让大模型实现无限的输入长度(但并不增加上下文窗口长度),就属于这一方向的研究类型。
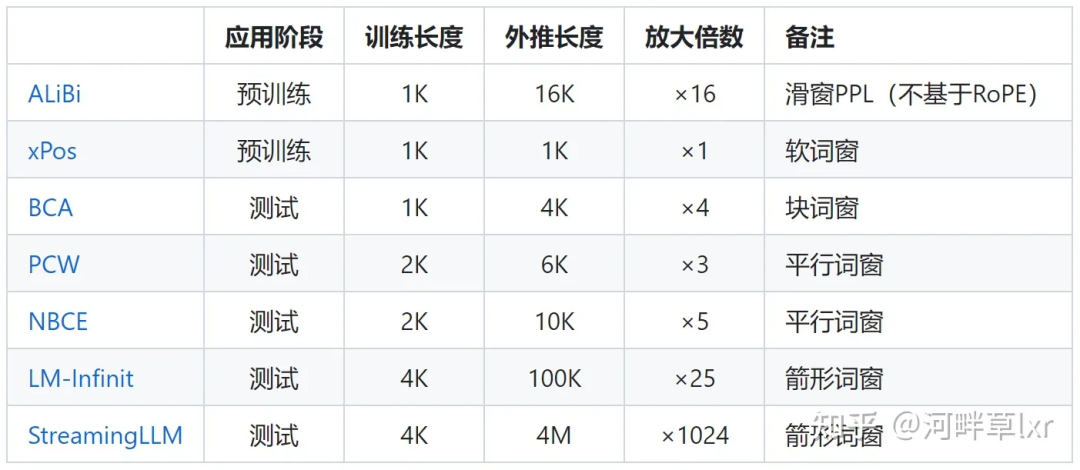
△图源作者
调整旋转角的工作则更多,典型代表如线性内插、Giraffe、Code LLaMA、LLaMA2 Long等都属于这一类型的研究。
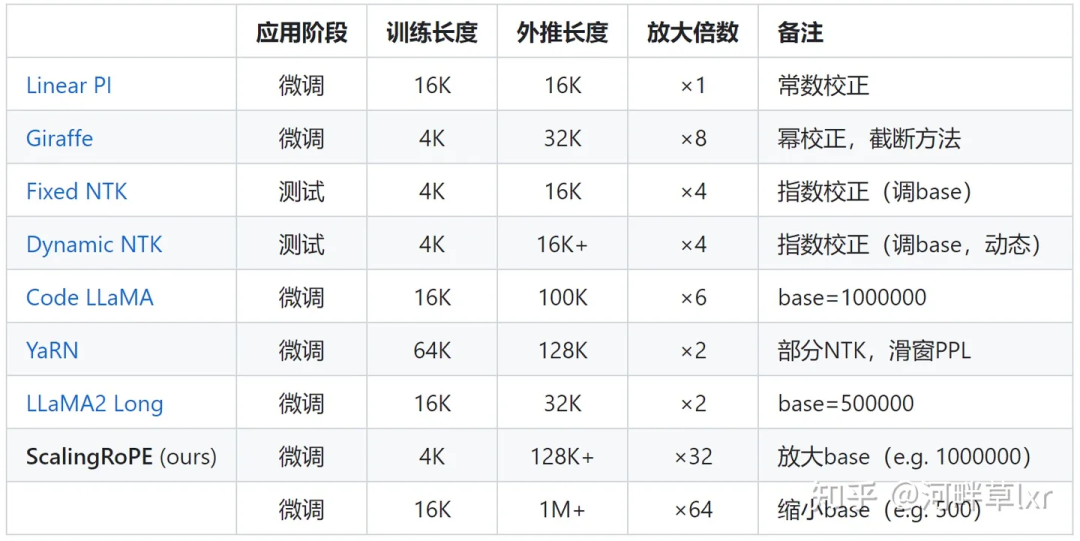
△图源作者
以Meta最近爆火的LLaMA2 Long研究为例,它就提出了一个名叫RoPE ABF的方法,通过修改一个超参数,成功将大模型的上下文长度延长到3.2万tokens。
这个超参数,正是Code LLaMA和LLaMA2 Long等研究找出的“开关”——
旋转角底数(base)。
只需要微调它,就可以确保提升大模型的外推表现。
但无论是Code LLaMA还是LLaMA2 Long,都只是在特定的base和续训长度上进行微调,使得其外推能力增强。
是否能找到一种规律,确保所有用了RoPE位置编码的大模型,都能稳定提升外推表现?
掌握这个规律,上下文轻松100w+
来自复旦大学和上海AI研究院的研究人员,针对这一问题进行了实验。
他们先是分析了影响RoPE外推能力的几种参数,提出了一种名叫临界维度(Critical Dimension)的概念,随后基于这一概念,总结出了一套RoPE外推的缩放法则(Scaling Laws of RoPE-based Extrapolation)。
只需要应用这个规律,就能确保任意基于RoPE位置编码大模型都能改善外推能力。
先来看看临界维度是什么。
从定义中来看,它和预训练文本长度Ttrain、自注意力头维度数量d等参数都有关系,具体计算方法如下:

其中,10000即超参数、旋转角底数base的“初始值”。
作者发现,无论放大还是缩小base,最终都能让基于RoPE的大模型的外推能力得到增强,相比之下当旋转角底数为10000时,大模型外推能力是最差的。
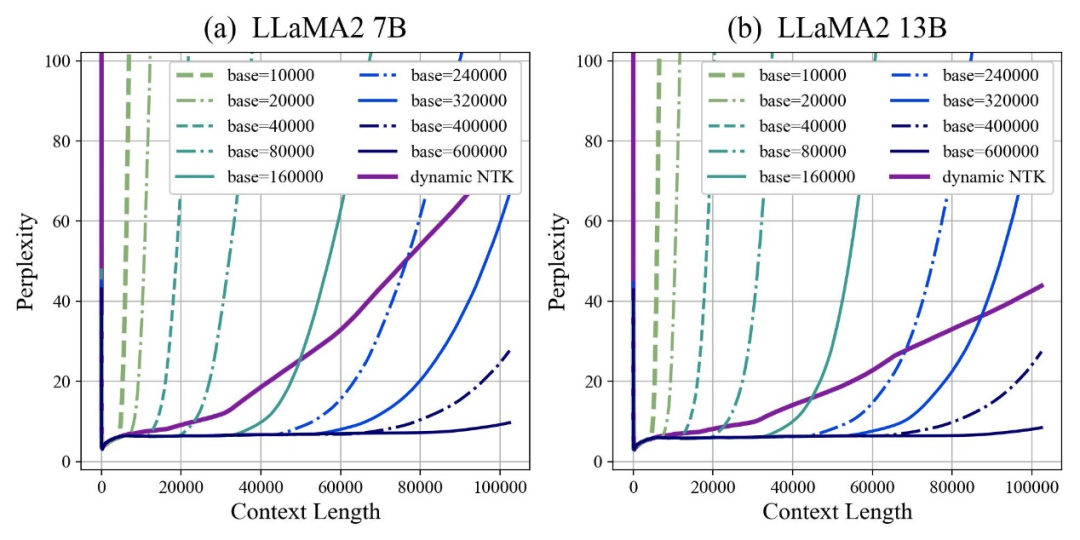
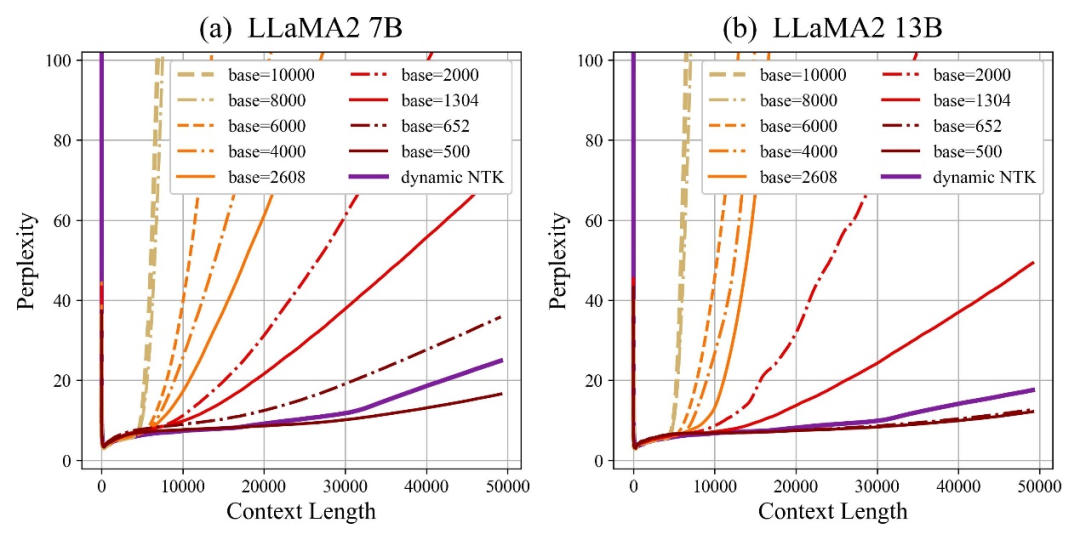
对此论文认为,旋转角底数更小,能让更多的维度感知到位置信息,旋转角底数更大,则能表示出更长的位置信息。
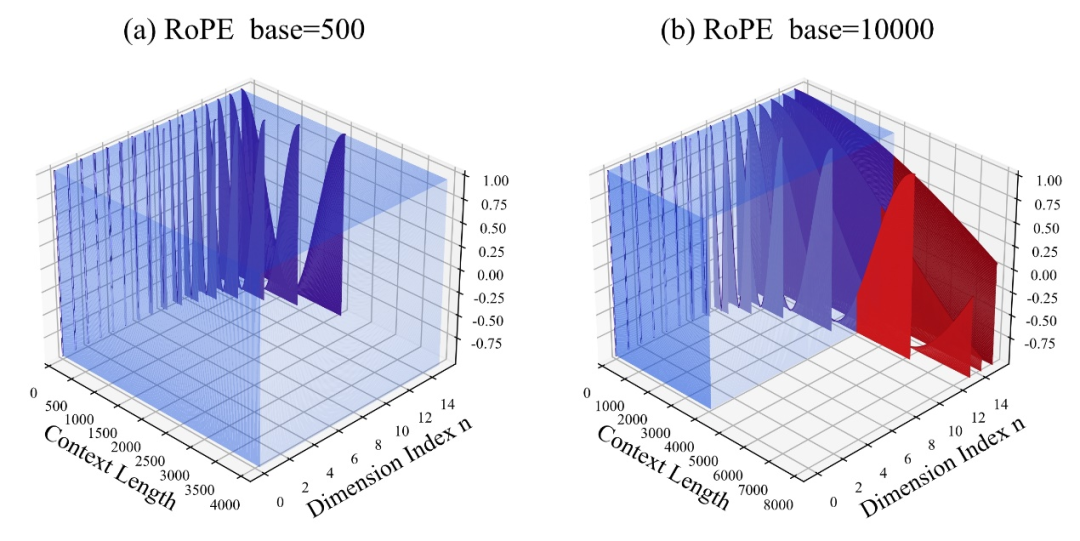
既然如此,在面对不同长度的续训语料时,究竟缩小和放大多少旋转角底数,才能确保大模型外推能力得到最大程度上的提升?
论文给出了一个扩展RoPE外推的缩放法则,与临界维度、大模型的续训文本长度和预训练文本长度等参数有关:

基于这一规律,可以根据不同预训练和续训文本长度,来直接计算出大模型的外推表现,换言之就是预测大模型的支持的上下文长度。
反之利用这一法则,也能快速推导出如何最好地调整旋转角底数,从而提升大模型外推表现。
作者针对这一系列任务进行了测试,发现实验上目前输入10万、50万甚至100万tokens长度,都可以保证,无需额外注意力限制即可实现外推。
与此同时,包括Code LLaMA和LLaMA2 Long在内的大模型外推能力增强工作都证明了这一规律是确实合理有效的。
这样一来,只需要根据这个规律“调个参”,就能轻松扩展基于RoPE的大模型上下文窗口长度、增强外推能力了。
论文一作柳潇然表示,目前这项研究还在通过改进续训语料,提升下游任务效果,等完成之后就会将代码和模型开源,可以期待一下~
-
在线研讨会 | 基于 LLM 构建中文场景检索式对话机器人:Llama2 + NeMo2023-10-13 2102
-
中断中的上下文切换详解2023-03-23 1526
-
如何分析Linux CPU上下文切换问题2022-05-05 3077
-
进程上下文/中断上下文及原子上下文的概念2021-01-13 1133
-
JavaScript的执行上下文2019-05-29 1097
-
进程上下文与中断上下文的理解2018-12-11 3438
-
关于进程上下文、中断上下文及原子上下文的一些概念理解2018-09-06 3906
-
初学OpenGL:什么是绘制上下文2018-04-28 2906
-
Web服务的上下文的访问控制策略模型2018-01-05 974
-
基于上下文相似度的分解推荐算法2017-11-27 997
-
基于Pocket PC的上下文菜单实现2011-07-25 1002
-
终端业务上下文的定义方法及业务模型2010-03-06 654
-
基于交互上下文的预测方法2009-10-04 716
-
基于多Agent的用户上下文自适应站点构架2009-04-11 661
全部0条评论

快来发表一下你的评论吧 !
