

揭秘编码器与解码器语言模型
描述
来源 | OSCHINA 社区
作者 | OneFlow深度学习框架
Transformer 架构的问世标志着现代语言大模型时代的开启。自 2018 年以来,各类语言大模型层出不穷。
通过 LLM 进化树(github.com/Mooler0410/LLMsPracticalGuide)来看,这些语言模型主要分为三类:一是 “仅编码器”,该类语言模型擅长文本理解,因为它们允许信息在文本的两个方向上流动;二是 “仅解码器”,该类语言模型擅长文本生成,因为信息只能从文本的左侧向右侧流动,并以自回归方式有效生成新词汇;三 “编码器 - 解码器” 组,该类语言模型对上述两种模型进行了结合,用于完成需要理解输入并生成输出的任务,例如翻译。
本文作者 Sebastian Raschka 对这三类语言模型的工作原理进行了详细解读。他是人工智能平台 Lightning AI 的 LLM 研究员,也是《Machine Learning Q and AI》的作者。
有人希望我能深入介绍一下语言大模型(LLM)的相关术语,并解释我们现在认为理所当然的一些技术性更强的术语,包括 “编码器式” 和 “解码器式” LLM 等。这些术语是什么意思?
编码器和解码器架构基本上都使用了相同的自注意力层对单词词元(token)进行编码,然而,不同的是:编码器被设计为学习可以用于各种预测建模任务(如分类)的嵌入;解码器被设计用于生成新的文本,例如回答用户的查询等。
1原始 Transformer
原始 Transformer 架构("Attention Is All You Need",2017 年)是为英法和英德语言翻译而开发的,它同时使用了编码器和解码器,如下图所示。
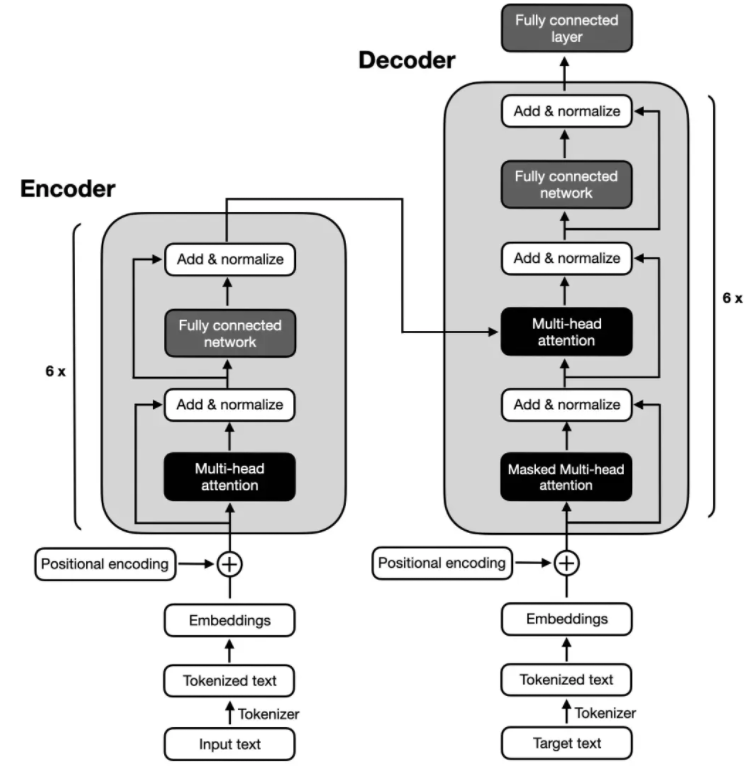
上图中,输入文本(即要翻译的句子)首先被分词为单独的单词词元,然后通过嵌入层对这些词元进行编码,完成后进入编码器部分。接下来,在每个嵌入的单词上添加位置编码向量,之后,这些嵌入会通过多头自注意力层。多头注意力层之后会进行残差与层归一化(Add & normalize),它进行了一层标准化操作,并通过跳跃连接(skip connection,也称为残差连接或快捷连接)添加原始嵌入。最后,进入 “全连接层”(它是由两个全连接层(全连接层之间有一个非线性激活函数)组成的小型多层感知器)之后,输出会被再次 " 残差与层归一化 ",然后再将输出传递到解码器模块的多头自注意力层。
上图的解码器部分与编码器部分的整体结构十分相似,关键区别是它们的输入和输出内容。编码器要接收进行翻译的输入文本,而解码器则负责生成翻译后的文本。
2编码器
上图展示的原始 Transformer 架构中的编码器部分负责理解和提取输入文本中的相关信息,它输出的是输入文本的一个连续表示(嵌入),然后将其传递给解码器。最终,解码器根据从编码器接收到的连续表示生成翻译后的文本(目标语言)。
多年来,基于原始 Transformer 模型中的编码器模块开发了多种仅编码器架构。其中两个最具代表性的例子是 BERT( 用于语言理解的深度双向 Transformer 预训练 2018)和 RoBERTa(鲁棒优化的 BERT 预训练方法,2018)。
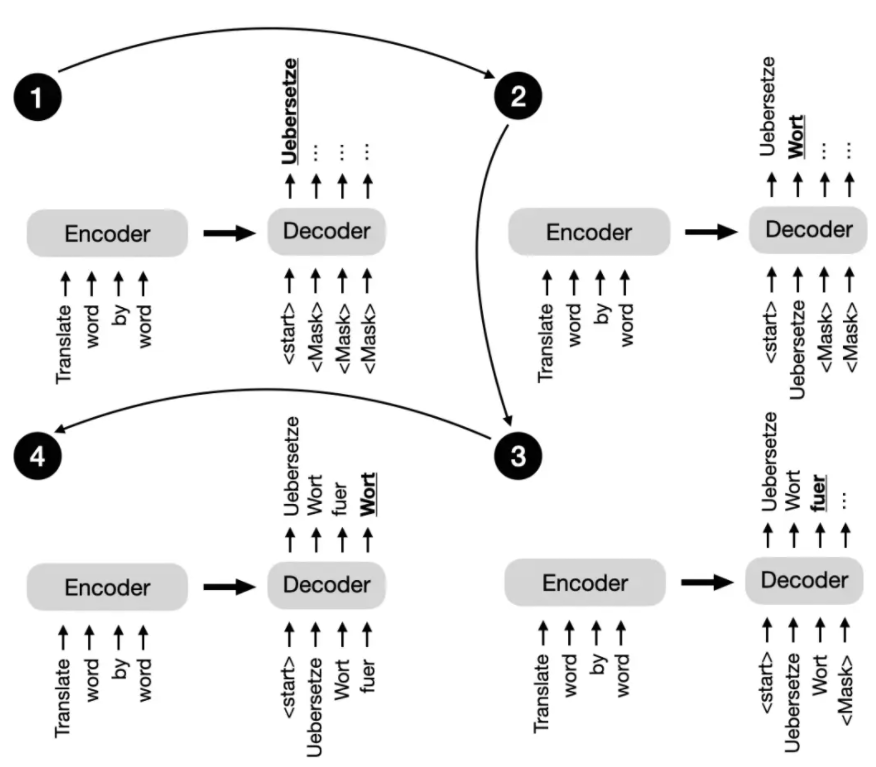
BERT(Bidirectional Encoder Representations from Transformers)是一种基于 Transformer 编码器模块的仅编码器架构,它使用掩码语言建模(如下图所示)和下一个句子预测任务,在大型文本语料库上进行预训练。

BERT 式 Transformer 中使用的掩码语言建模预训练目标图示。
掩码语言建模的主要思路是在输入序列中随机掩码(或替换)一些单词词元,并训练模型根据上下文来预测原始的掩码词元。
除上图所示的掩码语言建模预训练任务之外,下一个句子预测任务要求模型去预测两个随机排列的句子在原始文档中的语句顺序是否正确。例如,两个用 [SEP] 标记分隔开的随机句子:
[CLS] Toast is a simple yet delicious food [SEP] It’s often served with butter, jam, or honey.
[CLS] It’s often served with butter, jam, or honey. [SEP] Toast is a simple yet delicious food.
其中,[CLS] 词元是模型的占位符,提示模型返回一个 True 或 False 标签,用来表示句子顺序是否正确。
掩码语言和下一个句子预训练目标使得 BERT 可以大量学习输入文本的上下文表示,然后可以针对各种下游任务(如情感分析、问答和命名实体识别)对这些表示进行微调。
RoBERTa(Robustly optimized BERT approach)是 BERT 的优化版本。它与 BERT 保持了相同的整体架构,但进行了一些训练和优化改进,例如更大的 batch 尺寸,更多的训练数据,并去除了下一个句子预测任务。这些改进使得 RoBERTa 拥有更好的性能,相比 BERT,RoBERTa 能更好地处理各种自然语言理解任务。
3解码器
回到本节开头的原始 Transformer 架构,解码器中的多头自注意机制与编码器中的类似,但经过掩码处理,以防模型关注到未来位置,确保对位置 i 的预测仅基于已知的小于 i 的输出位置。下图为解码器逐词生成输出的过程。
原始 Transformer 中的下一个句子预测任务示意图。
这种掩码操作(在上图中可明确看到,但实际上在解码器的多头自注意机制内部发生)对于在训练和推理过程中保持 Transformer 模型的自回归特性至关重要。自回归特性能确保模型逐个生成输出词元,并使用先前生成的词元作为上下文,以生成下一个词元。
多年来,研究人员在原始编码器 - 解码器 Transformer 架构的基础上进行扩展,开发出了几种仅解码器模型,这些模型能高效处理各种自然语言任务,其中最著名的是 GPT(Generative Pre-trained Transformer)系列模型。
GPT 系列模型为仅解码器模型,它们在大规模无监督文本数据上进行预训练,然后针对特定任务进行微调,如文本分类、情感分析、问答和摘要生成等。GPT 模型包括 GPT-2、GPT-3(GPT-3 于 2020 年发布,具备少样本学习能力)以及最新的 GPT-4,这些模型在各种基准测试中展现出了卓越性能,是目前最受欢迎的自然语言处理架构。
GPT 模型最引人注目的特性之一是涌现特性。涌现特性指的是模型在下一个词预测的预训练中发展出来的能力和技能。尽管这些模型只是被训练预测下一个词,但预训练后的模型却能够执行各种任务,如文本摘要生成、翻译、问答和分类等。此外,这些模型可通过上下文学习来完成新任务,而无需更新模型参数。
4编码器 - 解码器混合模型
BART (Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension, 2019)
and T5 (Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer, 2019).
除传统的编码器和解码器架构之外,新型编码器 - 解码器模型的发展取得了重大突破,充分发挥了编码器和解码器模型的优势。这些模型融合了新颖技术、预训练目标或架构修改,以提高在各种自然语言处理任务中的性能表现。下面是一些值得关注的新型编码器 - 解码器模型:
BART(用于自然语言生成、翻译和理解的去噪序列到序列预训练模型,2019 年发布)
T5(通过统一的文本到文本 Transformer 来探索迁移学习的极限,2019 年发布)。
编码器 - 解码器模型通常用于自然语言处理,这些任务涉及理解输入序列并生成相应的输出序列。这些序列往往具有不同的长度和结构。这种模型在需要复杂映射以及捕捉输入序列和输出序列之间的元素关系的任务中表现出色。编码器 - 解码器模型常用于文本翻译和摘要生成等任务。
5术语和行话
这些模型(包括仅编码器、仅解码器和编码器 - 解码器模型)都属于序列到序列模型(通常简称为 “seq2seq”)。值得注意的是,虽然我们将 BERT 模型称为仅编码器模型,但 “仅编码器” 这个描述可能会引起误解,因为这些模型在预训练期间也会将嵌入解码为输出的词元或文本。
换句话说,仅编码器和仅解码器架构都在进行 “解码”。然而,与仅解码器和编码器 - 解码器架构不同,仅编码器架构不是以自回归的方式进行解码。自回归解码是指逐个词元地生成输出序列,其中每个词元都基于先前生成的词元。相比之下,仅编码器模型不会以这种方式生成连贯的输出序列。相反,它们专注于理解输入文本并生成特定任务的输出,如标签预测或词元预测。
6结论
简而言之,编码器模型在学习用于分类任务的嵌入表示方面非常受欢迎,编码器 - 解码器模型用于生成任务,这些任务依赖输入,以生成输出(例如翻译和摘要生成),而仅解码器模型则用于其他类型的生成任务,包括问答。
自首个 Transformer 架构问世以来,已经开发出数百种编码器、解码器和编码器 - 解码器混合模型,模型概览如下图所示:
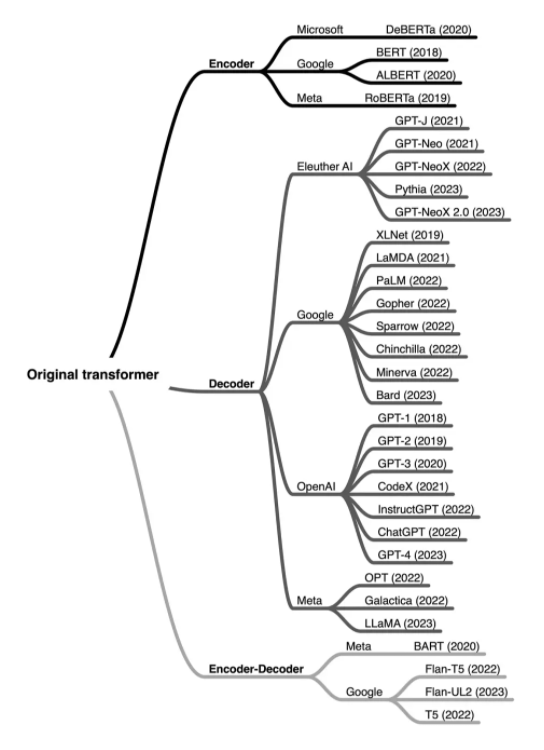
按架构类型和开发者分类的部分最受欢迎的大型语言 Transformer。
尽管仅编码器模型逐渐失去了关注度,但 GPT-3、ChatGPT 和 GPT-4 等仅解码器模型在文本生成方面取得了重大突破,并开始广泛流行。然而,仅编码器模型在基于文本嵌入进行预测模型训练方面仍然非常有用,相较于生成文本,它具备独特优势。
审核编辑:汤梓红
-
YXC丨视频编码器与解码器的应用方案2023-08-23 1634
-
视频编码器与解码器的应用方案2023-08-14 2711
-
详解编码器和解码器电路2023-07-14 5970
-
神经编码器-解码器模型的历史2023-06-20 2120
-
基于 Transformers 的编码器-解码器模型2023-06-16 2083
-
基于 RNN 的解码器架构如何建模2023-06-12 2066
-
基于transformer的编码器-解码器模型的工作原理2023-06-11 3355
-
PyTorch教程-10.6. 编码器-解码器架构2023-06-05 1814
-
详解编码器和解码器电路:定义/工作原理/应用/真值表2022-11-03 9386
-
信路达 解码器/编码器 XD74LS48数据手册2022-08-19 988
-
基于结构感知的双编码器解码器模型2021-05-26 1273
-
怎么理解真正的编码器和解码器?2020-09-01 2464
-
编码器和解码器的区别是什么,编码器用软件还是硬件好2018-08-02 35556
全部0条评论

快来发表一下你的评论吧 !
