

如何使用Rust创建一个基于ChatGPT的RAG助手
电子说
描述
如今,ChatGPT 已经成为家喻户晓的名字,每个开发者都主动或被动地使用过 ChatGPT 或者是基于 ChatGPT 的产品。ChatGPT 很好,但是应用到实际工作与生活场景,ChatGPT 经常会出现一些幻觉,“一本正经”地为我们提供一些错误答案,没有办法为我们提供专业的意见或指导。那我们如何让 ChatGPT 具备某个专业领域的知识,提升回答的正确率,从而让 ChatGPT 真的用起来?比如训练 ChatGPT 成为企业的智能客服助手,解放客服的双手。
如何构建一个具有专业知识的机器人
为了解决这个问题,一般我们有两种解决方法。第一种是利用自己的数据在大模型的基础上进行 fine-tune(微调),训练出一个具备相关领域的知识的大模型,另一种方法称作 RAG (Retrieval-Augmented Generation),检索增强生成,利用向量数据库的能力,将专业的知识数据转换成多个向量,然后再利用大模型的能力进行检索,最后回答问题。两种方法各有自己的优势和劣势,总体来说,尽管 RAG 的准确度不如 fine-tune 高,但是 RAG 的性能比更适合普罗大众,因为 RAG 更简化,更高效。RAG 的优势有以下几点:
相较于微调大模型需要 GPU 算力等硬件设备支持,RAG 只需要在软件层面添加向量数据库,操作起来更加简单,成本也更低。
当有数据更新时,RAG 允许开发者通过添加新的 embedding 以保证内容的时效性,但是微调大模型则需要反复重新训练模型,耗费资源比较多
| fine-tune | RAG | |
|---|---|---|
| 是否需要 GPU 资源 | 是 | 否 |
| 开发周期 | 长 | 短 |
| 更新/删除知识 | 需要重新训练 | 更新 embedding |
| 适合场景 | 赋予大模型某种能力 | 赋予大模型某种知识 |
| 结果准确度 | 高于 RAG | 低于 fine-tune |
如何使用 Rust 创建一个基于 ChatGPT 的 RAG 助手
常见的构建 RAG 助手的工具是以 Python 为主的 langchain,但是如何使用 Rust 来构建呢?这就需要我们有一套围绕 Rust 语言打造的 LLM 工具链。flows.network 就是这样一个专门为 Rust 开发者打造的构建 LLM Agent 的平台。和 langchain 一样,flows.network 为 Rust 开发者包装了常用的 LLM 工具库,比如 ChatGPT 、Claude、Llama2 以及我们常用的 SaaS 工具 GitHub 、Discord、Telegram、Slack。但是更进一步的是,flows.network 是一个 serverless Rust 平台,开发者只需构建业务逻辑,编译以及部署 Rust 函数都由平台完成。
具体到构建基于 ChatGPT 的 RAG 助手,flows.network 已经开源了一套开箱即用的框架供 Rust 开发者使用。最近新发布 Learn Rust 助手就是基于这套框架所实现的。
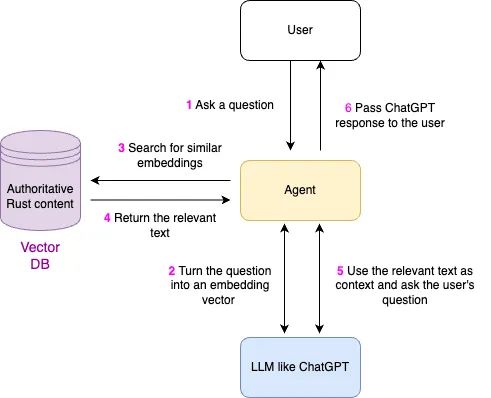
为了方便大家理解基于 ChatGPT 的 RAG 助手,我在这里补充了一张在 Learn Rust 助手询问问题的流程图。从用户问一个问题开始,Agent 就要和向量数据库和 LLM 打交道,为没有记忆的大模型补充手脚、眼睛和记忆。
下面我们来详细看看怎么使用 Rust 构建 RAG 助手。开源的代码分为两部分,一部分是利用向量数据库创建 embedding,另一部分是把加好 embedding 的向量数据库与我们常用的工具结合起来。这两部分代码都是完全用 Rust 编写的。
这篇文章主要聚焦如何搭建 RAG 知识库助手,不会对代码进行详细解释。对源代码感兴趣的朋友,敬请期待我们下一篇文章。
首先先来看第一部分在向量数据库中创建 embedding。
在创建 embedding 的这个 demo repo 我们需要做三件事:
fork 这个 repo,把文件 text1.txt 里的内容换成自己的内容。这里要注意 embedding 的方法,要把相似的内容放在一个 embedding 里,每个空行代表一个 embedding。你也可以直接在本地存储自己的 embedding。
将 RAG-embedding repo 的代码部署在 flows.network 上,得到一个可以访问向量数据库的 webhook。
在这个 webhook 中添加 embedding 的内容以及命名 collection。
第一步是主要是开发者自己的工作,你可以选择手动分段,也可以选择使用算法进行分段。
第二步需要用到 flows.network, 简单来说,我们需要把包含源代码的 repo 导入到 flows.network 平台,并且添加 OpenAI 的 API key。因为把 text 转换成 embedding 的工作是调用 OpenAI 的 embedding API 完成的。部署完成后,我们会在页面看到一个 webhook 链接。这个 webhook 链接需要保存下来,因为接下来我们将通过这个 wbhook 添加 embedding 的内容。
// webhook 示例 https://code.flows.network/webhook/I9GNgD5HKhFLY25DsOUI
第三步是用 curl 为这个向量数据库添加 embedding 内容。打开终端命令行工具,输入下面的命令行。
// 获取源代码及准备好的 txt 文件 git clone https://github.com/alabulei1/demo-RAG-embeddings.git cd demo-RAG-embeddings // 上传创建好的 embedding 文件。 // Webhook 链接要替换成在 flows.network 生成的链接 // collection_name 可以随意替换,要记住这个名字,后面需要用到 // "@test1.txt" 根据实际情况替换即可 curl "https://code.flows.network/webhook/I9GNgD5HKhFLY25DsOUI?collection_name=laokeshi&vector_size=1536&reset=1" -X POST --data-binary "@test1.txt" //添加成功后,终端会提示总共创建了多少个 embedding Successfully inserted 7 records. The collection now has 7 records in total
看到终端输出如上的命令行,就意味着我们的 embedding 已经创建好了。
下面的视频展示了如何在 flows.network 上部署这个创建 embedding 的 repo,并且在得到 webhook 链接后,如何把 embedding 添加到向量数据库。
接下来就可以将这些 embedding 与其他 SaaS 工具自由组装。这时候就用到我们的第二个 demo repo:使用这些 embedding 创建一个 discord 机器人(Agent),让用户能够在 Discord 直接咨询相关问题。
同样,我们需要将 RAG-discord-bot demo repo 导入到 flows.network 进行部署。我们需要配置五个环境变量。discod_token 和 bot_id 是设置 Discord 机器人的。这两个参数在 Discord 的开发者中心获取。
还有一个 collection_name ,这里要填入我们在上一步创建 embedding 的是所设置的 collection_name 的值, 让 Discord agent 知道去找哪个数据库检索相关内容。
另外两个是 Agent 本身的信息。error-mesg 是发生错误时,给用户的错误提示信息,system_promopt 是 agent 总的 Prompt,给 ChatGPT 规划任务。
同样,下面有一个视频展示了如何在 flows.network 上导入 github repo,创建这个 Discord 机器人。
当 flow 的状态变成 ready 后,就可以去 server 里找刚刚创建的 Discord 机器人,让这个 Discord 机器人回答问题。注意,这时的 Discord 机器人应该是 online 的状态,如果 Discord 机器人是 offline 的状态,请检查 Discord 机器人是否设置正确。
这就是使用 Rust 创建一个基于 ChatGPT 的 RAG 助手的全部过程。当然你也可以把 ChatGPT 换成其他的大模型,比如 Llama2。
使用 Rust 构建 LLM Agent 并没有那么难!如果你正在发愁不知道怎么把 Rust 用起来,来试试构建这个 RAG Agent 吧。你可以构建企业手册助手、开发手册助手、开源项目助手等等。
下一篇文章,我们将详细解读这个 RAG 助手的 Rust 源代码,帮助大家更好地理解这背后的原理。敬请期待!
审核编辑:汤梓红
-
高质量RAG系统的五个核心设计要点2026-04-24 404
-
RAG(检索增强生成)原理与实践2026-02-11 11099
-
和安信可Ai-M61模组对话?手搓一个ChatGPT 语音助手 #人工智能 #jf_31745078 2025-03-12
-
如何用Rust编写一个ChatGPT桌面应用(保姆级教程)2024-09-25 1300
-
如何手撸一个自有知识库的RAG系统2024-06-17 1816
-
什么是RAG,RAG学习和实践经验2024-04-24 3514
-
Rust GUI实践之Rust-Qt模块2023-09-30 3233
-
Rust的多线程编程概念和使用方法2023-09-20 2417
-
如何使用Rust连接Redis2023-09-19 3907
-
在Rust代码中加载静态库时,出现错误 ` rust-lld: error: undefined symbol: malloc `怎么解决?2023-06-09 1100
-
一个用Rust开发的压测工具rsb2023-03-21 1549
-
科技大厂竞逐AIGC,中国的ChatGPT在哪?2023-03-03 2404
-
一个用于打印漂亮的Rust结构和枚举表tabled2022-10-09 2354
-
只会用Python?教你在树莓派上开始使用Rust2020-05-20 4045
全部0条评论

快来发表一下你的评论吧 !
