

异构计算为什么会异军突起?基于FPGA的异构计算讨论
可编程逻辑
描述
一、异构计算ABC
简单的介绍几个概念,同道中人可以忽略这一段。云计算取代传统IT基础设施已经基本成为业界共识和不可阻挡的趋势。云计算离不开数据中心,数据中心离不开服务器,而服务器则离不开CPU。当然,世事无绝对,上述三个“离不开”自然是针对当下以及并不久远的未来而言。而异构计算的“异构”指的是“不同于”CPU的指令集。
异构计算听起来是一个高大上兼不明觉厉的概念,实际上,我们大致可以用“加速协处理器”的概念来替代异构计算,这样理解起来也许就容易多了。云计算在最开始指的就是基于CPU的计算,异构计算异军突起之后,云计算就分成了基于CPU的通用计算和基于CPU+FPGA、CPU+GPU的异构计算。
可能有的读者说:CPU+ASIC难道不是异构计算么?当然算,只不过,抛开ASIC的优点(高性能、大批量前提下的低成本)不说,ASIC的高开发成本(进入10nm工艺时代,流一次片可能动辄几百万乃至数千万美元)和长上市时间(从立项到上市最少也要一到两年的时间)是两个非常不利的因素。因为目前异构计算所针对的垂直行业都具有快速变化、快速迭代的特点,是ASIC完全没有办法满足的。所以到目前为止,基于ASIC的异构计算占比极少,基本可以忽略不计。
本文聚焦于讨论基于FPGA的异构计算,为了行文方便起见,下文中提到异构计算就是指FPGA异构计算。
下面的图、表对CPU、GPU、FPGA和ASIC各自的优劣势进行了简单的比较:
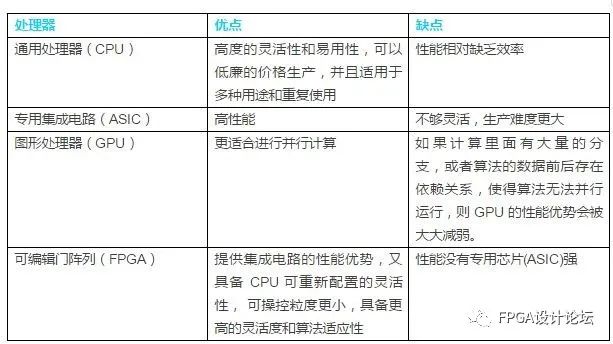
表1:CPU、ASIC、GPU、FPGA特性简单对比
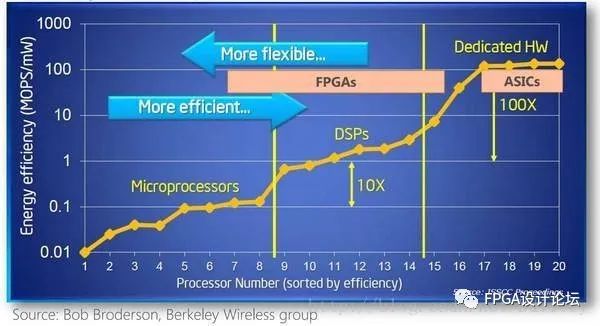
图1:CPU、ASIC、GPU、FPGA能效与灵活性对比
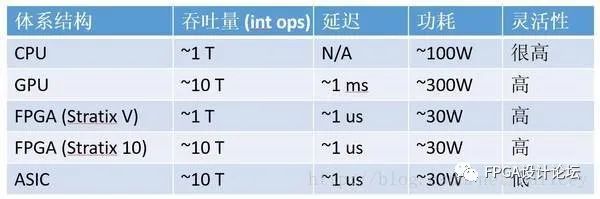
图2:计算密集型任务,CPU、GPU、FPGA、ASIC的数量级比较(16位整数乘法)
二、为什么要异构计算
异构计算为什么会异军突起?其实假如CPU一直很牛很牛,可以完全满足客户对于“计算”的海量需求,那就没有FPGA什么事儿了。当然了,CPU一直在摩尔定律的驱动下变的越来越牛,可是一来客户的需求变的比CPU的能力更牛,二来随着芯片工艺的推进,摩尔定律渐有失效的迹象,CPU越来越需要一位具备“专业”加速能力的伙伴了。
纵观CPU的演进历史,我们可以看到为了跟上摩尔定律的步伐,业界可谓是出了浑身解数。第一板斧就是通过不断的提升工作的主时钟频率来提高效率:时钟频率越高,意味着单位时间内可以执行的指令越多,从而提升了效率。但是时钟频率不可能无限提高,因为CPU本质上也是一种ASIC,也是由一个个的晶体管、一个个的逻辑门组成的,而晶体管、逻辑门都需要特定的充放电时间来完成“0”、“1”状态的转换。这个特定的充放电时间就决定了CPU工作时钟的时钟周期,也就决定了时钟频率。
提升时钟频率遇到了天花板,业界又想出了第二板斧:“多任务、多线程”,让CPU可以“同时”做两件乃至更多件事情,如同周伯通的“一心二用”,从而可以“左右互搏”,这当然是神话。CPU终究是一个“分时复用”的东东,再牛叉的CPU,同一时刻也只能跑一条指令。多任务多线程的实质不过是充分利用CPU执行某个任务时的“空闲”时间来干点别的活儿,假如某个任务长期100%霸占CPU,那么再多的任务和线程也没什么用,只能乖乖等着。
紧接着第三板斧又来了:多核。就是在一个package里面封装多个物理核,理论上多核CPU就相当于之前同等数量的单核CPU。但是这些核之间是需要通信协同的,这就导致了性能的降低,比如一颗双核CPU的效能大致等同于1.8颗单核CPU。而且由于散热、封装等因素的限制,也不可能在一个package里塞下几百上千个核,尽管Intel已经推出了96核的CPU。多核还面临DarkSilicon的问题,依靠增加核数来提升CPU性能之路已经走到尽头。关于什么是DarkSilicon,简单的说就是由于功耗的限制,多核CPU中可以同时以最高性能工作的核数是非常有限的,其他的核都处于闲置状态。如果想进一步了解可以参考如下网页:https://zhuanlan.zhihu.com/p/20833753。
除了上述三板斧,业界暂时没有再找到可以大幅提升CPU计算力的办法,而在某些特定领域,对CPU算力的需求简直是贪得无厌、无穷无尽的,比如深度学习、图像和视频转码等,这时候FPGA的“空间”计算力就可以大显身手了。
其实异构计算的兴起要感谢AI和GPU。AI离不开各种xNN,也就是神经网络,CPU算起来真是力不从心,而GPU则似乎天生适合干这个活儿(训练)。因此,随着过去两三年AI的炙手可热,GPU异构计算也风生水起,nVidia的股价居然在一年时间内暴涨三倍(当然不全是异构计算导致的显卡需求暴增,还有数字货币带动的挖矿产业)。
所以,归纳起来,异构计算之所以会兴起,就是因为在某些特定行业或者特定应用场景,采用CPU作为算力解决方案的性价比是不高的。而根据这些不同的行业或者场景来选用CPU+GPU或者CPU+FPGA做解决方案的性价比则是很高的。CPU、GPU和FPGA各自“天生”的特性决定了它们都有各自最擅长(或者说性价比最高)的应用领域,在这些领域里,CPU+GPU或者CPU+FPGA的组合而不是纯CPU组合,是最优的解决方案。从纯技术的角度来争论CPU、GPU和FPGA孰优孰劣不是一件很有意义的事情,一定要从解决方案和商业的角度来做对比才更有说服力。
三、FPGA异构计算的钱景
马老师说了,每天做着可以改变世界的事情,就会打满鸡血,充满激情。我斗胆替马老师接一句:做好了这些改变世界的事情,wholebunchofmoney就是自然而然的结果。我一直的观点是:技术是为商业服务的,技术只是手段,商业成功才是目的。因此见客户一定要先谈钱:使用阿里云的FPGA加速解决方案,既能帮您挣钱,又能帮您省钱,这样客户才会开开心心的掏钱。然后再谈情怀,谈诗和远方,光跟客户谈诗和远方,会被客户轰出来的。
基于上面的分析,我们来看看FPGA异构计算的钱景如何。先看下图(预测数据来自前瞻产业研究院):
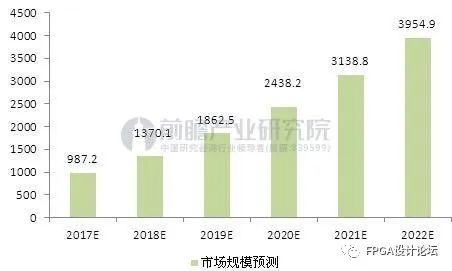
图3:2017-2022年中国数据中心市场规模预测(单位:亿元)
可以看到2020年中国数据中心市场规模可达近2500亿元人民币,约400亿美元。按照阿里云占据一半市场份额来计算,则为200亿美元。根据Intel发布的白皮书预测,到2020年,通用计算市场与异构计算市场会是一个7:3的比例,至于这三成的异构计算市场里面GPU和FPGA的占比如何,要看各自所适合的垂直行业的发展情况。我们姑且认为GPU和FPGA各占15%,那么FPGA异构计算市场规模为30亿美元,对比整个阿里云2017年全年营收133亿人民币(预计2020年超800亿,届时异构计算可能占比三成,达到240亿人民币),可见FPGA异构计算的市场钱景是相当可观的。
我个人坚定的看好FPGA异构计算的未来(学习博士当年坚持搞阿里云的精神和不达目的不罢休的劲头:nottobelievebecauseIseebuttoseebecauseIbelieve)。随着云计算逐步变成和水电煤气一样的基础设施,整个市场容量要以万亿乃至数十万亿美元来计算。FPGA异构计算即使只占10%,那也是千亿美元的大市场。
在未来的云计算、数据中心市场,纯CPU、CPU+GPU和CPU+FPGA的解决方案将长期并存下去,中、短期看,是一个CPU+GPU/CPU+FPGA方案不断蚕食纯CPU方案的过程。在这个过程中,CPU厂商、FPGA厂商也会为了巩固自己的地盘兼抢夺别人的地盘,基于各自的优势,选择提供一揽子芯片解决方案。比如CPU厂商会推出内嵌FPGA/GPU的超级CPU;而可编程逻辑器件厂商则会在FPGA器件中嵌入CPU和GPU硬核。
对于提供FPGAasaService(FaaS)的云服务提供商来说,FPGA异构计算能否成功的关键则在于IP生态的建设。IP解决方案齐全的云服务提供商,未来可以像搭乐高积木一样,迅速的为客户“量身定做”出性价比最高的解决方案,并通过自己的FaaS平台向客户输出,而缺乏IP生态的厂商则很难得到客户的青睐。
四、HLS与RTL—从菜刀到小李飞刀
在FPGA设计领域,HLS是HighLevelSynthesis(高层次综合)的缩写,RTL是RegisterTransferLevel(寄存器传输级)的缩写。顺便吐槽一下,从事ICT行业,就要不断的面对各种各样的缩写,很烦人,但是呢,表达效率确实很高。汉语也有类似缩写:比如喜大普奔、不明觉厉、男默女泪、火钳刘明,等等,等等。
1998年,作为新鲜出炉的大菜鸟一只,我加入了一家通信公司,职责是开发一块单板。就是画PCB、写单板软件、设计FPGA乃至到最后的焊板子等等全部自己搞定。那时候根本不知道硬件描述语言为何物,只能向当时的老鸟学习使用74系列集成电路来做FPGA设计。虽说不是一个逻辑门一个逻辑门的来搭电路,其实也差不多了。可想而知,这样做的效率能高到哪里去。但是这样做也有好处:你对整个电路了然于胸,可以清楚的知道到哪个时钟节拍哪个门该反转、哪个三八译码器该输出什么码、哪个移位寄存器的输出应该是什么。况且,那时候的FPGA和CPLD的容量都小,所以这么做效率上也没啥违和感。
等到了1999、2000年左右,XILINX开始推出Virtex系列时,这个办法就不太灵了:FPGA的电路规模已经太大,再画图设计的话,周期可能要两年乃至三年,完全抹杀了FPGA灵活可编程、上市时间短的优势。被逼无奈之下,自己开始学习VerilogHDL,摸索如何使用第三方综合工具来综合(那时候XILINX的ISE和Altera的Quartus综合和仿真功能都很弱)、使用第三方工具来做仿真。也要感谢当时同一个小团队的另一只老鸟(老鸟姓鲁,对我真是倾囊相授),给了我很多指点,非常无私的那种。我朴素的认为一花独放不是春、大家好才是真的好,于是就开始写各种教程、制定大规模FPGA的整套开发流程、写课件给同事讲课。事情越闹腾越大,引起了上层的注意,就把我跟另一个部门做FPGA的几个老鸟给抓到了一起,封闭了半年之久,整天啃各种各样的“工程类”的书籍。最终我们输出了“XX公司逻辑设计LCMM流程1.0”。LCMM就是LogicCMM,因为当时CMM很流行,各家软件公司都标榜自己是CMM3/4/5,我们就无耻的蹭了一下CMM的流量。
Verilog和VDHL都是基于RTL层级的硬件描述语言(HDL)。相对而言,Verilog灵活性高一些,而VHDL语法更严谨一些。综合工具很容易把HDL的描述映射成相应的硬件电路,所以综合工具把精力放在如何更高效上:比如综合时间尽可能短、综合效率尽量高(占用面积低、时钟运行频率高)。HDL相比画电路图,在“电路”效率上可能要低一些,因为毕竟多了一层抽象;但是在开发效率上,那可是高了不止一个数量级。而且随着综合工具的进步,“电路效率”的差异逐渐被抹平了。
HDL已经如此之“完美”,为什么又会冒出HLS呢?一方面,人类追求真善美是无止境的(这是一句鸡汤,不喜欢的就不用看了),真正重要的是:随着FPGA规模的增大,验证FPGA的功能仿真阶段在整个开发过程中的占比越来越高。2000年之前,可能设计电路和验证功能(功能仿真)时间占比可能是8比2,到后来逐渐的7比3,再到现在差不多4比6了。也就是说,超过一多半的时间花在了功能验证上了。这一多半时间中的一半又花在哪里了呢?设计和编写testbench了。testbench是个神马东东呢?讲白了就是一个数据发生器兼接收器兼鉴别器:把数据(不管是否合法)灌进FPGA、从FPGA接收反馈、然后根据预设的需求规格来判定FPGA反馈的对还是不对。
用HDL做设计,必须要考虑功能、可综合、效率、时钟树、功耗、IO、布局布线等等N多因素。可是用HDL写testbench完全没必要考虑那么多。一个显而易见的推论就是:使用更高层次的抽象语言显然可以大幅度提高testbench的建模和设计效率,从而就从整体上大幅缩短了FPGA的开发周期。在经历了SystemVerilog、SystemC、C、C++、OpenCL等诸多尝试之后,使用更高抽象层次的设计语言来设计FPGA就变成了众望所归(用中文来说就是变成了刚需),就有了今天的HLS。
那么问题来了:HDL和HLS相比,到底哪个更好?Well,回答这个问题还是需要一定的水平的,不然结局要么友谊的小船说翻就翻,要么就跳进人家给你挖的坑里了。如同前面介绍通用计算和异构计算时比较CPU、GPU和FPGA,要看面对的具体应用场景。回答这个问题也要看针对FPGA设计的哪个方面说。从电路效率角度,HDL肯定秒杀HLS;而从仿真建模效率角度,HLS肯定秒杀HDL。HLS当下最大的短板就是“电路效率”太低。简单说:同样一个功能,用HLS不但会占用面积大,而且能跑的时钟频率低。这个短板完全是HLS的高度抽象所带来的,也就是说,高度抽象既是HLS仿真建模的最大优势,又是设计综合的最大劣势。举个简单的例子(例子不一定实际可以验证,只是为了更简洁的说明问题):用HLS写了一段代码(不管是C/C++还是OpenCL),你期望综合出的电路就是一块可以做异步FIFO的RAM。但是由于HLS的高度抽象,对于(智商令人捉急的)综合工具来说,可以综合成RAM,也可以综合成组合逻辑,或许还有第三、第四种解读…也就是说,综合工具暂时没能力综合一个最高效的电路出来。
简而言之,在当下以及不那么久远的将来,使用HDL进行设计而使用HLS进行建模和验证,将是最佳的设计模式:取得了电路效率和验证效率的最佳平衡。随着EDA工具的不断进步(智商余额不断提高),将来我们可以期待HLS既可以设计代码,也可以建模验证。菜刀也就终于进化成了无坚不摧的小李飞刀。
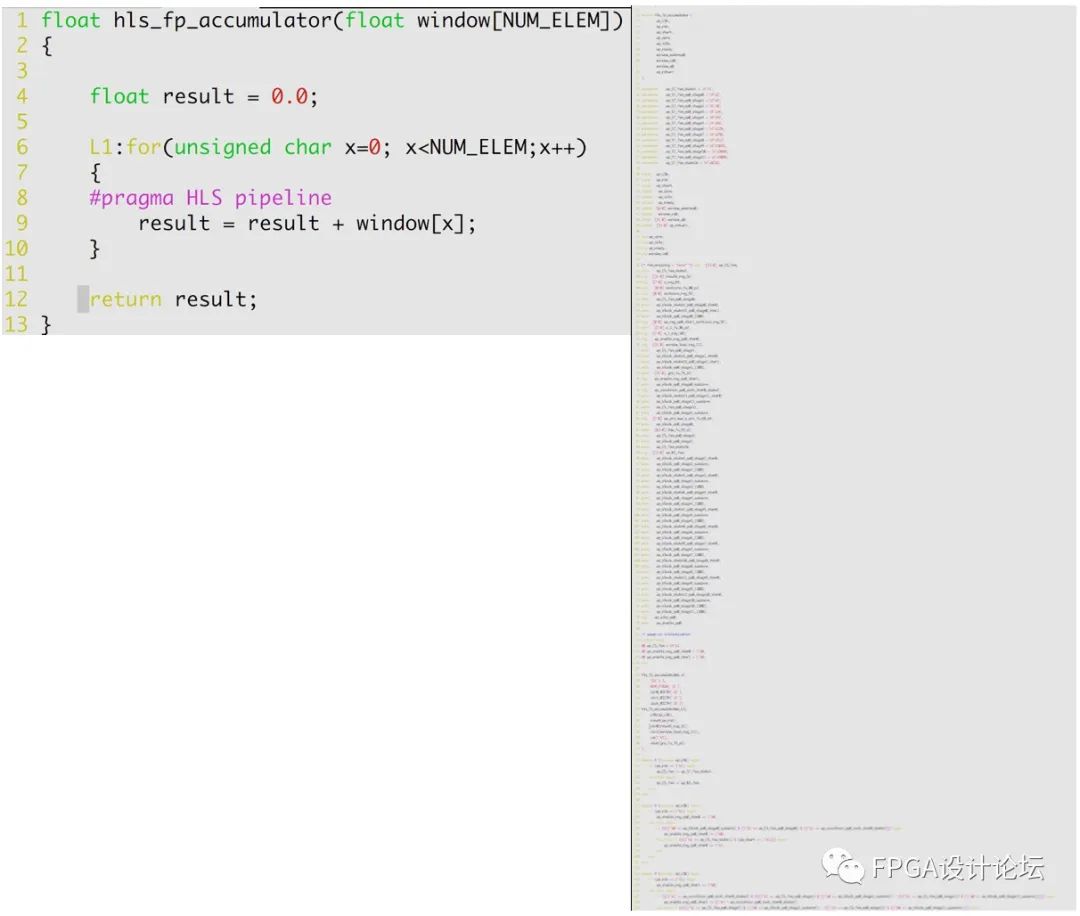
图4:同样的功能,使用HLS和使用RTL分别来描述的对比
审核编辑:刘清
-
异构计算的概念、核心、优势、挑战及考虑因素2025-01-13 2322
-
【一文看懂】什么是异构计算?2024-12-04 4450
-
异构计算:解锁算力潜能的新途径2024-07-18 30226
-
新一代计算架构超异构计算技术是什么 异构走向超异构案例分析2023-08-23 1737
-
异构计算场景下构建可信执行环境2023-08-15 1133
-
异构计算的前世今生2021-12-17 5915
-
什么是异构并行计算2021-07-19 2328
-
异构计算在人工智能什么作用?2019-08-07 3719
-
异构计算,你准备好了么?2018-09-25 819
-
异构计算:架构与技术2018-09-18 1269
-
异构计算的两大派别 为什么需要异构计算?2018-04-28 23616
-
基于FPGA的异构计算是趋势2018-04-25 11755
-
「深圳云栖大会」大数据时代以及人工智能推动下的阿里云异构计算2018-04-04 1849
-
异构计算芯片的机遇与挑战2017-09-27 1537
全部0条评论

快来发表一下你的评论吧 !
